基于可能性分布合成的车辆提取方法
2017-01-19张燕
张 燕
(山西传媒学院,山西 晋中 030619)
基于可能性分布合成的车辆提取方法
张 燕
(山西传媒学院,山西 晋中 030619)
为了综合机载激光扫描与测距系统(LIDAR)异源数据所能提供的车辆高度、强度及轮廓等信息,减少目标与特征对应关系不明确对车辆识别的影响,以取得更好的车辆识别效果,提出了基于可能性分布合成的 LIDAR数据车辆提取方法。首先,定义了差值融合规则对LIDAR首次回波与末次回波图像进行融合,并依据高度特征和面积特征分离地物点并去除大面积联通区域,提取出车辆预识别区域;其次,提取二值图像中的区域长宽比特征,并结合强度图像与可见光图像构建区域强度比特征;最后,对两种特征分别构造可能性分布,并进行分布的合成,以实现异源数据的协同决策。实验证实该方法有效。
机载激光扫描与测距系统数据;车辆提取;可能性分布合成;决策
监测和识别车辆能够为交通规划、高峰期车流量估计和车辆统计等应用提供数据依据[1]。学者们早期应用遥感航空影像数据进行车辆的识别和提取。但由于数据分辨率过低,并且大部分遥感影像中都会掺杂大量的噪声,导致车辆识别难以进行。特别是在城市中,由于高大建筑物和树木的遮挡,车辆常停在阴影处,使得车辆的识别更加困难。Eikvil等[2]对利用卫星图像进行车辆识别的方法进行了总结,并归纳出导致卫星图像识别车辆准确率低的 2个原因:①车辆受到阴影的遮挡,使的识别难以进行;②由于车辆停的位置一般在马路两侧,因此很容易与人行道周边的低矮树木混淆,导致识别错误。
近年来,用于车辆识别的数据从单一的光谱图像转变为与机载激光扫描与测距系统(light detection and ranging data,LIDAR)数据相结合。LIDAR系统能够获取地物不同的信息,如高程和强度。孙美玲等[3]提出了一种基于像素和面向对象分类的汽车提取方法,构造了多种特征进行汽车判别,但由于对多特征的决策是“与”的关系,导致实验结果漏检率较高。Yao等[4]通过分析地物类别间关系进行点云滤波,将汽车分类为地面点,然后采用提取感兴趣区域(region of interest,ROI)和标记控制分割的方法提取汽车,由于在提取过程中未考虑区域特征,导致识别率较低,而且实验区域地物类别较单一,无法证实方法的鲁棒性。Zhang等[5]融合LIDAR数据和光谱图像中的数据进行车辆检测,首先利用光谱图像中的区域特征生成潜在区域,再根据LIDAR数据中提供的信息进行相关车辆的识别,该方法相比基于视觉的方法效果有所提升。另外,许多监督分类方法如支持向量机和马尔科夫随机场等,需要训练大量的样本,消耗时间。
汽车具有特殊的形状特征和材料特质,因此在各LIDAR数据源中能表现出较强的区域一致性,利用区域特征进行汽车识别能够得到较好的效果[6]。但由于LIDAR数据的多样性,在结合不同性质的数据构建特征时,难以利用特征值的大小对该区域是否为车辆进行判断,即车辆的特征值范围是不确定的,并且这种不确定性用传统概率及经典集合无法表征。可能性理论是一种日渐成熟的处理不确定性问题的方法[7],其通过建立可能性分布来实现对不确定性信息的表征,并且利用适当的分布合成规则及决策规则实现对多种不确定信息的统一决策。因此本文利用可能性分布合成理论来进行车辆提取,通过构造各特征的可能性分布,并对其进行合成,达到多特征协同决策的目的,实现车辆的提取与统。
1 特征提取
1.1 方法框架
车辆提取方法的流程(图1):①进行地物的粗划分。利用差值融合方法对首、末次高程回波进行融合,得到包含地物高程信息的融合图像。基于统计信息构建车辆的高程阈值与面积阈值,并分别对融合图像进行阈值划分,得到车辆预识别区域。②构建强度比和区域长宽比两种特征,并分别构造相应的可能性分布。③利用T-模、S-模等算子构造可能性分布合成规则进行分布的合成,决策得到最终的分类结果。

