基于相对密度的加权一分类支持向量机
2017-01-10郑玮
郑 玮
(金陵科技学院 计算机工程学院, 江苏 南京 211169)
基于相对密度的加权一分类支持向量机
郑 玮
(金陵科技学院 计算机工程学院, 江苏 南京 211169)
提出了以相对密度的方式给训练集样本赋予权值.位于数据分布边缘的样本具有较低的相对密度,而位于数据分布内部的样本具有较高的密度.对于位于数据分布内部的样本赋予较大权值,位于数据分布边缘的样本赋予较小的权值.由于噪声通常位于数据分布外部,因此本文的方法可以赋予噪声较小的权值,从而使算法对于噪声更加鲁棒.人工数据集和UCI标准数据集的实验结果表明,该法优于用libsvm实现的一分类支持向量机方法.
加权一分类支持向量机; 相对密度; 一分类
0 引言
支持向量机由Vladimir Vapnik等于20世纪90年代提出[1].原始的支持向量机算法主要用于二分类问题.当数据集不同类别样本分布不均衡时,二分类支持向量机性能会有所下降.一种处理不均衡数据集的方法是用一分类来代替二分类.一分类支持向量机首先由Scholkopf提出[2],后来被成功用于多种问题[3-9].传统的一分类支持向量机同等的对待训练集中每一个样本,对于训练集中的噪声数据不够鲁棒,学习结果容易受到噪声影响.一种降低噪声的影响的方式是对处于训练集分布边缘的样本赋予低的权值,而对于位于数据集内部的样本赋予高的权值.通常,对于一分类支持向量机学习结果有影响的噪声位于数据集分布的边缘部分.一分类支持向量机同样实现了结构风险最小化,对于未知样本又更好的泛化性;同时一分类支持向量机具有全局最优解,并且解只由少量支持向量决定.然而,传统支持向量机具有的一些局限在一分类支持向量机中也仍然存在.如:没有考虑先验知识对学习的作用;需要一个好的核函数将训练数据映射到高维线性可分空间;需要求解一个时间和空间消耗都很大的二次规划等.
本文仅针对第一种问题,一种利用先验知识的方式是根据数据本身赋予不同样本不同权值,位于数据分布边缘与内部的样本对于一分类学习的作用不同,提出通过相对密度的方式给训练数据赋权值.位于数据分布边缘的样本相对密度较大,而位于数据分布内部的样本相对密度较小.在人工数据集和UCI标准数据集上的实验表明加权一分类支持向量机优于libsvm实现的算法.
1 相关工作介绍
如何在支持向量机中引入先验知识一直是机器学习与模式识别里的一个热门话题.一种方式是赋予不同数据不同权值,这样赋给噪声低的权值来降低噪声对于学习影响,提高算法的鲁棒性.但是,以前的工作大多关注的是二分类问题,而不是一分类问题[10-12].
加权一分类支持向量机首先由Manuele Bicego & Mario A.T. Figueiredo提出[13],并被用用于模糊聚类.在文献[14]中,作者用核概率c均值聚类算法(KPCM)给SVDD算法中样本加权.由于SVDD算法可以包含少量负类样本,KPCM算法中的聚类数设为2即可.而一分类支持向量机不包含负类样本,因此KPCM算法加权的策略不适合于一分类支持向量机.在文献[15],作者提出集成加权一分类支持向量机,在集成加权一分类支持向量机理样本权重仍然由聚类方式获得.然而,对于一个由M个一分类支持向量机组成的集成需要选择2*M的参数,因此选择一组适合的参数需要耗费大量时间.本文提出了一种非聚类方式的加权策略,且提出的策略不需要调整过多参数.
2 基于相对密度的加权一分类支持向量机
在一分类问题中,只有大量目标数据和非常少量的奇异数据可以利用.一分类问题的目的就是找到一个可以包含所有目标数据而排出所有奇异数据的数据描述.用X 表示训练数据集,数据集包含l目标{xi,i=1,…,l},xi∈Rn(n是xi的维数).x是一未知样本,一分类问题就是找到函数f(x),当x是目标数据时,f(x)返回1;否则,f(x)返回-1.
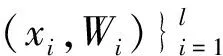
(1)
引入优化约束wTΦ(xi)-ρ+ξi≥0和ξi≥0的拉格朗日乘子αi,βi≥0,可以写出式(1)对应的拉格朗日函数:
(2)
对上式求关于w,ξ 和ρ的偏导,并令偏导数为0,可得:
(3)
(4)
将式(3)(4)带入式(1),可以得到式(1)的对偶形式:
(5)
其中,α=(α1,α2,…,αl)为拉格朗日乘子的向量形式;Q为核矩阵,Q(i,j)=K(xi,xj).显然,式(5)与一分类支持向量机的惟一区别是拉格朗日乘子约束上界,而加权一分类支持向量机与原一分类支持向量机的决策函数形式相同.当v→0,加权一分勒支持向量机等同于一分类支持向量机.
在加权一分类支持向量机中,可以通过在训练前赋予噪声较小权值来降低噪声对于学习结果的影响.
3 基于相对密度的加权方法
位于数据分布外围的噪声会引起一分类支持向量机的学习结果的偏移,因此希望赋予靠近数据分布边缘的样本低的权值,而赋予位于数据分布内部的样本高的权值,以降低噪声对学习结果的影响.而样本在数据分布中的位置与自身的相对密度有关.在文献[15]中,作者提出了样本的相对密度.样本的相对密度反映了样本周围的稠密情况.通常位于数据分布内部的样本相对密度较大,反之位于数据分布边缘的样本相对密度较小.图1显示了Iris数据集中不同位置样本的相对密度情况.
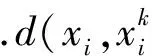
(6)
图2比较了传统一分类支持向量机与加权支持向量机在香蕉分布数据集上学习到的结果.其中训练集包含10%的高斯分布噪声.其中方框为训练样本,菱形◇为训练数据中的噪声,实现为学习到的一分类数据描述.由图2可以发现当训练集中混入10%高斯分布的噪声时传统的一分类支持向量机学习结果发生了严重的偏移,而加权一分类支持向量机仍然可以获得一个较好的学习结果.

