医学影像云存储模型的研究与设计
2017-02-27齐来军周丽娟任仲山
齐来军 周丽娟* 任仲山,3
1(首都师范大学信息工程学院 北京 100048)2(成像技术高精尖创新中心 北京 100190)3(中国科学院软件研究所 北京 100190)
医学影像云存储模型的研究与设计
齐来军1,2周丽娟1,2*任仲山1,2,3
1(首都师范大学信息工程学院 北京 100048)2(成像技术高精尖创新中心 北京 100190)3(中国科学院软件研究所 北京 100190)
为解决早期云计算模型对医学小文件存储出现的单节点问题,数据高冗余造成数据的不一致性以及检索效率低等方面的问题,提出一种新型云存储模式。模型中,引入BWFS算法实现优化海量医学小文件序列化合并,优化纠删码算法实现数据块编码,减少数据块的冗余存储,而且引入位图索引技术与HBase索引结合形成新型并行索引策略,优化HBase主索引的缺点。实验表明,新型存储模型通过使用BWFS算法和纠删码技术减少了集群主控节点的内存消耗,在保证数据快速恢复的情况下,减少了集群数据的冗余存储,并行索引技术提高了医学数据影像的检索效率。
医学影像数据 云存储 并行索引 编码技术
0 引 言
近年来海量数据急剧增长,云计算技术应用到互联网、金融、医学等各大研究领域。医学影像是病人相关疾病检测的载体,医护人员通过对病人的影像进行检测与诊断。互联网时代,借助云存储模型实现海量医学数据的实时存储和处理。然而,传统的云存储模型中存在大量的医学小文件,数据冗余存储,索引复杂等瓶颈。因此,需要对传统的云平台进行优化升级。
1 相关工作
本文围绕项目“第三方专科影像服务关键技术研究与应用示范”展开,关注医学影像数据分布式存储关键技术研究[1]。眼科医学影像数据属于小文件范畴,海量小文件上传到HDFS中会造成主存储节点内存开销的瓶颈,数据冗余存储,并且HBase检索效率低等。研究内容主要针对当前项目出现的问题进行优化和改造。首先,针对医学影像数据小文件的特点,提出了BWFS算法,该算法以影像的容量为权重,为其分配合理的序列化进程,实现小文件的快速合并;其次,在数据存储方面,舍弃HDFS的备份机制,采用数据编码规范技术,对数据块进行编码,优化数据块的冗余存储;最后,在数据检索方面,考虑到冷热数据因素对检索效率的影响,构造bitmap索引与HBase索引结合的双重索引,提高了海量医学数据检索效率。
2 数据云存储模型
2.1 影像数据云平台研究
Hadoop平台提供的HDFS适合存储大数据文件,但不适合存储小文件和大量随机读写的应用场景。为满足医学影像数据中心的海量图像的存储和检索要求,针对小文件处理,数据容灾技术以及数据检索这些瓶颈问题,设计了一种新型的存储模型[2],提供了医学影像“在线-近线”的二极存储架构,提高了医学数据的可用性。大型医院依然保留传统的PACS的在线数据,确保影像诊断业务的性能和连续性,近线和离线数据可远程存储在云平台影像数据中心。医学系统架构分成三层,底层是数据存储层[3];中间层是数据优化层;上层是文件访问组层,封装了客户端数据存储和检索请求服务。为此,眼科云存储平台总体集群环境结构如图1所示。

图1 医疗云存储平台总体集群结构示意图
服务访问层:传统的医疗设备、PACS系统通过API服务改造后通过WebService服务实现了与云接入;中间优化层实现数据的缓存处理和小文件的序列化操作,形成序列化大文件,降低了NameNode节点的内存消耗;存储层首先通过数据编码规范技术,实现对医学数据块的编码,形成校验码数据块。在保证数据快速检索的情况下,优化了HDFS的冗余存储;同时优化数据索引,实现了对冷热医学数据索引的双重存储,便于医学影像数据的存储和检索。