图1 本文方法的框架
1.2 特征空间
(1) 高度特征。车辆的高度处于地面和建筑之间,而且与两者有着明显的高度差,因此在高程图像中的特征较明显,可根据统计信息设立阈值将车辆区域识别出来。从表1中统计的常见车辆尺寸信息可知,车辆高度范围一般为1.3~2.2 m。
(2) 区域面积特征。从表1中可看出,常见车辆的长度范围在3.6~5.5 m,宽度范围在1.5~2.2 m,因此车辆区域的面积范围为

(3) 长宽比特征。其是一个表征车辆轮廓信息的统计特征,由于车辆的俯视图外形近似于长方形,且其长度和宽度都在一定范围内,因此其长宽比范围也较固定。确定车辆所在区域的外接矩形,并根据表1确定车辆区域的长宽比的范围
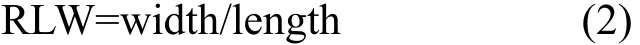
(4) 区域强度比特征。该特征的构建利用了车辆材质不同于其他地物的特点,车顶的材质一般为金属,而激光在金属上的反射率较大,使得在强度图像中,车辆区域有较大的灰度值。另外,将可见光图像从RGB颜色空间转化为HIS空间,其中,H表示图像的色调;I表示亮度或强度,S表示色饱和度。由于光反射原理,车辆在亮度图I中也有较大的值。根据以上物理原理,以结构相似度为基础构建区域强度比特征如下
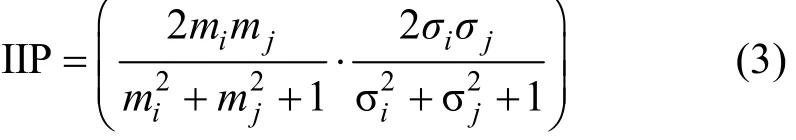
其中,m为均值;σ为方差;i为HIS空间中的I分量;j为LIDAR强度值。结构相似度是评价图像相似程度的重要评价指标,因此IIP特征可用来描述车辆区域的LIDAR强度图像与HIS空间中的强度值的相似程度,并且两种特征值越相似,IIP的值越接近1。

表1 常见车型的外型信息(m)
2 识别方法
2.1 预识别区域提取
2.1.1 高程阈值分类
在以往的地物分类过程中,由于LIDAR数据首次回波DSMFE与DSMLE末次回波两种特征在大部分地物中都表现出较强的一致性,常将二者相减构建HD(height difference)特征,以突显建筑边缘及树木顶端等差异特征。文中DSMFE与DSMLE在汽车区域的特征相近,但DSMFE受到树木遮挡的影响,使得部分汽车无法识别。因此本文提出了一种针对高程图像中车辆提取的差值融合方法,公式如下

其中,Max为取大操作,选取 DSMFE和 DSMLE中高程值较高的点;Imdilate为形态学膨胀操作,可扩大HD特征中的边缘信息。融合图像可包含较好的车辆高程信息,且去除了首末次回波中的差异信息。同时,由于HD中建筑边缘特征明显,将其减去可将位置与建筑极为相近的车辆分开,避免利用面积阈值进行划分时,将建筑与车辆化为同一区域。DSMFE、DSMLE和融合结果分别如图2(a)~(c)所示。根据表1中数据统计可知,车辆高度下限为1.3 m左右,以此为阈值将低于1 m的地物像素赋值为0,得到二值化图像,如图2(d)所示。
2.1.2 面积阈值分类
根据1.2节中描述的面积特征,提取满足车辆面积范围的区域,作为车辆预识别区域,并进行形态学的腐蚀膨胀处理,以修正区域的边缘,突显特征。文中使用的LIDAR数据分辨率为0.5 m,因此每个像素所代表的区域面积为0.25 m2(图3)。

