大数据环境下基于Hadoop框架的数据挖掘算法的研究与实现
2017-05-09洪波吕燕霞黄磊武汉市劳动和社会保障信息中心湖北武汉430022
洪波,吕燕霞,黄磊(武汉市劳动和社会保障信息中心 湖北 武汉 430022)
大数据环境下基于Hadoop框架的数据挖掘算法的研究与实现
洪波,吕燕霞,黄磊
(武汉市劳动和社会保障信息中心 湖北 武汉 430022)
为了提高大数据环境下的数据挖掘速度,对分布式计算构架Hadoop进行分析与研究,提出一种基于Hadoop平台的大数据关联规则挖掘算法MRPrePost。该算法在PrePost算法基础上改进而来,采用Hadoop平台降低分布式编程的难度且易于管理,通过一种自底向上的深度优化策略改进PrePost算法,降低内存开销,同时采用负载均衡的分组策略,来提高并行算法的性能,最终试验表明,该算法运行速度快,适应大数据关联规则挖掘。
大数据;Hadoop;关联规则;数据挖掘
随着智能设备的普及,全世界在2010年的信息量已达ZB级别,预计2020年将上升到35ZB,大数据时代已经来临,如何快速准确地挖掘出潜在的价值信息变得越来越重要。数据挖掘技术已经发展多年,但发展速度赶不上信息量的爆炸式增长,现有的算法在处理大数据时显得力不从心,如Apriori算法需多次检索原数据库,容易造成 I/O开销[2],FPGrowth算法在迭代挖掘频繁时,产生的子树结构太多,不利于大数据挖掘[2]。因此根据大数据环境的特点,研究相应的数据挖掘算法变得十分的迫切。本文基于Hadoop平台,对PrePost算法进行改进,提出一种基于Hadoop平台的大数据挖掘算法MRPrePost,该算法能够适应大数据关联规则挖掘,计算速度快,为大数据时代下的数据挖掘技术研究提供一种新思路。
1 相关技术简介
1.1 关联规则挖掘技术
关联规则挖掘以找出各事务相互间的联系为目的,在各行各业广泛应用,如在超市购物中的应用,根据交易记录找寻各类型物品之间的相关性,进而分析购物者的购买行为,并依据分析结果指导货架布局、货存安排和对客户分类。在进行数据挖掘之前,需要设定最小支持数和最小置信度,设定好参数之后,将挖掘出支持数大于或等于设定的最小支持数的项集,进而依据最小置信度得出有效的关联规则[3],关联规则挖掘主要在于挖掘全部的频繁项集。
设I={i1,i2,…,in},其中 in为项,事物数据库集Data={T1,T2,…,Tn},其中Tn为事物,使得T⊆I,则关联规则的逻辑蕴含形式为:A⇒B,A⊆I,B⊆I,且A∩B,A,B同为I的子集。
支持度为项集A、B的并集在事务集Data中出现的频率。置信度为在项集A发生的条件下B发生的频率。
1.2 Hadoop简介
Hadoop是Apache的一个开源项目[4],是可以提供开源、可靠、可扩展的分布式计算工具[7]。Hadoop主要包括HDFS和MapReduce两个组件,分别用于解决大数据的存储和计算。
1)HDFS
HDFS是独立的分布式文件系统,为MapReduce计算框架提供存储服务,具有较高的容错性和高可用性,基于块存储以流数据模式进行访问,数据节点之间相互备份[5-7]。默认存储块大小为64 M,用户也可以自定义大小。
HDFS是基于主从结构的分布式文件系统,结构上包括NameNode目录管理、DataNode的数据存储和Client的访问客户端3部分[8]。NameNode主要负责系统的命名空间、集群的配置管理以及存储块的复制;DataNode是分布式文件系统存储的基本单元;Client为与分布式文件系统的应用程序[9]。体系结构图如图1所示。

图1 HDFS体系构架图
2)MapReduce
