基于改进仿射传播聚类的图像分割算法研究
2017-04-13赵淑娟王江晴孙阳光
赵淑娟,王江晴,孙阳光
(中南民族大学 计算机科学学院,湖北 武汉 430074)
基于改进仿射传播聚类的图像分割算法研究
赵淑娟,王江晴,孙阳光
(中南民族大学 计算机科学学院,湖北 武汉 430074)
仿射传播聚类算法是一种比较新的基于质心的聚类算法,在图像分割领域得到了广泛应用。仿射传播聚类算法最终聚类数目会受到偏向参数P(Preference)的影响,得到的聚类数目往往偏多,影响分割质量。鉴于此,提出一种改进的仿射传播聚类的图像分割算法,该算法将仿射传播聚类算法与CURE层次聚类算法相结合,CURE算法能够对仿射传播聚类算法的分割结果进行优化。实验验证表明,改进后的算法图像分割效果更好。
图像分割;仿射传播聚类;聚类数目;偏向参数;CURE算法
0 引言
在计算机高速发展的时代,人们越来越多地借助计算机获取与处理自己所需的图像信息。然而,在对图像进行研究和处理时,人们不一定对所有的图像信息感兴趣,而有时只对图像中某些特定的、具有独特性质的部分感兴趣,这就需要将这些区域从图像中分割出来。图像分割就是将图像划分为几个不同的区域,在相同的区域内,图像的特征相近;而在不同的区域,图像特征差异性较大。图像特征可以是图像自身的特征,如像素的灰度、边缘轮廓和纹理等[1]。图像分割技术应用领域广泛,已在生物医学图像分析、工业自动化、在线产品检验、生产程控、文件图像处理、遥感图像、保安监视及军事等方面得到了广泛应用。然而由于图像自身的复杂性,其发展至今仍没有一个通用的、绝对好的方法,因此对图像分割方法的进一步研究具有十分重要的意义。聚类算法一经提出就凭借其在图像分割上的良好效果,在图像分割领域受到了广泛关注。聚类分析是根据图像在某些属性上的相似性,将图像划分为不同类的过程。聚类算法能够保证一幅图像上同一类内的对象有较高的相似性,类间对象有较高的差异性,这就有利于人们特定地去分析自己感兴趣的内容。根据聚类方法的不同,聚类算法可以分为多种,文献[2]中将聚类算法大致分为层次算法、划分算法、基于密度和网格的方法以及其它聚类算法。K-means聚类算法作为一种比较经典的图像分割算法,在图像分割中得到了很好的应用。然而,K-means聚类算法必须预先给定聚类数目,对初始聚类中心的选择比较敏感,如果给定的数值不合适则容易陷入局部最优状态。
仿射传播聚类算法(Affinity Propagation Clustering, AP)是2007年由Frey等[3-4]在《Science》上提出的同属于K-means算法的一种新的聚类算法,AP算法克服了K-means算法的缺点,不需要预先指定聚类中心,初始时将全部的数据点都作为候选聚类中心点,通过数据点之间的消息传递过程不停地循环迭代,最终获得高质量的聚类中心[5],避免了局部最优的状态,同时 AP算法对数据点之间生成的相似度矩阵的对称性没有要求,多次独立运行的结果都非常稳定。目前也有一些学者对AP算法进行了改进[6-9],有的是与其它算法结合来缩短运行时间,有的是对自身结构作了改进,然而并没有从根本上解决问题。AP聚类算法虽然运行结果比较稳定,但是在处理结构较松散的数据时产生的类数往往会偏多[10],在处理具有复杂结构的数据集时,不能够产生合理的聚类效果,因此会影响图像分割质量。同时AP算法最终的聚类数目在很大程度上会受到偏向参数ρ的影响,这就使得AP算法对ρ值的选择较为敏感[11-12]。CURE算法是一种凝聚型层次聚类算法,它是基于质心和代表点的策略,能够有效地处理非球形数据,且该算法能够很好地控制孤立点对聚类结果的影响[13-14]。因此,本文将AP聚类算法和CURE算法相结合,利用CURE算法的优点对AP聚类算法的结果进行优化,从而提高聚类质量。
