动态多源时间认知推荐算法研究
2017-02-27李敬兆朱东郡谭大禹
李敬兆 朱东郡 谭大禹
1(安徽理工大学电气与信息工程学院 安徽 淮南 232001)2(安徽理工大学计算机科学与工程学院 安徽 淮南 232001)
动态多源时间认知推荐算法研究
李敬兆1,2朱东郡2谭大禹2
1(安徽理工大学电气与信息工程学院 安徽 淮南 232001)2(安徽理工大学计算机科学与工程学院 安徽 淮南 232001)
一个好的推荐算法在如今的智能Web应用中变得十分重要。给出一种具有时间认知的推荐算法。传统的推荐算法通常不加选择地使用早期和近期的评价,随着时间的推移而忽略了用户兴趣的变化,且用户的兴趣在短期的时间间隔内保持稳定但在长期间隔内是有所改变的。在已有的协同过滤推荐算法基础上加入了时间向量因子用来激励近期记录或减弱早期记录,以达到更有效分类相似兴趣的用户的目的。结果表明应用该方法能有效提高在智能Web中推荐的准确率及效率。
智能Web 时间向量因子 协同过滤推荐 用户兴趣变化
0 引 言
随着互联网的不断发展,大量的信息出现在人们的视野中[8]。信息的爆炸使得用户很难获取到对自己有用的信息。虽然搜索引擎可以帮助人们从海量信息中检索出需要的信息,但同时也要求用户提供必要的关键词。当查询结果不能让用户满意时,用户还需提供更合适的关键词重新查询。如果查询关键词不能够恰当地反映出搜索需求,那么查询的结果就很令人失望。因此只有在用户能很好地用关键词描述自己的需求时,搜索引擎才能更好地体现其功能。而当用户对自身的需求比较模糊时,使用搜索引擎将很难查询出称心的结果。
然而推荐系统正是为解决这类问题而出现的。推荐系统通过分析用户的历史数据来建模用户兴趣[7],发现用户的可能存在的一些需求,并对其进行分析,根据分析结果为用户推荐相应的信息。
随着对推荐系统研究的深入,研究者们针对不同的需求提出了不同的推荐算法,其中包括基于内容的推荐、协同过滤推荐、基于聚类算法的推荐以及基于产品到产品的专利推荐等[7]。而协同过滤推荐是使用最为普遍和成功的。
协同过滤CF(Collaborative Filtering)是向用户推荐与其具有相似爱好的用户喜欢的产品[7]。它通过用户对产品的评价计算出与目标用户的爱好相似的用户,然后把他们喜欢的产品推荐给目标用户。协同过滤的假设是:多个用户对一些产品给予相似的评价,那么对另一些产品也会给予相似评价[7]。就像人们时常喜欢与爱好相同的朋友相互推荐和分享有趣的事物一样,这种推荐和分享更容易被人所接受。
