基于评论主题分析的评分预测方法研究
2017-06-01马春平陈文亮
马春平,陈文亮
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
基于评论主题分析的评分预测方法研究
马春平,陈文亮
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
推荐系统(recommender system)广泛应用于电子商务网站。目前流行的基于协同过滤的推荐算法利用用户的历史评分来预测用户对物品的喜好程度。随着互联网的发展,如今的电子商务网站越来越注重与用户的交互,于是产生了大量的用户生成内容(user generated content),如评论、地理位置、好友关系等。相对评分来说,用户对物品的评论从用户或者物品的各个角度具体表达了用户的观点。利用这些信息更有助于挖掘用户的喜好。该文提出一种基于词向量的方法挖掘用户评论信息,并结合协同过滤的方法设计新的推荐算法,来改善评分预测的效果。实验结果表明,该算法较大程度上提高了评分预测精度。
推荐系统;评分预测;词向量;用户评论
1 引言
推荐系统是根据用户的历史行为和兴趣特点,为用户推荐其感兴趣的信息或商品。推荐系统可以通过评分预测来实现,即将预测评分高的商品推荐给用户。传统的推荐算法包括基于内容的推荐[1](content-based recommendation)和协同过滤(collaborative filtering)。基于内容的推荐算法过于依赖用户和物品的描述性的特征,无法利用用户的反馈信息。协同过滤算法,如User-Based[2]、Item-based[3]、Slope One[4],简单有效,在互联网公司中得到广泛应用。但是协同过滤算法仅以用户的历史行为为依据推测用户对物品的喜好,没有深层次挖掘用户或者物品的特征,例如,两个用户均对一家餐馆打出5分满分,但是评价角度可能不同,一个人认为菜肴美味,另一个觉得服务周到。
近年来,Web2.0得到飞速发展,其关键特征之一就是用户主导生成内容。评论信息是重要的用户生成内容之一,一些电商网站,如淘宝、大众点评、Yelp等,拥有数千万用户对大量商品或者餐馆的评论。这些评论是用户对商品各个角度的评价,可以看作用户对物品评分的详细解释。而传统的推荐算法往往忽略这一重要资源。近几年,情感分析和意见挖掘领域已经有大量的工作成功从文本中挖掘出有效信息[5-7]。