流程挖掘应用于内部审计的研究
2017-05-15付亮
付 亮
长江职业学院湖北武汉430074
流程挖掘应用于内部审计的研究
付 亮
长江职业学院湖北武汉430074
随着新的记录有事务日志的各种工作流管理系统的不断开发和普及,大量流程相关数据伴随着系统运行以日志的形式被记录下来,可以避免人为主观判断偏差等,而流程挖掘正好可以对这样的信息进行分析挖掘,因此,将流程挖掘技术引入内部审计这一领域无疑会是一次很好的尝试。本文论述流程挖掘应用到内部审计的几个切合点,如识关键控制点定位、流程中可能瓶颈、非法舞弊团队、不合规账号等方面的应用展开论述,并提出将传统审计方法与模型审计相结合的新型审计,通过模型相关特性来分析业务流程中设计不太合理的地方。【关键词】流程挖掘;内部审计;研究
一、流程挖掘技术在内部审计中的应用
过程挖掘技术为内部审计提供了一种更严格的检查流程符合性和确定流程有效性的手段,审计人员可以避免因抽取样例而出现漏审或者为避免漏审而大量抽样导致审计的复杂度剧增的情况。引入流程挖掘技术,审计人员可以将业务执行整个过程中的所有实例都考虑在列,在更短的时间内做出更可靠的判断,可以将现有审计方法与模型审计结合起来,大大缩小日志范围,便于进一步的分析,例如专案审计。事件日志和过程挖掘技术使得新形式的审计成为可能,有理由相信,基于事件日志的流程挖掘技术审计将极大地改变审计行业,主要体现在以下两个方面:(1)关键控制点定位,流程中可能瓶颈发现。审计人员还可以基于事件日志数据对现有模型从新的方面进行扩展,比如通过综合考虑到每个活动(任务)执行开始时间以及持续时间,来分析得到流程中各活动执行相关性能数据而找出所有可能存在的瓶颈,例如出现某些对响应要求特别高的业务在某个任务执行或者等待时间相对较长的情况下,审计人员可以根据实际情况以及专业能力来判断其中哪些应该列为关键控制点予以重视。(2)多角度审计。多角度流程挖掘技术必然导致促进多角度审计实现,比如权限或非法操作问题,基于组织视角,有利于发掘出组织中各员工(操作者)间的相互联系,如亲密度,来识别可能的非法舞弊团队,又或者有的组织管理比较混乱,往往出现多个员工使用同一管理员账号登入系统操作,导致潜在的风险加剧,而审计人员往往很容易忽视这一现象或者很难发现相关证据,通过流程挖掘算法分析,可以很容易找出与其他员工执行任务存在差异的特殊“员工”,结合组织结构图和实地调查即可很容易做出判断,是否该“员工”账户存在共享的情况。此外,从审计人员还可以通过基于历史数据构建的流程模型进行预测,比如,结合一些经典的数据挖掘算法,来预测某个活动还需多长时间完成,或者会出现的结果,以此提出建议,最小化预期成本。
二、数据采集及预处理
我们以某保险公司索赔业务处理流程为例,该项业务是用来处理国内索赔问题,各种类型的保险索赔均经由电话进行提交,由两个独立的呼叫中心call centre agent brisbane和all centre agent sydney(简记为B和S)各自运营的组织提供支持,两中心在来电量和平均呼叫处理时间方面是相似的,但在代理的部署方式、底层IT系统上存在差异。通过抽取的日志中包含3512例索赔案例(也即前边提到的过程实例)共涉及46138个事件(即记录数),这里我们选取必要的几个字段进行挖掘,而选择忽略其他属性字段,当然,如果我们获取的数据足够丰富,那么还可以基于其他字段做更多扩展分析,如分析某个流程分支处分支的原因,也即影响流程选择其中某一个子流程继续的潜在因素,可以尝试引入数据挖掘中经典的决策树分析算法来进行操作,这里由于数据限制,我们选择的字段包括:事件所属实例标识(case ID)、事件名(activity)、执行人(resource)、事件开始事件(starttimestamp)以及事件完成时间(complete timestamp)。部分数据源日志数据如图1所示:

图1 部分事务日志
为了使构建的模型更加准确,我们需要首先将日志文件进行预处理,包括日志过滤以及对于多个日志文件进行整合,整合时可以使用ProMimport工具将整合后的日志文件以MXML(mining xml format)的格式输出,特别对于数据来源于某个数据库中多个表的情况以及多个数据库时,我们采用ProMimport工具可以进行很方便的整合转换处理,以MXML格式将整合后的日志用一个MXML格式文件输出。一个MXML文件可以存储大量的流程信息,其典型结构如图2,接下来的挖掘分析工作将利用ProM平台下集成的各类算法插件以及Disco工具完成,转化后的部分日志截图如图3:

