基于神经网络与MapReduce的科技云数据清洗模型
2017-07-20杨朔杨威陶砾金凤飞
杨朔+杨威+陶砾+金凤飞
摘 要: 科技云服务平台积累了大量科技数据,而数据质量问题会对大数据的应用产生致命影响,因此需要对存在质量问题的大数据进行清洗。文章提出了一种数据清洗模型,采用神经网络,依据数据相关性原则实现高可扩展性的大数据清洗。使用该模型,能够以计算机自动化数据修正的方式代替数据补录与修正工作,有效地提升工作效率。
关键词: 海量数据; 数据清洗; 神经网络模型; 多任务优化; MapReduce
中图分类号:TP399 文献标志码:A 文章编号:1006-8228(2017)07-06-03
Data cleaning model of the science and technology cloud based on
neural networks and MapReduce
Yang Shuo, Yang Wei, Tao Li, Jin Fengfei
(Zhejiang Topcheer Information Technology Co.,Ltd., Hangzhou, Zhejiang 310006, China)
Abstract: The science and technology cloud service platform has accumulated a large number of scientific and technological data, and the data quality problem will result in a fatal impact on the application of big data. Therefore, the massive data with quality problem need to be cleaned. In this paper, a data cleaning model is proposed, which according to the data correlation principle, uses neural networks to realize the big data cleaning with high scalability. Using this model, the repeated data refills and corrections can be replaced by computer automatic data correction, the work efficiency is effectively improved.
Key words: massive data; data cleaning; neural network model; multitask optimization; MapReduce
0 引言
科技創新云服务平台的建设过程中,集成了大量科技数据,由于数据的来源广泛,数据标准不同,数据录入要求及录入人的素质差异,导致大量的“脏”数据产生,从而导致了数据的可用性降低,影响整个数据分析的过程。
1 现状分析
云平台现有的数据分为几大类,一是基础数据,如机构信息、载体信息、人员信息等,该类信息有明确的来源,可通过业务认定系统以及工商、行政、公安、民政等第三方管理部门的接口进行验证;二是业务数据,由业务相关人员完成填报,需要经过监管部门和专家校验,出错的可能性不大,有一定的时效性和制约性;三是其他辅助数据,如证明材料等等。因为云平台的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来,而且包含历史数据,这样就避免不了有的数据是错误的,有的数据相互之间有冲突。目前不符合要求的数据主要有不完整的、错误的、重复的数据三大类。
⑴ 不完整的数据主要是一些应该有的信息缺失,如仪器设备信息中仪器设备的英文名称、产地国别、生产制造商、主要技术指标等等,这类数据在业务填报时往往不做要求,但在需要查找定位设备时却有很重要的意义。
⑵ 错误的数据产生的原因主要是业务系统不够健全,在接收输入后没有进行判断或无法判断正确值域的情况下直接写入后台数据库造成的。