对评论的角度(如服务、口味、环境等)和情感(正面、负面、中立等)的挖掘对推荐系统领域有重大的利用价值[8-13]。GANU等人[8]利用人工标注评论的主题和情感,然后训练SVM[9]模型,将评分的角度和情感进行分类,最后将正面评价、负面评价进行综合作出评分预测。QU等人[10]提出意见袋(bag-of-opinions)的概念,用来表示评价词根、修饰词和否定词。利用意见袋和评分训练线性模型进行评分预测。这些算法都是根据用户对物品的评论预测用户对物品的评分,并不能直接用于推荐系统。MCAULEY等人[11]提出利用HFT(hidden factors as topics)将评分和评论信息结合,构建特征矩阵,利用SVD[12]来作推荐,但无法同时考虑评论信息中的用户角度和物品角度。ZHANG[14]等人利用LDA(latent dirichlet allocation)[15]算法对评论进行主题分析生成主题词表,利用主题词表将用户评论表示成特征向量,然后利用机器学习算法建模进行评分预测。但是评论属于非结构化文本,具有异构、海量、实时等特点,处理难度较大,ZHANG等人的工作主要缺陷是主题词表产生了大量无关词,影响了推荐效果。
本文在上述基于评论分析的研究工作基础上,提出基于词向量的方法挖掘评论信息,设计基于评论分析的推荐算法,然后结合传统推荐算法改善推荐系统的性能。在大众点评数据集进行实验验证,结果表明本文提出的算法有效地提高了推荐系统的评分预测性能。
2 相关工作
Web2.0时代的到来使得用户能够在网络上发表自己的看法,同时也可参考他人的意见和评论作出自己的决定。因此,很多推荐系统的研究者把目光转移到从用户评论中挖掘用户喜好和物品特征,从而提高推荐效果。GNAU等人对评论进行情感和角度的标注,将标注结果利用SVM分类器进行训练和测试,然后对其他评论进行分类。最后利用式(1)来预测评分。
(1)
其中,P代表评论中正面评价的句子的数量,N代表评论中负面评价的数量。该方法只考虑正面评价和负面评价,忽略了中立评价和评论角度,并且该方法需要大量的人工标注工作且准确性不高。