图2 MXML格式
每一个processInstance标识的地方代表一个事件序列,其中的id号为标识一个事件序列,该事件序列中事件成员即通过该标识来识别,换句话说,具有相同该id号的事件属于同一个事件标识。每一个processInstance由多个auditTrail-Entry组成,一个auditTrailEntry代表记录中的一条事件记录,它由data、workflowmodel、ElementType、Timestamp、originator组成,data部分描述了诸如activity、resource、costs等事件属性,workflowmodel描述了事件名,ElementType描述了该事件所处状态,一般包含两种状态,一种为start(开始)状态,另外一种为complete(结束)状态。这样记录的好处在于,分析的时候可以很清晰的分清楚什么时候事件开始,什么时候事件结束,由此得出事件等待时间和处理时间,使分析更精准细致。Timestamp描述了该事件该种状态(开始或结束)时的具体时间,originator记录了该事件的操作者是谁。比如我们看图3的最前边一个事件记录,它代表的意思为该事件有三个属性:activity、resource和costs。Activity(活动名)是register request(注册申请),resource(执行者)是Pete,costs(开销)为50,当前事件名为registerrequest,事件所处状态为complete(完成)状态,所处时间timestamp为2010年12月30日14点32分,处理人是Pete。这样就详细描述了一条事件记录,接下来以auditTrailEntry开头再描述另外一个事件,直到id为3的所有事件被描述完,再接着描述另一个以processInstance开头、id标识的另一个事件序列。
将整合后的MXML格式日志导入Prom工具,可以看到有关日志详细信息的界面,如图4所示

图4 ProM日志查看
从中可以看到,该日志总共包含一个processes(流程),3512个cases(案例)共46138个events(事件条数)也即记录条数,共有21个不同event classes(事件类),event types(事件类型)为2种(这里代表start和complete两状态),orginators(执行者)有四种。从右侧的柱状图可以发现,每个案例均至少包含5个事件,最多情况下包含17个,平均包含13个事件。具体每个案例中事件个数及事件发生先后序列也即事件序列见图5:

图5由实例标识索引展示的活动序列
图5 中标有“0”的地方,代表的是编号为0的索赔案例,从图形右侧可以看到它包含9个事件,所有事件序列包含的事件情况有incoming claim(complete状态)、B check if sufficientinformationisavailable(start和complete两状态)、B registerclaim(start和complete两状态)等,对于每个事件这里清晰的列出了与之相关的信息,以B registerclaim(start)为例,代表该事件当前处于start状态,该状态下的时间为1970年1月1日8点,该事件的处理者为callcentre agentbrisbane。接下来的分析将借用Prom中集成的各种算法插件以及Disco完成。
三、流程模型构建
使用算法进行挖掘,挖掘出的模型用Petri表示,如图6为了便于分析,局部放大后得到图7:
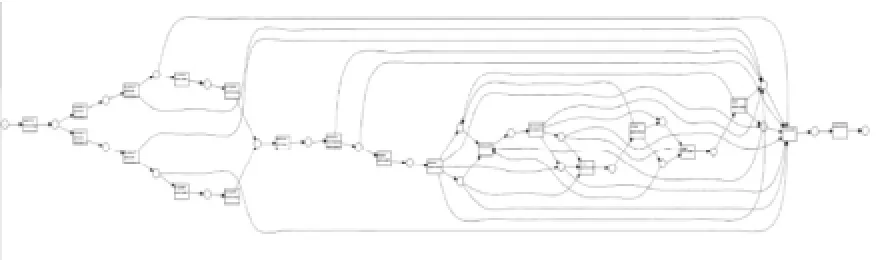
图6 petri网模型
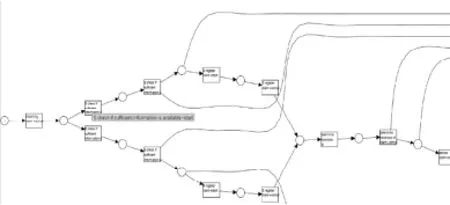
图7 放大后的petri模型
从中可以看到该业务流程为:当一起索赔案例发生后,会由S或者B来执行检查(基于足够的信息),如果是S做的检查,接下来它会有三种选择,如可以选择直接结束案例,也可以是提出索赔(registerclaim),如果S执行完提出索赔,则需要等到B也执行完了提出索赔后,才能进行下一步:确定索赔的可能性,之后可能会执行索赔评估(assess claim),等等。
利用启发式挖掘算法,并设定好相应参数后,得到结果模型如图8,可以看到这里计算出了模型的匹配度为大于0.9。

