一种改进的支持向量机模型研究
2017-04-10郭晨晨朱红康
郭晨晨, 朱红康
(山西师范大学 数学与计算机科学学院, 山西 临汾 041000)
一种改进的支持向量机模型研究
郭晨晨, 朱红康*
(山西师范大学 数学与计算机科学学院, 山西 临汾 041000)
传统的支持向量机无法充分、有效地检测出类间重叠区域中的少数实例,也无法对不平衡的数据集作出合理分类,而类的重叠分布和不平衡分布在复杂数据集中是常见的.因而,它们对支持向量机的分类性能产生负面影响.基于此,提出了一种利用距离度量代替支持向量机松弛变量的改进模型.在一定程度上解决了支持向量机处理复杂数据集中类间重叠和不平衡的问题.最后,利用合成数据集和UCL数据库中的数据集的实验验证了该算法的先进性.
支持向量机; 重叠; 不平衡; 松弛变量; 距离度量
0 引言
自Vapnik[1]提出支持向量机,因其有效的分
类性能,严谨的数学理论基础,成为处理分类问题的热门技术.在小样本数据集、非线性分类问题中有很好的效果,特别对于高维数据的处理,可以有效的避免维数灾难[2].支持向量机主要原理是最大化超平面边距同时最小化分类误差.但SVM无法充分、有效地检测出类间重叠区域中的少数实例,也无法对不平衡的数据集作出合理分类.因为类间存在重叠区域时,类间清晰的超平面边缘将不存在.而数据集中同时存在大样本类和小样本类时,支持向量机的处理结果往往趋向于大样本类,使分类结果产生严重的偏差.针对SVM存在的问题,目前已经提出了一批实用的方法,比如对数据预处理方式进行调整,对大样本类多取样,对小样本类少取样[3-5];改良核函数矩阵调整聚类边界降低迭代过程中原核矩阵与保形变换核矩阵之间会产生偏差[6];对误报率和漏报率之间进行权衡控制[7];通过修改松弛变量减少异常数据点对自适应边缘和决策函数的影响,利用数据点的平均值和标准差来克服数据扰动等[8-10].
本文试图通过一种新的方式改善这一问题.即调整决策边界,设置边缘为适当距离提高分类性能.由于原有松弛变量模型在学习阶段对离群数据点并不敏感,因而采用了新型的松弛变量模型,用距离度量代替原来的松弛变量,并在训练阶段适当扩大了异常点与正常点的距离.从而降低类分布的影响,使得大样本类和小样本类都能得到很好的划分.基于距离度量的松弛变量被包含在对偶问题的最优函数中,参数由梯度下降法得到.使得改进的松弛变量模型不容易受到复杂数据集的影响.
1 改进松弛变量的支持向量机
1.1 传统支持向量机
Vapnik[1]提出的支持向量机主要处理二分类问题,其核心思想如下:
在一个样本空间中,由决策边界将所有样本分为两个部分,即对训练样本集进行二元分类.对于一个含有n个样本点的训练样本集,每个样本点都表示为一个二元组,(xi,yi)(i=1,2,…,n)其中xi=(xi1,xi2,…,xik)T对应于第i个样本的属性集,yi∈{-1,1}表示分类结果.将原始空间中的样本点xi通过映射函数φ(x)映射到高维特征空间中,得到线性支持向量机决策边界基本形式如公式(1)所示:
f(x)=w·φ(x)+b
(1)
由于训练数据集中可能存在的噪声,即线性SVM不可分情况.必须考虑边缘宽度与线性决策边界允许的训练错误数目之间的折中.从而引入松弛变量实现边缘“软化”,如公式(2)所示.
(w·φ(x)+b)≥1-ξi,当yi=+1;
(w·φ(x)+b)≤-1+ξi,当yi=-1.
(2)
式(2)中:∀i,ξi≥0.
由于在决策边界误分样本数没有限制,从而可能产生边缘很宽,但误分离很多训练实例的决策边界.修改目标函数,以惩罚松弛变量值很大的决策边界.修改后的目标函数如公式(3)所示.
s.t.yi(w·φ(x)+b)≥1-ξi
(3)
式(3)中:C是软边缘惩罚参数.
1.2 改进松弛变量的支持向量机
虽然在传统SVM中利用软边缘的方法解决了线性不可分的问题,但这都建立在数据集中的类是大致平衡且少重叠的.针对数据集中存在的类间重叠和不平衡问题,利用距离度量代替原来的松弛变量ξi,在马氏空间中放大了正常样本与异常样本的距离,如图1所示.

