一种支持Superscalar-VLIW混合架构处理器的混合分支预测设计
2017-02-27付家为
付家为 王 旭 何 虎
(清华大学微电子学研究所 北京 100084)
一种支持Superscalar-VLIW混合架构处理器的混合分支预测设计
付家为 王 旭 何 虎
(清华大学微电子学研究所 北京 100084)
描述在一款支持超标量与超长指令字结构的混合架构数字信号处理器上设计的分支预测结构。为控制硬件复杂度并充分提高预测准确度,设计双峰预测器与PAp预测器混合型预测结构,充分发挥两种预测器的优点。在设计完成的处理器上,运行标准DSPstone程序。实验结果表明,添加分支预测结构使得处理器性能平均提升23%,并且混合型预测结构相比单一预测结构在准确度方面优势明显。
数字信号处理器 超标量 超长指令字 分支预测 双峰预测 PAp
0 引 言
数字信号处理器(DSP)已经越来越多地应用于通信及多媒体信号处理领域,随着如视频、音频、图像等多媒体应用越来越复杂多样,对处理器性能的要求也越来越高[1]。提高指令并行度(ILP)是提高处理器性能的重要手段。超标量(Superscalar)与超长指令字(VLIW)技术作为挖掘指令并行度的重要手段,分别在硬件层面与软件层面对指令并行进行调度。Superscalar技术由硬件决定指令并行性[2],硬件复杂度较高,对于编译器要求较低,软件可移植性较强[3];VLIW技术由软件调度指令并行性,大大降低了硬件复杂度,但随之而来的代价是软件复杂度的增大以及寄存器和功能单元数目的增加[4],而且VLIW处理器程序兼容性也较低。为充分利用两种技术的优势,本设计处理器采用Superscalar与VLIW混合架构,对于运算密集重复性较高的程序,采用VLIW模式执行,提高指令并行度以提高执行效率,其他部分程序采用Superscalar模式执行,确保程序可移植性。
现代高性能处理器中多数采用流水线技术,采用流水线技术随之而来的问题就是跳转指令所带来的周期损失,尤其对于深度流水线结构处理器更是明显。所以成熟精准的分支预测设计对于处理器性能的提升不言而喻。现阶段常用的分支预测技术主要分为静态分支预测与动态分支预测。对于静态分支预测,程序中每次遇到跳转指令,都对其进行固定的预测,静态分支预测准确率较低。动态分支预测在每次遇到跳转指令时,通过关联之前的跳转信息,对不同的跳转指令进行不同的预测,并实时更新跳转信息[5]。
动态分支预测中,广泛使用的方法主要有双峰预测与两级自适应预测,近年来各种改进型预测器如神经网络型预测器也是相继被提出。较成熟的双峰预测与两级自适应预测各有利弊[6],其中两级自适应预测中常被使用到的方法包括PAp、GAg、GAs、Gshare等。双峰预测器的优势在于硬件结构简单,预测稳定性高,训练时间短,但准确率较低;两级自适应预测器的准确率较高,但是硬件逻辑较为复杂,增加了面积功耗的额外开销。