QU等人提出用意见袋(bag-of-opinions)的表示方式来挖掘评论信息。每条评论中都有针对物品不同方面的多种评论意见,该方法将每条评论中的每个评论意见表示为一个三元集合,包括词根集(root words)、修饰词集(modifier words)、否定词集(negation words)。如“书不是非常便宜,但对自己很有帮助。”这条评论意见中“便宜”和“有帮助”是词根,“非常”和“很”是修饰词,“不是”是否定词。在一条评论意见中,词根决定了用户评价的情感,修饰词加强或者减弱了评价的情感,否定词则消减或者转变评价的情感。该算法为每个意见赋予一个评分,各个意见的评分的平均分即该条评论的评分,计算每个意见评分的公式如式(2)所示。
(2)
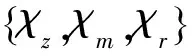
GANU和QU等人提出的方法都是利用用户的评论来预测该用户对商品的评分。这些算法无法直接用于推荐系统,因为在决定是否对一个用户推荐一款该用户从未接触过的商品时,无法得到该用户对该商品的评论。
MCAULEY等人提出利用HFT(hidden factors as topics)将评分和评论信息结合起来做推荐。HFT将评分中的隐含因子和评论中的隐含主题匹配生成用户或者物品的特征矩阵,然后用SVD来做评分预测。但是用户对物品的评论可能是从物品角度出发的,也可能是从自身角度出发的。HFT的缺点是每次只能考虑评论的用户角度和物品角度中的一个。
ZHANG等人利用LDA算法对评论进行主题分析,生成主题词表。根据评论中是否含有主题词来将一条评论表示成一组向量,将这些向量根据用户或者物品归类,经过平均、归一化等处理得到用户特征和物品特征。同时利用向量和对应的评分,通过机器学习模型训练得到用户对物品不同的主题的权重。在评分预测阶段,利用用户特征和物品特征模拟出目标用户对目标物品的评论特征向量,结合用户对物品不同的主题的权重得到目标用户对目标物品的预测评分。由于评论文本的非结构化特征和LDA算法的局限性,该方法生成的主题词表含有大量无关词,从而影响了推荐效果。因此本文分别提出了基于人工标注方法和基于词向量的方法构建主题词表,并结合协同过滤算法设计一种混合推荐算法。
3 基于评论的推荐算法
本节针对基于评论的现有工作[11, 14]所存在的问题,提出两种新的评论主题分析方法。在此基础上,提出一种结合协同过滤算法的组合算法。
3.1 相关定义

3.2 评论主题分析
本节使用不同方法进行用户评论分析,生成主题词表。根据评论是否涉及各个主题将评论表示成一组K维向量(K是主题个数),分析结果将在3.3节中被用于推荐系统。
3.2.1 基于LDA的评论分析
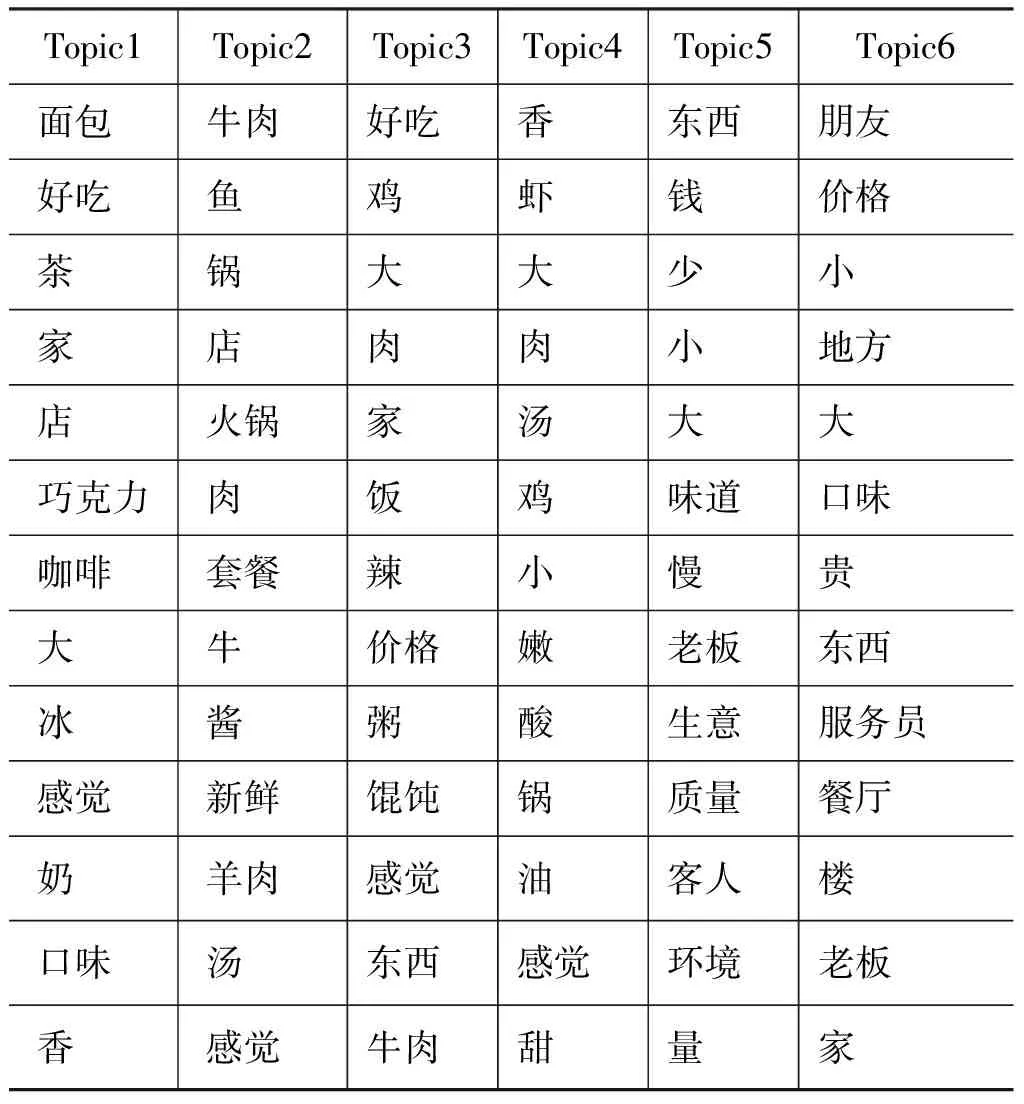