⑶ 重复的数据的产生原因主要因为数据入口不统一,同一个数据通过不同的入口被录入系统,由于申报口径并不统一,申报人不同,导致无法判断是否为重复数据。
科技数据本身的严谨性很重要,其相关性也是数据分析的重要因素,为了能有效的利用科技数据,将其作为科技工作决策提供依据,基础数据就需要尽量完整、严谨并且具有明晰的关系网,而这就需要进行数据清洗。数据清洗(Data cleaning)——对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
传统的清洗方式一般是要求数据来源方重新梳理补全并修正,但这样工作量很大,特别是不同的管理入口负责人并不能确保哪一方的数据是正确的,仅仅针对系统中几十万条待处理的科研仪器设备,就有很大的难度,更何况是云平台内TB级的海量数据,所以就需要有一种计算机自动化的方式来进行数据清洗工作。
2 模型设计
以科研设备为例,简单的设备信息记录的清洗通过对单一表的分析无法实现自动化数据清理,但是将设备的基本信息与申报单位信息、单位之间的关联信息、设备维护人员信息、设备使用信息等大量相关内容进行组合,将单一的设备信息变成多维度的综合信息后,就可以利用设备的关系网进行分析。因此本文设计通过神经网络,利用云平台中的海量数据进行分析,从而去除重复,修正错误并尽可能的补足缺失内容。
2.1 构建遗传神经网络
人工神经网络(artificial neural network,ANN)是一种模拟人脑信息处理机制的网络系统,它对输入输出样本进行自动学习,将输入输出之间的映射规则自动抽取并分布存储在网络的连接中,能够以任意的精度逼近复杂的非线性映射。BP(backpropagation)神经网络是至今为止应用最为广泛的神经网络。虽然得到广泛应用,BP神经网络也存在不足,最明显的两点不足是收敛速度慢和易陷入局部极小值。遗传算法(GA- Genetic Algorithm)是一种自适应的全局搜索算法,具有全局收敛、并行性和鲁棒性等特点。
本文采用神经网络和遗传算法结合的方法,利用遗传算法搜索神经网络的权值的最优解,可以在一定程度上能克服传统神经网络易陷入局部极小值的缺点。基于以上分析,将遗传神经网络应用到计算整个记录的相关性中。
2.1.1 参数设定
遗传神经网络各个参数设定如下。
⑴ 神经网络的网络结构
理论证明:三层BP神经网络可以以任意精度逼近非线性函数脚。本文采用三层结构,输入层、隐藏层和输出层的节点数分别为以n,m,1;神经元的激励函数一般采用Sigmoid函数,即
⑵ 适应度函数
在遗传算法中,对适应度函数的要求是:单调,连续,非负和最大化。由于目标函数是神经网络中的误差平方和,且为求其最小值,因此适应度函数定义如下。
该式中,S训练样本总数,M输出神经元的个数,E全局误差,t期望输出,y实际输出。
⑶ 遗传算子:选择、交叉是遗传算法的基本算子
选择算子:采用轮盘赌选择方式,以个体适应度值的高低来进行随机选择。保证了高适应度值的个体以大的概率遗传到下一代中去。计算适应度为的个体对应的选择概率为
交叉算子:从父代里随机选择两个个体,随机地、独立地选择相同数目的连接权值进行交换。选取的交换数目由自适应交换率决定。这使得适应值大的个体交换率小,适应值小的交换率大,从而保证优良个体的遗传性。
变异算子:采用自适应变异率,将变异率同个体的适应度值联系起来,使适应度大的个体变异率小,适应度小的个体变异率大。
2.1.2 网络训练过程
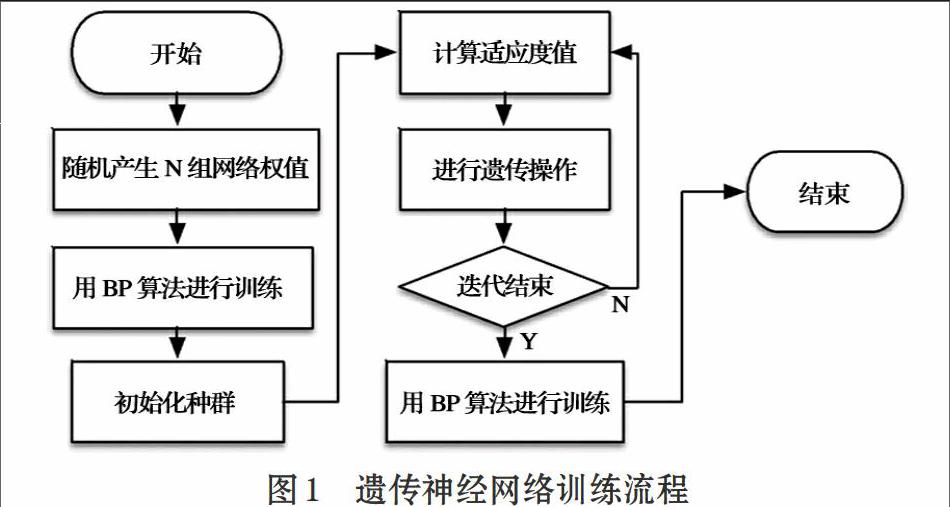
先用BP算法训练一个预定结构的神经网络,直到全局误差不再减少为止,然后在此基础上用遗传算法进行若干代的优化,最后,再利用BP算法进行局部的调整。这种组合方法的基本思想是先用BP算法确定使误差函数取最小值的权值组合,再利用遗传算法去掉可能的局部极小值,最后再利用BP算法进行局部优化。
网絡训练流程如图1所示。
2.1.3 记录相关性检测框架
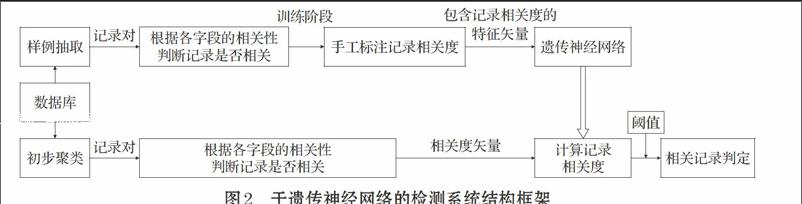
基于遗传神经网络的相似重复记录检测系统的框架如图2所示,系统分为训练阶段和检测阶段。