但是目前的协同过滤算法在相似度计算中往往不加选择地使用早期和近期记录。而用户浏览记录是和用户自身的行为逻辑,兴趣特点有紧密联系的。由于用户习惯的变化以及用户与用户之间的不同,推荐系统在浏览时间和评价时间的数据获取上存在不确定性、多源性。其数据在时间轴上表现出实时的动态变化。因此如果不考虑时间因素,忽略了用户兴趣的变化。随着时间的推移推荐系统就不能更精确地给用户推荐信息。而且用户的兴趣一般在短期的时间间隔内保持稳定,但在长期时间跨度内,不同用户的兴趣变化是不确定的甚至杂乱无章的。因此在用户相似度的计算中,用户对产品的评价时间就显得非常重要。比如用户A和用户B在评价记录中都对看过探险类的电影评价很高,但用户A是2年以前的评价,用户B是最近的评价。传统的KNN相似度算法就会认为用户A、B都喜欢看探险的电影,他们俩是偏好相似的用户。然而事实上用户A早在一年前就不看探险类的电影,而且认为其没有意思。所以近期来看用户A与B就探险类电影而言不能认为是具有相似偏好的用户。基于此,本文提出了融合时间向量算子的协同过滤算法。其核心思想是:某些用户在同一时期内对某些产品给出的评价相似,那么在这个时期内他们对另一些产品所给出的评价很大程度上也会相似。所以在用户相似度计算中多个用户在不同时期内对一些产品给予相似的评价,这种评价是不稳定的,需要在时间上进行衰减,而在同一时期内对一些产品给予相似的评价,在这种评价是有效,需要在时间上进行激励。从而让用户的相似度变得更加精确。
1 协同过滤推荐中常见的相似度算法
1.1 向量夹角余弦相似度计算
协同过滤可以分为基于产品或基于用户。基于产品的协同过滤算法(Item-based CF)是通过分析与某一产品相似的一些产品的评分,推测目标用户对这一产品的喜好程度。而基于用户的协同过滤算法(User-based CF)是通过与目标用户兴趣相似的用户对某一产品评分来推测目标用户对此产品的喜好度,本文主要讨论基于用户的协同过滤。
基于用户的协同过滤预测可以分成两部分:一是用户相似度的计算,即找出最相似的邻近用户。二是计算邻近的相似用户对产品评分的均值,预测目标用户的评分[7]。其中向量夹角余弦相似度计算是其中常用的方法。
假设包含了n个用户的集合U={U1,U2,…,Un)和m个产品的集合I={I1,I2,…,Im)。用矩阵表示如下。见表1所示。
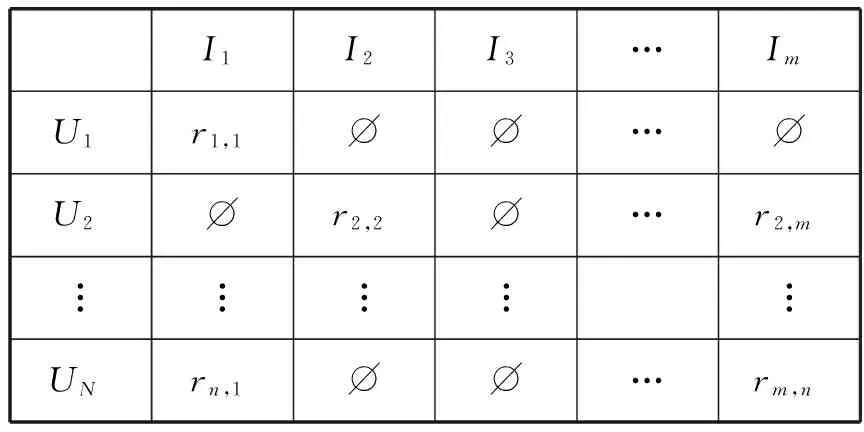
表1 用户-产品矩阵(User-Item Matrix)
表1中rn,m表示用户n对产品m的评价。如果rn,m=∅则表示用户n没有评价过产品m。
关于用户之间相似度的计算,设用户Uw和Uv共同评价过n个产品,那么这n个产品可以被看成n维向量空间,用户Uw和Uv可以看成这空间中的两个向量,通过向量夹角余弦(COS)[6]可以表示他们之间的相似度,如式(1):
(1)
式中Sim(Uw,Uv)代表用户Uw与Uv的相似度,Iw和Iv代表用户Uw和Uv各自评价过的产品(item)的集合,而用户Uw、Uv对产品i的评分则用rwi、rvi表示。由此定义看出Sim(Uw,Uv)的值在 [0,1]区间,值越大表明用户Uw与用户Uv越相似。
