不平衡数据分类研究综述
2017-04-25陈湘涛高亚静
陈湘涛,高亚静
(湖南大学 信息科学与工程学院,湖南 长沙,410082)
不平衡数据分类研究综述
陈湘涛,高亚静
(湖南大学 信息科学与工程学院,湖南 长沙,410082)
不平衡分类问题始于二分类任务中的数据偏态问题,当传统机器学习分类方法应用于不平衡数据集时,分类效果往往不尽人意。因此,许多用于处理不平衡数据集的分类器模型已经被提出,包括数据层面的方法、算法层面的方法、混合方法以及集成分类器模型。本文主要通过讨论不平衡分类问题的实质,对不平衡分类问题的研究进行综述,介绍几种主要的解决策略,针对不平衡数据特点讨论适应不平衡特点的性能指标,并针对已有研究分析所存在的问题及挑战。
机器学习;不平衡分类;数据层面;算法层面;集成学习
不平衡分类问题始于二分类任务中数据存在偏态的问题[1],即在二分类任务中,其中一类的样本数目远远大于另一类的样本数目,即类与类之间的样本不平衡。传统的机器学习分类算法假设类的样本数量大致相同,然而,在很多的现实情况中,类的样本分布是呈现偏态的。当传统的分类方法应用于不平衡数据集时,为了提高分类的整体精度,分类器会减少对少数类的关注,而偏向于多数类,从而分类边界将偏向于拥有样本数较少的类别导致多数类分类空间增大,少数类样本难以被识别出来,分类性能受到严重影响。为此,需要设计出智能化的方法克服分类器对多数类的偏向问题。
同时,少数类在数据挖掘时又很重要,尤其是当少数类携带很多重要及有用的信息时。例如,在欺诈检测工作中,更加注重检测欺诈的交易[2];在通讯工程中对失败设备的识别更感兴趣[3];在工业工程中更倾向于识别焊接失败的情况[4];在客户流失检测中,流失客户的数量相对较少,属于少数类,在实际应用中,正确检测流失客户并采取阻止方案是很重要的,因此,实际应用中更希望正确检测出少数类;在汽车保险欺诈检测的研究中,欺诈客户只占总样本数的很少部分,但对这种不平衡的数据分类时,传统方法往往将欺诈客户误分类为正常客户,虽然整体的准确率很高,但是误分类欺诈客户将会给保险公司造成巨大的损失。因此,现实应用中少数类具有特殊的意义,如果分类错误会带来很大的损失,因此不平衡分类的研究具有非常重要的实际研究价值。
不平衡分类问题的研究在数据挖掘领域引起了很多人的兴趣,很多方法相继被提出,如文献[5]提出了不平衡分类的研究,García等人[6]针对不平衡数据集提出了各种数据处理方法,包括不平衡数据预处理方法、采样方法以及不平衡数据的清理。文献[7]致力于研究不平衡预测模型的建立,文献[8]则研究了利用集成学习来解决不平衡分类问题;López 等人[9]则提出从不平衡数据特征这个新的视角研究不平衡数据,并讨论针对偏态数据集分类器的评价标准。在过去的几年里,不平衡分类在实际的应用领域也取得了很多的成就,如电子邮件过滤[10]、欺诈检测[11]、卫星图像溢油的检测[12]、医疗诊断[13]、车辆诊断[14]等。
根据以上的研究背景,本文主要对不平衡分类问题进行研究综述,讨论不平衡分类问题的研究现状,并分析在现实背景下我们所面临的主要问题,试图为数据挖掘等相关领域的研究提供有益参考。
1 影响稀有类数据分类的因素
对不平衡数据集分类,影响其分类的因素来源于其自身特点。研究表明,除类分布不平衡外,还包括数据的可分离性、子概念问题等,这些数据集内部的特点通常严重影响少数类数据的分类。
影响少数类分类的最主要因素是类分布不平衡。在二分类中,两类的样本分布不平衡,其中一类的样本数目大于另一类样本数目。此时,少数类样本的数目可能是极少的,因此,少数类样本信息不足以正确表达少数类,在分类过程中,少数类样本提供给分类器的信息太少而使分类器无法正确识别。另外一种情况是少数类样本相对于多数类样本占有比例很小,当类分布不平衡时,其中少数类的样本数,使得分类器不能获得足够的信息,分类器偏向多数类,不利于少数类分类。文献[15]研究了不平衡的类分布对判定树分类性能的影响;研究表明,在部分应用中,类分布不平衡比例超过1∶35时就难以建立正确的分类器,更有甚者,当不平衡比例达到1∶10时有些应用就很难建立正确的分类器了[16]。
除了数据分布不平衡外,影响少数类分布的因素还有数据的可分离性。高度线性可分的数据集对不平衡是不敏感的,即使类分布不平衡,其分类性能也不会受到影响。然而,当数据集非线性可分时,不平衡数据分类时,其性能会受到明显影响,性能降低。