2.2 医疗影像云存储技术架构
根据“第三方专科影像服务关键技术研究与应用示范”的应用需求,结合云计算技术的发展。医学影像数据云存储模型基于Hadoop开源架构,并对其进行优化整合,项目中利用Hadoop平台实现了计算资源、内存、硬盘、网络等资源的池化。同时应用中从数据缓存,数据冗余存储和数据索引三方面进行优化和改造,具体的云数据存储技术架构如图2所示。
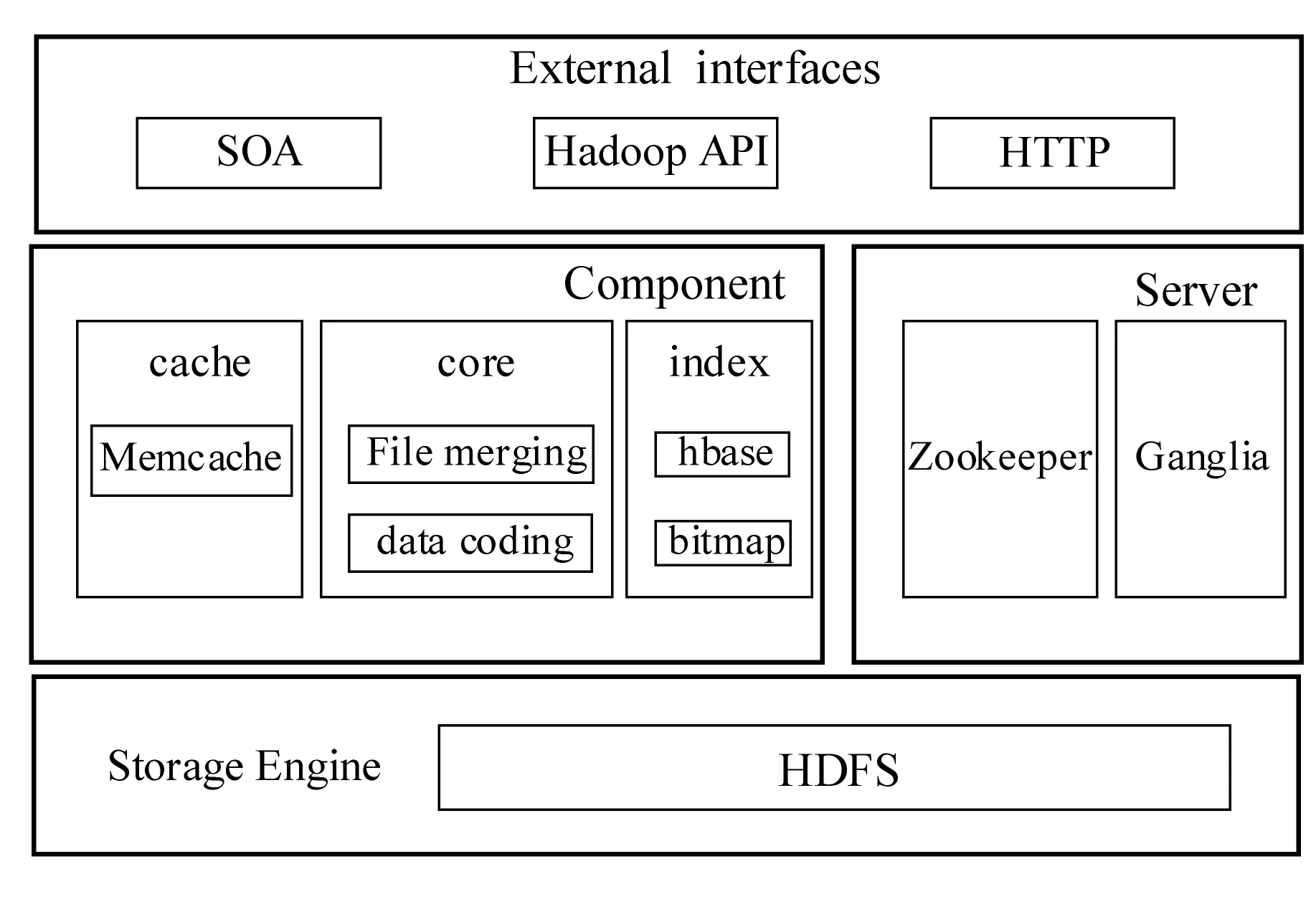
图2 海量医疗数据云存储技术架构图
由图2所述,项目主要对传统的云存储模型进行三方面的优化,首先为医学小文件处理提供了BWFS文件序列化算法,实现文件的归并化处理[4];其次构建了双重索引,提高了医学文件的检索效率;最后引入数据编码技术,既降低数据冗余,又保证数据的一致性。
3 医学影像文件处理技术
医学影像数据属于小文件范畴,且为非结构化数据类型,大小不确定,而且生成十分迅速。单次上传需占用的元数据容量为150 KB字节[5]。过多的小文件不仅消耗大量的NameNode的节点内存,而且增加了对HDFS访问次数,对数据的实时存储和检索带来很大影响。为此,提出BWFS算法在资源池实现小文件资源序列处理[5],将批量小文件序列化成大文件。
3.1 BWFS算法思想
为解决医学小文件上传造成的NameNode节点消耗问题,借用BWFS算法开启两条序列化进程,实现小文件的合并,后续开启第三条进程实现对合并后的文件再次序列化操作,为数据编码提供原始数据。BWFS算法开启两条并行的序列进程sf1、sf2,进程池的容量为block大小(128 MB),该算法依据文件的容量为权重,为文件选择合理的序列化进程sf进行序列化,当序列化进程达到容量时,开启第三条进程bsf,将序列化后的文件再次进行序列化操作。在bsf进程中,当文件总容量达到或接近1280 MB时,对大文件数据的分块和编码,随后上传到HDFS中。
3.2BWFS算法内容
BWFS算法,即Big Weight File Sequence,以文件的容量为权重,在一定的时间范围内,为文件选择合适的进程进行序列化操作。为了更好地描述该算法,特对相关的函数进行定义。
定义1 在时间点tn,上传容量为sn的小文件表示为fn,如式(1)表示。
fn=(tn,sn)
(1)
式中n表示第n个上传的小文件,tn表示第n个小文件上传的时间点,sn表示第n个文件的容量大小。因此用式(2)表示按照时间顺序上传的小文件,即:
f=(t,s)=f1,f2,…,fn
(2)
定义2 对上传的小文件序列化归并操作的进程称之为小型序列化进程,用sf表示。
算法中并行开启两个序列化进程sf1和sf2,其容量大小为128 MB。小文件上传后,进程sf1和sf2获取小文件的容量大小和自身剩余容量的大小这因素为小文件选择合理的序列化进程进行序列化操作。小文件在序列化资源池中进行序列化描述如图3所示。
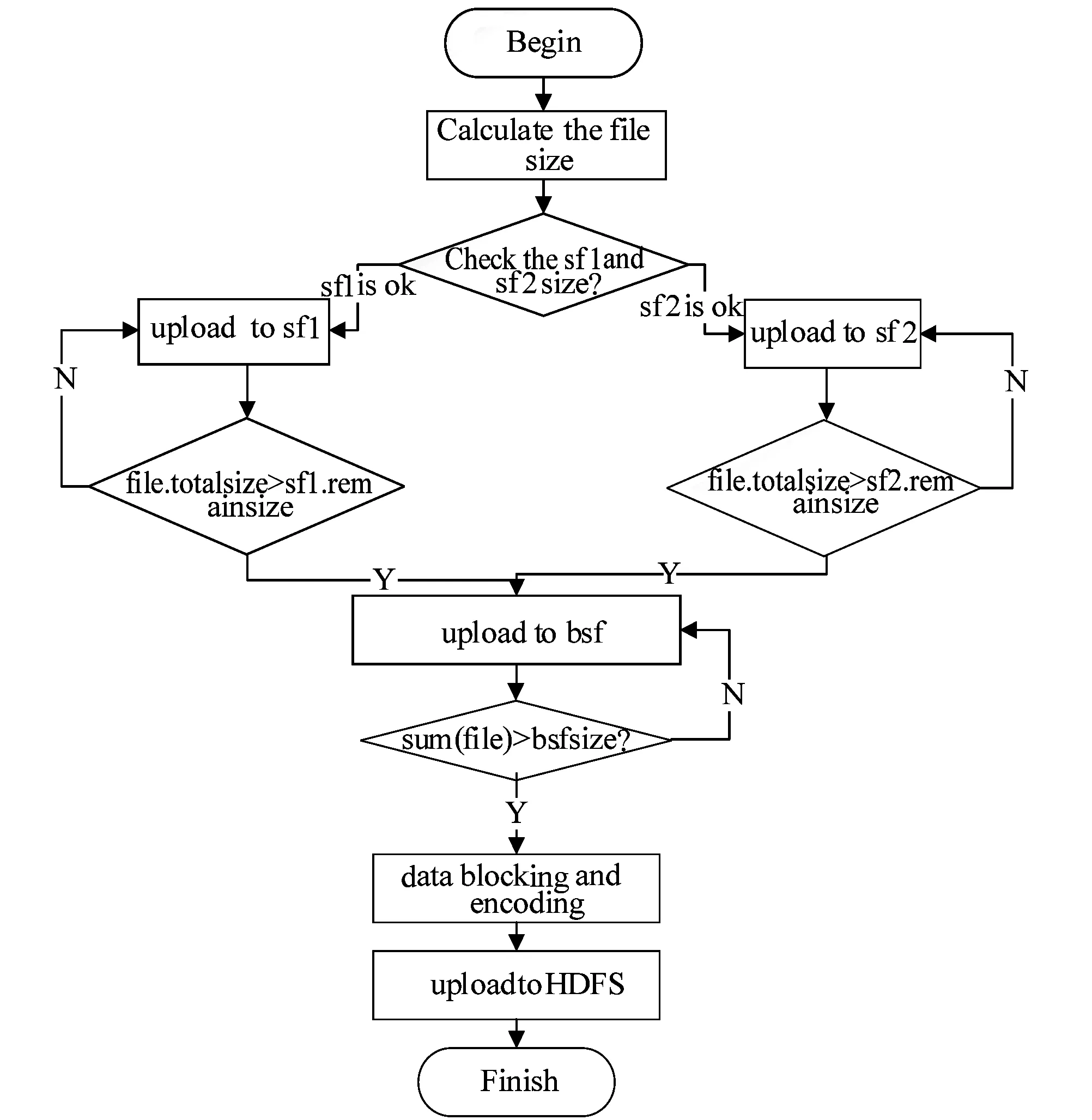
图3 医学小文件序列化流程图
定义3 序列化进程sf1或sf2达到其容量时,将序列化后小文件上再次序列化的进程称之为大型序列化进行,用bsf表示。
算法中此进程主要实现将序列化后的小文件再次进行序列化操作,一方面优化了小型序列化操作,另一方面,形成了适合分布式文件系统block的大文件,减少了对HDFS的访问次数。
