基于分布结构自适应筛选的数据库存储优化设计
2017-01-16戚斌
戚 斌
(陕西国防工业职业技术学院,西安 710300)
基于分布结构自适应筛选的数据库存储优化设计
戚 斌
(陕西国防工业职业技术学院,西安 710300)
通过对数据库的存储结构优化设计,提高数据库的吞吐量。传统方法采用存储节点校验数据适应度分区的数据库存储模型,数据库中存在重复冗余数据,不能自适应滤除,导致数据存储开销较大;提出了一种基于分布结构自适应筛选的数据库存储优化模型,首先进行数据库的存储机制和分布式数据结构分析,采用相空间重构方法进行存储空间的结构分布重组,采用分布结构自适应筛选方法对提取的数据信息流进行重复冗余数据滤波处理,改善数据在数据库存储空间中的结构分布,实现数据库存储优化;仿真结果表明,采用改进的方法进行数据库构建,能提高数据库存储吞吐量,降低数据存储开销,提高数据库的访问和调度性能,展示较好的应用价值。
分布结构;自适应;数据库;存储;相空间重构
0 引言
在信息化社会,随着网络信息和大数据信息规模的扩大,大量的数据信息需要存储和优化调度管理,数据库是按照数据结构来组织、存储和管理数据的仓库,充分有效地利用数据库进行信息管理和访问,能提高对各类信息资源的利用和调度能力。数据库的种类很多,比如网络数据库、本地数据库、DeepWeb数据库等,数据库的规模大小根据需要处理的数据规模而有差异性,从最简单的存储有各种数据表格到能够进行海量数据存储的大型数据库系统,在数据管理中都发挥着重要的价值。数据库的存储性能是评价数据库有效性的重要指标,通过对数据库存储结构优化设计,提高数据库吞吐量,研究数据库的优化存储设计具有重要意义[1-4]。
数据库的优化存储设计,对实现管理信息系统、办公自动化系统、决策支持系统等各类信息系统的优化具有重要意义,传统方法中,对数据库的存储设计采用的方法主要有基于分布式建模的数据库存储模型、基于决策树模型的数据库存储方法和基于语义本地模型的数据库存储方法等,分布式网络数据库实体模型挖掘和存储算法采用的是支持向量回归机学习方法,通过构建模糊决策模型,实现对分布式网络数据库的实体模型构建方法,参数设置复杂,具有不稳定性。为此,相关文献进行数据库存储模型的改进设计。其中,文献[5]提出一种基于关联为特征分析和最大Lyapunove指数谱分解的调数据库访问和存储优化设计,实现对数据库中的关键字的自适应分区调度和存储,提高数据库存储的吞吐量,但是该算法计算开销较大,数据库占有的冗余空间较多;文献[6]提出一种基于关键词分区调度额的数据库存储技术,在数据库访问实验中,通过关键字有向图模型和语义特征的两个特征矢量进行线性自适应特征提取,对Web数据库并集处理,实现对数据库中的两个相关度最低的Web数据集属性提取,提高数据库存储性能,但是该方法的抗干扰性能不好,需要进行数据库的优化设计和改进;文献[7]采用存储节点校验数据适应度分区方法构建数据库存储模型,数据库中存在重复冗余数据时,不能自适应滤除,导致数据存储开销较大。针对上述问题,本文提出一种基于分布结构自适应筛选的数据库存储优化模型设计方法,首先进行数据库存储机制和分布式数据结构分析,采用相空间重构方法进行存储空间的结构分布重组,采用分布结构自适应筛选方法,对提取的数据信息流进行重复冗余数据滤波处理,改善数据在数据库存储空间中的结构分布,实现数据库存储优化,最后通过仿真实验进行性能测试,展示本文方法在优化数据库存储优化设计中的优越性能,得出有效性结论。
1 数据库的存储机制及分布式数据结构分析
1.1 数据库的存储机制及模型总体构建
通过构建分布式环境下数据库的存储机制模型,对数据库中数据结构信息特征进行采样,实现数据库存储优化,设A⊂V,B⊂V且A∩B=φ,进行分布式环境下散乱点云数据的数据结构分析,假设分布式数据库中的特征空间采样数据集X={x1,x2,…,xn},进行分布式数据库的数据存储机制体系分析,采用子图近似同构的本体模型A、B,进行数据存储结构的自动筛选和自相关特匹配,设满足待匹配本体的关系模型G(A)、G(B)的数据库分布特征点
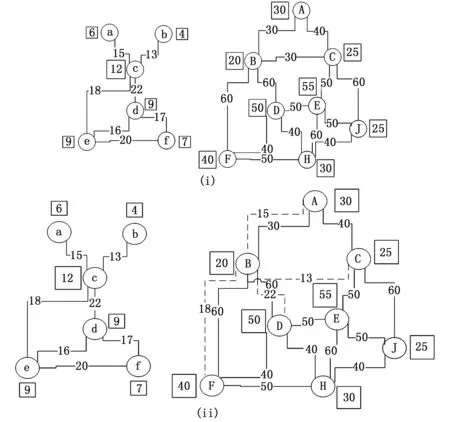
图1 大型分布式的数据库存储结构模型
分布式数据库存储结构中,数据库有向图的边(u,v)∈E,分布式数据库存储阵列节点都有相同的存储介质特征,记为r,设A⊂V,B⊂V且A∩B=φ,进行数据结构分析,抽取数据库访问特征序列的相空间模糊度点集,把数据队列当作一个Chunk来进行分块,得到数据信息流时间序列的多用户队列支持集为:
(1)
其中:t0和tg分别表示大数据特征分类的调度时长和存储开销;T0和Tg分别表示分布式数据库中的数据云存储停滞步数及阈值。采用分数阶Fourier变换进行分布式数据库存储结构特征提取和大数据特征匹配,此实现对数据的结构分析,对于数据库存储结构中的散布阵列,数据库存储的分布特征子集Si(i=1,2,…,L)满足以下条件:
Si∩Sj=φ,∀i≠j