图2 高程阈值分类

图3 汽车预识别区域
2.2 可能性分布合成理论
可能性理论由 Zadeh通过将可能性的概念与模糊集合紧密联系起来于1978年首次提出,并对可能性分布的概念进行了定义[8]。在随后的几年里,苏志远等[9-11]通过深入研究进一步将可能性理论发展并丰富。可能性分布是可能性理论中的一项重要内容,能够对事物变化的可能性进行预测,并且适用于少量数据的表征与度量;能够有效描述几何间多变的映射,计算复杂度低,在系统可靠性分析、故障诊断及风险评估等领域具有广泛的应用价值。本文使用的两种区域特征,均可通过统计得到其概率分布,且由于区域数量较多,因此使用适用于大量样本的概率分布——可能性分布的转化方法进行可能性分布的构造[12]。
2.2.1 概率分布到可能性分布的转换
如果一个支集为[a,b]的连续概率分布p,p在[a,u0]上为单调递增函数,在[u0,b]上为单调递减函数,u0为单峰值点,即

通过p得到具有最大确定性的最优转换
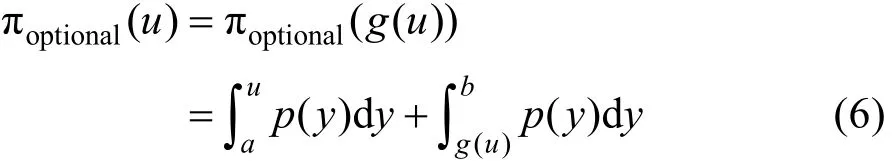

在工程应用中,由于信息匮乏或测量信息精度有限,可采用截性三角形转换来近似最优转换。转换形式为

其中,um、un、uε1和uε2满足 p( um) =p( un)、p( uε1) = p( uε2)。截性三角形近似转换参数如表2所示,其中σ为概率分布的方差;u0为均值。

表2 正态分布的截性三角形近似转换参数
2.2.2 特征可能性分布的构造
经济的发展,影响了各级政府的财务资源,使其都大大增加。除了满意表演者的基本需求外,还有一些才能来树立或支撑某些项目。如何正确办理资金以及如何正确反映这些项目的融资和使用,财务办理也提出了更高的要求,但行政体系行政体系采用的会计制度难以反映上述情况。
(1) 长宽比的可能性分布构造。图3中89个车辆预选区域的上、下、左、右 4个方向的边界点,构建外接矩形,如图 4所示。利用式(2)计算各矩形的长宽比,并统计数据的概率分布,由于样本数据量较大,所以可利用正态分布直接构造其可能性分布,通过计算可得各参数:σ=0.16、u0=0.76、um=0.36、un=1.17、uε1=0.52和uε2=1,直接代入式(8),则长宽比的可能性分布函数如式(9)所示。数据的概率分布曲线和长宽比的可能性分布如图5所示。

图4 区域长宽比

图5 长宽比特征的可能性分布

(2) 区域强度比的可能性分布构造。利用正态分布构造区域强度比特征的可能性分布,通过计算可得各参数为:u0=0.5、σ=0.299、um=0.27、un=0.73、uε1=0.36和 uε2=0.64,代入式(9),则区域强度比的可能性分布函数如式(10)所示。数据的概率分布曲线和区域强度比的可能性分布如图6所示。