另外,类内子概念问题也会影响到分类性能。子概念问题反映的是类内不平衡[17],即同一类样本的分布不平衡。前面提到的样本不平衡是指类与类之间的不平衡,子概念问题使得数据集内部进一步变得复杂,从而导致其分类性能下降。
2 不平衡分类问题解决策略
不平衡分类问题是不平衡问题的重要分支,因此,得到了学者们的广泛研究,产生了许多优秀的方法。总结来说,不平衡分类的主要包括数据层面、算法层面、集成学习的策略。数据层面的主要思想是改变原始数据集的分布,增加少数类样本或减少多数类样本,使不平衡数据集趋于平衡。算法层面通过直接修改已有的分类器,使之适应不平衡数据特征。集成方法使用集成的思想提高分类器的性能。
2.1 数据层面
通过近些年的研究,数据层面的采样思想在改进数据集方面展现了极大地潜力[18]。数据层面的分类方法旨在改变数据分布,对数据集进行重采样,以降低类与类之间样本不平衡程度,使修改后的数据可以应用标准的学习算法。因此根据不平衡数据集的重采样方法的不同,分为过采样方法和欠采样以及混合采样方法。
2.1.1 过采样方法
过采样方法的思想是增加少数类样本。最简单的过采样方法是随机过采样方法(ROS),但随即过采样方法生成的实体和原数据集的实体相似性大,因此会产生过拟合问题。为解决过拟合问题,文献[19]提出样本生成技术SMOTE,该方法根据为每个稀有类随机选取n个邻近样本,在连线上随机选取点生成无重复的新的稀有类样本。实验证明,SMOTE方法优于ROS方法,SMOTE方法通过生成新的不同的少数类,避免了过拟合问题。然而,SMOTE方法盲目的生成虚构的少数类,在生成新样本的过程中并没有考虑多数类,因此可能会引起过生成问题,即生成的实体和原数据集中实体重叠[20]。为解决过生成问题,很多方法被提出。文献[21]提出Safe-level SMOTE方法,该方法提出为少数类样本计算“安全层”的思想,然后生成接近安全阶段的样本。文献[22]提出的Borderline-SMOTE方法,通过分析识别边界样本,对边界的少数类进行过采样,提高边界的识别率,但该方法只对靠近边界的少数类样本进行过采样。另外自适应合成抽样算法(adaptive synthetic sampling,ADASYN)[23],该方法主要以密度分布作为标准,自动生成少数类样本,为少数类样本赋予权重,并不断自适应改变,自适应为每个样本生成相应的少数类样本。然而,Borderline-SMOTE和ADASYN方法无法识别出边界所有的少数类样本[18]。基于以上问题,文献[24]中提出A-SUMO方法,使用半监督层次聚类对少数类聚类,利用分类复杂性和交叉验证的方法自适应决策定过采样子聚类群的大小,通过考虑每个子簇中边界的少数类实体来识别比较难以学习的样本,该思想通过考虑在聚类和过采样阶段中的多数类,避免生成重叠样本。
2.1.2 欠采样方法
欠采样方法通过舍弃部分多数类样本的方法平衡训练数据集。最简单的欠采样方法是文献[15]中提出的随机欠采样方法,该方法随机选择部分多数类样本作为训练数据集中的多数类样本。然而该方法有个很大的弊端则是随机选择多数类样本可能会去除一些重要的多数类样本,因此会产生决策边界的失真。在此基础上,很多先进的思想被先后提出,Mani和Zhang[25]提出四种不同的欠采样思想,NearMiss-1,NearMiss-2,NearMiss-3和MostDistant,该思想主要使用K近邻的方法。NearMiss欠采样方法根据与少数类相邻的多数类被选择来训练决策边界[26]。Cateni等人在[27]中提出基于相似性的欠采样方法(SBU),为了减少信息的丢失以及平衡数据集,SBU趋向于减少密度空间中的多数类实体,根据欧几里得距离计算每一对多数类的相异值,相异性值小的多数类被去除。然而现有的欠采样方法存在的问题是:性能不稳定。因此为了最大限度的提高分类器的性能,降低在欠采样过程中对多数类的损失,文献[28]提出基于遗传算法的欠抽样方法来解决不平衡分类问题。该文献提出GAUS(genetic algorithm based under sampling),使用遗传算法进行样本选择将分类性能作为遗传算法的适应函数,该方法在一定程度上解决了性能不稳定问题,并减少了数据分布丢失。