基于特征相似度的可比语料挖掘汉柬命名实体等价对∗
2017-06-05
基于特征相似度的可比语料挖掘汉柬命名实体等价对∗
徐璐1,2严馨1,2夏青1,2周枫1,2莫源源3
(1.昆明理工大学信息工程与自动化学院昆明650500)(2.昆明理工大学智能信息处理重点实验室昆明650500)(3.云南民族大学东南亚南亚语言文化学院昆明650500)
命名实体翻译等价对在跨语言信息处理中具有非常重要的应用价值,然而由于语料资源的有限性,国内外关于汉柬命名实体等价对的抽取方法还没有深入研究。论文从可比语料文本出发,根据不同类型实体要素的特点以及在可比语料中的特点,选取了柬文命名实体到中文命名实体的音译特征、翻译特征、可比语料中命名实体的上下文特征及自身的长度特征,提出了一种基于多特征融合来计算相似度的方法来挖掘汉柬双语命名实体等价对。实验表明该方法取得了比较好的效果,其中挖掘人名实体对的准确率达到76%,召回率达到66%,证明了该方法要优于只采用单一特征的方法。
命名实体等价对;汉柬双语;多特征融合;可比语料;音译模型
Class NumberTP391.1
1 引言
命名实体是语言信息的关键载体,包括人名、地名、组织机构名等具有名称标识的实体,而命名实体翻译等价对是指源语言实体与目标语言实体可互为翻译,可比语料则是在两篇双语语料文本中,内容不完全一致,但是讨论的话题或主题是相同的。Cao[1]利用中英文网页中英实体共现的特点来进行命名实体等价对的挖掘。Lu[2]利用网页中的锚点文本获取命名实体等价对。Klementiev[3]提出在英俄可比语料中能够获取英俄命名实体音译等价对的方法。Lam[4]团队提出了基于语义和语音信息匹配的双语命名实体等价对的抽取方法。Rapp[5~6]在双语可比语料中通过计算上下文的词向量相似度来判断候选命名实体等价对的相似度。Lu和Zhao[7]在可比语料中挖掘实体等价对时,定义了多个特征并进行特征的线性融合来计算候选命名实体等价对的相似度。Tao[8]则利用在不同语言环境下同一主题下的命名实体具有时空分布的特性来挖掘命名实体等价对。Wang[9]对可比语料中使用高关联度词对种子词典没有覆盖到的词进行替代来扩充种子词典的覆盖率,提高了实体等价对挖掘的准确率。
本文针对以上研究现状,充分考虑各种类型命名实体从源语言转换为目标语言的特征、可比语料中命名实体所在位置的上下文特征以及命名柬文命名实体和中文命名实体自身的一些特征,采用特征融合的方法来挖掘汉柬双语命名实体等价对。
2 挖掘框架
汉柬命名实体等价对的挖掘总体框架如图1所示。

图1 可比语料获取实体等价对框架
具体步骤如下:
1)命名实体识别
针对柬文的命名实体的识别使用基于CRF模型的柬埔寨语分词工具和命名实体识别工具[10],而针对中文的命名实体的识别使用中科院的中文命名实体识别工具。
2)命名实体特征选取
计算源语言实体和目标语言实体的特征相似度,需要充分利用不同类型实体的特征[11]。柬文中的人名、地名转换为中文具有音译特征;而柬文组织机构名到中文组织机构名的转换往往通过意译结合音译,这就需要翻译特征;此外不同语言实体本身的长度也是实体的特征之一;由于实体的挖掘是在文本中进行的,就要充分考虑实体上下文的文本特点。综上所述,我们主要选取的特征为:音译特征、翻译特征、长度特征、上下文向量特征。
