随机模糊算法下的复杂社会网络研究
2017-06-05俞静,季姝
随机模糊算法下的复杂社会网络研究
∗
俞静季姝
(河海大学商学院南京211100)
针对全球化发展带来的复杂社会网络节点关系分析难度大的问题,论文在随机模糊算法概念下对复杂社会网络的节点集合进行划分。利用复杂社会网络拓扑结构性质,从网络矩阵关系结构为出发点,分别修正了网络节点路径长度和边集内聚集系数。通过随机概率定义实现了完全规则网络到完全随机网络的过渡,对每个独立的社会网络节点进行编码并设定唯一的标签,完成网络节点集合的聚集度发现。通过算法仿真结果表明:随机模糊算法在随机概率取0.5时,复杂社会网络节点聚集划分过程中节点时间复杂度优于传统的模糊聚类算法,该算法在8次迭代后社会网络节点重叠模块率达到0.92。
社会网络;网络节点;随机概率;模糊算法
Class NumberTP391.6
1 引言
在全球化相互关联的背景环境下,从事管理工作的人都认为社会网络至关重要[1]。随着社会的不断发展,不同类型的社会网络会产生不同的结果[2]。因此,充分了解复杂社会网络之间的关系可以为资源的整合利用带来更加高效的工作业绩。其中,社会网络理论将一定网络中的不同的个体与其他个体相互作用后,在外部环境中实现动态的接触、决策和分析,为整个社会网络及时分享共有资源信息[3]。现有的社会网络分析主要有角色连接轮廓方法[4]、混合隶属度随机块模型[5]和关系强度控制机制[6]等。论文在分析复杂社会网络拓扑结构的基础上,利用边集和点集构造复杂社会网络矩阵关系,通过修正网络节点路径长度和边集内的聚集系数将任意两个节点的边相连,即形成全连接的社会网络。运用固定概率定义完全规则网络到完全随机网络的过渡,在对网络节点设立唯一的标签并加以编码更新迭代,最终得到复杂社会网络节点集合的最佳划分。
2 复杂社会网络拓扑
2.1网络矩阵
关于复杂社会网络的表示方法主要分为两种[7]:一种是关于网络图的表示,一种是基于社会网络矩阵的表示。就网络图而言,对于社会复杂网络的描述可以利用符号以及图论的语言进行精确的表示[8]。一般情况下,边集E(G)和点集V(G)以及边集E(G)中的每条边eij共同构成整个复杂的社会网络G(V,E)。其中边集E(G)集合中的元素个数对应其边数,点集V(G)集合中的元素个数对应其网络的阶数。依据点集和边集的情况,可以将社会网络划分为无向网络、有向网络、无权网络、加权网络四种复杂的社会网络[9]。在社会网络G(V,E)的点集V(G)中可以将社会网络划分为定向网络和非定向网络。划分标准为按照任意的节点(i,j)以及(i,j)是否对应同一条边而进行的划分,所谓的定向网络则是指不对应同一条边的情况。同时还能够根据边集E(G)的长度进行社会网络的划分,将|eij|=1的情况划分为无权网络,将|eij|≠1的情况划分为加权网络。
就社会网络矩阵的描述而言,可以利用相互邻接的矩阵来描述某个关键节点之间的关系,它主要包含的社会网络的性质是最常见的网络的拓扑性质[10],这也是最基本的性质。可以利用相毗邻的矩阵进行表示。假设关联矩阵用L表示,邻接矩阵用N来表示,对于一个n阶的图论,将其设定为一个对称的n阶矩阵,表示内容如下


2.2路径长度修正
在社会网络中,可以通过利用m条边(i,k1),(k1,k2),…,(km-1,kj)将随机的节点i和节点j连接起来,那么两个节点之间形成的边则称为节点i和节点j之间的路径[12]。假设两个随机的节点之间所经过的边数为x,则取其值最小的路径为最短路径,长度用dij进行标记,那么对于选定的两个节
将节点w(eij)定义为G(V,E)上关于边eij的非负函数,此时称边eij的“权重”为w(eij)。同时将其邻接的矩阵N定义为[11]点之间的距离的平均值又称为社会网络的路径平均长度,其计算公式如下:

其中,N表示社会网络所拥有的节点的个数,同时每个节点同自身的距离为L=0,在假设社会网络不存在路径可连接的节点,那么此时利用公式计算出来的节点i和节点j之间的最短的距离被定义为无穷大[13],此时的社会网络路径平均距离的最小值L发散。此时还需要对社会网络的路径平均距离计算公式进行修正,其表达公式如下

其中,关于社会网络中随机两个节点之间进行信息传送的平均效率的表达式如下
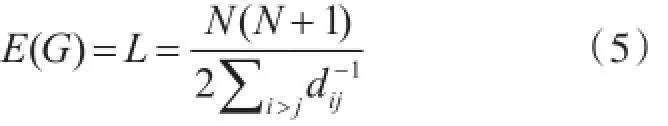
从以往的分析中可以发现,在复杂社会网络中的节点进行信息传送的平均效率与两个节点之间的距离呈现正相关的关系,也就是说,如果网络内的两个节点之间的信息传输效率越高,那么这两个节点之间的平均距离也相对较短。
2.3聚集系数测度
在复杂社会网络中,通过对聚集系数加以研究,将其设定的参数运用到实际的聚类特征分析以及复杂社会网络的集约化程度中去,实现对社会网络的深度研究[14]。当网络中的关键节点的边集中的k条边同其他相互独立的相同数量的节点相互连接时,可将这些边集构成的联系的边的数量设定为Ei。此时的边集内的聚集系数可表述为


其中,Si和Di代表包含顶点i的三角形的个数和以顶点i为中心的三点组合的个数。同时,在复杂社会网络的聚集系数中的平均值计算公式如下

同时可以通过集合定义的方式将其表述为
从上述公式中不难发现,C的取值范围在0~1之间。在网络规模的模式下,社会网络的聚集系数为O(1)。当C=1时,表明复杂社会网络中不管是什么节点,其聚集系数全部为1,在网络中布满了边并且相互连接,社会网络中的的节点也因此充分的聚集。而C=0则意味着社会网络中的节点与节点之间是相互独立的,因此此时的社会网络不存在边,只存在点。也就是说网络中的任意两个节点都有边相连,即网络是全连接的,网络中的节点是充分聚集的
3 随机模糊算法
3.1社会网络建模
复杂社会网络模型研究的对象主要是针对社会网络的聚类特征分析以及实际网络中的小世界分析。为了对复杂社会网络进行测量和分析,因此引入社会网络的网络模型进行研究。社会网络模型的具体构造如下:
1)基于规则网络的设定[15]:当邻耦合网络已知且最近,并且它主要节点的数量设为N,同时对于社会网络中的随机的节点与周围的节点相互关联,两侧的节点连接的个数设定为K 2。
2)边随机连接[16]:对社会网络中的聚类中的边进行重新连接,连接的规则随机,概率为固定概率P。这种情况下的连接主要是对于一条边的固定,然后按照之前固定的概率进行节点的选取。除此以外,还需要设定节点无法和自身相互连接同时节点与节点之间的距离不能超过一条边。