现有技术中,动态分支预测已在Superscalar结构上充分利用,而VLIW结构的分支预测功能多采用静态预测,由软件调度。事实上,大多数VLIW结构使用延迟跳转技术[7],这大大增加了编译器的负担,尤其对于VLIW结构单周期多发射指令编译,编译器为填满延迟槽大大增加了软件负担[8]。所以,为VLIW结构设计动态分支预测方法具有重要的意义。
本文提出支持Superscalar与VLIW双模式架构处理器的动态分支预测方法,预测设计采用双峰预测与PAp预测混合结构,对于不同跳转指令使用不同的预测方法,充分发挥两种预测器的优势。实验结果表明,使用混合结构预测器比单独结构预测器性能优势明显,并使处理器整体性能得到很大提升。
1 Orchid结构
1.1 Orchid硬件结构
本设计在清华大学DSP实验室自主开发的Orchid处理器上完成,Orchid是一款兼容ARM指令集的通用处理器,采用Superscalar-VLIW混合结构,整体分为程序存储器、数据存储器、指令获取模块、指令分发模块、执行模块以及寄存器堆模块,如图1所示,是Orchid处理器的整体硬件结构。
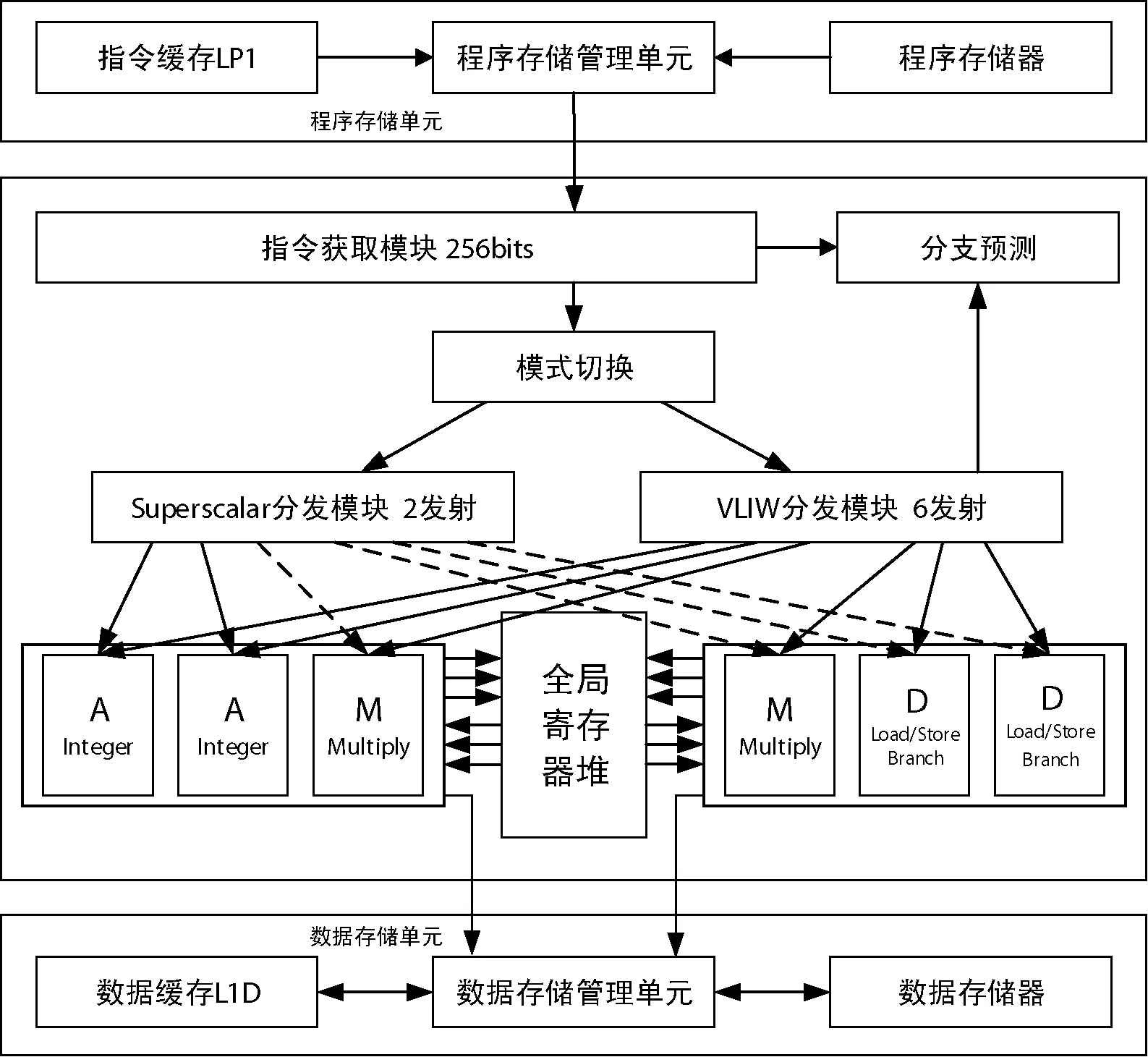
图1 Orchid整体结构图
指令获取模块每次从程序存储器中获取256位的指令包,包含16位与32位混编指令。分发单元可以工作在两种分发模式下,Superscalar模式和VLIW模式,由软件实现模式切换,Superscalar模式支持最多2发射,VLIW模式支持最多6发射。经过将指令包中的指令扩展、分发后,分配到相应的执行单元进行指令执行。为更好地兼容ARM指令集,Orchid的寄存器堆采用与ARM架构相应的15个通用寄存器。
Orchid功能单元分为两个A单元,两个M单元,两个D单元,最多支持六条指令并行执行。其中A单元用于算术逻辑运算以及移位运算,M单元用于乘法运算,D单元用于存储器的存取以及实现程序的跳转。
1.2 Orchid流水线结构
Orchid流水线设计为十级流水线结构,主要分为Fetch_PG、Fetch_PS、Fetch_WT、Fetch_IR、Fetch_EXP、Dispatch、Decode、Exe1、Exe2、Exe3,如图2所示。流水线各级功能如下:
Fetch_PG:分支预测以及产生PC地址。
Fetch_PS:将产生的PC地址传递给指令cache控制单元。
Fetch_WT:等待指令cache控制单元读取指令。
