基于聚类的个人健康档案补全方法的研究与实现
2017-01-10季金鑫姜丽红蔡鸿明
季金鑫,姜丽红,蔡鸿明
(上海交通大学 软件学院,上海 200240)
基于聚类的个人健康档案补全方法的研究与实现
季金鑫,姜丽红,蔡鸿明
(上海交通大学 软件学院,上海 200240)
诊疗记录对病人和医生而言都是十分有用的,但是由于同一个病人在不同的时间会以不同的识别信息在医院进行治疗,那么这个病人的诊疗信息就会分布在不同的记录中,这样使得医生无法判断这些诊疗记录是否来自同一个病人.为了解决这个问题,提出了个人健康档案补全的方法, 利用数值聚类、特征分析、实例类别匹配和诊疗记录补全的方法来识别相同病人的不同诊疗记录,继而实现个人健康档案的补全.最后,通过在某个医院特定的数据库对文中提出的方法进行试验来验证方法的可用性.
诊疗记录;个人健康档案补全;数值聚类;特征分析;实例类别匹配;记录补全
医疗数据可以较有效地描述诊疗过程的业务逻辑,但是,目前缺乏较好的方法对医疗数据之间的关联进行分析.比如,同一个病人在不同的时间段进入不同的医疗机构进行治疗,这个病人的诊疗记录就会分布在不同的数据库中,即使同一个病人在不同的时间段在同一个医疗机构进行治疗,病人的治疗记录也会分布在不同的科室或医院信息系统中,导致病人的历史诊疗信息不完整和个人健康档案数据更新不及时等问题.
针对这一问题,国内外很多学者都提出了一些方案来解决.文献[1]基于局部CON模型的记录匹配方法,利用关联规则挖掘和标准的tableau来匹配分布式数据库中的记录,识别相同身份人的记录. 文献[2]通过对数据库中不一致数据的修复以及用概率来表示记录上的属性值从而识别数据库中的相似重复记录.
本文旨在解决病人的历史诊疗信息不完整和个人健康档案数据更新不及时的问题,涉及数值聚类、对象匹配等方面的内容.
目前数值聚类方法被广泛应用于各种数据挖掘和数据分析. 文献[3]通过最小化不可连接性来进行数值聚类,使用MinDisconnect算法通过不断减小不可连接性来合并聚类. 文献[4]提出了通过计算基于上下文的数值之间的距离来对数值进行聚类的方法,即采用DILCA(distance learning for categorical attributes)方法来计算任意两个数值之间的距离.
为了实现对象与对象之间的匹配,不少学者做了巨大的努力,当然,对于对象匹配,最常用的就是相似度计算方法.文献[5]基于描述性特征,不依赖于模型的实例来对相似度进行度量,将实例匹配问题转化为二元分类问题来进行实例的匹配.文献[6]针对图像的匹配,提出了一个图像描述符的方法,利用这个图像描述符来比较相似的图像.
但是,上述方法均没有考虑数据缺省的情况,并且在上述的方法中只是识别相同实体的记录,并没有对这些记录进行融合. 因此,本文在考虑数据缺省的情况下提出了个人健康档案补全方法,基于数据库中病人的基本信息以及诊疗记录,对相同病人的诊疗记录进行融合.使用数值聚类和对实例类别匹配的方法来识别不同记录中的相同病人,针对特定医院的数据类型进行个人健康档案的补全,补全后实现了病人的诊疗记录的融合,可为今后的个性化治疗等提供帮助.
1 个人健康档案补全方法框架
针对目前的业务需求,专门针对医院数据库中病人信息表设计了个人健康档案补全方法.针对医院数据库中有关病人信息的数据库表,个人健康档案补全的方法分为4步,如图1所示. 具体步骤如下:
(1) 第一阶段为数值聚类.即通过分析数据库中的病人的基本信息以及诊疗等信息,提取病人的姓名、年龄、性别、身份证号和疾病特征,使用改进后的K-Means聚类算法将具有类似特征值的诊疗记录归为一类.