结合上文的序列化合并算法的描述和其流程的设计,基于BWFS算法的医学小文件序列化合并的核心执行流程如下:
1. 初始化进程sf1和sf2,设置进程容量为128 MB。
2. 上传文件f1,在sf1和sf2剩余容量相等的条件下,默认将文件上传到sf1,sf2进程仍处于空闲等待状态。
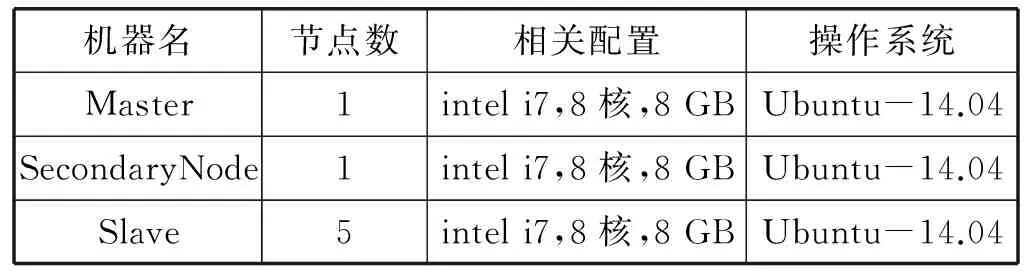
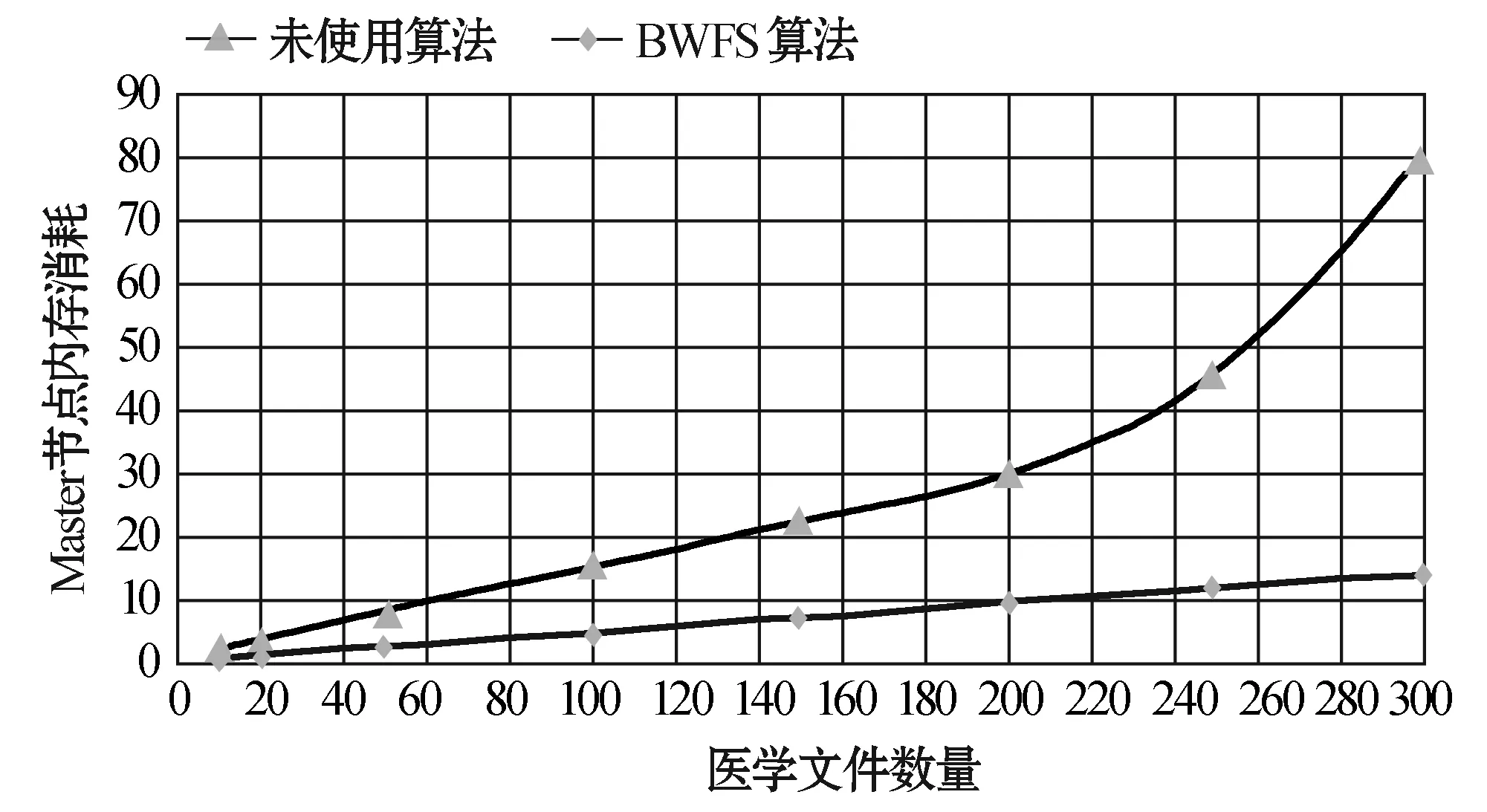
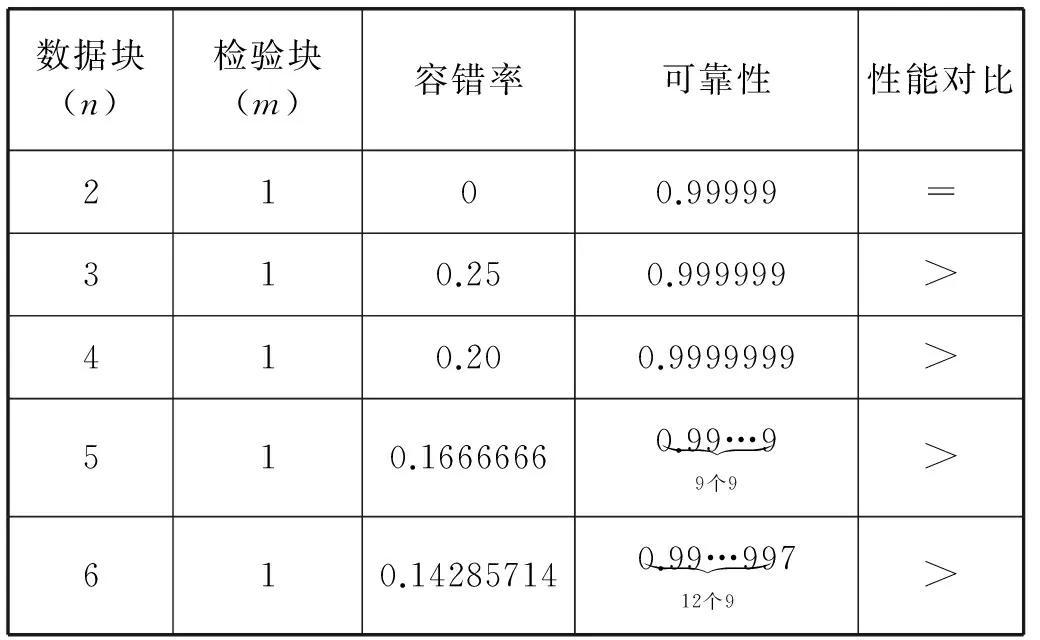
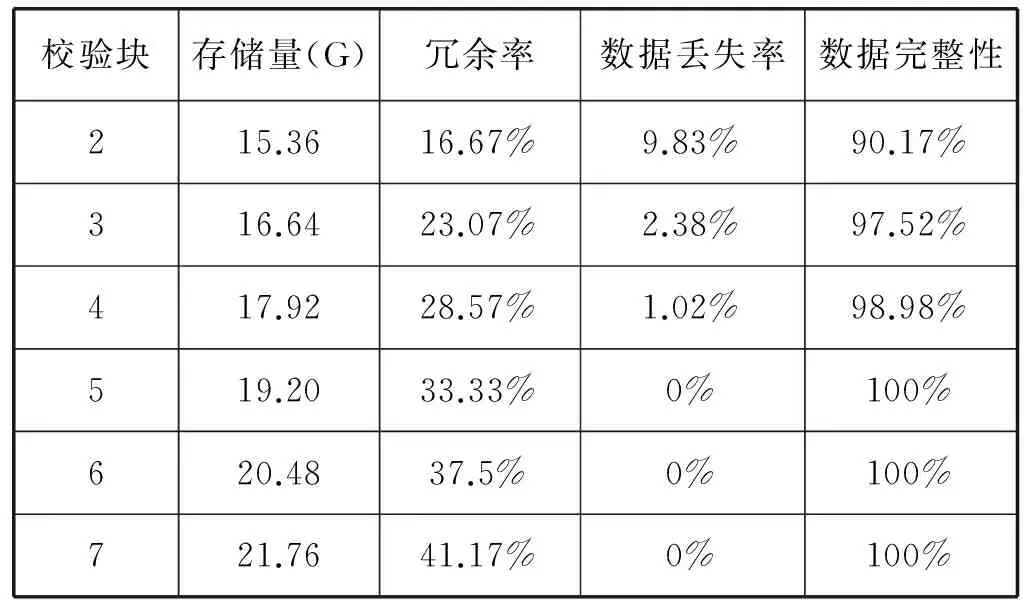
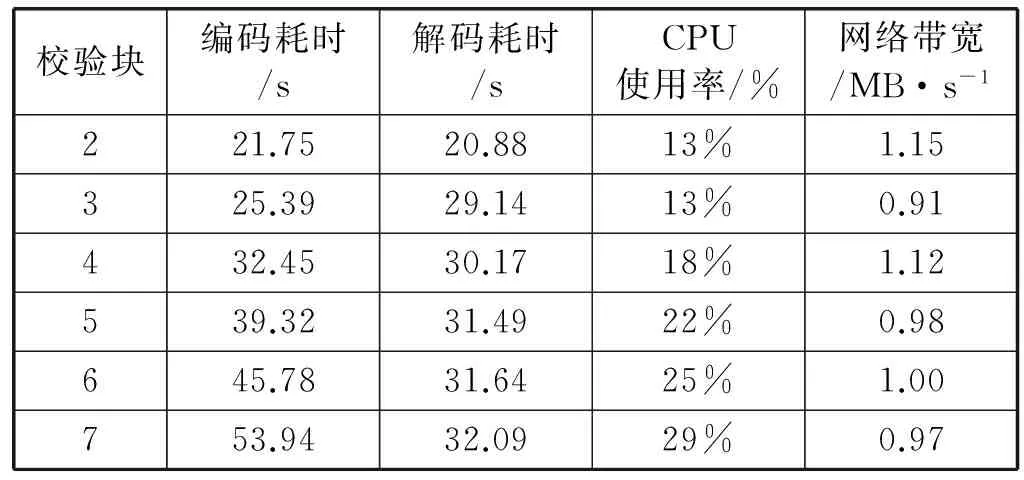
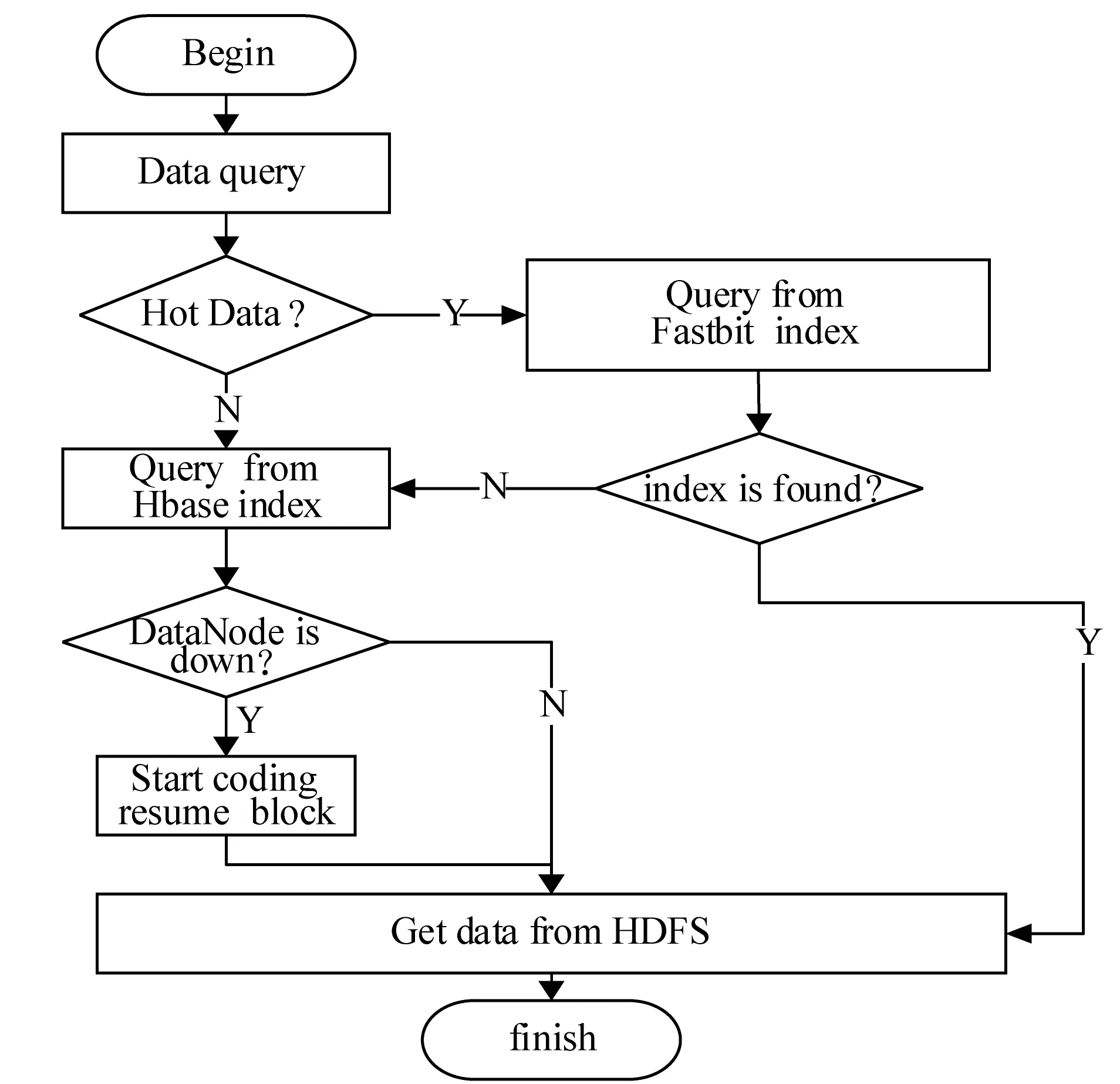
3. 后续小文件f2上传,判断s2+s1与sf1.remainsize大小,ifs2+s1 4. 文件f3上传,假设在f2上传到sf2中,需求解s3+s1,s3+s2大小,并与sf1和sf2剩余容量进行比较,若s3+s1 图4 小文件上传到bsf进程流程示意图 5. 重复执行步骤4,为后续的小文件选择合适的进程进行序列化操作。 6. 求解bsf(即big sequence file)中上传的医学影像小文件f1,f2,…,fk,…,fn-1对应的s1,s2,…,sk,…,sn-1的数据和与进程bsf的容量进行比较,ifs1+s2+…+sn-1 BWFS算法设计的核心思想是双重实现一些小文件序列化归并操作,最大限度地减少元数据占据Namenode节点内存,为集群节省更多的系统资源。在文件序列化后,通过文件分块和编码实现源数据的冗余存储。 3.3 医学影像云存储模型集群部署 为了验证BWFS算法在医学影像云存储平台的应用效果,监测BWFS算法对小文件合并是否减少Master 节点的内存消耗,以及上传批量小文件系统相应的时间。为此结合医学云存储模型搭建基于Hadoop医学影像云存储平台,集群中节点配置和部署如表1所示。 表1 Hadoop集群节点部署图 在医学影像云存储平台中,集群Master节点是NameNode节点,管理整个分布式文件系统的元数据和对DataNode节点的状态监控,Slave节点为资源存储节点,SecondaryNode节点负责对元数据备份。集群中相关开发组件版本如表2所示。 表2 集群相关组件描述 以上两表分别给出了医学影像云存储平台架构的集群部署和相关组件信息描述。为后续BWFS算法实验和数据编码实验相关数据的采集提供了平台基础。 3.4 BWFS算法实验测试与评估 部署Hadoop集群,将小文件合并的BWFS算法应用在项目开发中[7],并且对客户端提供序列化合并接口,若不采用序列化接口,则表示直接上传到HDFS中。 批量上传小文件的对比实验的大致流程如下: 1. 批量上传小文件份数10份(单文件的容量为15 MB),检测元数据占Master节点的内存消耗(单位为M),同时监测在整个文件上传的过程中云服务响应时间(单位为s)。 2. 使用BWFS算法,上传小文件份数为20、30、50、100、150、200、250、300份。进而统计各个点Master节点的内存消耗和上传过程中系统响应的时间。 3. 不使用BWFS算法,统计分别上传小文件份数10、20份,直到300份消耗Master节点内存和每次上传系统响应的时间。 