1.2 皮尔逊相关系数相似度计算
皮尔逊相关系数PCC(PearsonCorrelationCoefficient)[5]同样在相似度的计算中经常被用到。基于表1,PCC被定义为:
(2)
式中Sim(Uw,Uv)为用户Uw与Uv的相似度,Iw和Iv代表用户Uw和Uv各自评价过的产品(item)的集合,而用户Uw、Uv对产品i的评分则用rwi、rvi表示。据此定义,用户相似度Sim(Uw,Uv)的值落在 [0,1] 区间,并且其值越大表明用户Uw与用户Uv越相似。
COS和PCC被提出来之后,Candillier[2]及一些研究者提出,COS和PCC相似度算法仅考虑了两个用户之间共同评价的部分。这有可能出现两个用户只共同评价过1个商品但却是相似用户的假象(例如,某一个用户喜欢探险电影,另一个用户喜欢科幻电影,他们之间没有共同看过的电影,因此他们不是相似用户。然而之后很巧他俩都看了一部相同的科幻探险类电影且都非常喜欢,那么通过COS相似度算法计算得出他们俩个是相似用户。为了解决此问题,Candillier等人[2]在相似度的计算上融入两个向量之间交叠程度并用式(3)卡德系数表示:
(3)
式中的Iw、Iv分别为用户Uw、Uv评价过的产品(item)构成的集合。通过将jaccard系数分别与PCC、COS相乘,CandilHer等人[2]演化出两种相似度计算方法(以下简称JPCC、JCOS)。实验证明了JPCC优于其他三种相似度,这里给出JPCC的表达式:
(4)
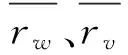
1.3PIP相似度算法
为了缓解协同过滤的冷启动问题,Ahn等人提出了PIP(Proximity-Impact-Popularity)[3,7]相似度算法。所谓冷启动指的是在一个推荐系统中当有新的产品或用户或加入时,由于用户没有对产品有过评价,新的产品也很少被用户评价过,造成产品不能被很好推荐给用户,而用户得不到好的推荐产品。PIP相似度算法表达式如式(5):
popularity(rw,i,rv,i)
(5)
其中proximity(rw,i,rv,i)是在两个评分rwi,rvi的算术差值的基础上,判断两个评分值是否相似,不相似时对这两个用户的相似度值进行惩罚;impact(rw,i,rv,j)是在用户w和用户v对产品i喜欢(或讨厌)程度的基础上,判断其对产品i喜欢(或讨厌)程度,如果他们都对产品表现出很明显的相同偏好,则对这两个用户的相似度值进行奖励;popularity(rw,i,rv,i)考虑了当用户对产品i评分值与其平均值差距较大时,则增大这两个用户的相似度值。