ZHANG等人提出利用LDA算法挖掘评论主题,大众点评数据集*数据表述见4.1节。经LDA算法生成的主题分布如表1所示,主题词按在该主题下的概率由大到小排列。实验主题数设置为6,每个主题的主题词个数设置为20。

表1 基于LDA的主题分布(大众点评网)
续表
3.2.2 基于人工标注的评论分析
由于基于LDA的评分分析存在大量的与相应主题无关的词,因此本节考虑利用人工标注的方法生成主题词表。考虑到评论中主要用形容词表达情感,本文提取评论中的所有形容词,按词频由高到低排序,然后对出现次数高于20的形容词标注主题和情感。主题数设定为6,分别为食物、服务、价格、环境、酒水、路程。由于各个主题的主题词数目不同,其中食物出现113个主题词,服务出现114个出题词,价格出现24个主题词,环境出现123个主题词,酒水的主题词只有13个,路程出现21个主题词。表2显示每类前20个主题词,其中正面情感标注为1,负面情感标注为-1。
从表2可以看出,人工标注的主题词表比LDA生成的主题词表可靠得多,但人工标注费时费力。
3.2.3 基于词向量的评论分析
为了解决人工标注的不足,本节提出基于词向量的主题分析方法挖掘评论中用户的喜好和意见,该方法既克服了LDA算法的局限性和不可靠性,

表2 人工标注主题分布
又避免了大量的人工标注工作。词向量(word embedding)是将语言中的词进行数学化,表示成一组向量的一种方式。word2vec是MIKOLOV等人[16]提出的将词表征转化为实数值向量的高效工具,其输入是大量文本语料库,输出是词的向量表示。得到的词向量可以被用于很多自然语言处理任务和机器学习任务,如词性标注、句法分析、命名实体识别等。我们可以利用词向量表示来寻找词的相近词集合。基于词向量的这个特性,可自动寻找某主题下的主题词,具体步骤如下。
(1) 利用word2vec*https://code.google.com/p/word2vec/工具将所有评论数据中的词表示为词向量;
(2) 本文中主题数设定为6,分别为食物、服务、价格、环境、酒水、路程。依据cosine相似度,找到与各个主题词最相近的20个词,过滤无关词,将剩余的词按相似度由大到小排序,取前10个词作为主题词候选词。
(3) 同样根据词向量相似度,找到各个主题下每个候选词最相近的10个词,将其加入到各个主题的主题词候选词中,每个主题下有110个主题词。