图8 启发式挖掘模型
将抽取出的10002条记录共包含1423条case(事件)序列导入Disco,利用模糊挖掘算法得到的挖掘模型如图9所示:

图9 模糊挖掘模型
图中可见每个节点的平均执行次数,连接箭头上的数字代表该路径执行次数,例如节点incoming claim(索赔传入)共执行了1423次,也即每一条case序列都执行了该节点,1423次中B checkifsufficientinformationisavailable(B检查资料是否齐全)和S check if sufficient information is available(S检查资料是否齐全)分别执行了713和710次,相差无几。B check执行完的713次接下来分为两个子流程,其中79次是直接到end(结束),另外634次是走到了B register claim(B提起索赔),从incoming claim到B check这条路径共被执行了713次。从incoming claim到S check这条路径共被执行了710次,以此类推。这里展现出来的是包括所有的路径和流程活动情况,可以很清晰的观察出哪些路径执行的次数相对少,而哪些路径相对多,比如,除去开始事件incoming claim和结束事件end之后,执行最多的事件要数determine likelihood of claim(判断索赔可能性),共执行了1198次;执行最多的路径为determinelikelihood ofclaim(判断索赔可能性)到accessclaim(索赔评估),共执行了988次;执行最少的事件为S register claim(S提起索赔),共执行了564次,相应的执行路径最少的为Bcheckifsufficientinformationisavailable(S检查资料是否齐全)到end,共执行了79次。具体到审计工作而言,类似审核审批的活动必然会相对较多一点,如果审计人员发现类似该种类的活动执行次数相对总的执行路径条数有一定差距时,就需要给予关注了,可能该流程的完整程度或者说控制程度有所欠缺,极有可能导致控制失败,应记录为潜在风险点。此外,也应考虑到另一极端,那就是对于一些执行次数相对较少的点或者路径也要给予关注,可能是某些人利用系统漏洞来进行非法操作所在,应具体就实际情况做记录并分析。
四、基于模型的分析
(一)关键节点路径分析
通过对图9所示挖掘模型进行简化,过滤掉执行次数比较少而得到包含相对执行路径次数比较多的关键路径如图10:

图10 路径过滤
可以看到经过滤后的关键路径为,首先是incomingclaim (传入索赔),紧接着要选择A和S中一个中心来审核数据是否充分(B check或Scheck),并各自registerclaim(登记索赔)后determine likelihood of claim(给出索赔可能性报告),然后经过assess claim(索赔评估)步骤后,下一步advise claiment on reimbursement(建议申请赔偿),再下一步就需要initiate payment(初始化赔偿),最后close claim(关闭索赔)end(结束)整个流程。那么,具体到实际内部审计中,我们需要关注哪些环节必须要有而不存在关键路径上的情况,也即缺失明显的审核检查流程,从而导致舞弊风险加剧,又或者哪些少量理应不该直接跨越的路径的存在,很有可能是某些违规操作的路径所在,而应给予重视。
(二)流程性能分析
1.基本性能分析
将日志采用Prom提供的性能分析算法进行挖掘后,得到图11(时间单位为小时)

图11 性能分析
从中可以获知每个任务的执行时间和等待时间信息,如close claim(索赔关闭)这一事件,平均处理时间为0.008(小时),该事件出现频数为1976次,最少处理时间为0(小时),处理时间中数为0.006(小时),最长处理时间为0.057(小时),平均等待时间为0(小时),最短等待时间为0(小时),最长等待时间为0(小时)。从图中可见数据可以发现,平均处理时间最长的事件为B register claim(B索赔注册)为0.144(小时),平均等待时间最长的事件为determine likelihoodofclaim(判断索赔可能性)达2.861小时,进一步观察可以发现该事件最少等待时间为2.193小时,等待时间中数为2.39小时,最长等待时间为10.309小时,说明之所以平均等待时间过长是由于有少数几次等待时间过长的现象存在,具体到审计工作中,基于这一点应进一步展开分析,提取出处理时间相对大于等待时间中数小于最大等待时间的事件和事件序列,展开调查,分析可能原因。再来比较A、B两个呼叫中心,可以很明显的发现,在处理时间上,两者没有太大差别,而在等待时间上,B平均为0.632(小时)远远高于A的0.119(小时),建议保险公司将此情况反映给B呼叫中心,促进其分析可能的原因并做出改进,出于尽最大努力满足客户的需要,如果B的等待时间远远长于A的情况持续存在,没有得到改善,那么可以有选择性的将更多或者部分重要客户的理赔案例通过A中心进行。
将抽取的10003条记录用Disco进行性能分析后得到图12