以下为式(5)中proximity(rw,i,rv,i)、impact(rw,i,rv,j)、popularity(rw,i,rv,i)3个因子的表达式。其中式(7)-式(9)中的agreement(rw,i,rw,i)的取值如式(6)所示:
(6)

(7)
(9)
根据Ahn等人的实验结果,PIP对冷启动问题的解决很有效,但在其他时候效果不佳[3,7]。
2 基于杰卡德皮尔逊相似度推荐算法的改进
目前的协同过滤算法在相似度计算中通常不加选择地使用早期和近期评价,而推荐系统在浏览记录的时间数据获取上存在不确定性、多源性。因此如果不考虑时间因素,忽略了用户兴趣的变化。那么随着时间的推移推荐系统就不能更好地为给用户提供有用的信息。为了解决这类问题,本文提出了杰卡德时间向量皮尔逊相似度算法JTVP(Jaccard Time Vector Pearson Similiarity Measurent)。JTVP基于同一时间向量空间中两个时间向量之间的距离对用户在同一或不同时期内的产品评价给予激励或衰减。
本算法是基于KNN(k-NearestNeighbor)算法模型预测用户对未评价过的产品的喜好,结果越大表明越喜欢。其算法通常需要以下三个步骤:
(1) 通过相似性算法计算出当前用户与其他用户之间的相似度;
(2) 从全部用户中选择K个与当前用户相似度最高的用户并作为当前用户的邻近相似集合[8];
(3) 根据这K个最邻近相似用户对某产品的评分的均值预测当前用户对其产品的评分。
本文把兴趣强度强弱变化设定在(0,5)之间。0表示极其讨厌,5极其喜欢。图1表示在用户对某事物随着时间变化其兴趣强度的变化。
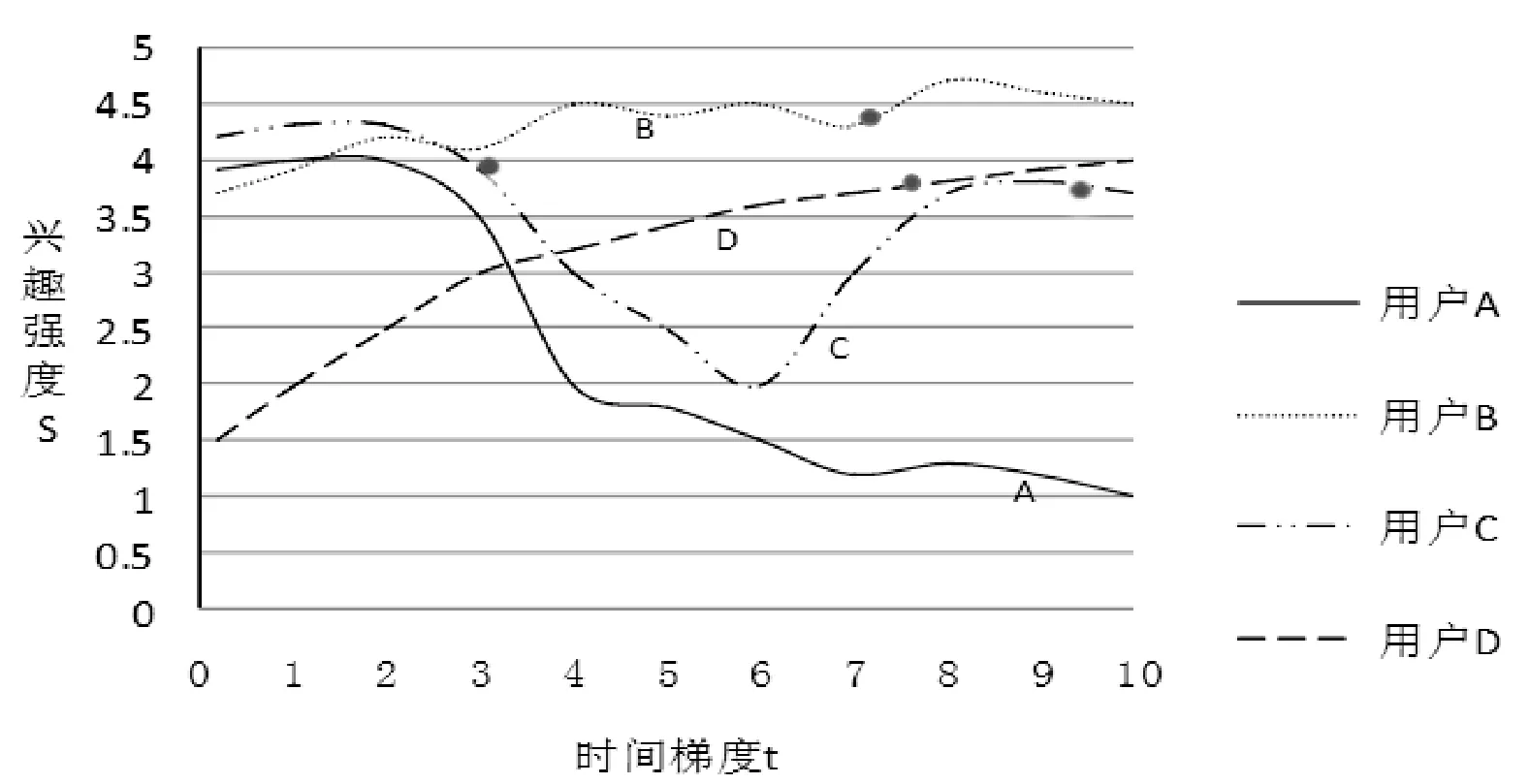
图1 兴趣强度维持曲线
从图1兴趣强度曲线可以看出在比较短的时间内用户A、用户B、用户C对同一件事都抱有很强的兴趣,而本文可以认为短期(0~3)内这三个用户是相似的用户。但随着时间的推移用户对此事物的兴趣发生了不同的变化,用户A对此事物失去了兴趣,用户B依然保持很强的兴趣,用户C的兴趣强度时而高时而低,用户D的兴趣强度是不断的增加的。这时(在8~10时间段内)用户BCD是相似用户。现在问题来了,假设用户ABCD都对此事物给出了好的评价,但评价的时间点不一样(如图点状标注)。不考虑时间因素的话显然ABCD都为相似用户,但这是不准确的。根据用户兴趣在一个短期的时间间隔内保持稳定但长期内不同的用户兴趣会产生不同是波动的情况,本文提出了时间向量算子TVO(TimeVectorOperator)的概念。TVO对于用户对产品的评价在时间上的不同给予其不同的权重,加大近期权重,减小久远的评价权重,从而让推荐算法具有了在时间上的认知。
为此本文给出了时间向量算子表达式:
(10)

之后用时间向量算子对用户评价的产品加权,如式(11)和式(12):
(11)
(12)