另外,欠采样方法使用之后的数据集在训练过程中保持不变,这样会导致一些有用的多数类无法参与训练过程,会丢失有效信息[29-30],因此,提出一种ODUNPNN单方面的动态欠采样技术,它可以适用训练过程中所有的样本,并且动态决定哪个多数类样本应该被用来进行分类器的训练。该方法是单方面动态欠采样技术与无传播神经网络的结合,它考虑所有的训练样本,在每次迭代中动态欠采样多数类。以此动态过程减少采样过程中信息的丢失。文献[31]根据对多个不平衡数据集进行不同重采样方法的试验统计发现,SMOTE-ENN是效果较好次数较多的混合采样方法,ROS是效果较好次数较多的过采样方法,而RUS是效果较好次数较多的欠采样方法。但实验结果只是对多个不平衡数据集效果次数的统计,针对不同的不平衡数据集,其适应的重采样方法不同,试验统计结果对以后的实验分析具有指导作用。
2.2 算法层面
算法层面致力于修改已存在的分类器减少对少数类的偏向,该思想研究方向主要为修改分类器的视角,以及如何精确预测分类结果的成败。在构造合适分类器方面,文献[32]通过减小多数类样本在训练中所占比例训练合适的分类边界。
另外,很多研究根据传统分类算法的改进,减缓分类器对多数类的偏向。其中文献[51]文章通过基于关联规则的分类方法的研究发现,基于关联规则分类方法对不平衡数据集分类时,由于其根据置信度选择规则的策略,多数类中置信度高,而少数类置信度低,因此使用基于关联规则的分类方法对不平衡数据分类时,分类结果会会偏向对多数类。文章提出类置信度比例的概念,传统置信度检验有多少预测正、负样本是实际正负样本,类置信度专注于有多少实际正负样本是预测正确的。用类置信度代替置信度,提出类置信度比例决策树,通过考虑类之间的联系,提高决策树的鲁棒性和对类大小的敏感性。基于此思想,文献[52]提出了类置信度加权kNN算法,通过kNN算法类置信度加权,对多数类的偏向。对kNN算法的修改,文献[53]通过少数类新样本的生成减缓决策边界的错误,在对样本检测时,算法考虑了少数类中群组距离减缓对多数类的偏向。文献[54]通过离子群优化算法提高不平衡数据分类性能,另外对SVM的修改[55],该文献提出OCSVM算法,该算法被用于不平衡文本分类中取得较好的结果。另外基于模式不平衡分类的研究,文献[56]提出ICAEP分类器,它使用最小编码推理给新样本分类,这种方法被用在不平衡分类中[57],实验证明ICAEP可以使用模式构造适合不平衡数据集的分类模型。在文献[58]中,作者提出一种新的基于模式的不平衡算法PBC4cip,该方法结合不平衡水平下模式的支持度,对每个类支持度之和加权,减缓不平衡对分类器的影响。
基于算法层面的方法主要是代价敏感方法[33],其考虑的是样本误分类的代价,由于可以赋予不同类的分类错误不同的代价,对原本是少数类而被误分为多数类的样本赋予更高的误分代价。因此,基于代价敏感因子的提出,很多基于代价敏感的分类算法被提出。其中文献[34]将代价敏感思想与松弛变量结合对SVM进行改进,使SVM应用超平面分类时对代价敏感。另外,在多类问题中的代价敏感SVM[35],在此文献中,也考虑了采样偏置。文献[36]中的加权线性模型WFLD,该判别模型采用加权Fisher,通过对多数类和少数类的类内离散度计算,根据离散度矩阵分别对多数类和少数类加权,根据类内离散度矩阵对两类调节平衡。总结以上代价敏感方法,都是对全局进行代价学习,是全局性模型。另外,文献[37]提出的局部代价敏感算法,该方法在对新样本预测分类时,对样本的k个近邻以加权的方式进行训练,根据对局部样本的代价敏感学习,得到预测分类器。代价敏感方法依赖于代价敏感矩阵,然而存在最大的障碍则是很多数据集中并没有给出代价敏感矩阵[38]。
通过已有的研究发现,算法层面的思想并没有像数据层面研究的广泛,这是因为它比较依赖于特殊的分类器,当解决类不平衡问题时,该方法需要针对某个特殊的分类器[39]。另外文献[40]给出基于对比模式分类器解决不平衡问题,它根据对比模式支持度对数据集进行加权,以加权数据集训练分类器,该方法结合了模式分类的优点处理不平衡问题。
2.3 混合方法