3)特征相似度计算
根据命名实体的类型,将不同的特征融合到一个计算模型中,为每一个特征分配不同的权重,计算每个候选等价对的相似度,取相似度最大的候选等价对作为最终的输出结果。
3 特征相似度计算
3.1音译特征
音译是指将目标语言具有相似的发音序列作为源语言的翻译,在人名和地名的翻译中经常用到的方式就是音译。其音译概率的计算流程如图2所示。

图2 音译概率生成流程图
音译概率的生成步骤为
1)将汉柬双语命名实体等价对的语料进行人工标注,包括柬文人名实体的音节切分标注以及柬文人名实体音节到中文汉字的翻译标注。
2)定义条件随机场模型进行数据训练所需要的特征模板,使用音译单元上下文特征、音译单元序列上下文特征、标注之间的转移特征组合形成的特征模板进行学习。
3)条件随机场根据训练数据和定义的特征模板对特征进行学习,对模型中的参数进行估计,构建出音译模型。
4)在汉柬人名实体集合中,由音译模型计算给定的柬语人名翻译为中文人名的概率值。
这里采用基于序列标注方法构建的柬-汉音译模型[12]。使用式(1)计算两个集合间的各实体间的音译相似度:

其中,km代表柬文人名实体集合中的一个柬文人名实体;cn代表中文人名实体集合中的一个中文人名实体;λ是音译模型中的参数;Z(x)表示归一化因子。
3.2翻译特征
命名实体中的组织机构名是一种特殊的实体要素,为了计算两个组织机构名的翻译模型概率,使用IBM统计翻译模型中的翻译模型概率。
翻译概率模型的生成流程图如图3所示。

图3 翻译概率模型生成过程
翻译概率模型的构建步骤为:
1)汉柬平行句对齐文本的预处理,去掉噪声和干扰。
2)GIZA++词对齐。此处考虑到翻译是正序的,故对应的GIZA++调序配置项设置为否。
3)计算翻译概率。
用生成的翻译概率模型计算组织机构名的翻译特征相似度,如式(2)所示:
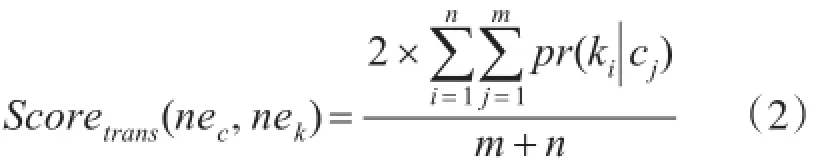
其中nec表示中文命名实体,n表示中文命名实体nec中词的个数,nek表示柬文命名实体,m表示柬文命名实体nek中词的个数,ki表示nek中的第i个词,cj表示nec中的第j个词。
3.3上下文词向量特征
在柬文和中文两种不同语言表述的可比语料中,如果文中某一个命名实体的上下文信息相通,则这两个命名实体就有可能是互为翻译的。上下文词向量特征相似度计算流程如下:
1)候选命名实体的识别
该部分在柬-汉音译特征研究中已经介绍,这里不再赘述。
2)上下文信息的选取
首先在柬文语料中标记全部的该柬文实体,然后将语料中该实体每个位置所在句子的前4个词及后4个词收集起来作为该柬文实体的上下文信息,形成集合个数为8的柬文实体上下文词集合。用同样的方法可以得到中文实体上下文词集合。
3)上下文词信息翻译集合构建
使用汉柬双语词典作为柬文实体上下文词的翻译工具,形成对应的中文翻译集合。
4)将中文翻译集合与中文上下文词集合进行比较
如翻译集合中的一个翻译词存在于中文上下文集合中,将该词放入中文实体上下文向量集合中,同时该柬文词放入柬文实体上下文向量集合中。重复此过程,直到源语言和目标语言上下文词集合中不存在翻译词。
5)向量相似度计算
