基于商业大数据的客户分类方案
2017-04-04李伟秦鹏胡广勤张毓福
李伟 秦鹏 胡广勤 张毓福
(六盘水师范学院数学与信息工程学院,贵州六盘水553001)
随着信息和网络技术的发展,人们已经进入了Web 2.0时代,导致数据量呈现爆炸式增长。在商业活动中企业营销焦点已经从以产品为中心转变为以客户为中心,客户关系管理成为企业的核心问题。客户关系管理的关键问题是客户分类,客户分类可以区分无价值客户和高价值客户。企业对待不同价值的客户制定个性化服务方案,采取不同营销策略,将有限的资源集中于高价值客户,提高经营效率。精确的客户分类结果是企业优化营销资源分配的重要依据,客户分类变得越来越必要。
Hughes提出了RFM模型(Hughes A,1994),以客户最近一次消费距现在的时间长度R、消费次数F、消费金额M三个变量来描述客户的特征及对客户进行分类。国内学者基于传统RFM模型变量含义的质疑,提出了修正的多指标RFM模型(曾小青等,2013)。同时,传统的客户端服务器结构处理商业大数据,进行客户分类的效率很低。近两年大数据技术在互联网、金融、物流领域的发展迅速,体现出极高的社会价值(李国杰和程学旗,2012),大数据分析技术已经成为数据挖掘领域重要趋势。本研究基于大数据技术,探讨在Hadoop平台上使用Hive和R分析处理商业数据,进行客户分类。
1 关键技术
Hadoop是Apache基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop的核心是分布式文件系统HDFS和并行计算框架MapReduce(J.Cohen,2009)。HDFS是一个高度容错性的系统(Chuck Lam,2010),提供高吞吐量的数据访问,适合大规模数据集上的应用,实现了以流的形式访问文件系统中的数据。HDFS以其高可靠性和高扩展性,尤其适合部署在商业计算机组成的集群上。
Hive是基于Hadoop的一个数据仓库工具,可以查询和分析存储在Hadoop中的大规模数据。Hive定义了类SQL查询语言(HQL),通过HQL语句可以快速实现MapReduce统计,十分适合数据仓库的统计分析。
R是一个开源的数据分析软件(Luis Torgo,2010),被科学家和数据分析师用于数据分析、数据可视化和预测建模。它允许以完全的、交互的和面向对象的方式编写脚本和函数。数据挖掘的结果可以使用R进行高效的可视化展现。
Hadoop平台存储数据,Hive分析统计数据,R则对数据进行聚类可视化。通过结合Hadoop、Hive和R来实现并行处理商业大数据,进行客户分类。
2 设计思想
随着大数据时代的来临和数据挖掘技术的发展,客户的数据量日益增多,传统的客户分类方法分类的实际效果和效率并不理想。因此,研究基于Hadoop平台,采用Hive对商业大数据进行统计分析,并在R中使用K-Means算法提高客户分类效果。
客户分类是根据客户的属性特征将客户划分为不同群体的过程。客户分类的目的是识别客户价值,即通过商业大数据识别不同价值用户。识别客户价值应用最广泛的是RFM模型,该模型有三个指标:最近消费时间间隔(recency)、消费频率(frequency)、消费金额(monetary)。
在企业拥有一个包含客户详细信息和消费记录信息大数据集的前提下,通过删除不适用的值与空值的方法来清洗数据,并把处理好的数据存储到HDFS中。在Hadoop平台上使用Hive预处理数据,从中抽取客户ID、消费时间和消费金额三个字段。以客户ID作为分类字段,将客户的消费金额汇总得到客户消费总金额;对客户ID进行计数,得到客户消费次数;根据客户最后一次消费时间,计算得到客户消费间隔。由于客户消费总金额与消费次数存在较重的共线性(Senthamarai,2007),因此通过使用消费平均金额代替消费总额来修正。
3 实现过程
实验以公司交易模拟数据作为研究对象,以其客户的消费数据作为依据,对客户进行分类,来识别客户的价值。客户分类系统架构如图1所示,其实现要经过3个过程:数据预处理、数据统计分析和数据聚类可视化。
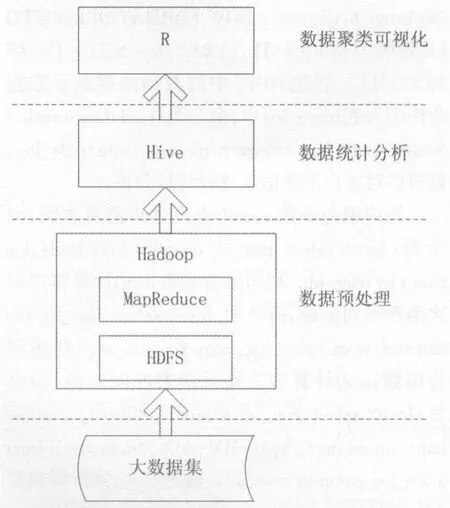
图1 客户分类系统架构
3.1 数据预处理
在数据预处理开始之前要选取最近一段时间的商业交易数据,只有最新的数据才有分析的价值。由于真实的商业交易数据是多样高维的,在数据原始的高维空间中,包含有冗余信息和噪音信息,这就会造成误差,降低分析结果的准确率,因此还要对原始数据进行降维。这里将采用PCA算法,通过线性投影将高维的数据映射到低维的空间中表示,使在投影的维度上数据的方差尽量大,在保留较多数据点特性的同时使用较少的数据维度。基于PCA算法将所有数据都投影到用户ID、消费金额和消费时间这三个维度,从而实现异构商业数据的同构化。最后,将预处理后的最近一段时间的交易大数据集上传到分布式文件系统HDFS中进行存储,其Shell命令为:./bin/hdfs dfs–put~/trade_log.csv/dataset。
3.2 数据统计分析