该方法主要结合数据层面和算法层面并充分利用它们的优点,减少二者的缺点[41]。比较流行的方法是结合数据层面的解决方法和分类器集成,这种结合可以产生有效的学习方法[42]。另外也有很多研究致力于采样方法和代价敏感方法的结合[43]。同时,混合方法也聚集了数据层面和算法层面的缺点,如何使二者的结合达到最好的结果需更多的分析二者的联系。
2.4 分类器集成方法
在处理不平衡分类问题中,集成学习受到很多学者的青睐[44]。其中采样思想和集成学习方法的结合被广泛应用到处理不平衡分类问题中。Chawal等人[58]在SMOTE和Boosting的基础上提出的SMOTEBoost,Seiffert[59]等人提出的混合集成思想RUSBoost,该方法结合了随机采样和Boosting集成,实验证明,RUSBoost方法要优于SMOTEBoost方法,Liu[60]等人提出的EasyEnsemble方法,该方法结合了Bagging、随机欠采样以及AdaBoost[45]。另外。过采样与集成学习方法的结合[50],可以平衡样本,同时也可以提高整体分类性能。然而,重采样和集成思想的结合,在每次迭代中,都会存在重采样思想所出现的问题,如过拟合问题以及数据丢失问题。因而,为避免出现重采样所带来的问题,文献[62]提出一种新的集成学习方法解决不平衡问题,该方法对原始多数类样本采用一种分裂策略,在不改变原始数据分布的情况下,将原始不平衡问题转化为多个平衡的问题,该方法避免了重采样所遗留的问题。
重采样和集成的结合可能会带来很多问题,因而,很多基于代价敏感与集成学习的结合的研究方法被提出。文献[61]中提出的Metacost算法,该算法采用bagging决定训练数据集的最优类标签,然而,它仍然很难决定精确地误分类代价。另外,由于Adaboost是为了提高整体的精度,因而,会偏向多数类[46]。因此,基于此的改进方法,如AdaCost[47]、RareBoost[48],这些方法主要改变迭代过程中的权重更新策略,对错分的稀有类样本赋予更高的权值。文献[49]通过研究代价敏感决策树集成有效解决不平衡分类问题,在文献[8]中提出新的集成思想,它将bagging,boosting,混合方法用于集成学习,构造有效分类器。
3 分类器评价指标问题
传统的分类指标会使分类器偏向于多数类,为了使分类精度更高,一般会把样本分为多数类,但不能正确识别少数类。因此,应有适应于不平衡数据集特点的评价指标。通过对不平衡数据集分类问题的研究,适用于不平衡数据集分类的评价指标主要包括G-mean、F-measure和ROC等。
在混淆矩阵概念的基础上,提出了不平衡数据集分类的评价指标。在两类问题中,用混淆矩阵表示两类中样本识别的情况,如表1。

表1 关于两类问题的混淆矩阵
在两类问题中,少数类表示为正类Positive,多数类表示为负类Negative。TP表示正类样本预测仍为正类,FN表示正类样本预测结果为负类,FP表示负类样本预测为正类,TN表示负类预测仍为负类。
(1)分类器的G-mean标准:
其中Positive Accuracy是正类正确率,Negative Accuracy是负类正确率。
根据G-mean的标准定义,改评价指标根据同时考虑了正类准确率和负类准确率,不仅仅是衡量整体的分类准确率,因此,改评价指标比较适合用来评价不平衡数据分类。
(2)分类器的F-measure标准
其中Recall为查全率,Precision为查准率;β表示调节系数,用来调节Recall和Precision,通过定义看出,F-measure同时考虑到正类和负类,也更注重对负类分类性能的评价,因此,该评价标准也更适合应用于不平衡分类评价。
(3)ROC曲线
经研究表明,ROC曲线(Receiver Operating Characteristics Curves)可以作为不平衡分类的性能评价指标,其中ROC曲线越凸,其对应分类器的性能越好,泛化能力越强。其表现方式可以由图1进行表示。其中X轴表示FPR,Y轴表示TPR。其中,两条ROC曲线L1和L2,,A,B,C,D,E和F表示的是ROC点,从图中可知,点A(0,1)表示的分类性能最好,B点最接近A点,其对应的分类器性能要比其他几个点优越。而E点处在对角线上,这样的分类器效果相当于随机分类的分类器,而F点的性能不如E点,即F点的性能不如随机分类的分类器性能。
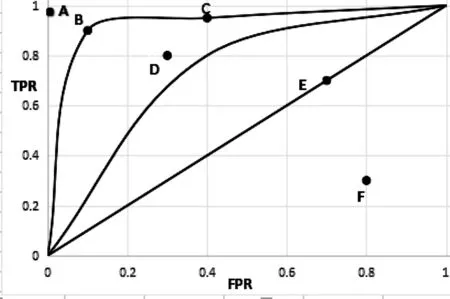