MapReduce是一种分布式计算框架,适用于离线大数据计算[10]。采用函数式编程模式,利用Map和 Reduce函数来实现复杂的并行计算。原理如图2所示。
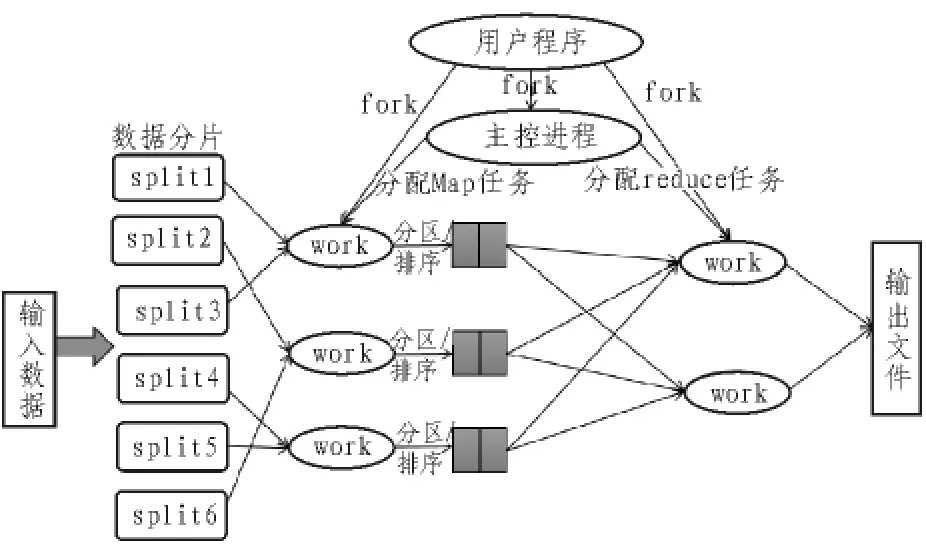
图2 分布式计算原理
2 基于 Hadoop平台的 MRPrePost挖掘算法
文中提出的MRPrePost算法是在改进的PrePost算法基础上发展而来,可通过并行化平台对数据进行关联规则挖掘,该算法算法主要分为3部分,流程如图3所示。
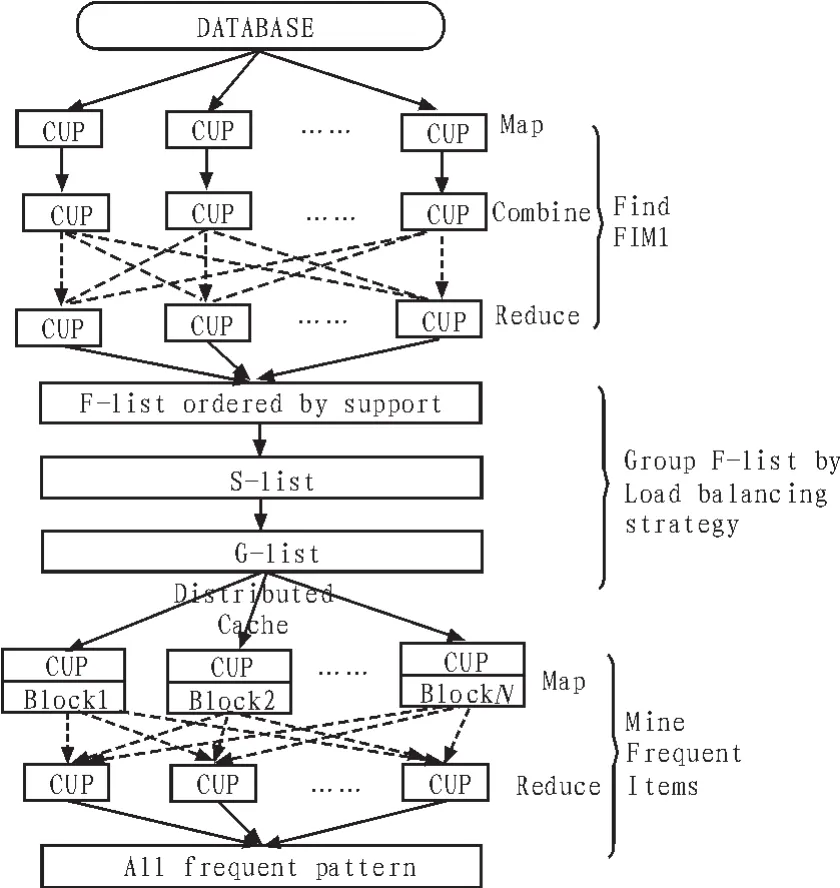
图3 基于Hadoop平台的MRPrePost算法流程图
2.1 统计频繁1项集
并行化计算首先将数据库进行水平分片处理[11-13],每一个子文件称为Block,每个Block被分配到集群的worker节点上,作为Map函数的输入值,并统计相应节点上Block文件出现的次数。具体过程为Map函数将Block文件分成pair<key=num,String>,之后对String按照项集进行分割,形成pair<key,value=1>,其中key为单个的项,Combine函数将具有相同key值的键值进行初步合并,将得到的新键值作为下一阶段Reduce的输入,最后合并来自各个节点的键值对,根据设定好的支持数阈值生成频率1项集FIM1,同时根据支持数降序排列生成全局F-list。统计过程如表1所示。

表1频繁1项集统计过程
假设最小支持数阈值为minsupp=2,则F-list序列
为(b:4;c:4;e:3;f:3;a:2)。
具体代码为:
Procedure:Mapper (Long Writable key,Text Writable values,Context context)
forearch values do
items[]<-split(values)
for i=0 to items.length-1 do
set<key,value>=<items[i],1>
context.write(key,value)
end
end
Procedure:combiner(TextWritable key,Iterator<LongWritable>values,Context context)
sum<-0
foreach LongWritable value in values do
sum+=value.get()
end
context.write(key,newLongWritable(sum))
Procedure:Reducer(TextWritable key,Iterator<LongWritable>values,Context context)
sum<-0
for i=0 tovalues.size()-1 do
sum+=values[i]
end
if sum>=minsupp do
context.write(key,newLongWritable(sum))
end
2.2 对F-list均匀分组
设置支持数阈值可以方便的调节F-list规模,当挖掘比价精准的关联规则时,需要得到尽可能多的频繁1项集,但过多的项集导致无法在内存中建立PPC-Tree树,使得后续挖掘工作无法进行,为了避免这种情况的发生,可将PPC-Tree树分割成多个独立的子树,降低了PPC-tree树的深度和占用的内存空间[14]。
对F-list分组涉及到系统的负载均衡问题,处理不好严重影响系统性能。本文采用将F-list中所有的项集均匀分散到N组中,记为G-list,其中组员记为(gid),设N=2,最小支持数minsupp=2,则分组情况如表2所示。