图1 马氏空间中正常样本与异常样本的距离示意图
此外,为了发现一个最佳超平面及边缘以达到克服扰动的最大鲁棒性并且减少错误分类风险的概率,超平面的变化过程如图2所示.

图2 超平面与边缘变化过程
以上通过图示展示改进产生的相关变化,下面对距离度量代替松弛变量ξi做具体解释.
传统的线性支持向量机的不可分情况如公式(3)所示,这里作出改进,将距离D(x)2替换原来的松弛变量ξi,并且最小化向量w而非原来的w与误差余量的和.D(x)2表示每个样本点与其各自类中心的归一化距离,修改后的目标函数如下:
s.t.yif(xi)≥1-θD(xi)2
(4)
式(4)中:θ是预选参数,用于测量松弛变量的平均影响,距离计算如公式(5)所示:
(5)
式(5)中:S-1是协方差矩阵的逆,μ是均值向量,t是转置符号.
样本点与其各自类中心间的距离在一定范围才能建立联系,距离D(x)2满足需要下面的约束条件:
0≤D(xi)2≤1
(6)
确定距离D(x)2,得到支持向量满足下面的等式:
yif(xi)=1-θD(xi)2
(7)
由此,该优化问题的拉格朗日函数可以记作如下形式:
(8)
式(8)中:αi叫做拉格朗日乘子.
为了最小化拉格朗日函数,采用与传统方法相似化的方法进行处理.对Lp关于w和b求偏导,并令它们等于0,得到(9)、(10)两个等式:
(9)
(10)
w可由公式(11)得到:
(11)
使用b的平均值作为决策边界的参数,计算公式如下:
αi{yif(xi)-1+θD(xi)2}=0
(12)
对于支持向量,将公式(11)带入公式(8)可得:
(13)
这样,不可分的对偶问题可以转化为下面的优化问题:
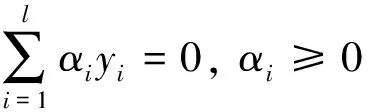
(14)
通过求解对偶问题得到最优参数w和b后,可以根据符号进行分类(公式1),参数θ可由梯度下降法求得,这是一个一阶优化算法.本方法需要最大化公式(13)并且找到合适的参数θ,从而进行如下计算:
(15)

t≥0.
(16)
由于θ的不同取值会对整个优化问题的性质产生根本影响,因此需要对参数θ进行分类讨论:
情况1:当θ=0,则边缘不用修改,此问题转化为硬边缘SVM问题;
情况2:当θ=1,则该问题同传统SVM相同;
情况3:当0<θ<1,则0<θ×D(xi)2<1,该算法对决策边界右侧的异常点有较好的效果,每个类中心的影响是有限的;
情况4:当θ>1,则θ×D(xi)2>1,对于落在错误位置的异常点,该算法性能强大.较大的θ使得支持向量靠近类中心,因而更容易得到一个清晰的决策边界.然而,分类的错误率也会随之增加,调整后的决策边界更趋向于检测异常点.

(17)