(2)
(3)
其中:i为大型分布式网络级联数据库的存储节点个数;Sink表示数据库中根节点。在对数据库中的存储数据特征分类过程中,假设在决策树模型上任意分枝Ti(i=1,2…,m,m为sink根节点)长度为Ni(Ni≥1),在邻近点(t-t′,f-f′)上通过相空间重构和自适应寻优,实现对数据库的优化存储。
1.2 数据库中存储数据信息流模型构建和时间序列分析
在上述进行数据库的存储机制及分布式数据结构分析的基础上,进行数据库中存储数据信息流模型构建,采用非线性时间序列分析方法进行数据库的优化存储结构设计,在分布式数据库存储结构中,数据存储和调度信息流时间序列模型为:
(4)
其中:amn称作分布式数据库存储结构中的存储空见包络幅值,在数据库存储介质中,为适应数据结构的特征分布需求,采用多元自回归模型构建数据库数据存储点的适应度函数如下:
fij=wtδt+wcδc+wqδq+wsδs
(5)
其中:wt+wc+wq+ws=1;t代表数据库存储和访问的调度时间(time);c代表数据库存储的开销代价(cost);q代表数据库进行数据存储的质量(quality);s代表数据库的安全性能(security)。采用相空间重构模型,对数据库中的各个存储子集进行空间特征重组,得到数据库存储节点满足适应度函数的概率分布为:
Xp(u) =
(6)
其中:p为分布式数据库存储结构的阶数;数据库中的数据信息流特征分类为a=pπ/2(π/2的非整数倍,即p为分数)。在此基础上,采用非线性时间序列分析方法进行数据库存储系统中信息流时间序列重构,重构表达式为:
(Fp)-1=F-p
(7)
Fc1p1+4[f(t)]=Fc1p1F4[f(t)]=Fc1p1[f(t)]
(8)
其中:f(t)为存储空间内的特征匹配傅里叶系数;Fc1p1为数据库中分布结构对数据的分类输出。设任意两个聚类簇Mi与Mj中心距离为Clustdist(Mi,Mj),当(i≠j,1≤i≤q,1≤j≤q),数据库中存储数据信息流模型能唯一映射数据库中的存储结构多普勒频移,以此为基础,得到数据库中重构的相空间为:
Fp[x(t)ejwτ]=Xp(u-vsina)
(9)
其中:Xp为数据库中存储数据使得谱分析特征;u为数据库的分布结构尺度特性;v为分数阶Fourier变换的正交基函数。通过上述对数据库的分布式存储结构分析和重组,进行数据库的优化存储设计。
2 数据库存储优化设计与实现
2.1 问题的提出和数据信息流重复冗余数据滤波处理
在上述进行数据库中存储数据信息流模型构建和时间序列分析基础上,通过对数据库的存储结构优化设计,提高数据库的吞吐量,分析得出,传统方法采用存储节点校验数据适应度分区的数据库存储模型,数据库中存在重复冗余数据时,不能自适应滤除,导致数据存储开销较大。为克服传统方法的弊端,本文提出一种基于分布结构自适应筛选的数据库存储优化模型,采用相空间重构方法进行存储空间的结构分布重组的基础上,采用分布结构自适应筛选方法对提取的数据信息流进行重复冗余数据滤波处理,在存储空间中,大数据分布重复冗余数据矢量为:
f(x)=βe-βx
(10)
数据库存储结构内部的任意组存储节点样本i,vi,采用最小竞争集来描述一个存储节点对数据库的存储开销,得到最优竞争节点u对冗余数据的特征衰减函数为:
CS(u)=N(p(u))∪(∪v∈N(u)Ch(u)CH(v)){u,p(u)}
(11)
对于分布式数据库链路中的两个节点C1(Ex1,En1,He1),C2(Ex2,En2,He2) ,通过分数阶Fourier域特征重组产生出n个结构分布区域,构建模糊隶属函数,在重组的多径特征空间中进行数据库的存储机制索引,索引映射为:
xn=[x(0),x(1),…,x(N-1)]T
(12)
存储空间内数据分布的训练样本集为X=[X1,X2,…,Xk,…,XN]T,其中任一训练样本为Xk=[xk1,xk2,…,xkm,…,xkM],把数据库中的冗余数据和重复数据的文件块及文件块的标签信息通过自适应匹配滤波进行删除处理,假设自适应匹配滤波的检测函数为:
-3[x(n)x(n+τ)][x2(n+τ)]
(13)
其中:[g(n)]表示对存储结构中的冗余数据取均值,假设h(·)为冲激响应特征函数。定义分数阶Fourier变换实现对重复冗余数据滤波和宽频带数据特征压缩,得到数据库中的存储数据进行重复冗余数据滤波后的输出向量集为:
X=Fα·x
(14)
其中:
X=[Xα(0),Xα(1),…,Xα(N-1)]T
(15)
采用分布式结构自适应筛选,进行数据存储区域的自动分区,得到分区后的数据分布信息流矩阵为:
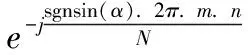
(16)
由此实现对数据库存储系统中的重复数据信息流滤波处理,提高数据库存储的效能的同时,降低数据库存储的开销。
2.2 数据库存储结构优化设计与实现