Fetch_IR:从指令cache控制单元读取指令。
Fetch_EXP:将16位于32位指令统一扩展成32位指令,每6条指令形成一个扩展包。
Dispatch:执行指令并行分发策略,将具有并行性的指令同时分发到各个功能单元。对于Superscalar模式,最多并行发射2条指令,并行分发原则是判断两条指令是否有依赖关系以及执行单元是否冲突;对于VLIW模式,最多并行发射6条执行,并行分发原则是按照指令执行单元顺序。
Decode:指令解码。
Exe1~Exe3:执行级,完成指令执行其中Exe1完成单周期执行指令,Exe2与Exe3完成多周期执行指令。

图2 Orchid流水线结构图
2 Orchid双模式分支预测设计
2.1 Orchid 双峰-PAp混合预测器结构
本设计采用了双峰预测器与PAp预测器结合的混合预测结构,对于不同的跳转指令采用不同的预测机制,充分发挥两种预测器的优势。
分支预测的原理是在Fetch_PG级,通过PC地址索引BTB表查找跳转信息,如果查到了跳转指令的信息,则按照跳转信息进行跳转操作。在执行级判断预测是否正确,如果预测正确,则按照预测结果继续执行,如果预测错误,则清空流水线,从正确位置重新执行并对BTB表中存储的跳转信息进行修改。分支预测原理如图3所示。
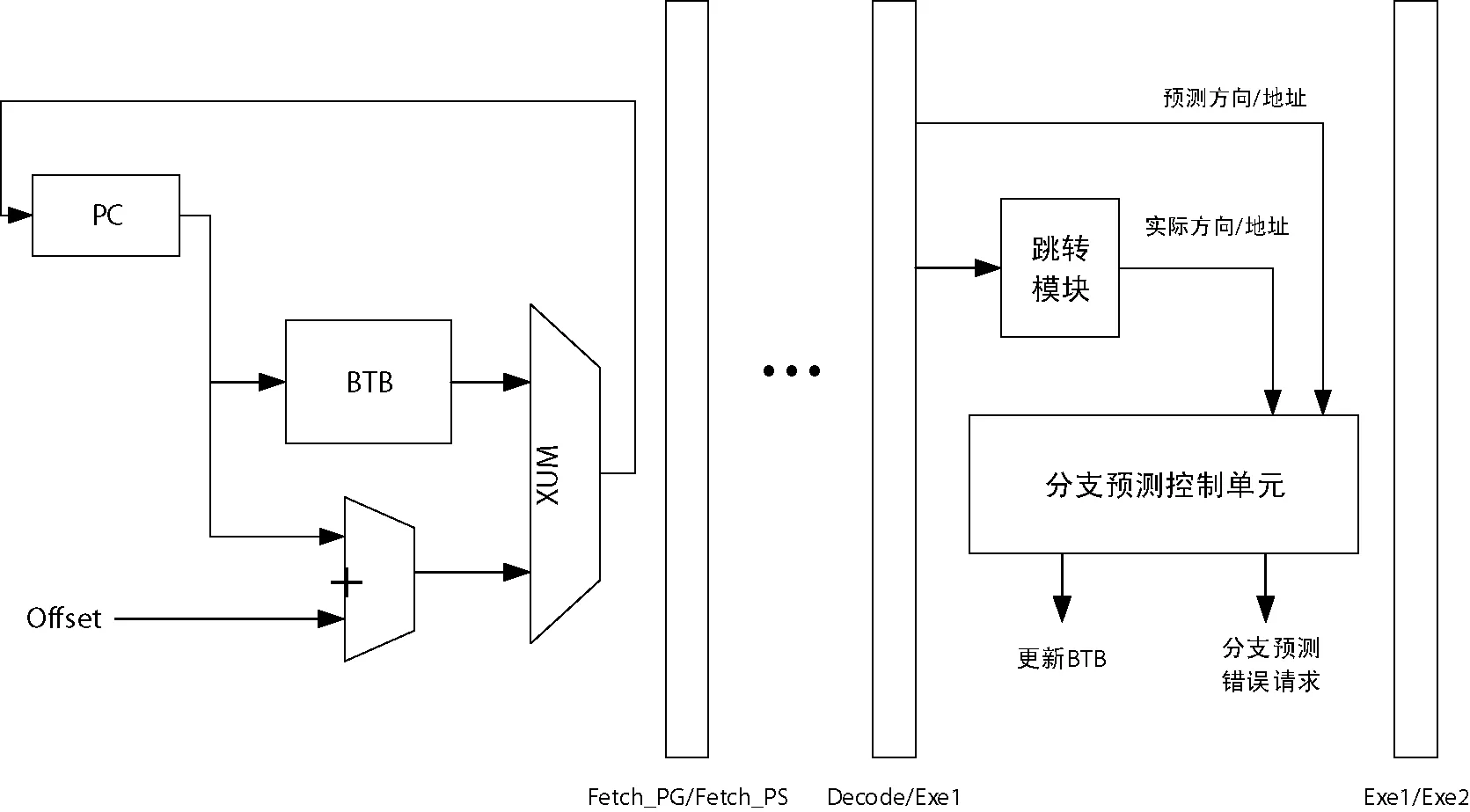
图3 分支预测原理图
双峰预测器的核心技术是分支目标缓存表(BTB),BTB表是一块SRAM,里面存储着各条跳转指令的跳转信息,由PC进行索引。双峰预测BTB表的每个表项存储四部分信息:跳转指令地址BIA(Branch Instruction Address)、跳转目标地址BTA(Branch Target Address)、跳转指令下一个执行包地址NDA(Next Dispatch_packet Addrees)以及分支历史信息BHI(Branch History Information),如图4所示。其中BIA用于索引BTB表项,BTA是跳转目标地址,BHI存储是否跳转,NDA是预测错误后重新执行的地址。跳转指令第一次执行时,将其相应信息存入BTB表中,当此跳转指令再次执行时,通过PC索引BTB表读取跳转信息进行预测,按照预测信息执行,在执行级判断预测是否准确,如果预测错误,则用正确的跳转信息改写BTB表。
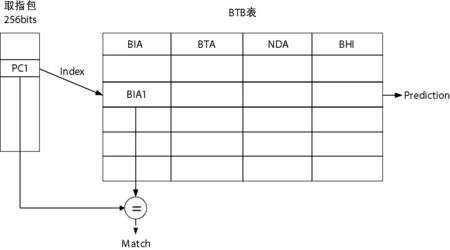
图4 双峰预测器BTB表示意图