图1 ROC曲线图Fig.1 ROC curves
在不平衡分类器评价中,通常使用ROC曲线下与X轴所成面积即AUC(Area Under the ROC),对分类器性能进行量化分析,以面积的形式表示ROC曲线对应的分类器的泛化能力。由图1可以看出,L1对应面积比L2对应的面积大,因此L1对应的分类器的平均性能要高于L2所对应的分类器的平均性能。
4 问题与挑战
由于不平衡数据集的偏态分布,以及传统分类算法的局限性,使不平衡数据集的分类成为分类问题中的挑战及难点之一。另外根据已有研究,分析在机器学习、数据挖掘及大数据环境下,不平衡分类问题所面临的挑战与问题。
4.1 类结构角度分析:
众所周知不平衡分类方法主要根据数据层面和算法层面,这两种方法是从不平衡数据集整体出发解决不平衡分为问题,另外性能的减低也可能由不同样本的分布产生,尤其是少数类样本。文献[45]对少数类样本的邻居定义为四部分:安全点、边界点、稀有类和离群点。因此,可以从类结构的角度分析少数类结构。可以有一下预测方向。
①从不同于分类的角度去解决不平衡问题,可以把少数类的样本作为异常点,因此,该问题可以转化为异常检测与变化趋势检测问题。
②在数据处理层面,在确立少数类样本的结构时要专注于重要样本的选择以及难以识别样本。可以通过重采样典型样本,或监督学习欠采样处理,避免一些重要的少数类样本被去除。
③单独研究方向可研究少数类中噪声及利群样本。如何辨别给定的实体是噪声数据还是离群点?如何鉴定给定点是合适的?
④自适应思想,用来调整分析邻居的大小。
根据少数类结构分析特殊点或重要样本,可以使少数类的结构得到维持;分析一些特殊点或重要点,研究样本的范围降低,因此可以降低时间复杂度,性能也可以提高。
4.2 极度不平衡分类
一般所研究的类不平衡程度在1∶4到1∶100,然而在大数据环境中,会出现有些类不平衡程度可以达到1∶1000到1∶1500,缺少对高度类不平衡现象的研究,在数据处理和分类算法分析中将是一个新的挑战。在高度不平衡数据中,少数类代表性较差,也缺少一个清晰的结构。因此普通的不平衡方法应用性能会降低。文献[46]中对高度不平衡分类问题,基于SMOTE提出SMOTE-RM采样方法,对多数类样本进行聚类成多个簇,之后每个簇与所有的少数类样本结合进行分类,该方法则是将原始问题分成多个子问题。另外预测还有以下的方法。
①给少数类一种授权,使之可以预测或重建一个潜在的类结构。
②用数据特征的方法处理,对数据特征的有效处理可以提高对少数类的识别。
4.3 集成学习方法解决不平衡问题
集成方法在解决类不平衡问题中是很受欢迎的方法,Bagging,Boosting、随机森林与采样方法或代价敏感思想的结合。但大多数方法是基于启发式的,对于偏态分类的分类性能考虑的并不多。根据已有研究可能存在以下挑战:
①在使用集成学习解决不平衡问题中,缺少对多样性的理解,在不平衡数据集中,多样性对多数类和少数类是否都很重要?为提高集成学习方法有效解决不平衡分类问题,需要研究不平衡学习中多样性的现象。
②在以往的研究中没有清晰的指导集成规模的大小。一般情况下集成规模的大小是人工选择的,这会导致一些相似分类器处于存储状态中。另外对于研究数据集特征和分类器之间的关系也有很大作用。因此应该研究发展用于不平衡问题中集成修剪技术。
③在不平衡集成技术中,大多使用多数类投票组合的思想,在之后的研究中可以提出新的方法,在组合中要充分利用样本自身的价值。
5 总结
在实际应用中,数据分布常常是偏态的,传统的机器学习分类方法应用在不平衡数据中时,效果往往会很差,而实际应用中,少数类的数据又是很重要的,具有重要的研究价值和使用价值。针对不平衡数据的分类,学者们提出很多针对性的研究方法,本文从数据层面、算法层面、集成学习三个角度总结已有研究,分析不平衡分类中出现的问题及相应的解决方法。另外,结合已有的研究,根据机器学习、数据挖掘领域,分析不平衡分类研究中面临的挑战,对今后的研究进行方向指导。
[1]Krawczyk B.Learning from imbalanced data:open challenges and future directions[J].Progress in Artificial Intelligence,2016:221-232.