图1 复杂社会网络模型
按照图1所显示出来的模型中参数,N=12,K=4,随机概率P的取值依次为0、0.5、1,与图1的模型的网络图依次对应。从上述的社会网络的模型中可以发现,当随机概率P的值取0时,此时的网络为完全规则网络,当随机概率P的值取1时,此时的网络为完全随机网络。当随机概率P的值取在0~1时,此时的网络可由完全规则网络实现到完全随机网络的过渡。
3.2算法构建
对于随机模糊算法的构建首先需要明确最核心的思想,即无论是哪个节点,所加入的节点集合的结果都是以其临近的邻居加入的节点集合为主要参考的。因此,随机模糊算法针对每个独立的节点,都将其编码并设定唯一的标签,同时这样的设定同之前预先设定的社会网络是不存在联系的,同时对于网络结构的问题的转移和更新,完成网络节点集合的发现。随机模糊算法的步骤具体内容如下:
Step1:首先对社会网络中的每一个节点设立唯一的标签并加以编码;
Step2:对算法中的迭代次数设定为t=1;
Step3:在算法中将社会网络的所有节点按照随机的原则进行排列,同时产生网络中节点的随机序列;
Step4:按照将社会网络中的之前设定节点的编码号变更为与其相邻的邻居的加入节点集合次数最多的编号,当次数等同出现时则随机抽取其中一个节点的编码原则实现对每一个节点进行编码的更新;
Step5:当出现社会网络中存在一个节点的编码同其周围的邻居参加节点集合的次数最高的编码相同时,则终止算法,编码不再更该,否则回到Step3同时设迭代次数为t=t+1;
Step6:算法停止,此时编码相同的节点,划分在同一节点集合中。
在上述的随机模糊算法的步骤中,其中自Step4开始,就会根据社会网络中成员加入节点集合最多者的编号来更新自己的编码,通过前人的实验可以表明,通过异步的方式将能够实现那些集聚节点集合的划分,这样的方式还有另外一个优点,即能够避免在二分图这样的特殊社会网络结构出现的编码震荡的问题。除此之外,通过这样的方式进行随机模糊算法演绎,还有一个最为突出的优点,即其时间复杂度与线性相似。设t表示算法中迭代的次数,n表示社会网络中存在的节点的个数,d表示在算法中的节点的平均度,则此时随机模糊算法的复杂度可以表示为O(tdn),设m表示社会网络中存在的边的个数,则此时随机模糊算法的复杂度可以表示为O(tm)。实验证明,随机模糊算法应用于大型网络效率最高,且能够较好地实现节点集合划分。
4 算法仿真
4.1仿真环境
本文实验部分选取的软件的配置为8核2.4GHz处理器,8G内存,安装的操作系统为Win⁃dow10 64位版本,同时进行模拟仿真算法演绎的软件选取的实验的Visual Studio 2010 Ultimate。前人对于社会网络的模拟仿真研究多选用NS2或者OPNET这样的模拟仿真软件,最主要的是针对不同层次协议而进行的性能统计。本文在社会网络的逻辑拓扑基础上进行算法推进,若采用以往的软件来做仿真,可能会受到网络传输因素的影响,同时不利于实现网络拓扑。如若选取Matlab进行仿真,好处在于数据处理方便,但也存在输入输出文件可能因为不规范而不匹配的问题。
4.2节点测试
利用被检测的节点数目表示复杂社会网络节点,在经过修正的路径长度和聚类系数测度对社会网络节点进行随机概率选取后生成标签号值,利用随机模糊算法对社会网络重复计算12次得到标签数据平均值。在选取随机概率P=0,0.5,1构造不同随机模糊系数与传统的模糊聚类算法进行比较。经过算法计算结果表明,随机概率P=0.5时的随机模糊算法在复杂社会网络节点编码设定的标签号数量明显少于传统的模糊聚类算法,即对于复杂的社会网络节点聚集划分过程中节点时间复杂度趋于平稳,具体的标签号变化情况如图2。

图2 编码标签对比
4.3迭代测试
利用本研究提出的随机模糊算法对复杂社会网络编码标签时间复杂度分析的基础上,为了比较社会网络模拟结构数据在网络节点的聚集性表现,即社会网络节点重叠模块率E。对选定不同的随机概率考查算法的12次迭代效果如图3所示。