在训练阶段,首先,从数据集中抽取若干对记录作为训练样例,其次,使用上文中提出的记录相关度计算方法根据两个记录的对应字段的相关性计算出的记录的相关度,并手工标注记录对的相关度;最后,将包含记录相关度的特征矢量作为输入,训练遗传神经网络。
在检测阶段,为了降低时间复杂度,先对数据集进行初步聚类,初步聚类采用基于Canopies的方法进行,这种方法可以在数据集上快速产生若干个重叠的可能的相关记录聚类;然后将同一聚类中的记录两两组成记录对,使用上文中提出的记录相关度计算方法计算出记录对的相关度,得到记录对的相关度矢量,再利用训练好的遗传神经网络计算记录的相关度。最后选择合适的阈值,确定相关的记录。
2.2 数据修正
整理出相关数据后,可使用Hadoop 平台对相关数据进行基于任务合并的并行大数据清洗。下面通过图3和式1简要介绍本模块的实现。
[开始][参数估计][连接][修正][结束]
⑴
⑴ 参数估计模块
整个修正系统是用贝叶斯分类的思想来计算出概率最大的记录作为标准记录。参数估计模块的任务是利用式⑴计算出所有的概率,其中P(X)对所有取值为常数,所以只需要计算P(X|Ci)P(Ci)即可。在各个取值的先验概率未知的情况下,不妨假设其是等概率的,因此只需计算P(X|Ci)即可。对于具有多属性的数据集则采用式⑵来计算P(X|Ci)。
⑵
因此,整个参数估计模块就是用来计算所有属性的每个取值的概率。概率论中认为,当样本空间足够大时概率≈频率,系统用统计不含缺失值的元组中各个属性取值出现的频率的方式来计算概率P(X|Ci)。
⑵ 连接模块
系统在修正模块会根据式⑵计算出拥有差异数据的元组在它的依赖属性取值确定的所确定的各个待修正值的概率。但是由于MapReduce函数在map阶段和reduce阶段一次只能处理一条记录,所以系统必须使依赖属性取值和其条件概率关联起来,这就是连接模块存在的必要性和需要解决的问题。连接模块的输入数据为参数估计模块的输出数据和原待修正数据,输出数据是将含修正数据的元组中依赖属性取值与该取值条件概率相关联的文件。
此模块的输入数据为原待修正数据和参数估计模块的输出,输出数据为经过填充之后的数据。利用式⑵计算出每个Ci(待填充属性可能的取值)对应的条件概率,选择其中P(X|Ci)概率最大的Ci进行填充。
⑶ 修正模块
修正模块由一轮MapReduce实现,首先将连接模块的输出结果和原始输入数据以偏移量为键值进行连接运算,map阶段和连接模块类似,reduce阶段利用式⑵计算出每个Ci(待填充属性可能的取值)对应的条件概率,选择其中P(X|Ci)概率最大的Ci作为基准数据对其他同组数据进行修正。
3 总结
本文提出的数据清洗模型,可用于数据的相关性分析,使用MapReduce编程框架利用并行技术可对现有的科技云服务平台数据进行清理,能够在保留原始数据的前提下提高数据质量。目前该模型成功地对科研设备数据完成了清洗,用计算机自动化数据修正的方式代替了重复数据的补录和修正工作,有效地提升了工作效率。下一步将把该模型扩展应用到云平台的所有相关数据,完成数据清洗工作的同时,研究提高决策分析的准确程度。
参考文献(References):
[1] 宋均,祝林.基于云计算的海量数据处理平台设计与实现[J].
电讯技术,2012.52(4):566-570
[2] 冯秀芳,肖文炳.神经网络的数据分类算法在物联网中的应
用[J].计算机技术与发展,2012.22(8):245-248
[3] 杨东华,李宁宁,王宏志等.基于任务合并的并行大数据清洗
过程优化[J].计算机学报,2016.1:97-108
[4] 金连,王宏志,黄沈滨等.基于Map-Reduce的大数据缺失值
填充算法[J].计算机研究与发展,2013.50(z1):312-321
[5] 孟祥逢,鲁汉榕,郭玲等.基于遗传神经网络的相似重复记录
检测方法[J].计算机工程与设计,2010.31(7):1550-1553
[6] 徐晓.基于RBF神经网络的数据挖掘研究[J].计算机与网络,
2014.19:67-69
[7] 李仲,刘明地,吉守祥等.基于枸杞红外光谱人工神经网络的
产地鉴别[J].光谱学与光谱分析,2016.36(3):720-723