(18)
1.3 算法描述
根据上节的推导过程,设计相应的算法进行实验分析.该算法需要对数据集xi进行最大次数T次的迭代运算,在每一次的迭代中,自适应的计算函数D(x)2并更新参数θ和σ的值,算法如下:
输入:训练数据集xi,核函数K,最大迭代次数T,终止条件η,核函数参数σ,规则化参数θ.
子函数:边缘函数Margin(xi,σ) ,训练模型SVM(xi,K,σ,θ) ,V-折交叉验证函数V-Fold(xi,v) ;
主函数:v←1
{
xiv←V-Fold(xi,v);
Ctv←SVM(xiv,K,σK);
t←0;
While(Ctv-Ctv+1<η&t { t←t+1; } End While Cv←Ctv; v←v+1; } ReturnAccuracy; 输出:Cv. 2.1 数据集复杂度的度量 分类算法性能的好坏很大程度上取决于训练数据集本身的特性,以前的研究往往通过减少未知数据集的选取进行分类的弱比较,很难从统计学和几何类分布角度来考虑分类结果.基于此,为了提高数据复杂度度量的合理性,采用两种量度方式进行综合评估. 2.1.1 Fisher鉴别准则 Fisher的广义判别式(F1)[11]用来对两个类间的区别进行鉴别,公式如下: (19) 这样对于多维或多类数据集的类间重叠率(R1),可以表示为如下形式: (20) 2.1.2 重叠率 对于重叠率的计算,该方法采用的指标R2[12]进行度量,具体公式如下: (21) 式(21)中: min maxi=min{max(fi,ci),max(fi,c2)}, max mini=max{min(fi,ci),min(fi,c2)}, max maxi=max{max(fi,c1),max(fi,c2)}, min mini=min{min(fi,c1),min(fi,c2)}. max(fi,ci)和min(fi,ci)分别是类ci(i=1,2) 的特征值fi中的最大值和最小值.R2的值越小表明类间的重叠程度越高. 2.2 性能度量 准确率度量是将数据集中所有的类看成同等重要,因此并不适合分析不平衡数据集.在不平衡数据集中,少数类往往比多数类更有意义. 二元分类问题中,少数类通常记为正类,多数类记为负类.表1显示了汇总分类模型正确和不正确预测的实例数目的混淆矩阵. 表1 类不是同等重要的二分类问题的混淆矩阵 混淆矩阵中的计数可以表示为百分比的形式.灵敏度定义为被模型正确预测的正样本的比例,即: (22) 同理,特指度定义为被模型正确预测的负样本的比例,即: (23) 精确度定义为模型正确预测的所有样本的比例,即: (24) 通过该算法与传统SVM进行性能对比来展示改进算法在复杂数据集分类性能上获得的提升.对合成数据集的各个变量进行控制,产生三种因素的不同组合来研究类不平衡问题与类间重叠问题对分类精度产生的影响. 3.1 析因实验 实验一设计加入了三个程度的“类不平衡”因素、三个程度的“类重叠”因素、两个种类的“分类器”几种不同的情况,将它们安排在同一个析因实验中.根据不同的处理组合产生合成数据集.每个数据集分为两个类并且随机地以二维正态分布,共100个实例. 重叠性根据重叠程度划分为三个层次:低度:μ1=40,μ2=60;中度:μ1=45,μ2=55;高度:μ1=50,μ2=50. 则合成数据集的协方差矩阵定义为: 同理,将不平衡性划分为三个不同层次.低度:50%的实例属于第一类,50%的实例属于第二类;中度:75%的实例属于第一类,25%的实例属于第二类;高度:90%的实例属于第一类,10%的实例属于第二类. 分类器因素:一种是传统的SVM,一种是本文改进算法. 根据上面的各种因素设计出9种不同的合成数据集,其中坐标轴Y轴对类重叠性和类不平衡性没有影响.分别将类重叠的低、中、高三种程度表示为1、2、3,类不平衡的低、中、高三种程度表示为一、二、三,“×”表示少数类,“Ο”表示多数类,实验结果如图3所示. 图3 合成数据集聚类实验 表2显示了用R1和R2两种测量指标对合成数据集的计算结果. 表2 合成数据集的R1和R2指标计算结果 根据表2中的指标数据,得到最终实验结果,如表3所示. 表3 数据集不同程度重叠性和不平衡性的度量结果对比 从表3可知,改进算法在灵敏度和准确度上均有较大提升,特别在高度重叠性和高度不平衡性的合成数据集中体现的尤为明显,在中低度层面基本保持不变.结果表明,数据复杂性(重叠性和不平衡性)对分类精确度影响明显,且成反相关性. 3.2 UCI数据集实验 实验二设计从UCI数据库中选择6个数据集进行测试,如表4所示. 表4 UCI数据集测试 表4中,第二列中括号中的数据分别表示多数类和少数类样本的数量,即正样本和负样本的数量.仅从正负样本的比例分析,German、Glass、BCW数据集存在低度不平衡性,Yeast和Car数据集存在中度不平衡性,Abalone数据集存在高度不平衡性.但考虑复杂性度量指标R1和R2,Yeast是最不平衡的.因此,单一分析正负样本率不能充分了解数据集的特性. 除了考虑数据复杂度对分类精度产生的影响外,还需要对分类器的性能进行验证.使用4-交叉验证法验证传统SVM和本文改进算法的性能.该方法将原始数据集分为两部分,一部分为训练数据集,一部分为测试数据集.首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型,以此来做为评价分类器的性能指标.使用多折交叉验证主要为了提高可利用的训练数据集样本数量.此外,可以分为多个相互独立的测试数据集有效地覆盖整个样本空间.实验二重复4次,得出结果. 核函数选择径向基核函数(Radial Basis Kernel Function),利用梯度下降法获得参数θ和σ,终止条件设置为100,并在迭代50次后得到稳定的参数.实验结果如表5所示. 表5 SVM与本文所提算法在UCI数据库上的对比结果 由表5可得,改进算法关于三种指标的度量值均优于传统SVM.此外,由4-交叉验证法得到参数的θ值与数据集的复杂度成正相关,而参数σ仅依赖于数据的规格参数.从表5可得,前三个数据集参数θ值均少于1.5,数据集的复杂度相应地呈现低度状态,而参数σ明显不具有这样的性质. 根据以上两个实验可得,改进算法在分类性能方面明显优于传统SVM,即柔性地距离边缘适合在重叠且不平衡类分布的区域预测稀有样本. 本文展示了一种新的SVM二次优化模型,通过改变特征空间中决策边界到边缘的距离改良边缘的性能.自适应的边缘模型可以在训练复杂数据集方面显示良好的分类性能.现实生活中往往存在这样的规律,少数类的正确分类要比多数类的正确分类更有价值.因此,本文所提方法才显示出其应用的潜力.