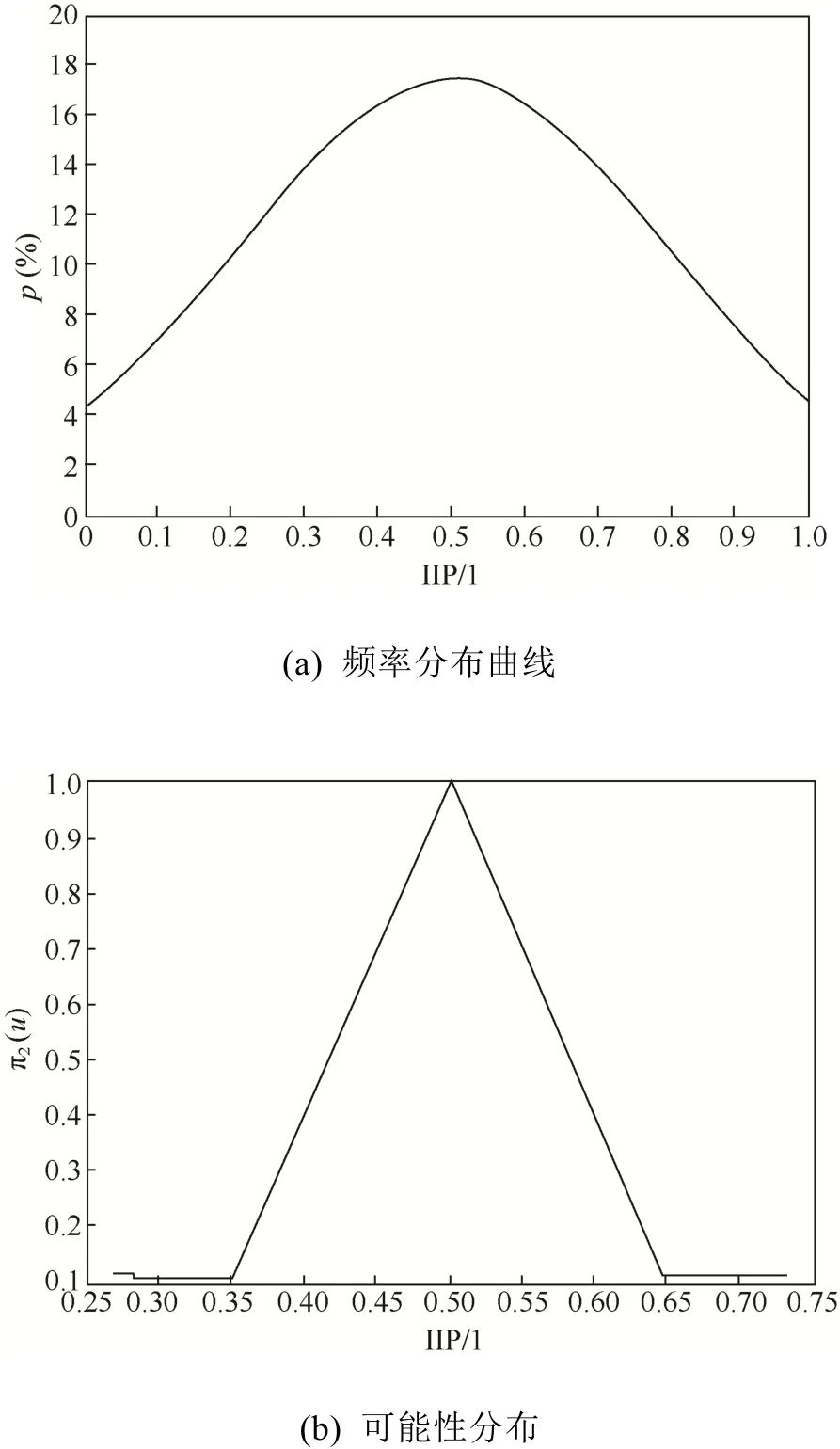
图6 区域强度比的可能性分布
2.3 可能性分布的合成与决策
可能性分布合成是指通过将同一目标或事件不同信息源的多个可能性分布按照一定的规则或方法进行综合,获得比单一可能性分布关于事件更精确、更可靠的描述与估计。
最基础的分布合成方法是利用一些算子对多个分布进行运算,这些算子包括T-模算子、S-模算子、平均算子等。在现有模糊算子的基础上,本文对可能性分布运算进行改进,已知测量数据的两个可能性分布π1和π2,构造如下的可能性分布合成规则
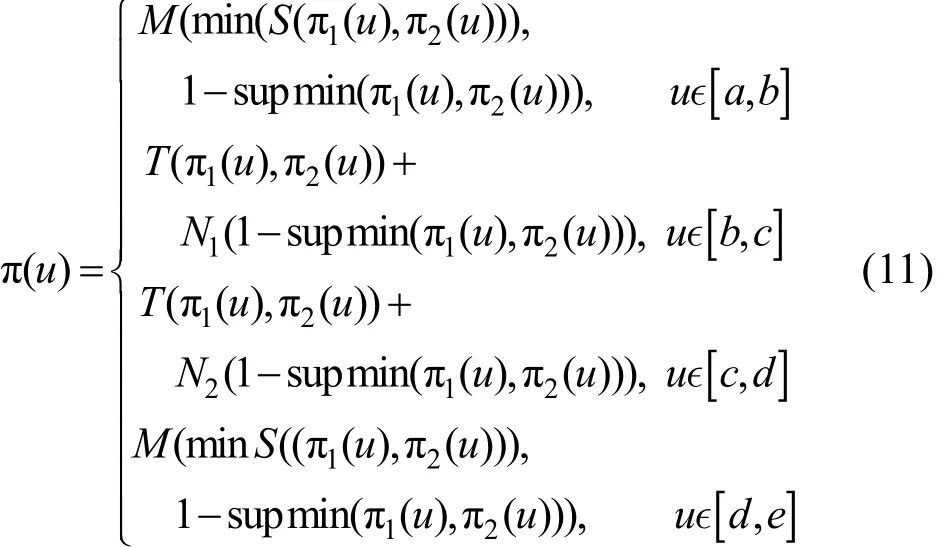
其中,T、S与M分别为T-模算子,S-模算子和平均算子;[b,c]和[c,d]为一致区间;[a,b]和[d,e]为非一致区间;N1和N2分别为两个分布的权值系数;supmin(π1(ui), π2(ui))为两个可能性分布提供信息的一致度,即两个分布交集的高度(C点高度)。