1 相关算法
1.1 传统AP聚类算法
AP聚类算法不需要事先指定聚类数目,而是在初始时把全部的数据点都作为候选聚类中心,通过计算数据点间的相似度矩阵S,确定偏向参数p(preference),经过循环迭代过程,判断决策矩阵E从而找到聚类中心。
设任意两个数据点xi和xk,它们之间的相似度s(i,k)是通过计算它们的负的欧氏距离来得到,最终得到的相似度矩阵S是一个N×N的矩阵,s(i.k)的计算公式如下:
(1)
式(1)中,当i=k时,s(i,k)本应该是零,但为了确保每个点成为聚类中心的可能性相同,这里全部设置为偏向参数ρ的值。
AP算法在消息传递过程中涉及两个重要参数:吸引度矩阵R和归属度矩阵A。吸引度矩阵R:吸引度r(i,k)是由点xi发送到候选聚类中心点xk的消息,表示点x可以成为点xi的类中心点的程度。归属度矩阵A:归属度a(i,k)是由候选聚类中心点xk发送到点xi的消息,表示点xi是否选择点xk作为其类中心点的程度。
r(i,k)与a(i,k)的大小直接决定着xk能否成为聚类中心,值越大,xk成为聚类中心的可能性越大。它们之间的消息传递过程如图1所示。
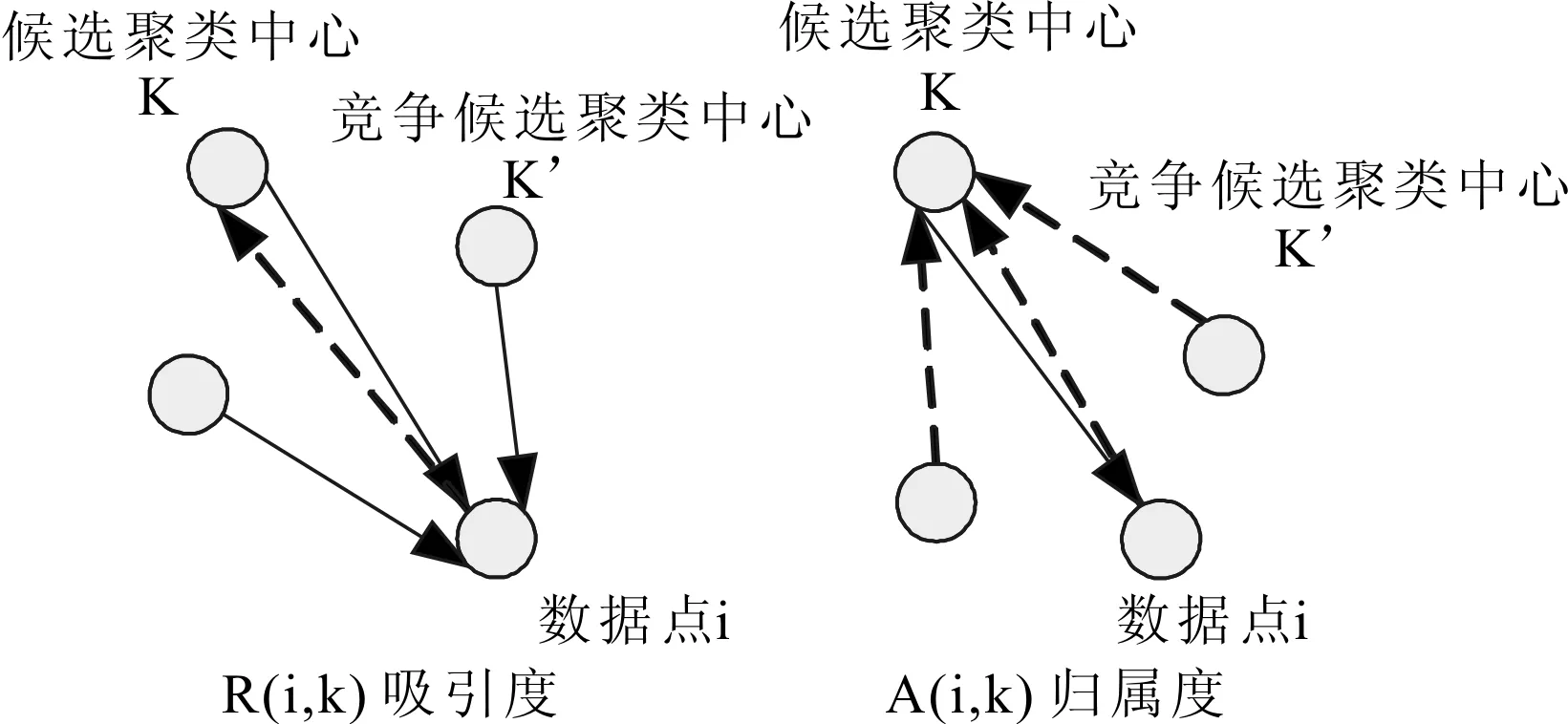
图1 消息传递过程
根据文献[3]用相似度矩阵S来计算吸引度矩阵R和归属度矩阵A:
(2)
(3)
(4)
(5)
AP算法还引入了两个重要的信息参数:阻尼振荡因子lam和偏向参数p(preference)。在每一次的更新迭代过程中,R和A的值利用lam来进行迭代更新,更新过程如下:
(6)
(7)
其中,当迭代过程中获得的聚类个数不停地发生震荡而无法收敛时,适当增大lam的值可消除震荡,使算法更快收敛。通常情况下,lam设置在0.85左右可以直接避免震荡。对于偏向参数p,在很大程度上影响最终的聚类数目,通常会把p值设置成相似度矩阵的中值,但即使设置成相似度矩阵的中值也并非就能够获得最好的聚类效果,因此很难直接知道p取何值时能够获得最好的聚类效果。
AP算法不停地更新吸引度矩阵R和归属度矩阵A的值,当超过预先设置的最大迭代次数maxits或聚类中心连续convits次稳定不变时,算法将停止迭代。通过终止时r(i,k)+a(i,k)的值来确定最终的聚类结果。数据点k确定为i的类中心点,k的值为:
k=argkmax(r(i,k)+a(i,k))
(8)
对式(2)两边同时加上a(i,k)得:
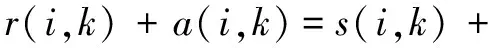
(9)
1.2 AP算法步骤
对于由N个数据点组成的数据集T,AP算法的运算步骤可以用图2所示的流程图来表示。
AP聚类算法虽然多次独立运行的结果比较稳定,但其仍然存在两个缺点:①AP算法对偏向参数P的选择较敏感,P值偏小获得的聚类个数偏少,P值越大获得的聚类个数越多。如果逐个去试就会增加算法的复杂度,因此P值的选择不容忽视;②AP算法在处理较松散的数据时容易产生较多的聚类数,影响聚类效果,即在消息传递过程中有可能多个数据点成为聚类中心的优先级相同,从而导致聚类数目偏多,影响图像分割质量。
1.3 CURE算法
CURE算法是针对大多数数据集而提出的一种基于质心的聚结型层次聚类算法。CURE算法最开始是将每个数据点都看成一个类(即每个类中只有这个数据点本身),然后计算各个数据点间的相似性,将最相似的两个数据点进行合并。CURE聚类算法可以适用任意形状的簇,通过收缩因子来控制孤立点的影响。因此在遇到较松散的数据集时CURE算法能够更好地处理孤立点,而且能够识别非球形和大小并改变较大的类。