4. 从Master节点内存消耗方面,对两种情况进行比较。 5. 从上传批量消耗时间方面,对两种情况进行比较。 6. 将测试的结果进行可视化对比,对BWFS算法效果进行评估。 实验中,通过检测元数据的信息量确定Master节点的内存消耗;同时监测上传所消耗的时间。批量上传医学小文件,Master节点内存消耗对比如表3所示。 表3 Master节点内存消耗对比表 数据表明,采用BWFS算法在序列化医学小文件上减少了Master节点的内存消耗。可视化表示两种情况下Master节点的内存消耗,如图5所示其中蓝色标记的曲线代表未使用序列化算法消耗内存的曲线图,红色标记曲线代表使用BWFS算法的消耗Master节点内存曲线图。 图5 批量上传小文件Master节点内存消耗对比图 由图5所示,小文件数量增多,在未使用序列化算法的情况下,NameNode节点内存消耗急剧增大,在上传300份小文件时,节点内存消耗近80 MB。然使用BWFS实现小文件的序列化操作,在上传300份小文件的情况下,仅仅消耗Master节点内存约为12 MB,是未使用算法消耗内存的七分之一,并且随着小文件的增加,内存消耗曲线变化非常缓慢,因此BWFS算法很适合海量医学小文件上传后的序列化合并操作。 实验中对每次完成批量医学影像数据上传的消耗时间也进行了监测,其中s1表示的是在未使用序列化算法的情况下,系统完成上传所消耗的时间,s2表示使用BWFS算法系统消耗的时间,具体如表4所示。 表4 批量上传完成消耗的时间对比表 对上传批量小文件消耗的时间对比进行可视化表示,如图6所示,其中黑色表示使用BWFS算法系统消耗的时间,灰色表示未使用序列化算法系统消耗的时间。 图6 批量上传小文件消耗时间对比图 由图6可知,少量数据上传时,系统响应的时间差别不明显,但批量文件上传时,两者之间的时间消耗越来越大。在上传300份小文件时,应用BWFS法可以使系统响应的缩减到原来的十分之一,因此在处理海量医学小文件时,BWFS算法具有很好的优势。Hadoop2.X集群引入了HA(High Availablity),即高可用方案[7],解决NameNode的单节点问题,若将BWFS算法应用结合到高版本的Hadoop集群中,不仅实现海量医学小文件的序列化存储,而且缩减对HDFS的访问次数,更加提高了系统的稳定性和高可用性,具有很好应用价值。 传统云存储模型实现了海量医学数据的持久化存储,同时为了保证数据存储的完整性和可靠性,提高海量数据的检索效率,采用数据备份的技术实现了对海量数据的无损和扩充备份。在云环境中,考虑到网络带宽、CPU性能等方面的影响,很难保证数据的完整性、一致性和分区容错性等特性。为此,借鉴纠删码技术[9],这样既可实现海量数据较少冗余存储,又能当数据节点出现故障时,能够及时实现数据的迅速恢复。 4.1 数据编码方法内容 纠删码是一种数据保护的方法,实现原数据分割成片,把冗余数据块扩展、编码、并将其存储在不同的位置,借此理念,将其应用在海量医学云存储模型中。 (3) 向量D表示元数据分块,向量C表示检验信息块,同时矩阵Fi表示F的行,会有FD=C,假设将F定义成大小为m×n的范德蒙矩阵,并且令fi,j=ji-1,即求出数据块的校验矩阵信息C。随后,依据利用范德蒙行列式[11],得出数据块编码方法如式(4)所示: (4) 通过计算得到矩阵L便是所需的n+m个等长的数据块d1d2,d3,…,dn和检验块c1,c2,c3,…,cm,将数据块和校验块一同存储到HDFS中。