根据两分布的物理意义可知:区域长宽比由车辆形状决定,而区域强度比由车辆材质决定,两分布π1和π2不相关。此时,T (π1,π2)=π1·π2,S (π1,π2)= 1 -T(1-π1,1-π2)= π1+ π2- π1·π2。同时,本文根据线性可能性分布的斜率k确定分布的权值系数为
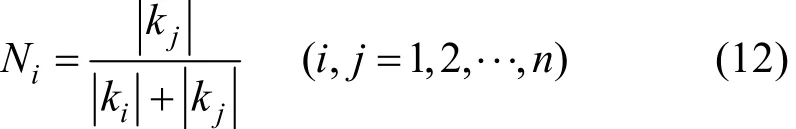
如图7(a)所示,各参数值为:a=0.36、m=0.5、b=0.52、c=(0.595 7,0.384 2)、d=0.64、n=0.76、则式(11)可写为
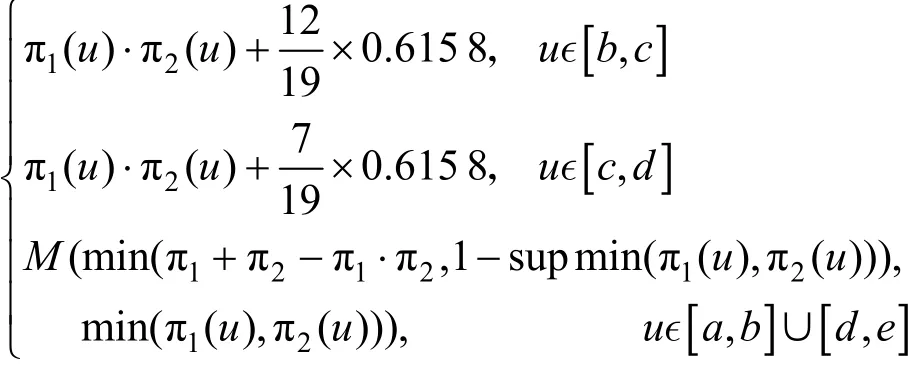
另外,依据式(11)可得可能性分布的合成结果如图7(b)所示。