(4) 过滤重复词与无关词,然后将剩余词按相似度排序,取前20个词。以此得到的主题词表如表3所示,主题词按相似度由大到小排列。
3.3 基于评论主题的评分预测
基于评论分析结果,本文使用线性回归模型构建评分预测系统。
3.3.1 模型参数训练
根据评论分析结果,对评论进行特征表示。评论Cu i的特征表示为θu i,如式(3)所示。
(3)
其中,K是实验设置的主题的个数;θu ik表示用户u对物品i的评论第k个特征值。特征值的计算方式如式(4)所示。
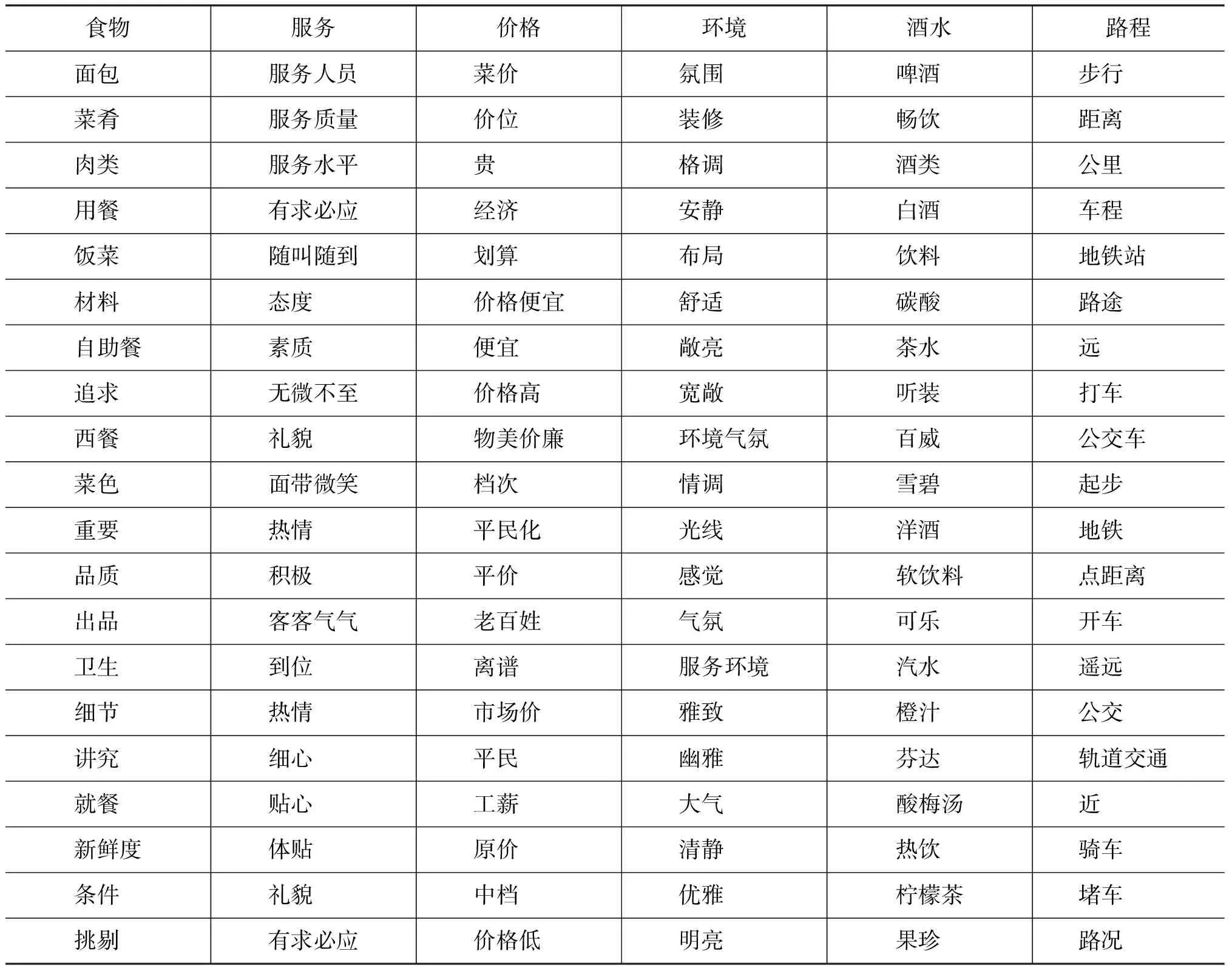
表3 基于词向量的主题分布
(4)
其中,n是各个主题下主题词的个数,若评论中包含该主题词t,则θuikt是各个主题词对应的值,反之,θuikt为0。根据不同的主题分析方法,θuikt的值略有不同,具体计算方法如表4所示。

表4 θuikt计算方式
在得到每条评论的特征表示之后,利用线性回归模型训练特征权重,如式(5)所示。
(5)
其中,W是各个主题的权重;ε是误差偏置;rui是该条评论中用户u对物品i的评分。
3.3.2 评分预测
由于在评分预测阶段,系统无法预知用户的评论,因此本文模拟用户u对物品i的评论的特征表示用于评分预测。首先,生成用户和物品过的特征表示。用户u第k维特征用puk表示。
(6)
其中式(6)是对相应的特征进行归一化。同样,定义物品i第k维特征,如式(7)所示。
(7)
由式(6)产生的用户特征和式(7)产生的物品特征计算出评论的特征如式(8)、式(9)所示。
(8)
(9)
然后,对于给定的目标用户u和目标物品i,根据线性回归得到的权重W和误差偏置ε,以及模拟的评论特征表示,使用式(10)计算目标用户u对物品i的评分。
(10)
3.4 组合推荐算法
在上述基于评论主题的推荐算法的基础上,本文提出结合协同过滤算法的组合算法。协同过滤算法由于简单高效而得到广泛应用。Bias From Mean是协同过滤算法中的一种,由HERLOCKER等人[17]在1999年提出,它的优势就是计算代价低,可解释性较强。计算公式如式(11)所示。
(11)

将Bias From Mean的预测结果βui作为线性回归模型的特征之一,新的计算公式如式(12)所示。
(12)
其中,W是各个主题的权重;θui是用户u对物品i的评论的特征表示;ε是误差偏置;βui是Bias From Mean算法的计算结果;Wβ是βui的权重;rui是该条评论中用户u对物品i的评分。得到各个特征的权重,利用模拟出的评论的特征表示和Bias From Mean算法的计算结果即可进行评分预测。