PAp预测器的BTB表在双峰预测器的基础上增加了跳转历史寄存器BHR(Branch History Register),通过PC索引BTB表项,由BHR索引模式表(Pattern Table),对应模式表中设计一个计数器,每个计数值记录一次跳转指令的跳转方向。这样对于条件执行的跳转指令,可以准确预测出每次的跳转方向,即准确预测出哪一次跳转,哪一次不跳转。PAp预测器BTB表如图5所示。
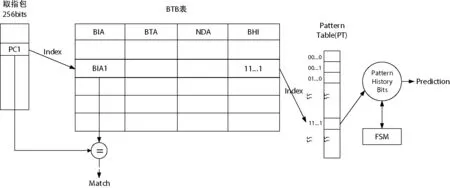
图5 PAp预测器BTB表示意图
双峰预测器的优势在于逻辑结构简单,面积、功耗较小,并且正确预测之前所需的训练次数少,训练完成后预测稳定性高,但是对于条件执行的跳转指令,只能预测出一种跳转方向,预测命中率较低;PAp预测器的优势在于可以准确预测出跳转指令的不同跳转方向,预测命中率较高,但是逻辑结构较复杂,随之带来了面积、功耗的增加,同时,需要为每次不同跳转方向建立对应的模式表表项,即建立完整跳转指令信息的BTB表项时间较长,且BTB表较大增加额外存储资源负担。将建立完整跳转指令信息BTB表项的时间称为预测训练时间,PAp预测器的训练时间是双峰预测器的数倍甚至数十倍,后文将介绍缩短训练时间的方法。为更好地利用两种预测器的优势,本设计采用一种混合的分支预测机制:对于非条件执行的跳转指令,其只有一种跳转方向,所以采用双峰预测器,降低面积、功耗与训练时间,减少存储资源负担;对于条件执行的跳转指令,其存在两种跳转方向,采用PAp预测器进行预测,提高预测命中率。
2.2 Superscalar-VLIW双模式下分支预测技术
本设计中,包的概念十分重要,在整个流水线设计过程中,指令是以包的形式存在的,即取指包、扩展包、分发包。取指包是指令获取单元从程序存储器中读取的256位数据包,包含16位与32位指令;扩展包在Fetch_EXP级生成,将16位指令与32位指令统一扩展成32位,每6条指令形成一个扩展包,即192位;分发包在Dispatch级生成,根据分发策略,将并行执行的指令装载在一个分发包中。
分支预测是在Fetch_PG级进行的,从BTB表中读出BIA、BTA、NDA、BHI、PT等预测信息,在Exe1级要对预测信息进行判断是否正确,所以预测信息需要随着跳转指令一起沿流水线逐级传递下去,因为跳转指令是以包的形式逐级传递的,所以预测信息也要与相应的包一起逐级传递。确定预测信息与某个包中的跳转指令对应的原则是判断预测信息中的BIA是否与包中的跳转指令PC对应。对于Superscalar模式,最多2发射,即BIA与2条指令作比较;但对于VLIW模式,最多6发射,BIA需要与6条指令分别对照,所需逻辑复杂,所以存入VLIW模式存入BTB表项中的BIA并不是跳转指令的PC,而是跳转指令所在分发包的首地址,这样只需要将BIA与分发包首地址做比较即可,逻辑较为简单。