图7 可能性分布的合成
3 实验
图8为实验所用到的LIDAR数据,图像大小为300×300。数据由TopoSys GmbH系统获取得到,根据特征的构造原理,在该车辆提取过程中,使用了5种LIDAR数据,分别为首次回波高程图像、末次回波高程图像、高程差图像、强度图像和RGB图像[13]。
3.2 实验结果评估
图9(a)是通过结合可见光图像与高程图像,由人工标注的用于评价分类结果的标准图;图 9(b)为本文算法的分类结果;图9(c)为用于评价分类方法有效性的评价图,其中蓝色是被正确识别的车辆,红色是非车辆区域被误识别为车辆的区域,黄色本应为车辆却未被识别出的区域。
(1) 主观评价。由图9(c)可看出,大部分的车辆被正确识别出,图10为几个漏识别和错识别区域的局部放大图,误识别区域主要有3种类型:
①与低矮树木混淆。如图10第1行所示,本文方法均将树木误识别为车辆,这主要由于这两棵树木相对比较低矮,与车辆的高度相近,因此在高程图像中无法将其进行区分;另外由于这两棵树木是孤立的,且其顶冠较茂密导致在图像中呈现出类矩形,导致在识别时产生错误。
②与垃圾桶或工具房等人造物品混淆。如图10第2行所示,在两建筑中间有一块区域,其材质和高度都与车辆相近,由其位置推断为垃圾桶或工具房等人造物品被误识别为车辆。