设任意一个数据集W,CURE算法最初聚类时每个数据点都是一类,通过计算两两之间的距离,然后融合距离最近的两个类,直到达到预先设定的聚类个数。对于任意一个类u,u.mean和u.rep分别表示类u的聚类中心点和属于类u的数据点,类与类之间的距离是采用欧式距离,两个聚类u、v之间的距离计算公式定义为:
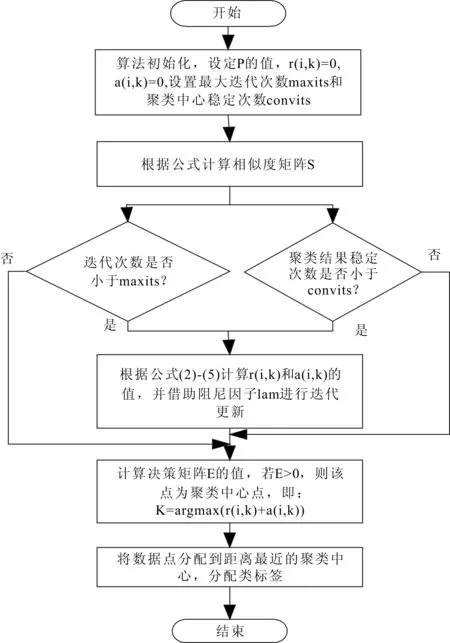
图2 AP算法运算步骤流程
dist(u,v)=min(dist(u.rep,v.rep))
(10)
当确定距离最小的两个类后,将这两个类融合,融合后形成新的聚类中心点,计算公式为:
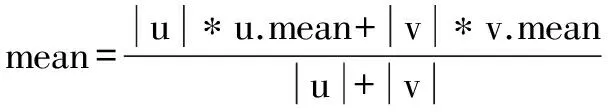
(11)
其中|u|为类u的数据点个数。
2 改进的AP聚类算法
针对AP聚类算法存在的一些缺点,以及CURE算法能够处理任意形状数据集的优点,本文是将两种聚类算法进行结合形成一种新的算法,即C-AP算法,以克服AP算法的不足,经验证C-AP算法的图像分割效果明显优于AP算法的聚类结果。
2.1 算法原理
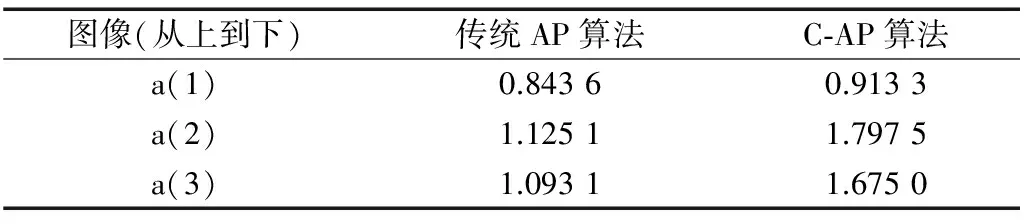
C-AP算法进行聚类分为3个过程:首先运用AP算法对数据集进行预分割,会获得n个聚类中心;其次对于获得的这n个聚类中心进行去异常值处理,获得n个质量较好的聚类中心;最后阶段是将这个质量较好的聚类中心作为CURE算法的输入数据,经过CURE算法聚类后将获得最终的聚类中心,也是质量最高的聚类中心Cbest,再将其余的数据点分配到所属的类。C-AP算法为了得到更好的聚类效果,偏向参数p的值不能设置得太小,这样才能保证在进行CURE聚类的阶段输入数据点个数不会太少。若值设置得太大,一些噪声点就会被分割出来,这就必须进行去噪声处理。C-AP算法引入了去噪声率α,若centeri为中心的簇中样本点个数ni<α 由于CURE算法需要初始设定聚类数目,为了能够得到最好的聚类个数,本文加入了聚类有效性指标Silhouette指标,能够通过Silhouette指标值来判断出最优的聚类个 数[15]。设一个有N个样本的数据集被划分为k个类Ci(i=1,2,l,k),其中,ni表示Ci类中的样本点个数。t为类别Ci中的样本点,则设a(t)表示为Ci中t与其类内其它样本的平均距离(此处为欧氏距离),d(t,Ci)表示t到另一类别中所有样本平均聚类,得到bt=min{d(t,Ci},j=1,23,…,k,且j≠i,得到样本t的Silhouette指标为: (12) 一个聚类中所有样本点的平均值能够反映该类的紧密性和可分性,那么整个数据集内所有样本的Sil平均值就可以反映整个聚类结果的质量,平均Silhouette指标越大表明聚类质量越好,其最大值对应的类数即为最优聚类个数。本文是通过比较不同的分割类数得到不同的Silhouette指标值,选择Silhouette指标值较大的类数输出。 2.2 C-AP算法进行图像分割步骤 Step1:输入待分割图像,提取图像的灰度值作为数据点输入。 Step2:初始化聚类算法参数:计算数据点间的相似度矩阵S,偏向参数P,去噪声率α。 Step3:应用AP算法对图像进行预分割,会得到M个聚类中心点{center1,center2,…,centerm}。 Step4:对m个聚类中心进行去噪声点处理。