在给产品的评价加时间权重时,为了提高准确度和减少不必要的计算时间,本文给产品的评价设立一个阈值L,如式(13),只有大于L才给产品评价加上时间权重。
(13)
加入时间权重后使用改进的皮尔逊相关系数相似性算法为用户找出用户邻居:
(14)

最后产品的推荐分数可以通过下式得出:
(15)
式中Score(i) 为目标用户度产品i的预测评价,Sim(Uw,Uv) 为用户Uw、Uv之间的相似度,K表示相似邻近用户的个数,Svi为用户Uv对产品i的评价。
最后把这些评分从高到低进行排序,把TopN即前N个产品推荐给用户。
3 实验仿真
本节通过k-折交叉验证来检验杰卡德时间向量皮尔逊相似度算法的推荐质量,并验证以下两个问题:
(1) 数据集的不同对推荐的影响;
(2) 不同时间的梯度会对推荐效果造成何种影响。
验证的具体过程如下:随机地将数据分成k个大小相等且不相交的子集。其中k-1个集合作为训练集,剩下一个集合作为测试集。训练集用来预测测试集中用户的评分并与测试集的数据相比较来判断测试的准确性。然后重复k次,目的是让每个子集都作为测试集预测一遍,从而减小实验的误差,保证实验的准确性。最后,通过计算准确率与召回率验证方法的有效性。本实验把数据分成了十份也可以说成十折交叉验证。这种实验的优点是所有的集合都能轮流作为测试集验证,仿真的可信度更高。
实验使用的数据集是MovieLens(一种电影评分数据集)。该推荐系统的评分是从0.5到5分,按0.5递增。5分表明该用户非常喜欢这部电影,而0.5表明该用户对这部电影评价很差。
实验环境:本课题的实验是在Windows7系统下,IntelCorei7-4700HQ2.40GHz处理器,内存4.0GB的PC机上进行,采用MySQL数据库存储数据集,Java语言编程实现。
实验用两个MovieLens数据集(MovieLensl、MovieLens2)进行验证,其时间戳的跨度为10年,如表2所示。
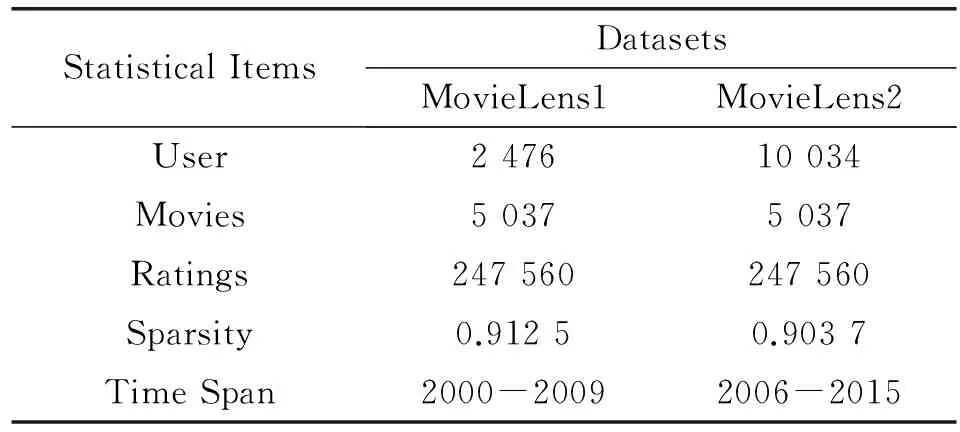
表2 数据集
评价标准:实验通过准确率Precision、召回率Recall来对推荐质量进行评价。Precision指在所有的推荐中用户喜欢的产品数占总的推荐产品数的比;Recall指在所有的推荐中用户喜欢的产品数与推荐系统中用户喜欢的所有产品数的比。其的形式化定义如式(16)、式(17)所示,符号的含义见表3所示。

表3 变量含义表
(16)
(17)
实验中,使用MovieLens-l数据集时,时间梯度是以2009年开始以每次向后退2年的方式一直到2000年。即2009-2008(2009和2008两年),2009-2006,…,2009-2000,时间跨度T的取值则分别为2、4、6、8、10;使用MovieLens-2数据集时,同上以2015年开始以每次向后退2年,一直到2006年,时间跨度T的取值则为2、4、6、8、10。实验结果,如图2-图5所示。