在上述进行数据信息流的重复冗余数据滤波处理的基础上,进行数据库的存储机制和分布式数据结构分析,改善数据在数据库存储空间中的结构分布,实现数据库存储优化。在分布式数据库中,由于数据存储空间的结构特性和存储介质的物理特性,导致各个存储节点之间存在干扰特征向量,采用分布结构自适应筛选方法进行数据库存储优化,假设在数据库存储空间内的存储介质的性能衰减函数为:
(17)
其中:k表示分布式数据库的特征融合中心,由数据信息流的IMF分量进行数据信息融合,得到数据库中存储数据的信息融合集合为:
P={p1,p2,…pm},m∈N
(18)
其中:m为数据信息流融合的嵌入维,N为数据采样个数,对融合后的数据进行自适应校验,进行数据存储空间的自适应特征提取,得到提取结果为:
flowk={n1,n2,…,nq},q∈N
(19)
式中,q表示数据的分布时宽,nq表示数据库存储信息流的时间序列单元,N表示信息位总数。数据库存储结构内部的任意组存储节点样本xi,i=1,2,...,n的发散幅值表达式为:
(20)
其中:数据的多普勒频率散布函数簇ψa,b是由ψ(t)通过自适应平滑更新得到,对各宽频带分量采用能量检测和波束形成实现数据库的分布式存储结构的自适应筛选和分区,其中,数据结构中的频率散布(频率标准差)为:
(21)

3 仿真实验与结果分析
为了测试本文算法在实现数据库存储结构优化,降低存储开销中的性能,进行仿真实验。仿真硬件的CPU为Intel® CoreTMi7-2600,采用Matlab仿真工具进行数学仿真。分布式数据库中存储数据的数据格式为VMDK、EXE等格式,首先对分布式数据库中的数据存储资源信息及冗余数据集进行特征采样,分布式数据库中数据信息流的测试数据采集的样本个数为1024,数据存储的开销从100 MB到1 GB递增,特征采样的频率为12 kHz,采样带宽为16.3 dB,数据库中杂质数据干扰强度为19 dB,数据信息流的最小融合阈值为2.24,进行相空间重构的嵌入维数为m=12,数据集采样的时间延迟为τ=1.45,根据上述参数设定,进行数据库存储性能仿真,通过对数据库1 000次访问,得到数据库中存储数据的采样信息流时域波形如图2所示。

图2 数据库中存储数据的采样信息流时域波形
上述数据库中存储数据的采样信息流时域波形描述了各个存储分布区间上的特征采样,以此为测试样本数据集,采用相空间重构方法进行存储空间的结构分布重组,采用分布结构自适应筛选方法,对提取的数据信息流进行重复冗余数据滤波处理,得到滤波处理后输出的存储数据在数据库存储空间中的特征分布如图3(a)所示,为了对比算法性能,给出没有进行重复冗余数据滤波处理的数据库存储结构特征分布如图3(b)所示。
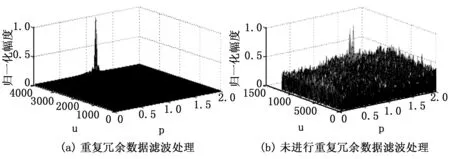
图3 数据库存储空间特征分布
从图可见,采用本文方法进行数据库存储空间优化,通过分布结构自适应筛选和重复冗余数据滤波,提高对干扰数据的抑制能力,增强了数据库的存储吞吐性能,降低了存储开销,为定量分析算法性能,采用本文方法和传统方法,以数据库存储开销为测试技术指标,得到仿真结果如图4所示,从图可见,采用本文方法进行数据库存储,存储开销比传统方法降低效果显著,提高了数据库的访问和调度性能。
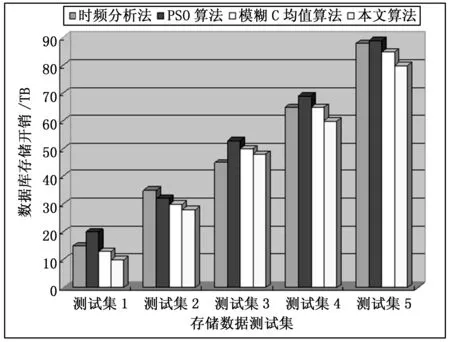
图4 数据库存储性能对比分析
4 结束语
本文研究数据库的优化存储问题,通过对数据库的存储结构优化设计,提高数据库的吞吐量,提出一种基于分布结构自适应筛选的数据库存储优化模型,首先进行了数据库的存储机制和分布式数据结构分析,采用相空间重构方法进行存储空间的结构分布重组,采用分布结构自适应筛选方法,对提取的数据信息流进行重复冗余数据滤波处理,改善数据在数据库存储空间中的结构分布,实现数据库存储优化。仿真结果表明,采用该方法进行数据库构建,能提高数据库存储吞吐量,降低数据存储开销,提高数据库的访问和调度性能,测试指标优于传统方法。
[1] 张 磊,王 鹏,黄 焱,等.基于相空间的云计算仿真系统研究与设计[J].计算机科学,2013,40(2):84-86.
[2] 文天柱,许爱强,程 恭.基于改进ENN2聚类算法的多故障诊断方法[J].控制与决策,2015,30(6):1021-1026.
[3] 余晓东,雷英杰,岳韶华,等.基于粒子群优化的直觉模糊核聚类算法研究[J].通信学报,2015,20(5):99.
[4] 关学忠,皇甫旭,李 欣,等.基于正态云模型的自适应变异量子粒子群优化算法[J].电子设计工程,2016,23(8):64-67.
[5] 阎 芳,李元章,张全新,等.基于对象的OpenXML复合文件去重方法研究[J].计算机研究与发展,2015,52(7):1546-1557.
[6] Kareem I A, Duaimi M G.Improved accuracy for decision tree algorithm based on unsupervised discretization[J].Int. J.of Computer Science and Mobile Computing,2014,3(6):176-183.