[2]Sahin Y,Bulkan S,Duman E.A cost-sensitive decision tree approach for fraud detection[J].Expert Systems with Applications An International Journal,2013,40(15):5916-5923.
[3]Wei W,Li J,Cao L,et al.Effective detection of sophisticated online banking fraud on extremely imbalanced data[Z].World Wide Web,2013,16(4):449-475.
[4]Liao T W.Classification of weld flaws with imbalanced class data[J].Expert Systems with Applications,2008,35(3):1041-1052.
[5]Sun Y,Wong A K,Kamel M S.Classification of imbalanced data:a review[J].International Journal of Pattern Recognition and Artificial Intelligence,2009,23(4):687-719.
[6]García S,Luengo J,Herrera F.Data preprocessing in data mining[M].Intelligent Systems Reference Library,2015.
[7]Branco P,Torgo L, Ribeiro R.A survey of predictive modelling under imbalanced distributions[Z].arXiv preprint arXiv,2015.
[8]Galar M,Fernandez A,Barrenechea E,et al.A review on ensembles for the class imbalance problem:bagging-,boosting-,and hybrid-based approaches[J].IEEE Transactions on Systems,Man and Cybernetics Part C (Applications and Reviews),2012,42(4):463-484.
[9]RC Prati,GEAPA Batista,DF Silva.Class imbalance revisited:a new experimental setup to assess the performance of treatment methods[J].Knowledge and Information Systems,2015,45(1):1-24.
[10]Dai HL.Class imbalance learning via a fuzzy total margin based support vector machine[J].Applied Soft Computing,2015,31:172-184.
[11]Deng X,Tian X.Nonlinear process fault pattern recognition using statistics kernel PCA similarity factor[J].Neurocomputing,2013,121(18):298-308.
[12]Guo Y,Zhang H Z.Oil spill detection using synthetic aperture radar images and feature selection in shape space[J].International Journal of Applied Earth Observation and Geoinformation,2014,30(1):146-157.
[13]Ozcift A,Gulten A.Classifier ensemble construction with rotation forest to improve medical diagnosis performance of machine learning algorithms[J].Computer Methods Programs Biomedicine,2011,104(3): 443-51.
[14]Murphey Y L,Chen Z H ,Feldkamp L A.An incremental neural learning framework and its application to vehicle diagnostics[J].Applied Intelligence,2008, 28(1):29-49.
[15]Batista G E,Prati R C,Monard M C.A study of the behavior of several methods for balancing machine learning training data[J].ACM Sigkdd Explorations Newsletter,2004,6(1):20-29.
[16]Joshi M V.Learning Classifier Models for Predicting Rare Phenomena[Z].University of Minnesota,2002.
[17]Japkowicz N.Concept-learning in the presence of between-class and within-class imbalances[J].Biennial Conference of the Canadian Society for Computational Studies of Intelligence,2001,2056:67-77.
[18]Barua S,Islam M M,Yao X,et al.MWMOTE--majority weighted minority oversampling technique for imbalanced data set learning[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(2):405-425.
[19]Chawla N V,Bowyer K W,Hall L O,et al.SMOTE:synthetic minority over-sampling technique[J].Journal of artificial intelligence research,2002,16(1):321-357.
[20]López V,Fernández A,García S,et al.An insight into classification with imbalanced data:Empirical results and current trends on using data intrinsic characteristics[J].Information Sciences,2013,250(1):113-141.