在数据读取时,若其中有m块丢失时,将这个m块对应的矩阵F和矩阵L所对应的行删除,进而得到新的n×n的矩阵F′和n×1的矩阵L′。由于矩阵F′是非奇异矩阵,对F′求逆矩阵F′-1,进而得到数据恢复的矩阵式(5)所示: D=(F′)-1L′ (5) D矩阵即是元数据块信息向量,求解到D即可实现原数据块的快速恢复。综上所述,在进程bsf中,在超过其阈值的情况下,首先进行数据分块,之后利用式(4)生成校验码块,其中校验块和元数据块的大小一致,之后通过将其存储到HDFS中,数据块的索引存储到HBase中。 4.2 数据编码技术实验和性能评估 随着海量数据的存储,传统的Hadoop集群的副本机制造成大量的数据冗余,造成大量资源的浪费,不利平台的拓展。医疗云存储模型通过编码规范技术极大地减少了集群数据的冗余,实现数据的检验备份,即使在DataNode节点出现问题时,也可做到数据快速恢复[12]。 医疗影像云存储平台中,假设使用n+m个DataNode节点,可以容忍系统最多有m个块出现故障,q表示单个DataNode的可靠性(q=99.999%)眼科影像云存储平台提供的可靠性(P),使用式(6)表示。 (6) 同时用reds表示冗余率,n表示切分数据块的数量,m表示编码校验块的数量,切分和编码数据带来的冗余率的计算用式(7)表示。 reds=m/(n+m) (7) 当n=2,m=1时,可靠性P=0.999999,,精确度可以达到6个9,此时的冗余率为33.3%。通过式(6)和式(7)当节点校验块为1的情况下,扩大原数据的块的个数,求解数据的容错率和系统的可靠性,并与传统的Hadoop集群默认提供的可靠性(99.999%)性能进行对比,如表5所示。 表5 数据编码技术系统可靠性 由表5得知,从理论角度在默认检验块为1的情况下,增加集群中的存储节点数量,可以看数据的可靠性快速增高,远高于Hadoop默认的可靠性能。 4.3 医学数据编码实验测试 医学数据编码技术包含数据编码算法和数据解码算法,医学小文件从序列化资源池bsf中进行分块并进行编码,形成源数据块和校验块存储到HDFS中,当源数据块丢失后,会调用解码算法实现对源数据的恢复。在医学云存储模型中,数据恢复时只需要找到其中的一块校验码,采用解码算法实现对原数据快的恢复。 为验证数据编码技术在平台中的应用效果,特进行测试。实验中设置序列化资源池bsf的容量为1280 MB,对列化文件进行分块处理,默认块大小为128 MB,形成10块原数据。同时设置校验块数分别为2,3,…,7。分别进行100次实验,统计医疗影像数据的所占用的存储空间和医学影像数据的丢失率,在保持云平台高性能的条件下,确定原数据n和校验块m最佳的数据。 表6 编码技术在实验中性能数据采集表 由表6可以看出,采用数据编码规范技术降低了数据的冗余率,在原数据块10块,校验块为5时,数据的丢失率为0。此时存储数据仅是传统Hadoop存储平台的二分之一,为云平台节省了50%的存储空间。项目中同样使用了传统的Hadoop副本策略进行存储数据,测试发现在副本为3时,进行100次实验测得数据的丢失率为4.15%,采用副本为4时,同样的100次实验数据的丢失率为2.12%,相比使用数据编码技术,在校验块为4时,数据的安全性均高于相应的副本策略。因此数据编码在较低冗余存储的情况下,保证了数据的安全性[12]。 实验中对数据编码和解码时消耗,以各节点CPU使用率和网络带宽等方面进行统计,验证云平台性能的稳定性。 