图12 性能分析
从图中可以看出,B check事件(信息充分提供后B中心完成检查)平均用时29.2秒,S check事件(信息充分提供后S中心完成检查)平均用时31秒;B register claim(B中心提出索赔)平均耗费时间为8.5分,S register claim(S中心提出索赔)平均耗时8.3分。由此验证两中心B中心和S中心确实在处理能力上相当。这里有很多等待时间和处理时间为instant(及时)状态的事件,如B register claim和S register claim的等待时间,assess claim的等待时间等。处理时间上基本上都有耗费一定时间(出去首尾事件incoming claim和end事件),耗费处理时间最短的是B check事件,用时29.2秒,耗费处理时间最长的是assess claim,耗时10.9分钟,耗费等待时间最长的前两位分别为B registerclaim(B注册索赔)到determine likelihood of claim(判断索赔可能性)和S registerclaim(S注册索赔)到determinelikelihood ofclaim(判断索赔可能性),分别高达3小时和3.2小时。说明在有关任务接洽上存在明显的缺陷,部分流程受阻导致整体效能急剧下降,很有可能因此耽误总体工作而导致重要客户流失。通过对流程各节点执行时间的分析,可以准确定位出影响整个流程的主要延迟点所在,审计过程中将那些执行时间相对长的节点应给予相对高的重视,记录下来作为整个审计工作中的重要关注点,也即风险点。
2.瓶颈分析
为了找出影响整个流程完成时间的任务,也即分析该业务流程中可能存在的瓶颈环节,以检测业务流程资源分配是否合理,将日志在按照Prom工具挖掘出的petri网模型上进行重演,找出影响流程效益的关键任务点,得到的性能序列图如图13:

图13 性能序列图
图中显示小方块的地方就是一个耗时较长的block(瓶颈),不难发现,比如图中标记的地方显示,assess claim(索赔评估)环节出现了block(瓶颈),该环节的平均处理>236分钟,阻塞时间超过了11分钟,如果这是一个对响应要求非常高的业务,那么针对这一信息,审计人员可以就此预测该业务流程运行中可能存在的风险,并在制定审计方案中重点关注。
而对Disco而言,图12已经很清晰的反映出瓶颈点,图中每个节点、路径均标出了平均执行时间。如B registerclaim平均耗时达8.5分钟,assessclaim(索赔评估)达到了平均10.9分钟(与Prom分析的结果正好相互验证),而路径上的瓶颈处在于B中心和S中心提出索赔后到determinelikelihood of claim(确定索赔可能性)耗费时间相当长,分别达到了平均一次需要3小时和3.2小时,极大的拖后了整个流程的执行时间,成为整个索赔流程的主要滞后点,也即瓶颈点所在,如果能够针对这种情况再进一步深入进去调研出现该子流程滞留的原因分析,是什么因素导致该子流程执行时间如此慢,是因为人手不够还是重视程度不够,还是环节上设计本身不太合理,如工作量太多,资源配置结构不相匹配等,从而积极改进,如有没有别的方法来加快该进程,或者如何有效的将整个索赔可能性确认工作分给多个部门协作,加快进程等将可以很好的改善整个流程的总体质量。
五、结论
应用流程挖掘技术可从系统日志中提取被记录的业务活动,将这类信息按照固定格式进行收集和整理后,形成可以被分析利用的事件日志,再结合一定的模型进行表示与分析,避免了管理者对流程运行过程的主观理解乃至错误认识,将流程挖掘技术应用于内部审计中,不仅能够实现对现有内部控制流程中存在的漏洞与缺陷进行更全面地识别与定位,同时也可以减少因管理者对流程运行过程的主观理解而导致的审计失败,通过将基于模型审计与当前审计方法相结合,极大提高内部审计质量的同时,也能促进审计风险防范能力,将内部审计由事后查错向事前、事中转变,使内部审计能更好地发挥包括“免疫系统”在内的更多功能。
[1]王红霞,景波.多维数据聚类技术在电子政务审计分层抽样中的应用研究[J].商业会计.2014(01)
[2]王辉,杨光灿,韩冬梅.基于贝叶斯网络的内部威胁预测研究[J].计算机应用研究.2013(09)
[3]杨姗媛,朱建明.基于内部威胁的信息安全风险管理模型及防范措施[J].管理现代化.2013(02)
[4]刘国城.BS7799标准及其在中观信息系统审计中的运用[J].审计与经济研究.2012(03)
[5]王会金.中观信息系统审计风险控制体系研究——以COBIT框架与数据挖掘技术相结合为视角[J].审计与经济研究.2012(01)
付亮(1976-),女,湖北宜昌人,硕士,经济师。研究方向:经济管理。