表2 监控的指标
2.3 并行挖掘频繁模式
对F-list分组是为了将事务重新划分,保证划分后能够建立独立的PPC-tree树,本次采用将事务记录集的各条记录中的非频繁项去除,频繁项按照支持数降序组成一条路径path,沿着path这条路径遍历所有的项集,如果path[k]对应的组号为gid,则将gid与path[k]左边的所有项组成键值对然后发送到Reduce函数,传输之前必须进行序列化,因此需要对path[1,2...,k]进行Java序列化处理,建立序列化对象PathArray。预处理之后,各节点启动新任务,Map阶段根据G-list将事务记录的路径分配到不同的Reduce节点中,具体过程如下举例说明。表3为G-list的hash的映射过程。

表3 监控数据指标
在Map阶段:
1)读取缓存中的F-list和G-list,将G-list项集中的各个数据项用序号代替。
2)建立hash表HTable,以G-list中项作为key组号gid作为值value。
3)依次读取频繁项item,利用步骤二的组号gid,并以gid作为键key,将排在item左边的全部频繁项作为值 value构成键对值<key=gid;value= items>,作为Map阶段的输出值,为了避免重复,删除HTable中的value=gid的所有键值对,如果hash过程找不到对应的组号,则继续前一个项进行相同操作,直到一条记录处理完毕。
4)重复3)直到所有记录完成分配。
例如将最后一条事务记录经预处理之后变为(1,2,3,4),当读取4时,组号为gid=1,于是输出键值对<key,value>=<1:(1,2,3,4)。同时删除value=1的所有键值对,继续读取3,组号为gid=2,输出键值对<key.value>=<2:(1,2,3)>,同时删除value=2的所有键值对。继续读取2、1,在HTable中不能找到对应的组号,无需输出任何数据。记录如表4所示。

表4记录
2.4 算法性能测试
选取美国10年间发生的交通事故数据集accidents.dat,来测试MRPrePost算法的性能[15],将数据集在集群模式上对MRApriori算法、PFP-Growth算法及MRPrePost算法进行对比试验。硬件上选用配置相同的台式机,CPU主频为2.11GHz,内存为2G,硬盘为256 G。操作系统均为Ubuntu10.0。经过运算,3种算法的速度对比如图4所示。

图4 3种算法速度对比
从图4中可看出3种算法随着支持数的增加,运算得时间都减少,同时可看出MRPrePost算法的速度最快,效果最好。
3 结 论
文中针对现有大数据挖掘算法规则繁琐、计算速度慢等问题,提出了一种基于Hadoop平台的使用并行关联技术的大数据挖掘算法MRPrePost,将“并行化”处理数据的方法融入PrePost挖掘算法中,缩短计算时间。与MRApriori算法、PFP-Growth算法的性能测试结果表明:改进后的算法能够适应大数据关联规则挖掘,缩短了挖掘算法的计算时间,具有一定的现实意义。
[1]王海涛,陈树宁.常用数据挖掘算法研究[J].电子设计工程,2011(11):90-93.
[2]胡志刚,梁晓扬.基于Hadoop的海量网格数据建模[J].计算机系统应用,2010(10):22-24.
[3]吴泽伦.基于Hadoop的数据挖掘算法并行化研究与实现[D].北京:北京邮电大学,2014.
[4]金连,王宏志,黄沈滨,等.基于Map-Reduce的大数据缺失值填充算法 [J].计算机研究与发展,2013(S1):29-33.
[5]胡善杰.在云环境下的数据挖掘算法的并行化研究[D].成都:电子科技大学,2013.