获取Km所在句子中Km的前4个名词与后4个名词,组成柬文实体上下文词集合INFOkm={kq1,kq2,kq3,kq4,kh1,kh2,kh3,kh4},同理得到中文实体上下文词集合INFOch={cq1,cq2,cq3,cq4,ch1,ch2,ch3,ch4}。使用汉柬双语词典比较IN⁃FOkm和INFOch,假定INFOkm中的一个柬文词ki具有的翻译集合为T={t1,t2,…,tw},比较翻译集合T与中文实体上下文词集合INFOch,若翻译集合T中的一个翻译ti存在于INFOch中,我们就把这个翻译ti作为中文命名实体Ch的上下文词向量VECch=[vc1,vc2,…,vcn]中的一维元素,将柬文词ki作为柬文实体上下文词向量VECkm=[vk1,vk2,…,vkm]中的一维元素。最后分别从柬文实体上下文词集合INFOkm和中文实体上下文词集合INFOch中删除ki和ti。对这个过程进行不断的迭代,直到上下文INFOkm和INFOch中不再有等价的翻译词。
使用式(3)计算VECkm和VECch中每个词的权重,这样使得柬文命名实体上下文词向量和中文命名实体上下文词向量中的每个词都有一个权重值。

式中tfi表示ti在Km的上下文中出现的次数。Km上下文中所有词出现的次数总和用∑tfi表示。
VECkm和VECch中每个词向量权重计算完成后,将上下文词向量转换为对应的权重向量valuekm和valuech。最后,候选汉柬命名实体等价对的上下文词向量特征相似度如下:
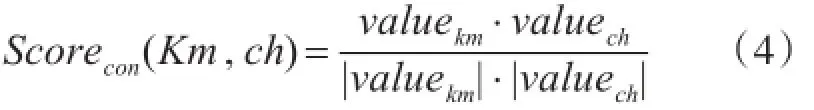
其中valuekm为柬文命名实体对应的权重向量,valuech为中文命名实体对应的权重向量。
3.4长度特征
我们统计了8392对汉柬命名实体等价对,发现中文实体汉字的长度和对应柬文实体kcc字符的长度的比值在1~2之间,因此使用柬文kcc的长度与汉字长度的比值作为一维特征相似度来约束柬文实体与中文实体的长度匹配,长度相似度的计算如式(5):

其中,Ch表示中文命名实体,Km表示柬文命名实体,Lkcc表示柬文命名实体kcc字符的长度,Lcha表示中文命名实体汉字的长度。
4 汉柬双语实体等价对相似度计算
分别为选取的四种特征进行权重分配,将各特征值进行归一化处理后得到最终的汉柬双语实体等价对相似度。表1为命名实体各特征组合的权重设置统计表。

表1 实体特征组合权重分配表
每种特征值都表示候选汉柬命名实体等价对在该特征方面的相似度,我们将四种特征融合到一个计算模型中来评价候选汉柬命名实体等价对的相似度,计算模型如式(6)所示。
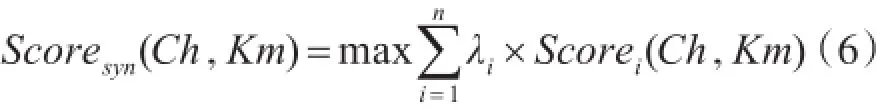
其中,Km表示候选汉柬命名实体等价对中的柬文命名实体,Ch表示候选汉柬命名实体等价对中的中文命名实体。Scorei(Ch,Km)是当使用第i个特征计算中文命名实体Ch与柬文命名实体Km在该特征上的相似度,λi表示特征i在计算中的权重,将所有的特征进行加权求和,取结果最大值的候选命名实体等价对作为最终的挖掘结果输出。
5 实验及结果分析
5.1评价方法
评价方法包括准确率(P),召回率(R),F值(F),计算公式如下:
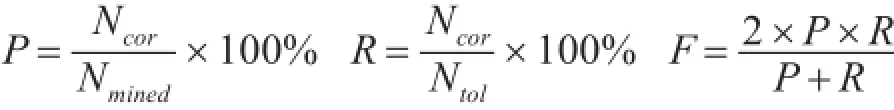
其中Ncor是挖掘到的正确的命名实体等价对,Nmined是挖掘到的命名实体等价对,Ntol是可比较语料中存在的命名实体等价对。