即基于该聚类中心的簇中样本个数是否小于α×N,若小于a×N的值,则将该聚类中心删除;反之将该聚类中心进行下一步聚类,这样就得到n个质量较好的聚类中心{goodcenter1,goodcenter2,…,goodcentern}。 Step5:对获得的这n个聚类中心进行CURE算法聚类,通过比较不同类数对应不同的Silhouette指标值选出最好的聚类个数,对剩余的数据点进行类标签分配。 Step6:根据聚类结果输出分割后的图像。 本文的实验运行环境是在MATLAB 7.10.0(R2010a)版本上运行。图像均来源于Berkeley的标准灰度图像分割数据库BSDS300中的图像。本文是对AP算法和C-AP算法的聚类性能进行比较,实验中AP算法初始时偏向参数P设置为相似度矩阵的中值,算法最大迭代次数设置为1 000,迭代过程聚类结果连续不发生改变的次数设置为100,阻尼系数lam设置为0.9,去噪声率α取值为0.02。本文选取了其中的3幅图像进行分割,分割效果如图3所示。 图3 AP算法和C-AP算法分割结果 从图2可以看出,本文的C-AP算法分割效果要优于传统的AP算法分割效果。其中传统AP算法将第一幅图像分割成了6类,本文算法是分割成了3类,传统AP算法分割数目多于本文算法,天空背景区域出现了错分割现象,本文算法分割后的图像更加干净,相对准确。第二幅图像,传统AP算法对草地分割得比较粗糙,本文C-AP算法则比较细腻,将背景和山羊明显的区分开来。第三幅图像中,本文C-AP算法对背景光晕处的分割效果明显优于传统AP算法的分割效果。直观上看,实验结果验证了本文改进后的算法在分割效果上更加精确,但有时通过肉眼观察会存在主观性,缺乏定量分析,因此本文引入了区域间对比度来客观评价算法的性能。图像分割就是将图像分割成若干类,类与类之间的差异越大表明分割效果越好,因此选择区域间对比度能很好地反应分割的好坏。区域间对比度(GC)用于衡量分割后图像各区域之间的差异度,GC值越大表明分割效果越好[16]。设一幅图像被分割成fi和fj个区域,i和j分别表示图像中的任意两个区域,fi和fj分别表示第i个区域和第j个区域的平均灰度,则GC可表示为: (13) 传统AP算法和本文算法的区间对比度如表1所示。 表1 两种算法GC值对比 从表1中的数据可以看出,改进后的仿射传播聚类算法(C-AP算法)与传统的AP聚类算法相比,3幅图像的区域间对比度都得到了提高,说明改进后的算法分割效果更好。 本文针对传统的仿射传播聚类算法在图像分割上存在的不足,对传统的仿射传播聚类算法作了改进,通过与CURE层次聚类算法结合使得算法克服了对偏向参数选择的敏感性,对于一些孤立点的处理更加健壮,经验证改进后的算法在图像分割效果和性能上都得到了一定的提高。由于本文算法是在传统放射传播聚类算法分割之后再利用CURE算法作进一步分割,在运行时间上会略长,因此如何进一步缩短运行时间是下一步研究的重点。 [1] 章毓晋.图像分割[M].北京:科学出版社,2001. [2] 孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61. [3] FREY B J,DUECK D.Clustering by passing messages between data points[J].Science,2007,315(5814):972-976. [4] MÉZARD M.Where are the exemplars[J].Science,2007,315(5814):949-951. [5] SHANG FAN-HUA,JIAO L C,SHI JIA-RONG,et al.Fast affinity propagation clustering:a multil- evel approach[J].Pattern Recognition,2012,45(1). [6] 肖宇,于剑.