图3 网络节点聚集度对比
由图3可得,当随机概率P=0.5时,随机模糊算法在7-8次迭代过程中可以得到最佳的社会网络节点聚集划分效果(E=0.92);当随机概率P=0时,随机模糊算法则要通过9-11次迭代才能得到较好的社会网络节点聚集划分;当随机概率P=1时,随机模糊算法的最优节点聚集划分随着迭代次数的增加而增加。总体而言,在随机概率P=0.5时,可以在经过较少的迭代次数条件下得到较好的社会网络节点聚集划分效果。由于复杂的社会网络节点反应节点在聚集度中的标签,因此,论文提出的随机模糊算法的编码标签迭代可以经过简单的随机概率控制社会网络节点的聚集度结果划分。
5 结语
研究复杂社会网络之间的关系可以提升资源整合力度、加快工作业绩,论文讨论了复杂社会网络拓扑结构,从复杂社会网络节点路径长度和聚集系数两个方面进行修正改进,提出了一种针对复杂社会网络节点聚集度的随机模糊算法。该算法利用随机概率定义完全规则网络到完全随机网络的过渡,利用每个独立的社会网络节点进行编码并设定标签,通过网络结构的问题的转移和更新迭代实现网络节点集合的聚集度划分。实验验证了该算法在网络节点编码标签聚集划分时间复杂度与迭代计算过程中表现出更佳的结果。
[1]李栋,徐志明,李生,等.在线社会网络中信息扩散[J].计算机学报,2014,37(1):189-206.
LI Dong,XU Zhiming,LI Sheng,et al.Online social net⁃works of information diffusion[J].Journal of Computers,2014,37(1):189-206.
[2]田家堂,王轶彤,冯小军.一种新型的社会网络影响最大化算法[J].计算机学报,2011,34(10):1956-1965.
TIAN Jiatang,WANG Tietong,FENG Xiaojun.A new kind of social network influence maximization algorithm[J].Journal of Computers,2011,34(10):1956-1965.
[3]陈运森.社会网络与企业效率:基于结构洞位置的证据[J].会计研究,2015(1):48-55.
CHEN Yunseng.Social Networks and Enterprise Efficien⁃cy:Based on the location of evidence of structural holes[J].Research on Accounting,2015(1):48-55.
[4]窦炳琳,李澍淞,张世永.基于结构的社会网络分析[J].计算机学报,2012,35(4):741-753.
DOU Binglin,LI Shusong,ZHANG Shiyong.Analysis Based on Social Network Structure[J].Journal of Comput⁃ers,2012,35(4):741-753.
[5]师锋洋,王莉,黄博.基于混合隶属度随机块模型社会网络结构分析[J].太原理工大学学报,2015(5):561-565.
SHI Fengyang,WANG Li,HUANG Bo.Random block model of social network analysis based on mixed member⁃ship[J].Journal of Taiyuan University of Technology,2015(5):561-565.
[6]蔡红云,马晓雪.在线社会网络中基于关系强度的访问控制机制[J].山东大学学报(理学版),2016,51(7):90-97.
CAI Hongyun,MA Xiaoxue.Access control based on rela⁃tionship strength for online social network.Journal of Shan⁃dong Universuty(natural science),2016,51(7):90-97.
[7]徐恪,张赛,陈昊,等.在线社会网络的测量与分析[J].计算机学报,2014,37(1):165-188.
XU Ge,ZHANG Sai,CHEN Hao,et al.Measurement and analysis of online social networks[J].Journal of Comput⁃ers,2014,37(1):165-188.
[8]刘向宇,王斌,杨晓春.社会网络数据发布隐私保护技术综述[J].软件学报,2014,25(3):576-590.
LIU Xiang,WANG Bing,YANG Xiaochun.Social network data released Survey of privacy protection[J].Journal of Software,2014,25(3):576-590.
[9]成平广.基于拟态计算的社会网络划分算法[J].计算机科学,2015,42(8):136-137.
CHENG Pingguang.Social Network mimicry computing di⁃vision algorithm[J].computer science,2015,42(8):136-137.
[10]郭进时,汤红波,王晓雷.基于社会网络增量的动态社区组织探测[J].电子与信息学报,2013(9):2240-2246.
GUO Jinshi,TANG Hongbo,WANG Xiaolei.Detection Based on Dynamic Social Network Community Organiza⁃tion increments[J].Electronics&Information Technolo⁃gy,2013(9):2240-2246.
[11]李卫平,杨杰.基于随机梯度矩阵分解的社会网络推荐算法[J].计算机应用研究,2014,31(6):1654-1656.
Network nodes for complex social relations brought about by globalization analysis difficult problems,the present study in the random algorithm fuzzy concept network node complex set of social divide.The use of complex topologies nature of so⁃cial networks,from the relationship network matrix structure as a starting point,each network node corrected path length and clus⁃tering coefficient within the edge set.By random probability defined rules to achieve a complete network transition to a fully random network,encode each independent social network nodes and assign a unique tag,complete set of network node discovery.By algo⁃rithm simulation results show that,the random probability is 0.5,and complex social network aggregation node node partitioning of time complexity than traditional fuzzy clustering algorithm after 8 iterations social network node module overlap rate of 0.92.
social networks,the network node,random probability,fuzzy algorithm
TP391.6
10.3969/j.issn.1672-9722.2017.05.031
2016年11月7日,
2016年12月20日
国家自然科学基金面上项目(编号:71171207);河海大学中央高校基本科研业务费项目(编号:2013B33114)资助。
俞静,女,博士,副教授,研究方向:资本市场。季姝,女,硕士研究生,研究方向:信用风险。
Complex Social Networks Based on Random Fuzzy Algorithm
YU JingJI Shu(Business School,Hohai University,Nanjing211100)