表7中的数据表示在实验100份数据时,编码算法和解码算法平均的耗时时间。数据表明,随着校验块增多数据编码耗时增加,同时数据解码时间降低,编码和解码时间总体小于100 s,过程中CPU的使用率均低于30%,网络带宽在1 MB/s左右,满足医学影像云平台的性能要求。当出现源数据块丢失后,使用解码算法实现了数据的快速恢复,保证医学数据的完整性和一致性[13]。 表7 编码技术在实验中资源使用描述 综上所述,数据编码技术在没有增加过多的存储空间开销的基础上,通过冗余编码来保证数据的高可靠性和可用性。相对于传统的Hadoop云存储模型中,数据的安全性取决于副本所在的DataNode节点,若所有的副本节点无法提供正常的服务时,那么该数据失效。采用编码技术,只需找到校验块数据,即可实现原数据的快速恢复,不仅减少数据的冗余,而且保证数据的高一致性,因此具有很好的科研价值和商业应用价值。 4.4 医学数据编码改进 云存储模型实现了医学数据的快速读写,然而医学数据分为冷热数据。对那些上传较早,并长时间未被访问的数据称之为冷数据,而最新上传或反复被访问的数据称为热数据。 为了能够实现对海量医学数据的访问,对云存储平台数据索引进行升级改造[14]。提出Fastbit+HBase的双重索引,对热数据采用位图索引,并将索引写入到HBase中,实现了海量数据的索引的双重存储。对热数据设置时间周期,bitmap为定期更新存储索引信息,对超过时间周期尚未被访问的数据,其索引将会从bitmap索引中删除,冷数据索引主要存储在HBase中。 Bitmap索引是基于内存的索引,在数据检索时,可以根据索引实现数据的快速查询;同时又属于key-value存储类型,与HBase存储机制相似,很容易实现索引复制到HBase中;并且bitmap索引占用的内存空间不大,索引表定期更新,HBase索引存储属于持久化存储,并且是一次写入多次读取的机制,不会造成数据索引的丢失,属于持久化存储。因此在云存储平台中,使用bitmap索引与HBase索引相结合[15],对提高医学影像数据的检索具有很好应用效果。 医学数据检索时,根据用户提交的请求,判断检索信息的类。如果是热数据,则从位图索引中查找,否则到HBase索引中查找[16]。若位图索引查找不到索引时,回到持久化索引中进行检索,当出现DataNode宕机时,便启用数据编码技术,获取校验块信息,并实现数据块的恢复,进而实现数据的检索。数据检索流程如图7所示。 图7 医学数据检索流程图 数据检索时,bitmap索引会挂在到内存,实现对热数据的检索,同样的对于冷数据,需要到HBase索引表中检索,进而查找相关的数据。结合数据编码技术的应用,源数据块索引与校验块索引相同,同时满足热数据索引存储在bitmap索引中,并且持久化到HBase中。在Hadoop集群中,当DataNode节点宕机时,采用上述的检索方法,首先在bitmap索引对校验块数据进行检索,否则到HBase索引中检索校验块,并通过数据解码算法,完成对源数据块的恢复[17],进而实现了对海量医学数据的快速检索。 本文针对传统云计算模型在数据存储和检索以及数据冗余等方面出现的瓶颈问题提出BWFS算法实现小文件序列化合并,减少对Master节点的内存消耗和对HDFS访问次数;使用纠删码数据编码技术,在降低数据冗余存储前提,实现了对海量医学数据的快速恢复;并引入一种基于位图索引的列式存储bitmap与HBase索引相结合的并行索引[18],实现了医学数据的快速检索。