XUD: 一种扩展的不可靠数据报传输服务
2017-05-04
江南计算技术研究所,江苏 无锡 214000
1 简介
1.1 IBA 中的传输服务
在 IBA[1]规范中,每个通信接口称为一个队列对 (Queue Pair,QP),由一个发送队列和一个接收队列组成。创建 QP 时须指定其传输服务类型,IBA 规范定义了 5 种服务类型:
(1) 可靠连接服务 (Reliable Connection,RC):该服务类型中,每个 QP 仅能跟其对应的另一个 QP通信;每个 QP 都维护了连接的完整信息以实现可靠数据传输。RC 服务支持各种长度、各种操作类型的消息,是 IB 中使用最广泛的一类传输服务。
(2) 不可靠数据报服务 (Unreliable Datagram,UD):该服务类型中,一个 QP 可以同任意 QP 进行通信,具有良好的可扩展性;QP 不维护连接信息,数据传输没有可靠性保证。由于可扩展性好,该服务类型在不要求可靠传输的应用中被广泛使用。
(3) 可靠数据报服务 (Reliable Datagram,RD):该服务类型与 UD 服务类似,一个 QP 可以跟任意QP 进行通信;与 UD 服务不同的是,该服务通过名为“端到端上下文 (End-to-end Contexts, EEC)”的对象维护了连接信息,可以实现端到端的可靠传输。如图 1 所示,一个 EEC 可以被多个 QP 使用,但每个 EEC 仅允许一个飞行消息,即不允许并发传输多个消息,这会对消息性能造成严重影响。
(4) 不可靠连接服务 (Unreliable Connection,UC)。该服务类型同 RC 服务类型类似,每个 QP 仅能跟其对应的另一个 QP 通信,但该服务不保证消息传递的可靠性。该服务类型很少被使用。
(5) 扩展的可靠连接服务 (Extended Reliable Connection service,XRC)。该服务类型是 RC 服务的变体,用于在虚拟化环境下减少 QP 的个数。如图 2 所示,若处理器 1 上的进程 1 要向处理器 2 上的 3 个进程发送数据,则首先在处理器 1 上创建一个 XRC Send QP 用于发送,并在处理器 2 上创建一个 XRC Recv QP 用于接收。另外,每个进程都创建一个 XRC SRQ,用于从多个进程接收数据。XRC Recv QP 被 3 个进程共享,收到消息后,根据包头中的 XRC SRQ 号将消息分发给不同的 XRC SRQ。XRC Send QP 与 XRC Recv QP 是一一对应的,类似于 RC型 QP,维护了连接信息,可以实现可靠传输。
1.2 现有服务存在的问题