Superscalar与VLIW模式下分支预测另一个不同点是,Superscalar模式下,跳转指令后面一条指令不能与跳转指令并行发射,而VLIW模式下,跳转指令后面指令如果没有执行单元冲突,则可与跳转指令并行发射。NDA表示预测错误后正确的执行地址,对于Superscalar模式,NDA为跳转指令后面一条指令的地址,而对于VLIW模式,NDA为跳转指令所在分发包的下一个分发包的首地址。如图6所示,是取指包中Superscalar与VLIW模式下BIA与NDA位置示意图,其中Dp_package1与Dp_package2是两个分发包,即Dp_package1中指令并行发射,Dp_package2中指令并行发射。

图6 取指包中Superscalar与VLIW模式下BIA与NDA位置示意图
2.3 分支预测的技术改进
对于PAp预测器,虽然其预测命中率较高,但是存在训练时间较长的缺点,所以降低训练时间对于提高分支预测器性能至关重要。动态的基于历史信息的跳转方向预测方法可使用有限状态机来描述,图7(a)表示预测方向状态机示意图。状态机由四个状态组成,每个状态有2 bit信息组成,代表最近两次跳转方向。状态机中状态存在BTB表的BHI中,代表跳转方向,00、01表示不跳,10、11表示跳。BHI的初始状态为00。对于训练一条方向为跳转的跳转指令,需要两次训练,第三次才能正确预测,对于PAp预测器,每个PT模式状态都需要两次训练,如果循环为for(i=0,i<10,i++)这种10次的循环,训练次数至少为20次,这将付出相当大的代价。本设计对有限状态机做改进,改进的状态机如图7(b)所示,00表示不跳,10、11表示跳,从不跳到跳只需1次训练,将原有训练时间减半。

图7 有限状态机
改进后的PAp训练时间减半,但是对于循环次数较多的跳转指令,需要对每个PT模式状态都进行训练,如果循环为for(i=0,i<10,i++)这种10次的循环,训练次数至少为10次,训练代价依然很大,所以对PT模式表中对应的BHI值训练方法进行改进。第一次训练时,不仅仅对PT模式计数器中计数为000项的BHI值进行更改,对所有计数项的BHI都做000项的更改,也就是将所有项都置成跳转方向,这样只需要对不跳转的一项即最后一项进行训练即可,通过此改进方法,训练项仅为第一项与最后一项,大大缩短了训练次数。
Fetch_PG级还未对指令进行解码,通过PC索引BTB表的方法是对取指包中的每条指令进行遍历,看BTB表中是否有与之对应的表项,如果查到对应的表项,说明该指令是跳转指令,并取出跳转信息进行预测,每个包遍历一次得到一组跳转信息。存在一种情况是一个取指包中包含两条跳转指令,第一条跳转指令方向为不跳,第二条跳转指令要执行。 但是这个取指包中只能取出第一条跳转指令的跳转信息,而得不到第二条跳转指令的跳转信息,因此需要多加入一套跳转信息。即在遍历到一条方向为不跳的跳转指令后在取值包中继续遍历,如果又遍历到跳转指令则取出第二套跳转信息,与第一套跳转信息共同完成预测并一起沿流水线逐级传递并在Exe1级进行分支预测正确性的判断。
