日志综合管理平台基于Storm框架的实现
2017-05-02李团结从新法李光明
李团结+从新法+李光明
【摘要】 日志对于每个系统来说都是不可或缺的一部分,而现阶段对日志的处理效率却不尽如人意。实时性日志考验的是大数据处理框架的实时计算能力,基于Storm 并借助开源框架 Kafka,设计了一个实时数据收集与处理的系统,将数据转为流的形式,对收集来的数据直接在内存以流的形式进行计算,输出有价值的信息保存到Redis。最后对系统进行性能测试以及计算能力的测试。实验结果表明,该系统可扩展性良好,且并行计算能力稳定,适合大量实时数据处理。
【关键字】 Storm Kafka Redis
一、引言
大数据时代,与互联网行业息息相关的诸多领域中用户数量和其产生的数据在不断地累加,为之提供支撑的服务器端存放的日志信息量也随之剧增,如何准确及时的筛选海量日志中的关键信息成为了亟待解决的问题。众所周知,Hadoop架构可以使用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储,但是对于实时性极强的流式数据,显然流处理框架Strom更适合,并且处理效率客观。
二、Storm计算框架
Storm是由BackType开发并被Twitter于2011 年开源的分布式实时计算系统[1],能够很容易可靠地处理无界持续的流数据,进行实时计算 [2]。
任务拓扑是Storm的逻辑单元,一个实时的应用打包为拓扑后发送,拓扑是由Spout和Bolt组成,其二者的关系如图1所示。Spout节点从数据源中源源不断的消费数据并把数据发送到后面的Bolt节点,而Topology是将Spout和Bolt组合在一起完成一项具体的计算任务。Topology一旦提交就会一直执行。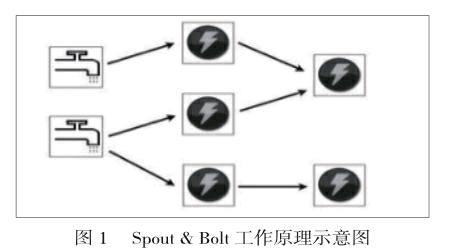
Storm主从架构图包含一个主节点Nimbus和多个从节点Supervisor,Zookeeper完成两者之间的协调。每个 Worker都执行且只执行任务拓扑中的一个子集, 在每个Worker 内部,会有多个 Executor,每个 Executor对应一个任务,负责具体数据的计算,即用户所实现的 Spout /Bolt 实例。
三、日志综合管理平台基于Storm的实现方案
3.1开发环境及采用的测试数据集
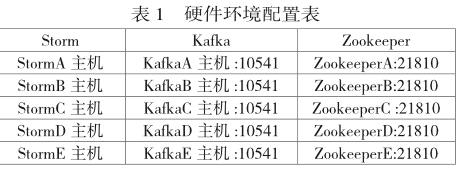
硬件环境包括Storm集群,Kakfa集群,Zookeeper集群,Storm包括1个Nimbus和4个Supervisor;Kafka集群包括5个节点;Zookeeper集群也包括5个节点,集体配置如表1所示。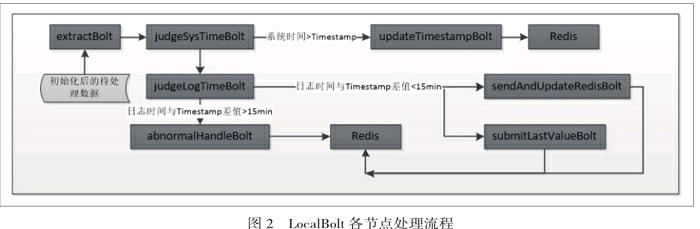
软件环境:jdk-1.7.0_79、logstash-2.3.4、elasticsearch-2.3.4、storm-0.9.5、kafka_2.9.1-0.8.2.0
zookeeper-3.3.5、python-2.7.12。
操作系统:Linux version 3.10.0-327.el7.x86_64
数据集:用户话单日志信息(约2 billon/day)。
3.2平台架构及处理流程
日志综合处理平台主要由三层组成,包括:数据采集层、数据分析及存储层以及数据展示层。可以实现对日志从采集到分析处理的全过程并在页面监控平台显示。
本实验方案使用 Kafka为消息中间件传递消息。Kafka是一种高吞吐量的分布式发布订阅消息系统,其依赖Zookeeper保存每组消费者消费的相应Topic的偏移量。