[21]Bunkhumpornpat C,Sinapiromsaran K,Lursinsap C.Safe-level-smote:Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem[C]//in Pacific-Asia Conference on Knowledge Discovery and Data Mining,2009,5476:475-482.
[22]Han H,Wang W Y ,Mao B H.Borderline-SMOTE:a new over-sampling method in imbalanced data sets learning[C]//in International Conference on Intelligent Computing,2005,3644(5):878-887.
[23]He H,Bai Y,Garcia E A,et al.ADASYN:Adaptive synthetic sampling approach for imbalanced learning[C]//in 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence),2008:1322-1328.
[24]Nekooeimehr I,Lai-Yuen S K.Adaptive semi-unsupervised weighted oversampling (A-SUWO) for imbalanced datasets[J].Expert Systems with Applications,2016,46:405-416.
[25]Mani I,Zhang I.kNN approach to unbalanced data distributions:a case study involving information extraction[C]//in proceedings of workshop on learning from imbalanced datasets,2003.
[26]Prati RC,Batista GEAPA,Monard MC.Data mining with imbalanced class distributions:concepts and methods[J].Indian International Conference on Artifical Intelligence,2009:359-376.
[27]Cateni S,Colla V ,Vannucci M.A method for resampling imbalanced datasets in binary classification tasks for real-world problems[J].Neurocomputing,2014,135(8):32-41.
[28]Ha J,Lee J S.A New Under-Sampling Method Using Genetic Algorithm for Imbalanced Data Classification[C]//in Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication,2016:95.
[29]Lin M,Tang K,Yao X.Dynamic sampling approach to training neural networks for multiclass imbalance classification[J].IEEE transactions on neural networks and learning systems,2013,24(4):647-660.
[30]Fan Q,Wang Z,Gao D.One-sided Dynamic Undersampling No-Propagation Neural Networks for imbalance problem[J].Engineering Applications of Artificial Intelligence,2016,53(C):62-73.
[31]Loyola-González O,Martínez-Trinidad J F,Carrasco-Ochoa J A,et al.Study of the impact of resampling methods for contrast pattern based classifiers in imbalanced databases[J].Neurocomputing,2016,175(PB):935-947.
[32]Seiffert C,Khoshgoftaar T M,J Van Hulse,et al.RUSBoost:A hybrid approach to alleviating class imbalance[J].Systems Man & Cybemetics Part A Systems & Humans IEEE Transactions on,2010,40(1):185-197.
[33]Zhou Z H ,Liu X Y.On multiclass cost-sensitive learning [J].Computational Intelligence,2010,26:232-257.
[34]Raskutti B,Kowalczyk A.Extreme re-balancing for SVMs:a case study[J].ACM Sigkdd Explorations Newsletter ,2004,6(1):60-69.
[35]Lee Y,Wahba G.Multicategory support vector machines,Theory and application to the classification of microarray data and satellite radiance data[J].Journal of the American Statistical Association,2003,99(465):67-81.
[36]XIE J G,QIU Z D.Fisher Linear Discriminant Model with Class Imbalance [J].Journal of Beijing Jiaotong University,2006,30(5):15-18.
[37]Karagiannopoulos MG,Anyfantis DS,Kotsiantis SB,et al.Local cost sensitive learning for handling imbalanced data sets[C]//in Control & Automation 2007.MED’07.Mediterranean Conference on,2007:1-6.
[38]Min F,Zhu W.A competition strategy to cost-sensitive decision trees[C]//in International Conference on Rough Sets and Knowledge Technology,2012,7414:359-368.
[39]Rodda S,Mogalla S.A normalized measure for estimating classification rules for multi-class imbalanced datasets[J].International Journal of Engineering Science and Technology,2011,3(4):3216-3220.
[40]O Loyola-González,MA Medina-Pérez JF Martínez-Trinidad,et al.PBC4cip:A new contrast pattern-based classifier for class imbalance problems[J].Knowledge Based Systems,2017,115 :100-109.
[41]Wozniak M.Hybrid Classifiers:Methods of Data,Knowledge,and Classifier Combination[M].Springer Publishing Company,2013.
[43]Cao Q,Wang SZ.Applying over-sampling technique based on data density and cost-sensitive SVM to imbalanced learning[C]//International Joint Conference on Neural Networks,2011,2:543-548.
[44]Jerzy Blaszczynski,Jerzy Stefanowski.Neighbourhood sampling in bagging for imbalanced data[J].Neurocomputing,2014,150:529-542.