4 实验结果与分析
4.1 数据集
本文实验采用了大众点评网的数据集。大众点评网(www.dianping.com)是中国最大的独立第三方消费点评网站。本文使用的数据集为中文数据集,全部来自上海地区,包含自大众点评2003年成立到2013年中,70万用户对5万个商户的440万条评论。评论信息包含用户名、商户名、总体评分,以及评论文本内容。根据实验需要,过滤数据集中没有文本评论信息的评论,因此本文使用的数据集包含63万个用户对五万个商户的360万条评论,其中88.6%的用户评论数为1~10,平均每个用户评论5.6次,平均每个商户拥有74.3条评论。本文实验采用5重交叉验证,将评论数据按数量随机平分成5份子集,交叉验证重复5次,每次选择一个子集作为测试集,其余子集作为训练集,并将5次交叉实验的平均结果作为最后的实验结果。其中评论数据的评分人数分布如表5所示。
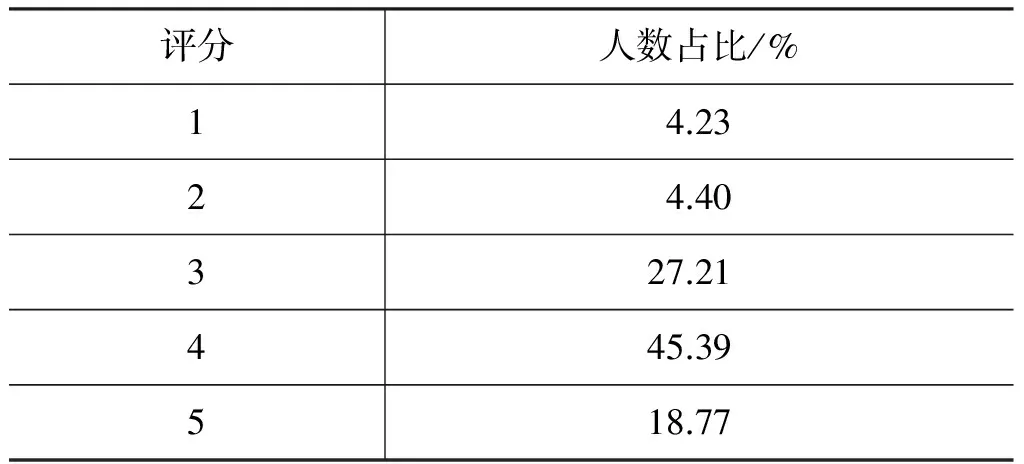
表5 评分人数分布
4.2 评价指标
本文采用平均绝对偏差(mean absolute error,MAE)评价算法预测准确程度,MAE的计算公式如式(13)所示。
(13)

4.3 实验结果与案例分析
所有实验结果如表6所示。实验1、2、3均是协同过滤的推荐算法,它们的优势在于简单有效,三种方法中BIAS FROM MEAN的效果最好。
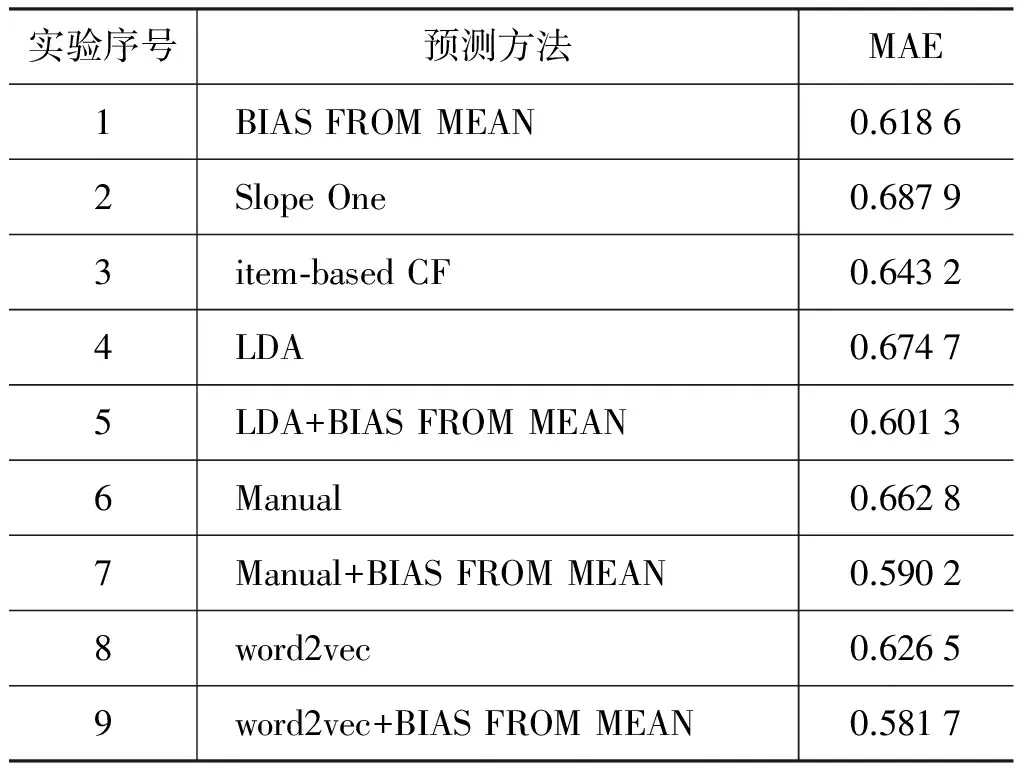
表6 实验结果
实验4~9均是通过分析评论来预测评分,其中实验4、实验5利用LDA算法分析评论。在进行LDA实验时,主题数设置为6,每个主题的主题词个数设置为20,超参数α设置为0.2,β设置为0.1, 迭代次数为1 000,保存步长为100。本文使用的LDA工具是GibbsLDA++*http://gibbslda.sourceforge.net/。为了得到最佳效果,本文考虑将评论作预处理,只取评论中的形容词和名词。实验4以LDA算法进行主题分析,实验结果MAE为0.674 7。实验5在此基础上构建组合推荐系统,其实验结果MAE为0.601 3。