图1 可靠数据报服务Fig. 1 Reliable datagram service
在高性能计算中,随着多核、众核技术的飞速发展,超级计算机中的处理器数和每个处理器中运行的进程数越来越多,在所有进程间建立全连接的开销也越来越大[2]。假设有 N 个处理器,每个处理器上有 P 个进程,则在所有进程间建立全连接时,各种服务类型需要的 QP 数如表 1 所示。
可以看到,利用 RC、UC、XRC 等可靠服务为大规模并行课题建立全连接,会消耗大量的 QP,消耗大量内存。我们在 x86 服务器上分别测试了创建不同类型的 QP 时的内存消耗情况,结果如表 2 所示。实验中,x86 服务器安装一块 Mellanox ConnectX-4 HCA 卡,速率为 4x25Gbps;每个 QP的发送队列和接收队列深度均为 32,支持的 SGE 数为 1。可以看出,各种服务类型的 QP 消耗的内存基本相等,平均每个 QP 消耗约 22KB 内存;在 QP 数为 13 万时,内存消耗量已经超过了 3GB。随着队列深度、SGE 数的增大,内存用量还会增加。文献 [2]指出在 MVAPICH 0.9.8 中,每个 QP 约消耗 68KB内存。由此可见利用这些服务在数十万个进程间建立全连接是不可行的。
RD、UD 等数据报服务每个处理器上需要的 QP数是 P,内存消耗比 RC、XRC、RD 等其他服务类型小的多,具有良好的可扩展性,是实现大规模并行课题全连接的优先选择。目前很多 MPI 实现采用了纯 UD 服务[2-4]或混合服务的模式[5-7]。但 RD 服务不允许并发传输多个消息,性能较差。而 UD 提供的是不可靠的传输服务,需要应用程序在软件层实现可靠传输,以处理丢包、重复包、乱序包等问题,这大大增加了上层软件的复杂度。
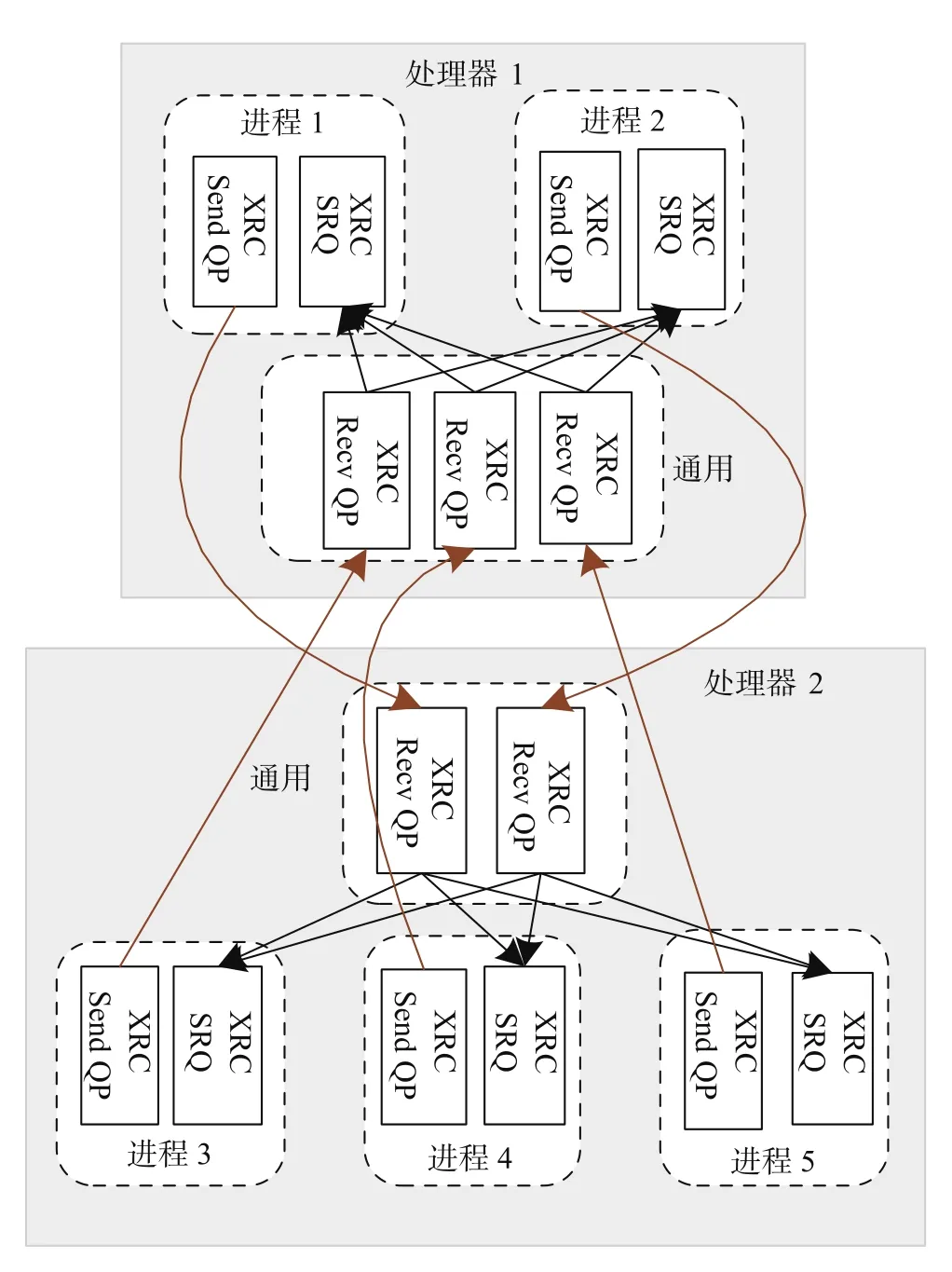
图2 扩展的可靠连接服务Fig. 2 Extended reliable connection service