[45]Yoav Freund,Robert E Schapire.Experiments with a new boosting algorithm[C]//international conference on machine learning,1996,13:148-156.
[46]Robert E Schapire,Yoram Singer.Improved boosting algorithms using confidence-rated predictions[J].Machine learning,1999.37(3):297-336.
[47]Wei Fan,Salvatore J Stolfo,Junxin Zhang,et al.AdaCost:misclassification cost-sensitive boosting[C]//international conference on machine learning,1999:97-105.
[48]Mahesh V Joshi,Vineet Kumar,Ramesh C Agarwal.Evaluating boosting algorithms to classify rare classes:Comparison and improvements[C]//international conference on data mining,2001:257-264.
[49]Bartosz Krawczyk,Michal Woniak,Gerald Schaefer.Cost-sensitive decision tree ensembles for effective imbalanced classification[J].Applied Soft Computing,2014,14(1):554-562.
[50]Nitesh V Chawla,Nathalie Japkowicz,Aleksander Kotcz.Editorial:special issue on learning from imbalanced data sets[J].Sigkdd Explorations,2004,6(1):1-6.
[51]Wei Liu,Sanjay Chawla,David A Cieslak, et al.Chawla.A Robust Decision Tree Algorithm for Imbalanced Data Sets[C]//Siam International Conference on Data Mining,2010,21(3):766-777.
[52]Wei Liu,Sanjay Chawla.Class confidence weighted kNN Algorithms for imbalanced data sets[C]//PAKDD(2),2011:345-356.
[53]Yuxuan Li,Xiuzhen Zhang.Improving k nearest neighbor with exemplar generalization for imbalanced class if ication[C]//PAKDD,2011:321-332.
[54]Jinyan Li,Simon Fong,Sabah Mohammed,et al.Improving the classification performance of biological imbalanced datasets by swarm optimization algorithms[J].The Journal of Supercomputing,2016,72(10):3708-3728.
[55]B Schölkopf,J Platt,J Shawetaylor,et al.Estimating the support of a high-dimensional distribution[J].Neural Computation.2001,13(7):1443-1471.
[56]Xiuzhen Zhang,Guozhu Dong,Kotagiri Ramamohanarao.Information-based classification by aggregating emerging patterns[Z].Intelligent Data Engineering and Automated Learning,2000,1983:48-53.
[57]X Zhang, G Dong. Overview and analysis of contrast pattern based classification[J].Contrast Data Mining: Concepts, Algorithms, and Applications, Chapman & Hall/CRC, United States of America,2012: 151-170.
[58]Nitesh V Chawla,Aleksandar Lazarevic,Lawrence O Hall,et al.SMOTEBoost:Improving prediction of the minority class in boosting[J].in knowledge discovery in Database:PKDD,2003,2838:107-119.
[59]C Seiffert,Taghi M Khoshgoftaar,J Van Hulse.Improving software-quality predictions with data sampling and boosting[J].Systems man and cybernetics,2009,39 (6):1283-1294.
[60]Xuying Liu,Jianxin Wu,Zhihua Zhou.Exploratory undersampling for class-imbalance learning[J].systems man and cybernetics,2009,39(2):539-550.
[61]P Domingos. Metacost: a general method for making classifiers cost-sensitive[C]//in Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2006:155-164.
[62]Zhongbin Sun,Qinbao Song,Xiaoyan Zhu,et al.A novel ensemble method for classifying imbalanced data[J].Pattern Recognition,2015,48(5):1623-1637.
A survey of imbalanced classification problems
CHEN Xiangtao,GAO Yajing
(School of Information Science and Engineering, Hunan University, Changsha 410082, China)
The imbalanced classification is derived from a data skew issue in the binary classification.When handing imbalanced data using a traditional classifier,its classification result is often unsatisfactory.Therefore,many classifiers for dealing with skewed data set have been put forward,including data-level techniques,algorithm-level techniques,hybrid methods and also ensemble classifiers.The essence of imbalanced classification problem,the related works,the processing strategies,the nature of imbalanced data and the corresponding evaluation indicators are presented in this paper.Aiming at the exiting studies,we also introduce existing problems and future challenges in this field.
machine learning; imbalanced classification; data-level methods;algorithm-level methods;ensemble learning
1672-7010(2017)02-0001-11
2017-01-18
陈湘涛(1973-),湖南新宁人,副教授,博士,湖南大学硕士生导师,从事模式识别、机器学习方面的研究,E-mail:lbcxt@hnu.edu.cn
TP391
A