Hive是基于Hadoop的数据仓库,使用HQL编写的查询语句,会被Hive自动解析成MapReduce任务由Hadoop来执行,因此要先启动Hadoop再启动Hive。在Hive中创建一个数据库test,命令为:hive> create database db_test;hive> use db_test。在数据库db_test中创建一个表trade_log,包含字段(user_id,trade_day,amount),命 令 为 :hive>create table db_test.trade_log (user_id INT,trade_dayDATE,amountFLOAT)COMMENT'Welcome to db_test!'ROW FORMAT DELIMITED FIELDSTERMINATED BY ' 'STORED AS TEXTFILE。再把HDFS中的数据加载到了数据仓库的大表trade_log中,命令为:load data inpath'/dataset/trade_log.csv'overwrite into table trade_log,就可以对客户消费信息进行统计分析。
利用聚合函数count()查询客户消费次数,命令为:hive> select user_id,count(*)from trade_log group by user_id。利用聚合函数avg()计算客户每次消费平均金额,命令为:hive>select user_id,avg(amount)from trade_log group by user_id。利用聚合函数min()计算客户最近消费时间间隔,命令为:hive> select user_id,min(datediff(from_unixtime(unix_timestamp(),'yyyy-MM-dd'),trade_day))from trade_log group by user_id。通过Hive分析得到客户分析的结果,最后将该结果利用R进行聚类分析可视化。
3.3 数据聚类可视化
R是用于统计分析和统计制图的优秀工具,可以与Hive等数据分析软件结合起来使用,在R中使用K-Means聚类算法进行客户分析。其中K-Means算法公式为:
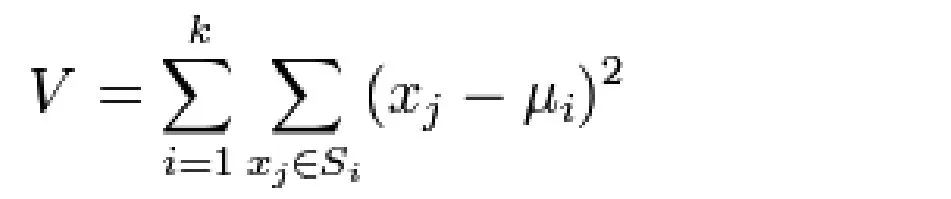
K-Means算法是基于距离的聚类算法,采用距离作为客户相似性的评价指标,即两个客户的距离越近,其相似度越大。该算法首先随机选取任意k个客户作为初始聚类的中心,然后每次迭代对Hive分析后数据集中剩余的每个客户进行聚类,直到该算法收敛。
4 实验分析
客户分类的3个指标通过R可视化的箱尾图(肖楠,2014)如图2、图3和图4所示,展示了客户消费次数、客户平均消费金额和客户最近消费时间间隔的连续值的分布情况,并给出了三个变量统计信息,通过该图明显可得出变量中的异常值。

图2 客户消费次数指标箱尾图 图3客户平均消费金额指标箱尾图 图4客户最近消费时间间隔指标箱尾图
在数据预处理之后,数据会被使用K-Means算法在R中进行客户聚类。再在R终端执行如下关键命令:
result$Species<-NULL;#对训练数据去掉分类标记
kc<-kmeans(result,3);#分类模型训练
plot(result[c("消费次数","消费平均金额")],col=kc$cluster);#聚类结果可视化
points(kc$centers[,c("消费次数","消费平均金额")],col=1:3);#不同的颜色代表不同的聚类结果。
客户消费次数和消费平均年龄的K-Means客户分类结果可视化图如图5所示,实验结果主要分为三类客户。第一类客户:客户数量比较少,消费次数较多,平均消费金额较高,并且最近一段时间有过消费。第二类客户:客户数量较多,或者消费次数多,或者消费平均金额高,数量达到了客户总量的一半。第三类客户:消费次数少,并且消费平均金额低。第一类客户是公司最有价值的客户,公司应该给其分配更多的资源。第二类客户是公司最应该发展的客户,应向其推荐针对性的产品,来促进他们的消费。第三类客户价值最低,公司应减少对其资源的分配。

图5 K-Means客户分类结果可视化图
5 结语
本文研究了基于商业大数据的客户分类,以解决传统的客户分类方式在处理商业大数据后变得低效的问题。提出了一种使用Hadoop作为商业大数据的存储处理平台,利用Hive提取有用信息,利用R可视化结果的解决方案,并且在实验分析时选择K-Means算法进行聚类来提高客户分类效果。同时也存在不足之处,实验的数据为模拟数据,在以后的研究中使用真实的数据来完善研究方法。
参考文献:
李国杰,程学旗.2012.大数据的研究现状与科学思考[J].战略与决策研究,27(6):647-656.
肖楠.2014.R数据可视化手册[M].北京:人民邮电出版社.
曾小青,徐秦,张丹.2013.基于消费数据挖掘的多指标客户细分新方法[J].计算机应用研究,(10):2944-2947.
Chuck Lam.2010.Hadoop in Action[M].Manning Publications.
J.Cohen.2009.Graph Twiddling in a MapReduce World[J].Computing in Science&Engineering,(6):63-69.
Hughes A.1994.Strategic database marketing:the masterplan for starting and managing a profitable,customer based marketing program[M].Irwin Professional,85-90.
Luis Torgo.2010.Data Mining with R[M].Chapman and Hall.
Senthamarai.2007.Automated Classification of Customer Emails via Association Rule Mining[J].Information Technology Journal,(3):81-86.