基于近邻传播算法的半监督聚类[J].软件学报,2008,19(11):2803-2813. [7] 许晓丽,卢志茂,张格森,等.改进近邻传播聚类的彩色图像分割[J].计算机辅助设计与图形学学报,2012,24(4):514-519. [8] 董俊,王锁萍,熊范纶.可变相似性度量的近邻传播聚类[J].电子与信息学报,2010,32(3):509-514. [9] 刘晓楠,尹美娟,李明涛,等.面向大规模数据的分层近邻传播聚类算法[J].计算机科学,2014,41(3):185-188. [10] 王开军,李健,张军英,等.半监督的仿射传播聚类[J].计算机工程,2007,33(23):197-199. [11] KAREN K.Affinity program slashes computing times [EB/OL].http://www.news. utoronto. ca/bin6/ 070215-2952.Asp,2007-10-25. [12] BODENHOFER U,KOTHMEIER A,HOCHREITER S.APcluster:an R package for affinity propagation clustering[J].Bioinformatics,2011,27(17):2463-2464. [13] GUHA S,RASTOGI R,SHIM K.CURE:an efficient clustering algorithm for large databases[J].ACM SIGMOD Record,ACM,1998,27(2):73-84. [14] 沈洁,赵雷,杨季文,等.一种基于划分的层次聚类算法[J].计算机工程与应用,2007,43(31):175-177. [15] DUDOIT S,FRIDLYAND J.A prediction-based resampling method for estimating the number of clusters in a dataset[EB/OL].http://www.edlab.cs.umass.edu/cs69 1k/conlon/readings/Dudoit Fridlyand2002GB.pdf,2002. [16] LEVINC M D,NAZIF A M.Dynamic measurement of computer generated image segmentations[J].IEEE Trans.PAMI-7,1985,7(2):155-164. (责任编辑:孙 娟) 国家自然科学基金项目(60975021);中南民族大学中央高校基本科研业务费专项资金项目(CZZ15003) 赵淑娟(1990-),女,山东菏泽人,中南民族大学计算机科学学院硕士研究生,研究方向为图像处理、人工智能;王江晴(1964-),女,湖北武汉人,博士,中南民族大学计算机科学学院教授,研究方向为人工智能、数字图像处理;孙阳光(1978-),男,湖北武汉人,博士,中南民族大学计算机科学学院副教授,研究方向为数字图像处理。 10.11907/rjdk.162273 TP312 A 1672-7800(2017)003-0018-043 实验结果及分析

4 结语