表1 各种服务类型需要的 QP 数Table 1 Count of QP needed for each transport service

表2 创建不同数目的 QP 时消耗的内存情况Table 2 Memory usage for creating different count of QPs
为了克服 IB 现有传输服务类型在大规模并行时遇到的难题,本文提出了一种扩展的不可靠数据报传输服务 (eXtended Unreliable Datagram,XUD),由软硬件协同实现数据的可靠传输,在显著降低内存用量的同时,为上层用户提供高效、可靠的数据传输服务。
2 扩展的不可靠数据报传输服务 XUD
同 UD 一样,XUD QP 可以向其他任意 XUD QP 发送数据,也可以从其他任意一个 XUD QP 接收数据。与 UD 服务相比,XUD 在硬件实现上为可靠数据传输提供了一定的支持:
(1) 接收方对每个收到的数据包进行应答,但不需要检测和处理丢包、重复包、乱序包等错误;
(2) 发送方在规定时间内收到应答后,产生状态为成功的完成;
(3) 发送方在规定时间内未收到应答,则产生状态为超时的完成;
这意味着,如果发送方完成状态为超时,则存在两种可能,一是接收方没有收到数据,二是接收方收到了数据但应答丢失。
表3 对 XUD 和 UD 进行了对比。

表3 XUD 和 UD 比较Table 3 Comparison of XUD and UD
2.1 XUD 数据包格式
用户向 XUD QP 投递发送请求时,需指定接收方 LID、QP 号等地址信息。发送请求被调度执行后,会根据操作类型产生对应的数据包。XUD 使用的数据包如图 3 所示。
其中 IBA 基本传输头 BTH、应答包扩展传输头AETH 是 IBA 规范定义的标准数据包头;XUDETH是 XUD 的扩展包头,长度为 16 字节,其格式如图4 所示;win_id、win_msn 字段由软件层使用,其作用在 2.1 节介绍。
对 XUD 的每个发送请求,其基本传输头 BTH内各字段的填充方式同 UD 类似。其中数据包序列号 PSN 填充为:(cur_psn+1) mod(2^24);cur_psn 的初始值由用户在创建 QP 时指定;每发送一个消息,cur_psn 加 1,以保证了每个飞行消息有一个唯一的PSN。
2.2 接收端应答机制
接收端收到数据后,首先对数据长度、操作码、CRC 码进行校验。如果校验失败,则以正确的NAK 码填充应答。如果校验成功,则从 QP 的接收队列中取接收请求,进行数据拷贝,并为接收请求产生一个完成条目 CQE,同时将数据包的 XUD 扩展传输头拷贝进 CQE 供 Verbs 消息库软件进行消息排重。不论校验是否成功,都会返回应答包,其MSN 字段填写为收到的数据包的序列号 PSN。