PT模式表计数器的计数规则为每次遇到跳转指令,对BTB表中对应表项的PT模式表计数器加1,遇到跳转指令方向为不跳或预测错误需要清空流水线时,BTB表对应项PT模式表计数器归零。由于预测是在Fetch_PG级进行的,PT模式表计数也要发生在Fetch_PG级,计数原则是在取指包中遍历指令,如果发现跳转指令,则对其相应的PT模式表计数器加1。在预测错误需要清空流水线的情况下,对预测错误的跳转指令PT表计数器归零,但是存在一种情况,即在Fetch_PG级,按照预测信息执行的指令中有其他跳转指令,它们的PT表计数器也发生了改变,而预测错误的跳转指令后面执行的跳转指令本不该执行,它们的PT表计数器也不应该发生变化。如图8所示的一段程序,指令B1预测方向为不跳转,但实际方向为跳转,固B2、B3两条跳转指令本不该执行,但根据预测信息,这两条指令在B1到达Exe1级之前执行,B2、B3的PT表计数器发生了不该有的变化。本设计考虑到了预测错误的跳转指令,让它们的PT表计数器恢复到正确的计数值,即对于图8所示的程序,当B1后流水线清空后,B2与B3的PT表计数器恢复到了正确的计数值。

图8 跳转示例程序
PT模式表的计数器位数同样决定了PAp预测器预测的准确率。当计数器为3位时,计数范围是0~7,对于循环次数大于8的跳转指令,则无法记录每次跳转方向,所以增加计数器位数可有效提高预测的命中率。但是增加计数器位数又会增大面积与功耗,所以计数器位数的选择应为命中率与面积功耗折中的结果。
3 性能评测
3.1 对2.3节分支预测技术改进性能指标评测
本实验采用DSPstone基准程序对处理器及分支预测部分性能进行评估。表1对2.3节分支预测技术改进前后预测准确率进行对比,由表中可以看出,改进后分支预测命中率较改进前均有明显提升,即对于混合预测器,预测训练时间较改进前大大减少,命中率最高可以提升32%,命中率平均提升23%。

表1 改进分支预测器预测命中率比较
3.2 混合预测器与单一预测器以及不采用分支预测器性能比较