未来的工作是将本方法应用到更多现实生活中存在不平衡和重叠性的数据集中,并根据应用情况调整算法细节. [1] Vapnik V.The nature of statistical learning theory[M].New York:Springer Verlag,1995:142-165. [2] Tan P N,Steinbach M,Kumar V.Introduction to data mining[M].New Jersey:Addison Wesley,2005:115-131. [3] Zhao H,Chen H,Nguyen T.Stratified over-sampling bagging method for random forests on imbalanced data[M].Switzerland:Springer International Publishing,2016:46-60. [4] Vluymans S,Tarragó D S,Saeys Y.Fuzzy rough classifiers for class imbalanced multi-instance data[J].Pattern Recognition,2016,53:36-45. [5] Liu Alexander,Ghosh J,Martin C.Generative oversampling for mining imbalanced datasets[C]∥Proceedings of 2007 International Conference on Data Mining .Las Vegas,Nevada,USA :CSREA Press,2007:66-72. [6] Wu G,Chang E Y.KBA:Kernel boundary alignment considering imbalanced data distribution[J].IEEE Transactions on Knowledge and Data Engineering,2005,17:786-794. [7] 徐小凤,刘家芬,郑宇卫. 基于密度的空间数据聚类的正常用户筛选方法[J].计算机应用,2015,35(S1):43-46. [8] Trafalis T B,Gilbert R C.Robust classification and regression using support vector machines[J].European Journal of Operational Research,2006,173(3):893-909. [9] Trafalis T B,Gilbert R C.Robust support vector machines for classification and computational issues[J].Optimization Methods and Software,2007,22:187-198. [10] Song Q,Hu W,Xie W.Robust support vector machine with bullet hole image classification[J].IEEE Transactions on Systems Man and Cybernetics Part C (Applications and Reviews) ,2002,32:440-448. [11] Mollineda R A,Snchez J S,Sotoca J M.Data characterization for effective prototype selection[J].Iberian Conference on Pattern Recognition & Image Analysis,2005,523(20):295-302. [12] Ho T K,Basu M.Complexity measures of supervised classification problems[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2002,24(3):289-300. 【责任编辑:蒋亚儒】 Research on an improved support vector machine model GUO Chen-chen, ZHU Hong-kang* (School of Mathematics and Computer Science, Shanxi Normal University, Linfen 041000, China) Traditional support vector machines can not sufficiently and effectively detect the instance of the minority class in the overlap region and can not make a reasonable classification of the imbalanced data sets.However,the overlapping and imbalanced of the classes are common in complicated data sets.As a result,they have a negative impact on the classification performance of support vector machines.Based on this,an improved model is proposed to replace the slack variables of support vector machine based on distance measure.To a certain extent,it solves the problem that the support vector machine is dealing the overlapping and imbalanced of the classes in complicated data sets.Finally,the advanced nature of the algorithm is verified by the experimental results of the data set in the synthetic data set and the UCL database. support vector machine; overlapping; imbalanced; slack variable; distance measure 2017-01-16 基金项目:山西省自然科学基金项目(2015011040) 郭晨晨(1992-),男,山西长治人,在读硕士研究生,研究方向:计算机应用 朱红康(1975-),男,山西汾西人,副教授,博士,研究方向:数据挖掘,zhuhkyx@126.com 1000-5811(2017)02-0189-06 TP18 A


2 性能测试


3 实验





4 结论