图8 LIDAR数据源
对于漏识别车辆,如图10(d)的上图中黄色区域,主要原因是两辆车的间隔太小,或与其他地物相邻太近,导致利用面积阈值进行判别时被去除。另外,即使是正确识别出的车辆区域,其区域内也会出现一些错误。如图10(c)的下图中右下角的区域,虽被正确识别为车辆区域,但由于与低矮树木间距离太近,使得树木与车辆被划在同一个区域内。
(2) 客观评价。本文利用准确率、漏检率与错检率 3种评价指标对该方法的有效性进行评价:错检率
其中,D为本文方法所识别出的车辆个数;K为错检数,即D中实际不是车辆区域的个数;B为漏检数,即未被准确识别出的车辆区域的个数。

图9 分类结果

图10 局部放大图
统计得到该区域实际车辆数为 38,本文算法识别出车辆数为43,其中错检数为9,漏检数为4。利用文献[3]和[4]中所提出的算法对该区域进行车辆提取,则各指标值如表3所示。

表3 提取结果评价指标(%)
从评价指标可以看出,文献[3]算法有较好的准确率,但由于该算法中的特征间“与”的组合关系,其漏检率远高于本文算法;文献[4]中方法适用于大面积区域,但由于过分割的问题,其对于文献[4]中试验区域和本文数据的识别准确率均较低,无法满足实用需求。本文算法能综合各种LIDAR数据的优势,将可见光图像中难以识别的车辆准确识别出,准确率能够达到89.4%,同时错检率和漏检率均在可接受范围内,能够满足多数应用的需求。
4 结 论
本文提出了一种基于可能性分布合成的LIDAR数据车辆提取方法,通过构建4种车辆特征,并对特征进行可能性分布的构建及合成,实现了 LIDAR数据中的车辆识别。综合了LIDAR系统中多源数据的特点,减少了目标与特征对应关系不明确对车辆识别的影响,取得了较好的车辆识别效果,为车辆识别提供了一种新方法。
[1] 张 勇, 牛成磊, 谷正气, 等. 结合SURF与SVM的高分遥感影像车辆提取技术[J]. 湖南工业大学学报, 2014, 28(2): 67-71.
[2] Eikvil L, Aurdal L, Koren H. Classification- based vehicle detection in high-resolution satellite images [J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2009, 64: 65-72.
[3] 孙美玲, 李永树, 陈 强, 等. 基于机载LiDAR点云高程和强度数据的城区汽车目标自动提取[J]. 遥感信息, 2014, 29(5): 73-77.
[4] Yao W, Hinz S, Stilla U. Automatic vehicle extraction from airborne LIDAR data of urban areas aided by geodesic morphology [J]. Pattern Recognition Letters, 2010, (31): 1100-1108.
[5] Zhang F H, Clarke D, Knoll A. Vehicle detection based on LIDAR and camera fusion [C]//2014 IEEE 17th International Conference on Intelligent Transportation Systems (ITSC). New York: IEEE Press, 2014: 1620-1625.
[6] Yang B, Sharma P, Nevatia R. Vehicle detection from low quality aerial LIDAR Data [C]//In IEEE Computer Society’s Workshop on Applications of Computer Vision (WACV), 2011. New York: IEEE Press, 2011: 541-548.
[7] Ji L N, Yang F B, Wang X X, et al. An uncertain information fusion method based on possibility theory in multisource detection systems [J]. Optik, 2014, (125): 4583-4587.
[8] Dubois D, Prade H. The legacy of 50 years of fuzzy sets: a discussion [J]. Fuzzy Sets and Systems, 2015, (281): 21-31.
[9] 苏志远, 刘 慧, 李秋萍. 基于模糊C均值图像抗噪分割方法的研究[J]. 图学学报, 2015, 36(3): 477-484.
[10] 吉琳娜. 可能性分布合成理论及其工程应用研究[D].太原: 中北大学, 2015.
[11] 周新宇. 基于多源信息不确定性的可能性融合方法研究[D]. 太原: 中北大学, 2012.
[12] 吉琳娜, 杨风暴, 王肖霞, 等. 基于库水位的坝体安全等级的可能性分析方法[J]. 计算机工程与应用, 2013, 49(11): 224-227.
[13] 冯裴裴, 杨风暴, 卫 红, 等. 基于正态DS证据理论的机载LIDAR数据地物分类方法[J]. 图学学报, 2015, 36(6): 926-930.
A Vehicle Detection Method Based on Fusion Theory of Possibility Distribution in LIDAR Data
Zhang Yan
(Communication University of Shanxi, Jinzhong Shanxi 030619, China)
In order to obtain a better vehicle recognition result, this paper proposed a method based on the synthesis of probability distribution of light detection and ranging (LIDAR) data to extract vehicle. By fusing the characteristics of the multi-sources of LIDAR data, and reducing effect caused by the corresponding unclear relationship between objectives and features. Firstly, a difference fusion rule of LIDAR first and last echo image was defined. The height and area feature were obtained and large area Unicom areas were removed, the pre-recognition areas of the vehicle were extracted. Secondly, the value of ratio of length and width of pre-recognition areaswere extracted, and the regional strength characteristics were constructed by combing the intensity image and visible images. Finally, the possibility distributions of these two features were constructed. After fusion and making collaborative decisions, results were obtained. Heterogeneous data proved that this method is effective.
light detection and ranging data; vehicle detection; fusion of possibility distribution; decision making
TP 751.1
10.11996/JG.j.2095-302X.2016060791
A
2095-302X(2016)06-0791-08
2016-04-14;定稿日期:2016-05-21
张 燕(1981−),女,山西运城人,讲师,硕士。主要研究方向为信号与信息处理。E-mail:zhangyan_05@126.com