图3 XUD 使用的数据包Fig. 3 Packet structure used by XUD

图4 XUD 扩展传输头格式Fig. 4 The XUD extended transport header
2.3 发送端完成产生机制
应用程序通过查询完成队列判断发送请求是否正确完成。在下列情况下,XUD 会产生一个完成:
(1) 在解析发送请求、组织数据包的过程中发生本地错误,则会直接产生状态为错误的完成;
(2) 硬件收到应答包后,根据应答包扩展传输头的 MSN 字段,匹配飞行消息的 PSN,为匹配成功的请求产生完成;
(3) 在规定的时间内没有收到应答包,则产生状态为超时的完成。
3 利用 XUD 在 Verbs 库中实现可靠传输
在发送端,用户通过查询完成队列获知发送请求的执行情况。在正常情况下状态一般为成功,表明数据被接收端正确地接收。如果状态为超时,则无法判断接收端是否收到了数据,此时存在两种可能:(1) 数据包丢失,接收方未收到数据;(2) 接收方已正确收到数据,但应答包丢失。为了在 XUD上实现完整的可靠传输服务,需要在 IB Verbs 接口层进行重传及排重工作。重传是指发送方查询到消息超时后,重新投递一个跟超时消息一样的发送请求。如果消息超时是由 ACK 丢失引起的,则重传会导致接收方收到重复的消息,接收方要将重复的消息丢弃。
3.1 轻量级滑动窗口
我们在软件层为每个连接都建立多个发送/接收窗口,每个窗口中每条消息都分配一个唯一、递增的序列号,通过 XUD 扩展传输头传递给接收方,由接收方根据序列号判断收到的是新的数据包还是重复的数据包。每个窗口仅允许一个飞行消息,即使用该窗口的消息收到状态为成功的完成后才能释放该窗口。每对连接间可同时使用多个窗口来实现消息并发,最多支持 65536 个窗口。图 5 显示了处理器 1 上的 1 个进程同处理器 2 上的 2 个进程各建立一条连接时的窗口情况 (省略了进程 1 到进程 2、进程 3 接收相关的信息)。在发送端,每个窗口维护了下一个要用的序列号,每成功发送一个 XUD 消息,该序列号加 1;在接收端,每个窗口维护了期望的序列号,每收到一个正常的数据包,该序列号加 1。该滑动窗口同 RC 使用的滑动窗口相比,通信双方无需进行握手和信用反馈,无需对乱序数据包进行缓存,维护并发窗口的内存开销和 CPU 开销都非常小。

图5 软件层实现可靠传输使用的窗口结构Fig. 5 Window information used by verbs library to implements reliable transport
3.2 消息重传及排重
投递发送请求时,Verbs 库首先从该连接的发送端数据结构中找到一个空闲窗口,然后将窗口 ID、窗口 next_msn 分别填入 XUD 扩展传输头的 win_id、win_msn 字段。
接收方收到数据后,硬件会将 XUD 扩展传输头拷贝到接收请求对应的完成中,Verbs 软件根据该扩展头内携带的信息判断消息是否是重复消息。判断过程为:
(1) 根据收到数据包中的 win_id 找到接收窗口;
(2) 比较数据包的 win_msn 与接收窗口的expected_msn 是否相等;若相等,则该消息是新的数据包,首先将接收窗口的 expected_msn 加 1,然后将消息提交给用户;
(3) 如果数据包的 win_msn 与接收窗口的expected_msn 不相等,则认为该消息是重复消息,直接丢弃。
在发送端,当查询到发送请求状态为成功后,将发送窗口的 next_msn 加 1,并释放发送窗口。如果查询到状态为超时,则利用原来的发送窗口及win_msn 填充 XUD 扩展传输头,并重新投递一次发送请求,从而完成消息重传。
4 性能评估
4.1 实验环境
我们在 FPGA 环境下开发了支持 XUD 的 HCA硬件,并在 IB Verbs 库中实现了 XUD 消息的可靠传输。为了提高查找连接信息的速度,我们将 QP的连接信息组织成如图 6 所示的 Hash 表结构。端到端连接信息所需的内存空间是动态按需分配的。受限于 FPGA,我们仅建立了两台 x86 对连的测试环境,每台 x86 安装一块 HCA 卡,网卡速率为4x25Gbps。