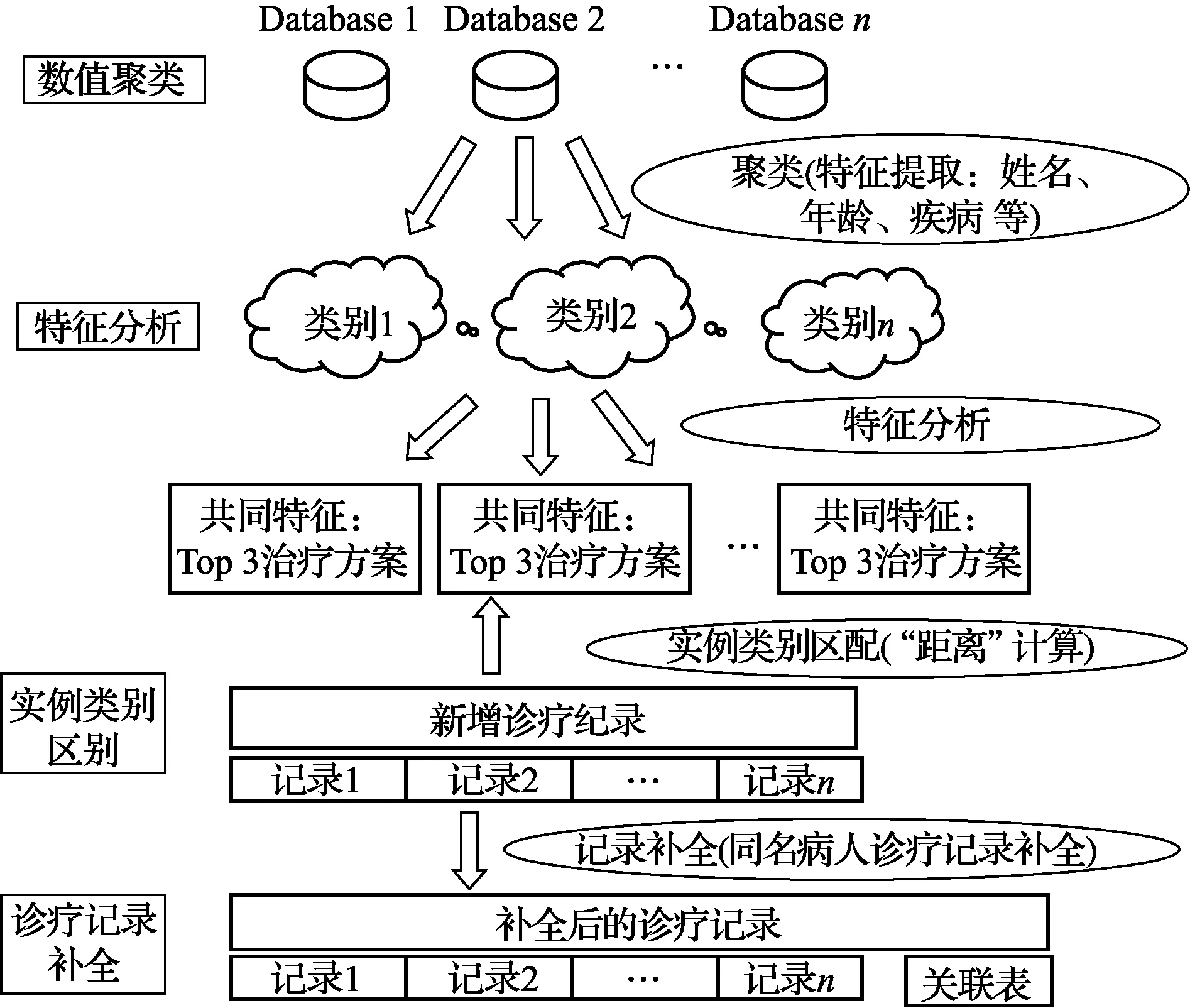
图1 个人健康档案补全框架Fig.1 Personal health records completion framework
(2) 第二阶段为聚类特征分析.即对于每个类别,使用文档频度的方法分析类别的特征,得出每一个类别所具有的共同特征,比如一些治疗方案等.
(3) 第三阶段为实例类别匹配.即根据第一阶段得到的聚类分析的结果,对于每一个新的诊疗记录,提取其姓名、年龄、性别、身份证号和疾病特征,然后利用相似度计算的方法,将这个新的诊疗记录匹配到某一个类别中.