实验6、实验7通过人工标注评论中的主题和情感来分析评论,实验6的结果MAE为0.662 8,实验7在此基础之上构建组合推荐系统,其实验结果MAE为0.590 2。为了避免大量的人工标注工作,同时提高评论主题分析的准确性,实验8、9利用基于词向量的方法分析评论预测评分,实验8的实验结果MAE为0.626 5,实验9在此基础上构建组合推荐系统,其实验结果MAE为0.581 7。
最近研究工作表明,在训练词向量时不同来源的语料对结果有很大影响。本文使用中文Gigaword*https://catalog.ldc.upenn.edu/LDC2003T09语料来获取词向量,进行对比实验。实验结果如表7所示。结果显示,使用餐饮领域(dianping)的评论语料的系统可以更准确预测结果。经过进一步分析,我们发现由于 Gigaword主要是新闻语料,生成的主题词分布中产生大量新闻中常见的专业性词语,而这些词语在评论文本中很少见。这对评分预测的准确性产生影响。

表7 对比实验结果
综上所述,各个方法在加入BIAS FROM MEAN的结果作为线性回归模型的特征之一构建组合算法时,实验性能都能得到一定提高。本文提出基于词向量的方法,采用word2vec工具挖掘评论中的主题和情感,在此基础上构建的组合推荐系统的实验结果是众方法中最佳的。另外,针对用户打分和评论内容存在矛盾这一现象,例如,淘宝用户因怕商家骚扰而给商品好评,但在评论文本中写出真实感受,本文选出一些案例进行实验分析。实验结果如表8所示,实验证明利用本文提出的基于词向量的评分预测模型得出的评分可以在一定程度上更贴近用户的真实评分。
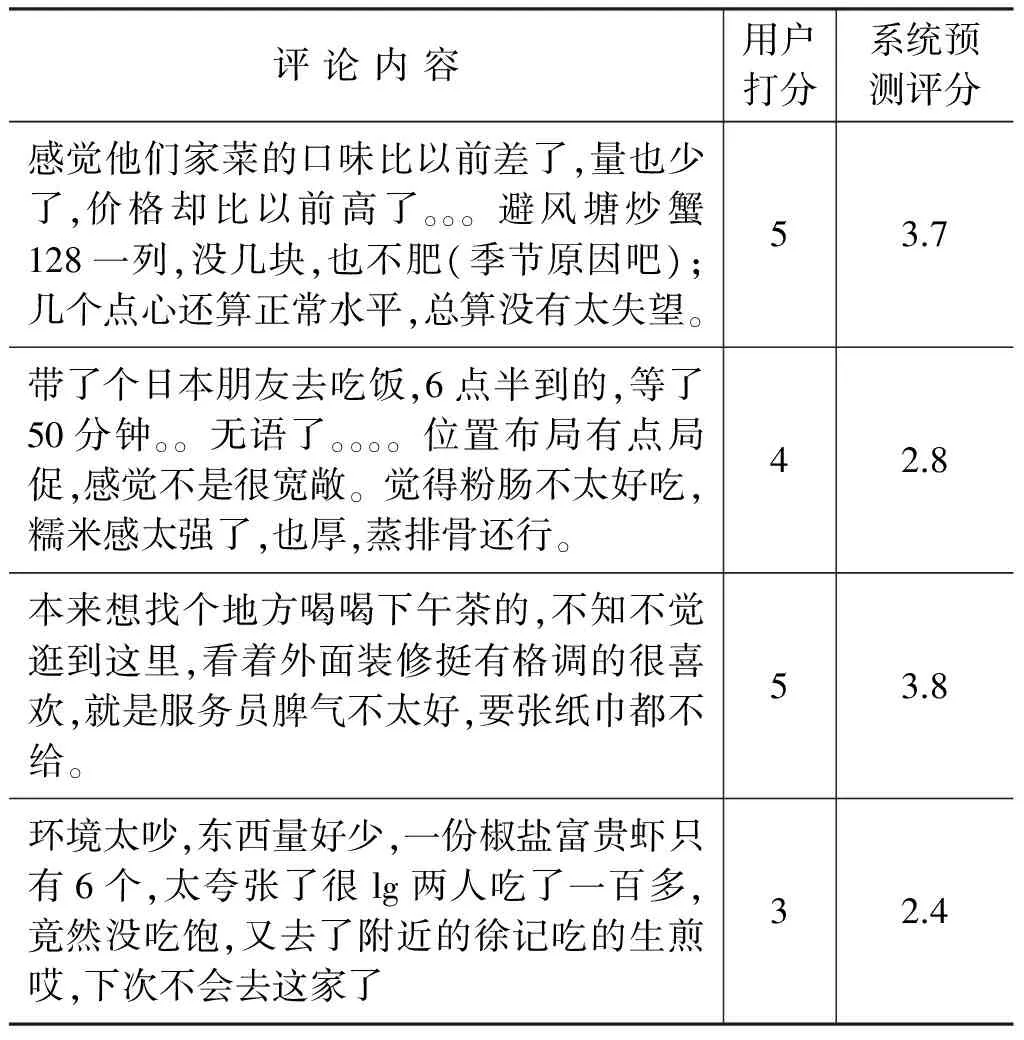
表8 评论内容与打分矛盾案例分析
5 总结与展望
本文针对协同过滤算法和基于评论分析的推荐算法的局限性和不稳定性,提出了采用基于词向量的方法挖掘评论中的评论主题和情感,并结合协同过滤算法,从而形成一种组合推荐模型,起到两者互补的作用。大规模评分预测实验结果表明组合推荐模型能有效提高预测性能。基于评论的推荐算法还有很大的研究空间,如何准确有效地挖掘评论中的主题、情感,避免用户打分和内容生成得分之间出现矛盾,并减少人工干预将是下一步的研究工作。
[1] Schafer J B,Konstan J, Riedl J. Recommender systems in e-commerce[C]//Proceedings of the 1st ACM conference on Electronic commerce. ACM, 1999: 158-166.