图6 端到端连接连接信息的组织方式Fig. 6 The organization of end context information
4.2 内存开销
XUD 的内存用量由队列缓冲区、发送窗口表、接收窗口表等部分组成。由于只有两块 HCA卡,为了测试大规模互连时 XUD 的内存用量,我们采用了如下测试步骤 (连接数为 n):
(1) 在第一块 HCA 上创建一个 XUD QP;
(2) 在第二块 HCA 上创建 n 个 XUD QP;
(3) 在第一块网卡上分别向第二块网卡的每个QP 各投递 1 个请求,这样可以为第一块网卡的 QP建立起 n 个连接所需的发送窗口表;
(4) 在第二块网卡上每个 QP 都向第一块网卡的QP 发送 1 条消息,这样可以为第一块网卡的 QP 建立起 n 个连接所需的接收窗口表;
(5) 测量第一块网卡消耗的内存。
测试中,每条连接的并发窗口数为 32。测试结果如表 4 所示。可以看出,XUD 创建一条连接的内存消耗量平均约为 2.8KB,仅为 RC 等服务的12%,在内存消耗方面具有巨大的优势。
4.3 消息性能
XUD 提供的可靠传输能力相比 RC 要弱,硬件实现的复杂度和性能开销都较 RC 低,但需要额外的软件开销 (包括获取发送窗口、填充 XUD 扩展传输头、根据 XUD 扩展头进行排重等)。我们利用OFED[8]提供的标准测试程序,分别测出了开启和关闭可靠传输时 XUD 的最小消息延迟及最大网络带宽。测试环境如下:x86 服务器频率为 2.4GHZ,HCA 卡时钟频率为 781.25MHZ;测试中通过读取HCA 卡时钟节拍来计时,并根据 HCA 卡时钟频率换算出消息延迟及带宽。结果如表 5 所示。可以看到,在软件层实现可靠传输时,最小消息延迟约增加0.03usec,带宽约下降 70MB/s,在可接受的范围内。

表4 创建不同数目的连接时 UD 的内存使用量Table 4 Memory usage for XUD when creating different count of connections

表5 XUD 的性能Table 5 Performance of XUD
5 结束语
IB 中 RC、XRC 等服务在建立大规模全连接时会消耗大量的内存,而 UD 服务则没有提供可靠传输能力。XUD 是 RC 与 UD 的一种折中,由硬件提供一定的可靠传输能力,由 Verbs 接口软件通过消息重传与排重实现完整的可靠传输。同 RC 相比,在大规模互连时 XUD 的内存仅为 RC 的 12%。同UD 相比,软件层采用了轻量级滑动窗口,大大降低了软件复杂度,实现可靠传输导致的消息延迟仅增加约 0.05usec,带宽约下降 70MB/s。相比 IB 中原有的传输服务,在实现大规模互连时具有明显的优势。XUD 也存在一些局限性:(1) 不支持消息保序;(2) 最大仅支持一个 MTU 长度的数据包;(3) 仅支持 Send/recv 操作。后续研究中我们将探讨这些问题的解决方案。
[1]InfiniBand Trade Association. InfiniBand Architecture Speci fi cation Volume 1, Release 1.3 [S/OL]. (2015-03-03)[2017-09-01]. https://cw.in fi nibandta.org/.
[2]Matthew J, Sayantan S, Qi G, et al. High performance MPI design using unreliable datagram for ultra-scale In fi niBand clusters [C]// Proceedings of the 21st annual international conference on Supercomputing. New York: ACM,2007:180-189.
[3]Koop M, Sur S and Panda D K. Zero-Copy Protocol for MPI using InfiniBand Unreliable Datagram [C]// Proceedings of the 2007 IEEE International Conference on Cluster.Washington, DC: IEEE Computer Society, 2007: 179-186.
[4]Amith R M, Sundeep N, Abhinav V, et al. On using connection-oriented vs. connection-less transport for performance and scalability of collective and one-sided operations: trade-offs and impact [C]// Proceedings of the 12th ACM SIGPLAN symposium on Principles and practice of parallel programming. New York: ACM,2007:46-54.
[5]Masamichi T, Norio Y, Balazs G, et al. Adaptive transport service selection for MPI with In fi niBand network [C]//Proc of the 3rd Workshop on Exascale MPI. New York:ACM, 2015.
[6]Jithin J, Hari S, Krishna K, et al. Scalable Memcached Design for InfiniBand Clusters Using Hybrid Transports[C]// Proceedings of the 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing.Washington, DC: IEEE Computer Society, 2012: 236-243.
[7]Koop M, Jones T, and Panda D K. MVAPICH-Aptus:Scalable High-Performance Multi-Transport MPI over InfiniBand [C]// Proceedings of the 2008 IEEE International Symposium on Parallel & Distributed Processing. Washington, DC: IEEE Computer Society,2007: 1-12.
[8]The OpenFabrics Alliance web site. OpenFabrics software[EB/OL]. [2017-09-01]. https://www.openfabrics.org/.