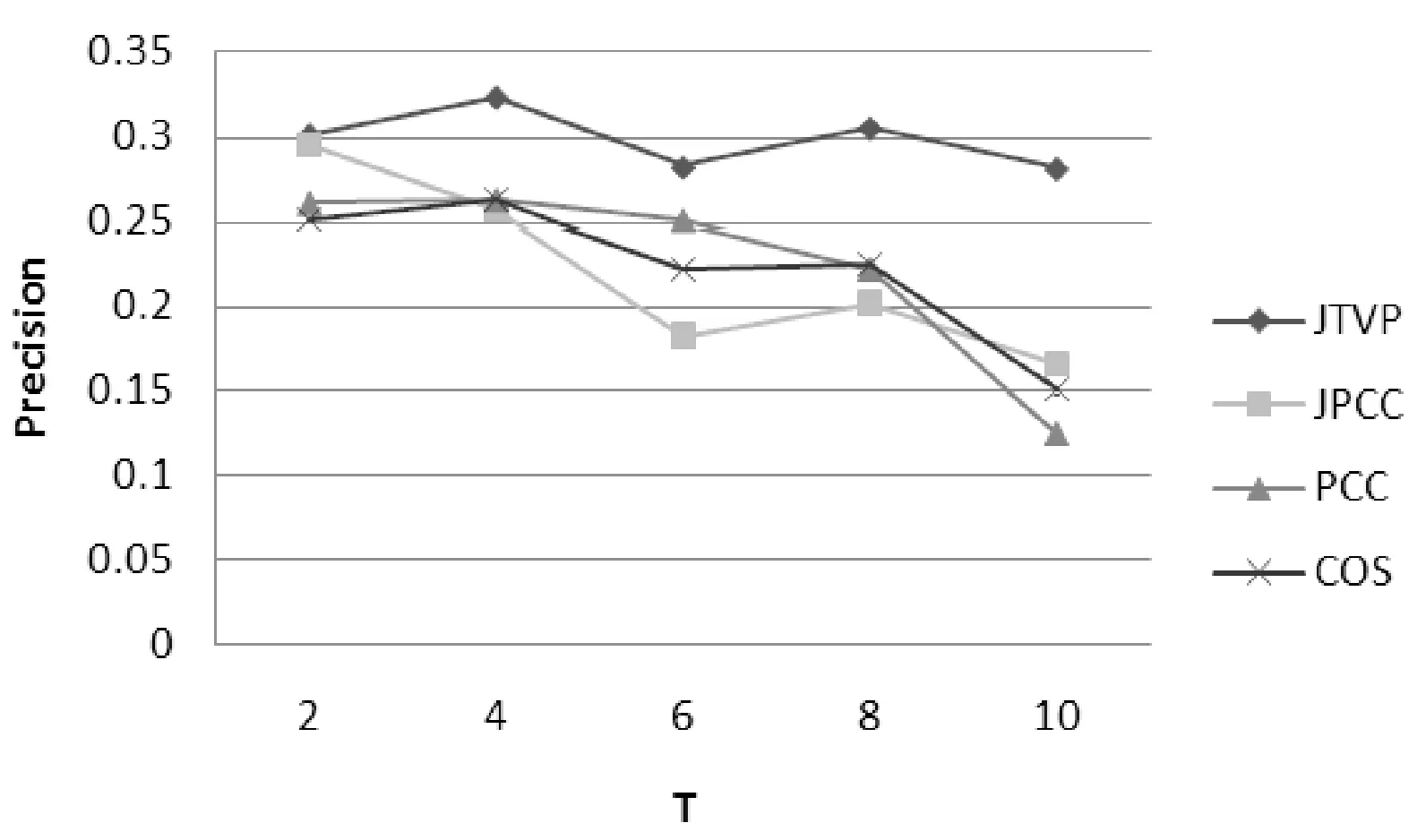
图2 MovieLens-1中不同方法的准确率对比
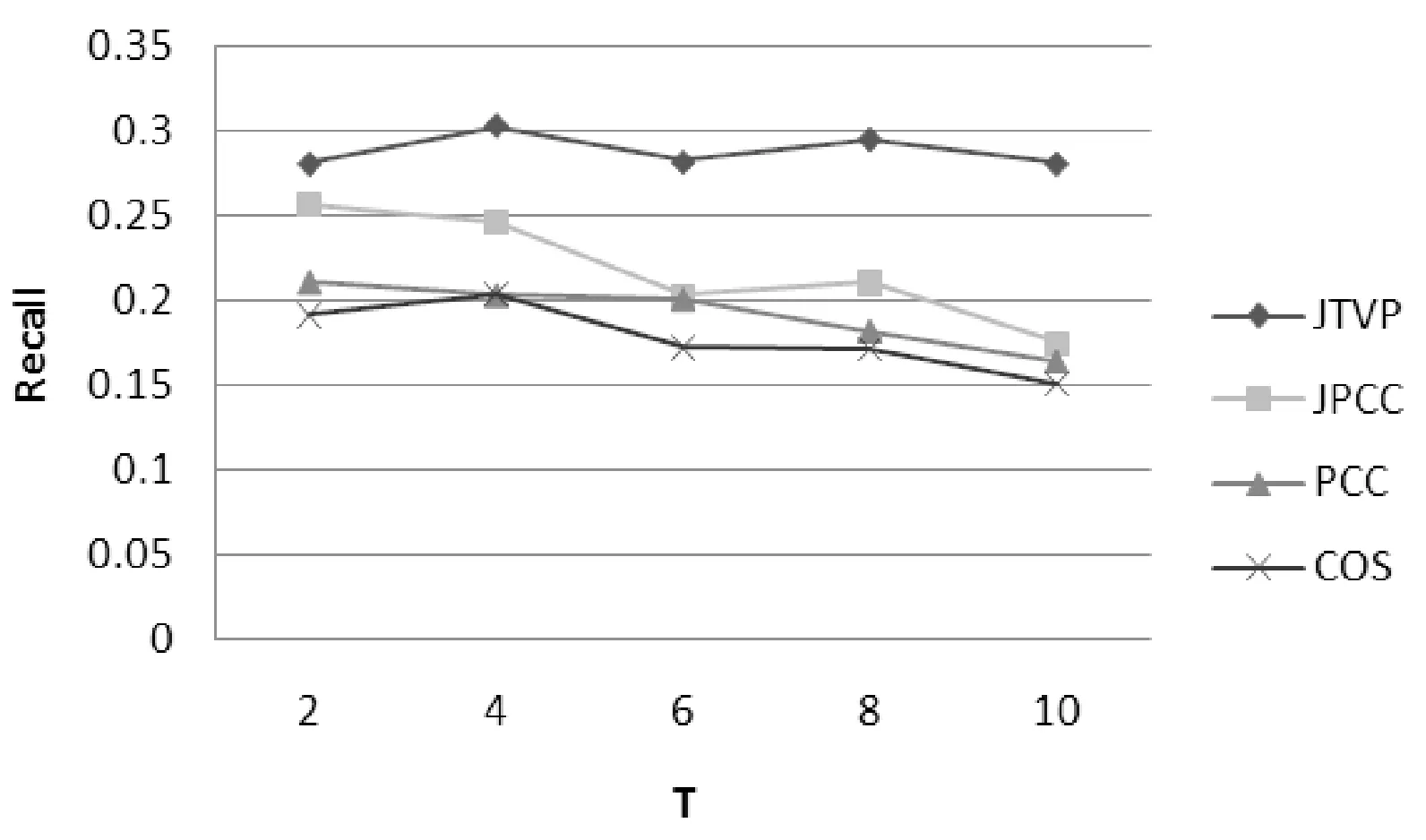
图3 MovieLens-1中不同方法的召回率对比
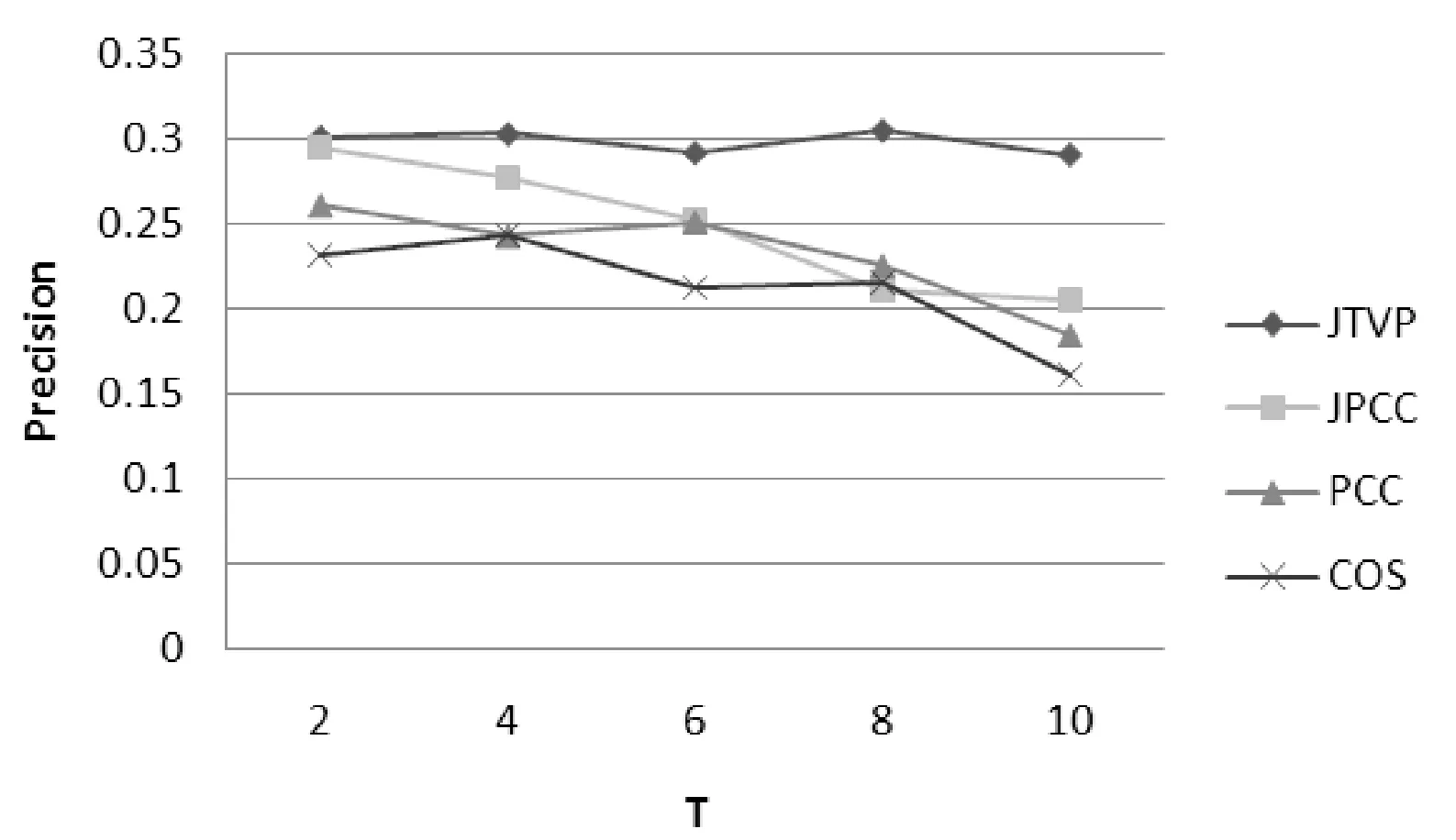
图4 MovieLens-1中不同方法的准确率对比
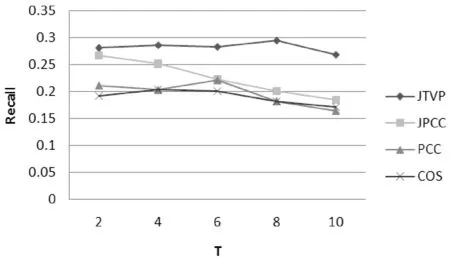
图5 MovieLens-2中不同方法的召回率对比
图2和图3表示使用MovieLens-1数据集时,在不同的时间梯度上四种相似度算法在准确率和召回率上的对比结果。由图可以看出随着时间梯度的增加JPCC、PCC、COS推荐算法在准确率和召回率上都出现了下滑趋势。而JTVP推荐算法依然能保持较高的准确率和召回率。
图4和图5表示使用MovieLens-2数据集时,在不同的时间梯度上四种相似度算法在准确率和召回率上的对比结果。由于数据集的不同其准确率和召回率在大体程度上存在些差异,但可以由图看出JTVP推荐算法依然能保持较高的准确率和召回率。而其他三种推荐算法在准确率和召回率上依然出现了下滑的趋势。
实验结果表明加入时间向量算子的JTVP推荐算法能有效的解决随着时间推移用户兴趣发生变化而带来的推荐质量的下滑问题。
4 结 语
针对用户的兴趣一般在短期的时间间隔内保持稳定但在长期时间跨度内不同用户的兴趣变化是不确定的情况。本文提出了杰卡德时间向量皮尔逊相似度算法JTVP,采用时间向量算子tvo把用户的评价加入时间认知。同时,引入杰卡德系数对皮尔逊相关系数相似度模型对相似度算法加以完善提升,从而确定用户相似度的最佳模型;然后对相似邻近的用户评价的产品进行预测,选出最有可能被用户接受的产品,并推荐给用户。最后在时间梯度上把不同推荐算法的准确度和召回率进行比较、分析。实验结果表明融入时间向量算子的JTVP推荐算法能有效地解决因用户兴趣变化而带来的推荐质量的下滑。从而说明本文提出的杰卡德时间向量皮尔逊相似度算法JTVP在应对用户兴趣变化方面是有效并可行的。
随着大数据时代的到来,网络的规则将变得越来越完善,各大网络公司的合作及数据共享会变得越来越频繁。越来越多用户将只需一个账号就可以登录各大网站,从而让网站为自己提供自己的专属服务。这时用户-产品矩阵会更加密集,用户的数据会更加丰富精确,融合时间向量算子的协同过滤推荐算法的准确率将会得到进一步的提升。
[1]LiWJ,XuYY,DongQ,etal.TaDb:Atime-awarediffusion-basedrecommenderalgorithm[J].InternationalJournalofModernPhysicsC,2015,26(9):5-9.