[6]钱爱玲,瞿彬彬,卢炎生,等.多时间序列关联规则分析的论坛舆情趋势预测[J].南京航空航天大学学报,2012(6):32-35.
[7]吕奕清,林锦贤.基于MPI的并行PSO混合K均值聚类算法[J].计算机应用,2011(2):26-29.
[8]白云龙.基于Hadoop的数据挖掘算法研究与实现[D].北京:北京邮电大学,2011.
[9]刘军.Hadoop大数据处理[M].北京:人民邮电出版社,2013.
[10]胡金安.云数据中心计算资源监控系统的设计与实现[D].成都:电子科技大学,2012.
[11]孙寅林.基于分布式计算平台的海量日志分析系统的设计与实现[D].西安:西安电子科技大学,2012.
[12]胡光民,周亮,柯立新.基于Hadoop的网络日志分析系统研究[J].电脑知识与技术,2010(22):13-16.
[13]杨旻.Hadoop云计算平台在高校实验室教学环境中的实现[J].电脑知识与技术,2011(9):34-38.
[14]黄立勤,柳燕煌.基于MapReduce并行的Apriori算法改进研究[J].福州大学学报:自然科学版,2011 (5):36-39.
[15]耿生玲,李永明,刘震.关联规则挖掘的软集包含度方法[J].电子学报,2013(4):38-41.
Research and design of distributed cloud monitoring platform system based on Hadoop
HONG Bo,LV Yan-xia,HUANG Lei
(Wuhan City Labor and Social Security Information Center,Wuhan 430022,China)
In order to increase the speed of data mining for large data environment,analyze and study on distributed computing architecture Hadoop,put forward a kind of large data association rule mining algorithm based on Hadoop platform MRPrePost.In PrePost algorithm based on improved the algorithm,and reduce the difficulty of the distributed programming with Hadoop platform and easy to manage,through the depth of a bottom-up PrePost algorithm optimization strategy,reduce the memory overhead,at the same time using grouping strategy of load balancing,to improve the performance of parallel algorithm,the final test shows that the algorithm is fast,to adapt to the big data mining association rules.
big data;Hadoop;association rules;data mining
TN918
A
1674-6236(2017)07-0041-04
2016-04-09稿件编号:201604090
洪 波(1976—),男,安徽泾县人,中级职称。研究方向:数据挖掘。