[2] Resnick P, Iacovou N, Suchak M, et al. GroupLens: an open architecture for collaborative filtering of netnews[C]//Proceedings of the 1994 ACM conference on Computer supported cooperative work. ACM, 1994: 175-186.
[3] Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th international conference on World Wide Web. ACM, 2001: 285-295.
[4] Lemire D, Maclachlan A. Slope One Predictors for Online Rating-Based Collaborative Filtering[C]//Processdings of the SDM. 2005, 5: 1-5.
[5] Kiritchenko S, Zhu X, Mohammad S M. Sentiment Analysis of Short Informal Text[J]. Journal of Artificial Intelligence Research, 2014, 50:723-762.
[6] Tang D, Qin B, Liu T. Learning semantic representations of users and products for document level sentiment classification[C]//Proceedings of the ACL. 2015:1014-1023.
[7] Wang L, Liu K, Cao Z, et al. Sentiment-Aspect Extraction based on Restricted Boltzmann Machines[C]//Proceedings of the ACL. 2015:616-625.
[8] Ganu G, Elhadad N, Marian A. Beyond the Stars: Improving Rating Predictions using Review Text Content[C]//Proceedings of the WebDB. 2009, 9: 1-6.
[9] Joachims T. A support vector method for multivariate performance measures[C]//Proceedings of the 22nd international conference on Machine learning. ACM, 2005: 377-384.
[10] Qu L, Ifrim G, Weikum G. The bag-of-opinions method for review rating prediction from sparse text patterns[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Association for Computational Linguistics, 2010: 913-921.
[11] McAuley J, Leskovec J. Hidden factors and hidden topics: understanding rating dimensions with review text[C]//Proceedings of the 7th ACM conference on Recommender systems. ACM, 2013: 165-172.
[12] Koren Y, Bell R. Advances in collaborative filtering[M]. Recommender systems handbook. Springer US, 2011: 145-186.
[13] 陈庆章, 汤仲喆, 王凯,等. 采用数据挖掘的自动化推荐技术的研究[J]. 中文信息学报, 2012, 26(4):115-121.
[14] Zhang R, Gao Y F, Yu W Z, et al. Review Comment Analysis for Predicting Ratings[C]//Proceedings of the The 16th International Conference on Web-Age Information Management. Qingdao, 2015:247-259.
[15] Blei D M, Ng A Y, Jordan M I. Latentdirichlet allocation[J]. the Journal of machine Learning research, 2003, 3: 993-1022.
[16] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the Advances in Neural Information Processing Systems. 2013: 3111-3119.
[17] Herlocker J, Konstan J, Borchers A, et al. An algorithmic framework for performing collaborative filtering[C]//Proceedings of Reseach and Development in Information Retrieval. New York: ACM Press, 1999,230-237
A Review Topic Analysis Method for Rating Prediction
MA Chunping, CHEN Wenliang
(School of Computer Sciences and Technology, Soochow University, Suzhou, Jiangsu 215006, China)
Recommender system is widely used in e-commerce web sites. Traditional recommendation algorithms, e.g. collaborative filtering, predict the degree of user preference to an item based on user scoring history. Due to the development of the Internet, e-commerce websites pay more attention to user interactions, which leads to a great deal of user generated contents like comments, geographic locations and social relationships. Compared to the user rating, user comment demonstrates their opinions on different facets of the item. By taking full advantage of user generated contents, user preference can be further discovered. In this paper, we proposed an approach to using word-embedding to analyze review comments and design a novel system to predict the scores. Empirical experiments on a large review dataset show that the proposed approach can effectively improve the precision of the recommender system.
recommender system; rating prediction; word embedding; user comment

马春平(1990—),硕士,主要研究领域为自然语言处理、推荐系统。E⁃mail:machunpingjj@163.com陈文亮(1977—),教授,硕士生导师,主要研究领域为句法分析、知识图谱。E⁃mail:wlchen@suda.edu.cn
2015-09-15 定稿日期: 2016-04-15
1003-0077(2017)02-0204-08
文献标识码:
表可以看出,通过LDA算法挖掘出的主题大致将评论分为以下六个主题,依次为: 甜品,饮料;肉类,火锅;面类小吃;鲜嫩菜类;服务评价;环境评价。同时可以看到在各主题下出现了大量无关的词,这势必会影响评分预测的效果。