[2]CandillierL,MeyerF,FessantF.Designingspecificweightedsimilaritymeasurestoimprovecollaborativefilteringsystems[C]//IndustrialConferenceonAdvancesinDataMining:MedicalApplications,E-Commerce,Marketing,andTheoreticalAspects.Springer-Verlag,2008:242-255.
[3]AhnHJ.Anewsimilaritymeasureforcollaborativefilteringtoalleviatethenewusercold-startingproblem[J].InformationSciences,2008,178(1):37-51.
[4]WeiS,YeN,ZhangQ.Time-AwareCollaborativeFilteringforRecommenderSystems[M]//PatternRecognition,2012:663-670.
[5]ResnickP,IacovouN,SuchakM,etal.GroupLens:anopenarchitectureforcollaborativefilteringofnetnews[C]//Proceedingsofthe1994ACMConferenceonComputerSupportedCooperativeWork.ACM,1994:175-186.
[6]BreeseJS,HeckermanD,KadieC.Empiricalanalysisofpredictivealgorithmsforcollaborativefiltering[C]//FourteenthConferenceonUncertaintyinArtificialIntelligence,2013:43-52.
[7] 孙慧峰.基于协同过滤的个性化Web推荐[D].北京:北京邮电大学,2012.
[8] 项亮.推荐系实践[M].北京:人民邮电出版社,2012:36-73.
[9] 成军.面向电子商务的协同过滤推荐算法与推荐系统研究[D].南京:南京理工大学,2013.
RESEARCH ON DYNAMIC MULTI SOURCE TIME COGNITIVE RECOMMENDATION ALGORITHM
Li Jingzhao1,2Zhu Dongjun2Tan Dayu2
1(FacultyofElectricalandInformationEngineering,AnhuiUniversityofScienceandTechnology,Huainan232001,Anhui,China)2(FacultyofComputerScienceandEngineering,AnhuiUniversityofScienceandTechnology,Huainan232001,Anhui,China)
A good recommendation algorithm is becoming very important in today’s intelligent web applications. In this paper, we propose a time cognitive recommendation algorithm. Traditional recommendation algorithms often use early and recent evaluations indiscriminately, ignoring user interest changes over time. And user interests remain stable over short periods of time but change over a long period of time. Based on the existing cooperative filtering recommendation algorithm, the time vector factor is used to motivate the recent records or weaken the early records in order to achieve the purpose of more effective classification of similar interests. The results show that the proposed method can effectively improve the accuracy and efficiency in the intelligent web.
Intelligent web Time vector factor Collaborative filtering recommendation User interest changes
2016-07-21。国家自然科学基金项目(61170060);安徽省学术与技术带头人学术科研活动资助项目(2015D046);安徽省高等学校优秀拔尖人才项目(gxbjZD2016044)。李敬兆,教授,主研领域:机器学习。朱东郡,硕士生。谭大禹,硕士生。
TP39
A
10.3969/j.issn.1000-386x.2017.02.010