表2是在Superscalar模式与Superscalar-VLIW混合模式下混合预测器与单一预测器及无分支预测器性能预测命中率的比较。由表中可以看出,对于单独Superscalar模式与Superscalar-VLIW混合模式,分支预测均适用,并且两种模式下分支预测准确率相近。混合模式分支预测器命中率相比无分支预测器和单一双峰预测器都有非常明显提升,命中率最高可达到近99%,并且对于类似fir2dim、matrix2、matrix1这样较大的程序,混合预测器命中率提升更为明显并且准确率更高,原因在于,对于小程序,跳转指令数目较少并且训练时间所占比例较大,所以准确率和优化空间有限。
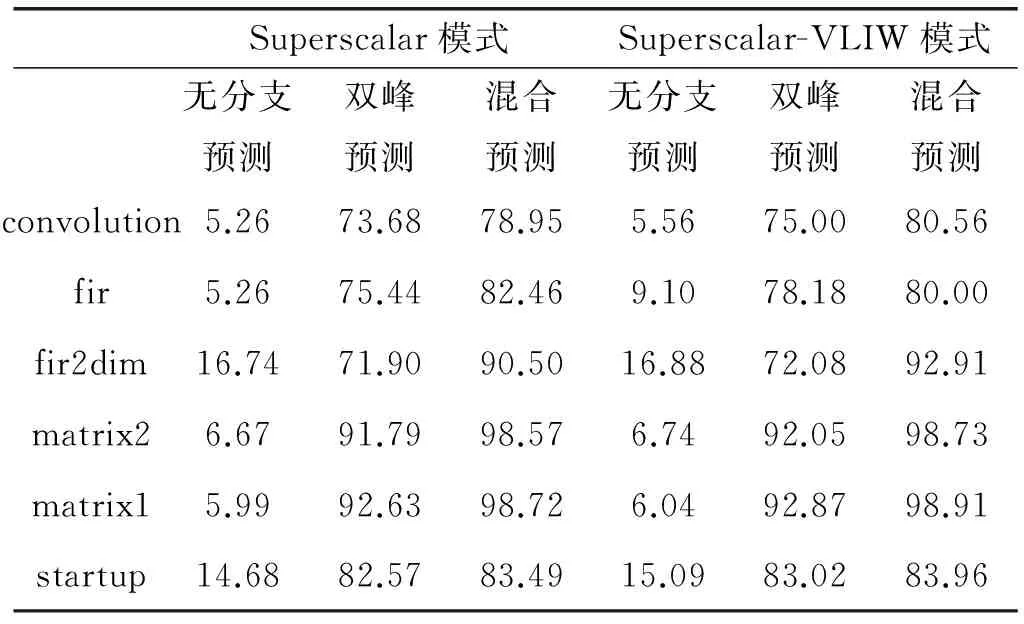
表2 混合预测器与单一预测器及 无分支预测器性能预测命中率比较 %
表3是混合预测器与双峰预测器相比无分支预测器运行时间提升的比较,可以看出,混合预测器与双峰预测器对于程序运行时间提升明显,并且混合预测器相比单一双峰预测器运行时间也都有明显提升,最高提升达38%。
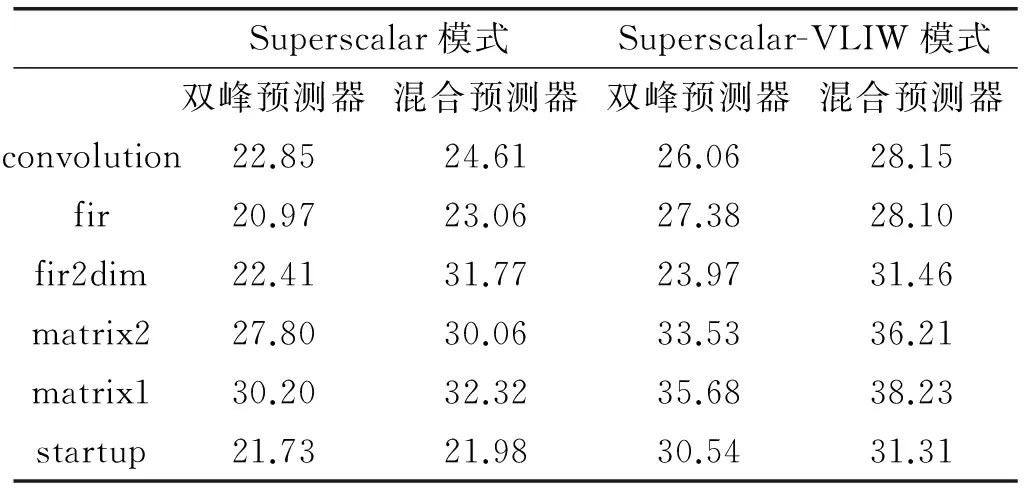
表3 混合预测器与双峰预测器相比 无分支预测器运行时间提升比较 %
3.3 综合报告
表4是使用xilinx vivado综合工具,选择XC7K-325T FPGA综合得到的结果,处理器内核的存储资源没有进行综合,目的在于更直观地对比分支预测部分的存储资源占用量。由表中可以看出,双峰与PAp混合预测器逻辑资源与寄存器数量占整个处理器的比例较小。混合预测器比单一的双峰预测器逻辑资源增加了48%左右,寄存器数量增加近40%,存储资源几乎没有增加;相比选用单一的PAp预测器,逻辑资源减小了一半,寄存器数目大大减少。由此可以看出,相比单一双峰预测器,混合预测器只增加了少量硬件开销,但占处理器内核比例依旧很小;相比单一的PAp预测器,混合预测器大大降低了硬件复杂度。由此可见,混合预测器以较小的硬件代价换取了处理器性能的很大提升,混合型预测器是处理器性能和硬件开销折中考虑的最优选择。

表4 综合报告
4 结 语
本文提出一种支持Superscalar-VLIW混合架构处理器的分支预测方法,在两种模式下均可以进行分支预测,预测机制采用双峰预测与PAp预测相结合,充分利用二者在预测稳定性、硬件结构以及预测准确率方面的优势。实验结果表明,该分支预测方法在Superscalar与VLIW两种模式下进行分支预测的效果相同,并且得到了较高的预测准确率,占用硬件资源较少,处理器性能得到了较大的提升。
[1] Lee J,Youn J M,Cho D,et al.Reducing instruction bit-width for low-power VLIW architectures[J].Acm Transactions on Design Automation of Electronic Systems,2013,18(2):99-109.