[7] Kumar A,Pooja R, Singh G K.Design and performance of closed form method for cosine modulated filter bank using different windows functions[J].International Journal of Speech Technology,2014,17(4):427-441.
[8] 衣晓蕾,彭思龙,栾世超.基于算子和局部正交约束的信号自适应分解方法[J].电子与信息学报,2015,37(11):2613-2620.
[9] 田 刚,何克清,王 健,等.面向领域标签辅助的服务聚类方法[J].电子学报,2015,43(7):1266-1274.
[10] Rajapaksha N,Madanayake A,Bruton L T.2D space-time wave-digital multi-fan filter banks for signals consisting of multiple plane waves[J].Multidimensional Systems and Signal Processing,2014,25(1):17-39.
Database Storage Optimization Design Based on Adaptive Filtering of Distributed Structure
Qi Bin
(Shaanxi Institute of Technology,Xi′an 710300,China)
Through optimizal designing the database storage structure, to improve the throughput of the database.Traditional methods use database storage model of storage nodes calibration data fitness divisional, repeat redundant data exists in the database, can not self-adaptive filter, resulting data storage pay expensive. Based on the distribution structure self-adaptive filter, put forward a database storage optimization model , firstly analysis database storage mechanism and the distributed data structure, use phase space reconstruction method to realize storage space reconstruction of structure distribution,to use distributed data structure self-adaptive filter to extract the data flow to repeat redundant data filtering processing,to improve the structure distribution of data in the database storage space, to realize database storage optimization.The simulation results show that the improved method of database construction can improve the database storage throughput and reduce data storage spending,to improve the interview and schedule performance of database ,to show good application value.
distributed structure; adaptive; database; storage; phase space reconstruction
2016-07-01;
2016-07-22。
戚 斌(1983-),男,陕西户县人,讲师,硕士,主要从事软件开发、数据库设计及高等职业教育方向的研究。
1671-4598(2016)12-0184-04DOI:10.16526/j.cnki.11-4762/tp
TP
A