(a) 样本位于数据分布的内部 (b) 样本位于数据分布的边缘

(a) 传统一分类支持向量机(OC-SVM) (b) 加权一分类支持向量机(WOC-SVM)
4 实验仿真

表1 无噪声时AUC值比较

表2 加入高斯噪声AUC值比较
对加权一分类支持向量机与传统一分类支持向量机作一比较.其中加权一分类支持向量机与传统一分类支持向量机均由libsvm实现[17].作为使用最广泛的支持向量机工具箱具有更高的效率,因此基于libsvm的改进也更有意义.求解样本相对密度的算法由Matlab环境下的mex接口实现,并且由VC2010编译.实验在Intel CoreTMi5-4690 CPU @3.50GHz,8GB DRAM的Windows 7机器上运行.
对于一分类问题由于只有目标可以利用(即正类样本),而奇异数据(负类数据)几乎没有.对于学习效果的评价第二类错误无法计算,本文中的实验在一分类效果上采用了ROC(Receiver Operating Characteristic) 曲线[18]和AUC(the Area Under the ROC curve) 值[19]作为评价标准.而本文的程序由Matlab实现.
首先比较了算法在人工数据集上的效果,然后比较了在UCI标准数据集[20]上的效果.与其他一分类研究类似,本节的实验结果主要比较了ROC curve和AUC值这两个指标.AUC值越大说明该一分类分类器的性能越好.