将其应用在医学影像数据云存储系统中降低海量数据的冗余存储,提高海量数据的检索效率,提高了医学影像的分析效率,具有很好的应用价值。 [1] 王意洁, 孙伟东, 周松, 等. 云计算环境下的分布存储关键技术木[J]. 软件学报, 2012, 23(4): 962-986. [2] 胡涛, 周兵, 郑明辉, 等. 基于Hadoop的移动云存储系统研究与实现[J]. 华中科技大学学报(自然科学版), 2013, 41(S2): 181-183. [3] 罗鹏, 龚勋.HDFS数据存放策略的研究与改进[J]. 计算机工程与设计, 2014, 35(4): 1127-1131. [4] 谢华成, 陈向东. 面向云存储的非结构化数据存取[J]. 计算机应用, 2012, 32(7): 1924-1928,1942. [5] 熊炼, 徐正全, 王涛, 等. 云环境下的时空数据小文件存储策略[J]. 武汉大学学报(信息科学版), 2014, 39(10): 1252-1256. [6] 李铁, 燕彩蓉, 黄永锋, 等. 面向Hadoop分布式文件系统的小文件存取优化方法[J]. 计算机应用, 2014, 34(11): 3091-3095,3099. [7] 张源悍. 基于Hadoop平台的高可用性云存储系统的设计与实现[D]. 哈尔滨:哈尔滨工业大学, 2014. [8] 杜勇. 基于HDFS的云数据备份系统的设计与实现[D]. 长春:吉林大学, 2011. [9] 敖莉, 舒继武, 李明强. 重复数据删除技术[J]. 软件学报, 2010, 21(5): 916-929. [10] 许文龙. 基于Hadoop分布式系统的重复数据检测技术研究与应用[D]. 长沙:湖南大学, 2013. [11] 王禹, 赵跃龙, 侯昉. 基于矩阵运算的最小冗余存储再生码MSRRC研究[J]. 计算机科学, 2014, 41(11A): 191-194,207. [12] 张亮. 云存储数据完整性检测技术研究[D]. 大连:大连理工大学, 2014. [13] 陈兰香, 许力. 云存储服务中可证明数据持有及恢复技术研究[J]. 计算机研究与发展, 2012, 49(S1): 19-25. [14] 丁琛. 基于HBase的空间数据分布式存储和并行查询算法研究[D]. 南京:南京师范大学, 2014. [15]LiuYB,WangF,JiKF,etal.NVSTdataarchivingsystembasedonFastBitNoSQLdatabase[J].JournaloftheKoreanAstronomicalSociety, 2014, 47(3): 115-122. [16] 卓海艺. 基于HBase的海量数据实时查询系统设计与实现[D]. 北京:北京邮电大学, 2013. [17] 颜湘涛, 李益发. 基于消息认证函数的云端数据完整性检测方案[J]. 电子与信息学报, 2013, 35(2): 310-313. [18] 孟必平, 王腾蛟, 李红燕, 等. 分片位图索引:一种适用于云数据管理的辅助索引机制[J]. 