5.2实验语料
实验用到的汉柬可比语料库的统计如表2,该可比语料库人工标注了语料中的命名实体等价对以及实体的类型用作标准结果来对比挖掘的汉柬命名实体等价对。

表2 可比语料数量及语料中各类型实体数量统计
5.3实验结果分析
命名实体对挖掘实验结果如表3所示,表中特征组合按照第4节中的权重分配表设置。
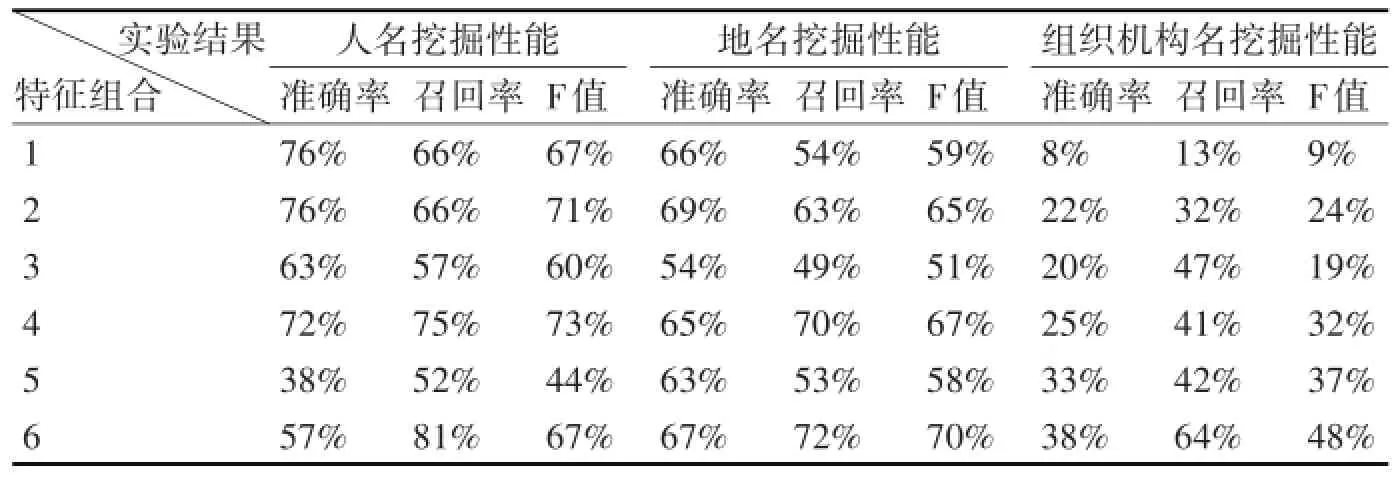
表3 使用不同特征组合挖掘人名、地名、组织机构名命名实体挖掘性能
从表3实验结果可以看出,人名和地名命名实体挖掘的主要特征是音译特征,在加入上下文词向量特征后,挖掘性能达到最高,说明上下文词向量特征对人名和地名的挖掘有一定的帮助,而长度特征和翻译特征对挖掘性能的提升并不大。而组织机构名的挖掘主要是音译特征与翻译特征的结合,当加入上下文词向量特征和长度特征会对挖掘性能有一定的提升。
6 结语
本文通过分析汉柬命名实体等价对的特点,提出了音译特征、翻译特征、上下文词向量特征以及实体的长度特征,并将这些特征进行了线性组合,并根据要挖掘实体的类型进行了相应权重的设置,从而在汉柬可比语料中挖掘汉柬命名实体等价对。最后设置相关的实验进行了验证,实验表明提出的各项特征都起到了较好的效果。在下一步研究中,我们将通过实验探索从而确定最佳的权值与特征线性组合,得到准确率和召回率更高的命名实体等价对。
[1]Cao G H,Gao J F,Nie J Y.A System to Mine Large-Scale Bilingual Dictionaries from Monolingual Web Pages[C]// Proceedings of MT Summit Xl.Copenhagen,Denmark:Dtw Deutsche Tierrztliche Wochenschrift,2007.
[2]Lu W,Lee H,et al.Anchor Text Mining for Translation of web Queries:A Transitive Translation Approach[J].ACM Transactions on Information Systems,2004,22(2):242-269.
[3]Klementiev A,Roth D,et al.Named Entity Transliteration and Discovery from Multilingual Comparable Corpora[C]// In Proceedings of the Human Language Technology Con⁃ference of North American Chapter of the ACL,New York,America:Association for Computational Linguis⁃ tics,2006.
[4]Lam W,et al.Named Entity Translation Matching and Learning:With Application for Mining Unseen Transla⁃tions[J].ACM Transactions on Information Systems,2007,25(1):1-32.