表3 加入均匀分布噪声AUC值比较

表4 UCI标准数据集
4.1 人工合成数据集
实验比较了对于Sine问题加权一分类支持向量机的效果.Sine问题中目标数据由以下方式产生:
其中,t是步长0.01在[0, 2π]范围的序列;N是均值[0, 0]T,方差0.04I(I是2*2的单位矩阵)的高斯噪声.奇异数据为均匀分布.实验中分别50,100和200个训练数据.为了验证算法对噪声的有效性,分别添加了10%,20%和30%的高斯分布噪声和均匀分布噪声. 测试数据集包含独立生成的1 000个目标数据和1 000个奇异数据. 实验重复执行50次,统计了50次实验结果AUC值的均值和标准差. 表1~表3分别表示在不加噪声以及分别加入高斯噪声、均匀分布噪声的实验结果. 算法中的参数σ和υ分别选自2-10,2-9,2-8,2-7,2-6,2-5}和{0.01,0.06,0.11,0.16,0.21}中使得AUC最大的参数组. 相对密度中近邻的取值为10.
4.2 UCI标准数据集
本文实验验证算法在UCI标准数据集:Yeast,Pima Indians Diabetes,Blood Transfusion和Satimage上的效果,如表4所示,其中括号里的数字是每一类包含的样本数.
每个数据集中包含样本数最多的类被作为目标类,其余类作为奇异数据类.没有独立测试集的数据集中目标数据被平均分为2份,一份用作训练,另一份连同奇异数据一起用作侧试.对于Satimage数据集,训练集中的目标数据用作训练,训练集中的奇异数据和测试集一起用作测试.图3~图6比较了算法的在Yeast, Pima Indians Diabetes, Blood Transfusion和Satimage的ROC value曲线.