SpoutA接收待初始化的数据,并将其发K-means&DBSCANBolt 通过数据簇形态识别以初始化微簇;SpoutB从Kafka中接收初始化后待处理的流数据,将其发送至LocalBolt进行局部微聚类;SpoutC用作处理时间戳,每单位时间向LocalBolt发送一次信息,当接收到时间戳消息,将局部微聚类更新结果存放到Redis做实时局部微聚类更新结果的保存,并合并原有的增量信息发送到GlobalBolt;SpoutD通过消息中间件 Kafka接收用户发送的查询参数。
K-means&DBSCANBolt接收 SpoutA传输的待初始化数据与聚类参数 k(簇数),进行标准 k-means聚类或者DBSCAN聚类,聚类的结果以微簇形式发送至 LocalBolt随后根据时间戳信息保存结果到Redis,并由滑动窗口触发机制合并局部微簇到全局微簇GlobalBolt。RL-DSCA算法的微簇在线维护微簇进行的在线增量更新是由LocalBolt来实现的,体现了RL-DSCA算法分布式数据的处理,到达的待处理流数据将会分配到各个LocalBolt节点,这些节点具体的功能均不相同,LocalBolt各节点处理流程如图2所示。主要處理Bolt的实现功能如下。
extractBolt:该Bolt主要实现从初始化后的数据流中筛选目标信息,并将筛选出来的数据发送到下一个处理bolt。
judgeSysTimeBolt:该Bolt用来判断系统时间和时间戳的关系检测拓扑停止工作的异常情况,如出现拓扑异常,系统时间>时间戳时间,对时间戳补齐并进行更新(updateTimestampBolt)结果存放到Redis。
judgeLogTimeBolt:改Bolt主要是判断来的日志是实时日志还是历史日志,如果日志时间在时间戳范围内即为实时日志,否则按照历史日志来处理。
sendAndUpdateRedisBolt:实时日志的发送,根据SpoutC传来的时间戳消息,将局部微聚类更新结果存放到Redis。
submitLastValueBolt:该Bolt用于处理历史日志的最后一个时间戳,根据来的一条正常日志触发将历史日志的微簇发送到Redis。
abnormalHandleBolt:该Bolt主要对历史日志进行处理,避免影响实时流数据的处理,并将历史日志的处理结果合并到Redis供全局微簇的合并。
现将该平台的主要功能概述如下:
接收 K-means&DBSCANBolt生成的初始化微簇生成初始缓存集Kafka;对于到达拓扑的待处理的数据流,LocalBolt按照单位时间生成局部聚类增量,并将该中间结果发送至Redis供合并;Redis实现RL-DSCA算法的合并部分,即合并局部增量结果进行全局微簇增量更新:接收LocalBolt生成的初始化微簇生成初始全局微簇;缓存各局部线程传输的中间结果;使用滑动窗口触发机制,达到触发时间点则合并暂存的中间结果,将结果打上相应时间标记Tag,生成实时全局微簇快照发送至GlobalBolt。GlobalBolt实现RL-DSCA算法的查询输出;接收GlobalBolt生成的全局微簇快照,将其存储至金字塔时间帧结构中供后续查询;当用户输入查询参数时,通过SpoutD接收查询参数,查找金字塔时间帧结构中的相应数据,将查询结果发送至SendBolt 进行输出。
四、结束语
本文设计开发了流数据计算平台 Storm 的计算架构处理海量数据日志综合管理平台,结合Kafka和Redis对日志进行了实时性的分析和处理。满足了用户对大数据量日志信息的使用需要,并达到了客观的处理效率。
参 考 文 献
[1] The Apaehe Foundation. Storm official website- [EB/OL].https://storm.apache.org/.
[2] Github Inc. Storm Wiki[EB/OL]. https://github.com/apache/storm.