[5]Reinhard Rapp.Identifying Word Translation in Non Par⁃allel Texts[C]//33rd Annual Meeting of the ACL,Massa⁃chusetts,USA:DBLP,1995.
[6]Reinhard Rapp.Automatic Identification of Word Transla⁃tions from Unrelated English and German Corpora[C]//37th annualmeetingoftheACL,GoldCoast,Australia,1999.
[7]Lu M,Zhao J.Multi-feature Based Chinese-English Named Entity Extraction from Comparable Corpora[C]// The 20th Pacific Asia Conference on Language Informa⁃tion and Computation,Wuhan,China:Association for Computational Linguistics,2006.
[8]Tao T,et al.Unsupervised Named Entity Transliteration Using Temporal and Phoetic Correlation[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing:Conference on Emnlp,2006.
[9]Lishuang Li,Peng Wang,Degen Huang,Lian Zhao:Min⁃ing English-Chinese Named Entity Pairs from Comparable Corpora[J].ACM Trans.Asian Lang.Inf.Process.(TALIP),2011,10(4):1-19.
[10]潘华山.基于条件随机场的柬埔寨语词法分析方法研究[D].昆明:昆明理工大学,2014.
PAN Huashan.Cambodian lexical analysis based on con⁃ditional random method[D].Kunming:Kunming Univer⁃sity of Science and Technology,2014.
[11]王鹏.从可比语料中抽取中英命名实体等价对[D].大连:大连理工大学,2011.
WANG Feng.The equivalence of named entities in Chi⁃nese and English from comparable corpora[D].Dalian:Dalian University of Science and Technology,2011.
[12]Qing Xia,Xin Yan,Zhengtao Yu,Shengxiang Gao.Re⁃searchontheextractionofWikipedia-basedChi⁃nese-Khmer named entity equivalents[C]//The 4th CCF Conference on Natural Language Processing and Chinese Computing,Nanchang,China:Springer International Publishing,2015.
Chinese-Khmer Named Entity Equivalents Excavation Based on Feature Similarity in Comparable Corpus
XU Lu1,2YAN Xin1,2XIA Qing1,2ZHOU Feng1,2MO Yuanyuan3
(1.School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming650500)(2.The Intelligent Information Processing Key Laboratory,Kunming University of Science and Technology,Kunming650500)(3.School of Southeast Asia&South Asia Languages and Cultures,Yunnan Minzu University,Kunming650500)
Named entity translation equivalent has been playing a significant role in the processing of cross-language informa⁃tion.However limited by the corpora resource,few in-depth studies have been made on the extraction of the bilingual Chi⁃nese-Khmer named entity equivalents.Starting from the comparable corpus text,according to the type of entity characteristics and comparable corpus characteristics,the paper selects transliteration feature,translation feature,context feature of the bilingual Chi⁃nese-Khmer named entity equivalents and length feature.So a method based on multi-feature fusion is proposed to calculate the sim⁃ilarity to excavate the bilingual Chinese-Khmer named entity equivalents.The experiment shows this method has a good perfor⁃mance when the bilingual Chinese-Khmer named entity equivalents are acquired through the computation of feature similarity,turn⁃ing out that the method proposed in this paper is able to give better effect compared with the method using only a single feature.
named entity equivalents,Chinese-Khmer bilingual,multi-feature fusion,comparable corpus,transliteration model
TP391.1
10.3969/j.issn.1672-9722.2017.05.020
2016年11月10日,
2016年12月20日
国家自然科学基金“柬埔寨语命名实体识别及汉柬双语语料库构建方法研究”(编号:61462055);国家自然科学基金“基于篇章特征的越南语新闻事件元素抽取关键技术研究”(编号:61562049)资助。
徐璐,男,硕士研究生,研究方向:自然语言处理。严馨,女,副教授,硕士生导师,研究方向:自然语言处理。夏青,男,硕士研究生,研究方向:自然语言处理。周枫,男,副教授,硕士生导师,研究方向:自然语言处理。莫源源,男,博士,讲师,研究方向:自然语言处理。