图3 Yeast数据集ROC曲线 图4 Pima Indians Diabetes数据集ROC曲线
图中点线表示加权一分类支持向量机,虚实线表示原始支持向量机.ROC曲线面积越接近左上角算法性能也越好.可以发现在这4个数据集上加权一分类支持向量机均好于传统一分类支持向量机.
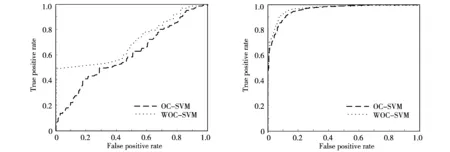
图5 Blood Transfusion数据集ROC曲线 图6 Satimage数据集ROC曲线
5 结论
提出了一种基于相对密度的加权一分类支持向量机算法.传统的一份类支持向量机由于同等的对待训练集中的所有样本,因此位于靠近数据分布边缘的噪声会对一分类支持向量机的学习结果产生偏差.由于位于数据分布边缘的训练样本通常相对密度也较小,而位于数据分布内部的训练样本相对密度较大,因此可以用样本的相对密度赋予训练样本权值.这样训练集中的噪声可以被赋予较小的权值,从而降低噪声对于学习结果的影响.在人工合成数据集和UCI标准数据上的实验结果均表明利用相对密度加权的一分类支持向量机均好于原一分类支持向量机.人工数据集上分别增加高斯噪声、均匀分布噪声的实验结果表明本文的加权方式可以使算法对于噪声更加鲁棒.
[1] Vapnik V. The nature of statistical learning theory[M]. New York:Springer-Verlag, Inc, 1995.
[2] Scholkopf B, Platt J C, Shawe-Taylor J, et al. Estimating the support of a high-dimensional distribution[J]. Neural computation, 2001, 13(7): 1443-1471.
[3] Guerbai Y, Chibani Y, Hadjadji B. The effective use of the one-class SVM classifier for handwritten signature verification based on writer-independent parameters[J]. Pattern Recognition, 2015, 48(1): 103-113.
[4] Lipka N, Stein B, Anderka M. Cluster-based one-class ensemble for classification problems in information retrieval[C]. Proceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval. ACM, 2012: 1041-1042.
[5] Cabral G G, de Oliveira A L I. One-class Classification for heart disease diagnosis[C]. Systems, Man and Cybernetics (SMC), 2014 IEEE International Conference on. IEEE, 2014: 2551-2556.
[6] Guo L, Zhao L, Wu Y, et al. Tumor detection in MR images using one-class immune feature weighted SVMs[J]. Magnetics, IEEE Transactions on, 2011, 47(10): 3849-3852.
[7] Li W, Guo Q, Elkan C. A positive and unlabeled learning algorithm for one-class classification of remote-sensing data[J]. Geoscience and Remote Sensing IEEE Transactions on, 2011, 49(2): 717-725.
[8] Cyganek B. Image segmentation with a hybrid ensemble of one-class support vector machines[M]. Springer Berlin Heidelberg: Hybrid Artificial Intelligence Systems, 2010: 254-261.
[9] Cyganek B. One-class support vector ensembles for image segmentation and classification[J]. Journal of Mathematical Imaging and Vision, 2012, 42(2-3): 103-117.
[10] Wu X, Srihari R. Incorporating prior knowledge with weighted margin support vector machines[C]. Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2004: 326-333.
[11] Yang X, Song Q, Wang Y. A weighted support vector machine for data classification[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2007, 21(5): 961-976.
[12] Karasuyama M, Harada N, Sugiyama M, et al. Multi-parametric solution-path algorithm for instance-weighted support vector machines[J]. Machine learning, 2012, 88(3): 297-330.
[13] Bicego M, Figueiredo M A T. Soft clustering using weighted one-class support vector machines[J]. Pattern Recognition, 2009, 42(1): 27-32.
[14] Zhang Y, Liu X D, Xie F D, et al. Fault classifier of rotating machinery based on weighted support vector data description[J]. Expert Systems with Applications, 2009, 36(4): 7928-7932.
[15] Krawczyk B, Wozniak M, Cyganek B. Clustering-based ensembles for one-class classification[J]. Information Sciences, 2014, 264: 182-195.
[16] Lee K Y, Kim D W, Lee D, et al. Improving support vector data description using local density degree[J]. Pattern Recognition, 2005, 38(10): 1768-1771.
[17] Chang C C, Lin C J. LIBSVM: A library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2011, 2(3): 27.
[18] Metz C E. Basic principles of ROC analysis[C]. Seminars in nuclear medicine. WB Saunders, 1978, 8(4): 283-298.
[19] Bradley A P. The use of the area under the ROC curve in the evaluation of machine learning algorithms[J]. Pattern recognition, 1997, 30(7): 1145-1159.
[20] Lichman, M. UCI Machine Learning Repository[M].Irvine CA: University of California, School of Information and Computer Science, 2013.
[责任编辑:蒋海龙]
A Weighted One-class Support Vector Machine based on Relative Density Degree
ZHENG Wei
(School of Computer Engineering, Jinling Institute of Technology, Nanjing Jiangsru 211169, China)
In this paper, an instance-weighted strategy was proposed based on relative density degree. The closer to the boundary of the training set the sample was, the higher the relative density degree was. The samples locating in the exterior of the data distribution are assigned with larger weights, while the samples locating near the boundary of the data distribution are assigned with lower weights. In general, the noises locate in the external of the data distribution. Therefore, the proposed method can assign the noises with lower weights. The weighted one-class support vector machine could be robust to the noises. The results of the experiments, performed on artificial synthetic datasets and UCI benchmark datasets, demonstrate that weighted one-class support vector machine performs better than one-class support vector machine, which was implemented by libsvm the most popular SVM toolbox.
weighted one-class support vector machine; relative density degree; one-class classification
2016-09-09
江苏省高校自然科学基金资助项目(16KJB520012)
郑玮(1981-),女,江苏泗洪人,讲师,博士生,主要研究方向为数据挖掘与模式识别. E-mail: vividzheng@163.com
TP391
A
1671-6876(2016)04-0317-06