[2] Moon S M,Ebcioglu K.An Efficient Resource-constrained Global Scheduling Technique For Superscalar And Vliw Processors[J].Acm Sigmicro Newsletter,1993,23(23):55-71.
[3] Steven G,Christianson B,Collins R,et al.A superscalar architecture to exploit instruction level parallelism[J].Microprocessors & Microsystems,1997,20(96):391-400.
[4] 沈钲,何虎,杨旭,等.Architecture Design of a Variable Length Instruction Set VLIW DSP[J].Tsinghua Science & Technology,2009,14(5):561-569.
[5] Palermo G,Sam M,Silvan C,et al.Branch prediction techniques for low-power VLIW processors[C]//Proceedings of the 13th ACM Great Lakes symposium on VLSI.ACM,2003:225-228.
[6] Yeh T Y,Patt Y N.Two-Level Adaptive Training Branch Prediction[C]//24th ACM/IEEE International Symposium on Micro architecture.1991:1028-1073.
[7] Patterson D A,Hennessy J L.Computer Architecture:A Quantitative Approach[M].2nd ed.Morgan Kaufmann,San Mateo,CA,1996.
[8] Hoogerbrugge J.Dynamic branch prediction for a VLIW processor[C]//International Conference on Parallel Architectures & Compilation Techniques,2000:207-214.
[9] Faravelon A,Fournel N,Pétrot F.Fast and accurate branch predictor simulation[C]//Design,Automation & Test in Europe Conference & Exhibition (DATE),2015.IEEE,2015:317-320.
[10] Zhou P,Nder S,Carr S.Fast branch misprediction recovery in out-of-order superscalar processors[C]//Proceedings of the 19th annual international conference on Supercomputing.ACM,2005:41-50.
[11] Eden A N,Mudge T.The YAGS branch prediction scheme[C]//Microarchitecture,1998.MICRO-31.Proceedings.31st Annual ACM/IEEE International Symposium on.IEEE,1998:69-77.
[12] 谢子超,佟冬,黄明凯.A General Low-Cost Indirect Branch Prediction Using Target Address Pointers[J].Journal of Computer Science & Technology,2014,29(6):929-946.
[13] 肖泽强.动态分支预测技术分析与量化研究[J].信息技术,2011(3):80-82.
[14] 张筱,史战果,吴迪.基于SimpleScalar的动态分支预测器研究[J].微型电脑应用,2011,27(11):19-21.
[15] 顾慧,龚育昌,赵振西.超长指令字技术[J].小型微型计算机系统,2000,21(2):174-177.
A DESIGN OF HYBRID BRANCH PREDICTOR SUPPORTING SUPERSCALAR-VLIW HYBRID MICROPROCESSOR
Fu Jiawei Wang Xu He Hu
(InstituteofMicroelectronics,TsinghuaUniversity,Beijing100084,China)
A design of hybrid branch predictor on a digital signal processor which supports Superscalar-VLIW hybrid architecture is described. To control hardware complexity and improve the accuracy of prediction, a hybrid branch predictor of bimodal and PAp is selected for the branch prediction scheme. The standard DSPstone programs have been run on the processor. The experimental results show that the processor with hybrid branch predictor has an improvement of 23% on average compared with processor without branch predictor, and processor with hybrid branch predictor predicts more accurately than processor with only bimodal predictor.
Digital signal processor Superscalar VLIW Branch prediction Bimodal prediction PAp
2016-01-12。核高基重大专项基金项目(2012ZX01034001-002)。付家为,硕士生,主研领域:微处理器架构设计。王旭,硕士生。何虎,副教授。
TP303
A
10.3969/j.issn.1000-386x.2017.02.018