计算机学报, 2012, 35(11): 2306-2316. THE RESEARCH AND DESIGN OF MEDICAL IMAGE CLOUD STORAGE MODEL Qi Laijun1,2Zhou Lijuan1,2*Ren Zhongshan1,2,3 1(CollegeofInformationEngineering,CapitalNormalUniversity,Beijing100048,China)2(AdvancedInnovationCenterforImagingTechnology,Beijing100190,China)3(InstituteofSoftware,ChineseAcademyofSciences,Beijing100190,China) In order to solve the single node problem of the small medical files in storage and the inconsistency of high data redundancy and the low retrieval efficiency in the early storage model,a new type of cloud storage mode is put forward.In this model,the BWFS algorithm is applied to optimize the serialization consolidation of massive medicine small files.Optimizing erasure codes algorithms to realize data blocks,which reduces the redundant storage of data block.At the same time,the bitmap index technology is applied to combining with the HBase index,which forms a new index technology.Experiments show that the new cloud storage model reduces the memory consumption of master node in the cluster by using BWFS algorithm and erasure coding technology,under the circumstance of ensuring rapid recovery,this model reduces redundant data storage,and the parallel indexing technology has improved the efficiency of searching the massive medical image data. Medical imaging data Cloud storage Parallel index Coding technology 2015-11-11。国家自然科学基金项目(31571563);北京市属高等学校创新团队建设与教师职业发展计划项目资助;高可靠嵌入式系统技术北京市工程研究中心;国外访学项目(067145301400);北京市高精尖——成像技术高精尖创新中心项目(GXTC-1663074)。齐来军,硕士生,主研领域:云计算,大数据。周丽娟,教授。任仲山,博士生。 TP3 A 10.3969/j.issn.1000-386x.2017.02.011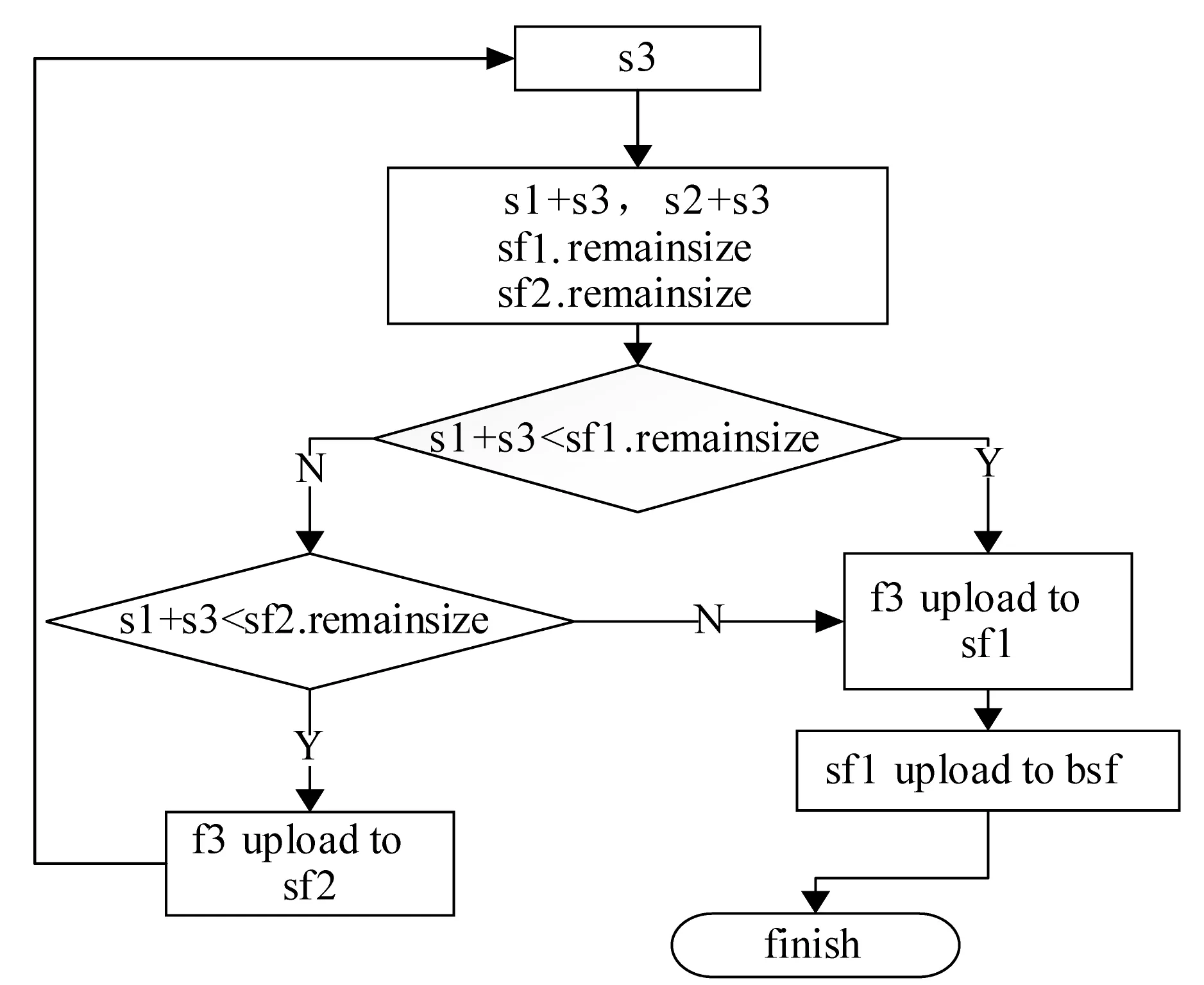



4 医学数据编码技术

5 结 语