(4) 第四阶段为诊疗记录的补全.即在判定了一条新的诊疗记录属于某一个类别之后,将这个类别所拥有的共同特征赋予这条诊疗记录,比如一些通用的治疗方案可以赋予这个诊疗记录对应的病人,同时,判断记录是否属于同一病人.此时有两种情况:第一种情况,若存在身份证号,相同的身份证号对应的一定是相同的病人;第二种情况,若身份证号信息缺省,则判断对于相同姓名和相同性别的记录,若在同一个聚类中,具有相同的群特征,则可以初步判定这些病人是同一个病人.此时可以进行相同病人诊疗记录的补全.由于每一条诊疗记录被赋予了群特征,这样对于医生而言,就多了一些可供参考的治疗方案,可以让医生知道之前类似的病症有哪些成功治疗的案例,医生就可以参照这些治疗方案对病人进行更加有效的治疗.
2 个人健康档案补全实现方法
2.1 数值聚类方法
通过分析数据库中数据记录的特点,找出关键属性值,利用关键属性值定义“距离”来衡量两个记录间的接近程度或相似程度,把比较接近的或类似的归为一类,而把不怎么接近或不怎么类似的分在不同的类别中.利用改进的K-Means算法实现数据库中记录的数值聚类.
(1) 第一步:特征提取.利用特征提取的方法对病人进行聚类,提取病人的姓名、年龄、性别、身份证号和疾病这些属性,用这5种特征来代表一个病人,即S代表一个病人,S(name, age,gender, ID, disease)即代表病人的一条记录,现有数据集S={S1,S2, …,Sn},代表了n个病人,每个病人包含5个属性,即姓名、年龄、性别、身份证号和疾病.
(2) 第二步:利用多维坐标系表示诊疗记录.建立空间多维坐标系,共5个维度,分别代表5个关键属性,即姓名、年龄、性别、身份证号和疾病.年龄按0~100排列;性别用0和1表示,0表示男性,1表示女性;身份证号取前6位表示;疾病按照类别排列,用数据0~200表示,相似的疾病放到相邻的坐标位置,其值越接近,例如腰椎间盘突出和腰椎病就是类似的病,可以放到相邻的坐标位置.
(3) 第三步:数据记录之间“距离”的定义.由第一步得到的每条记录有5个属性,给每个属性分配一定比例的权重,姓名属性权重(w1)为0.2,年龄属性权重(w2)为0.1,性别属性权重(w3)为0.1,身份证号属性权重(w4)为0.5,疾病权重(w5)为0.1,权重相加为1.每一条记录表示为空间坐标轴上的一个点S(A,B,C,D,E),其中,属性A,B,C,D,E分别表示姓名、年龄、性别、身份证号和疾病,D(Si,Sj)表示两条记录Si和Sj在空间坐标系中的距离,计算式如下.
D(Si, Sj)=|Ai-Aj|*w1+|Bi-Bj|*w2/100+|Ci-Cj|*w3+|Di-Dj|*w4+|Ei-Ej|*w5/200
(1)
其中:|Ai-Aj|表示姓名属性之间的距离,若姓名相同,则距离为0,否则距离为1;|Bi-Bj|表示年龄属性之间的距离,即为年龄的差值,这里要进行归一化处理;|Ci-Cj|表示性别属性之间的距离,性别相同则距离为0,否则距离为1;|Di-Dj|表示身份证号属性之间的距离,该距离用编辑距离表示,取身份证号前6位,这里身份证号前6位的编辑距离即为身份证号属性之间的距离;|Ei-Ej|表示疾病属性之间的距离,即为疾病数据对应的差值,同样,这里要进行归一化处理.因为身份证号信息是缺省信息,不一定所有的记录都会提供这一信息,所以若两条记录的身份证号信息均不存在,此时身份证号属性权重w4变为0,重新分配属性权重,即姓名属性权重(w1)为0.3,年龄属性权重(w2)为0.2,性别属性权重(w3)为0.3,疾病属性权重(w5)为0.2,距离仍按式(1)计算.
(4) 第四步:利用改进后的K-Means算法进行聚类.传统的K-Means算法简单、快速,并且可以处理大规模的数据,但是K-Means算法的第一步是随机选择K个对象作为聚类中心,这样就容易得到局部最优解,并且这个局部的最优解完全依赖于初始聚类中心的选择.同时,对于不同初始聚类中心的选择会得到不同的聚类结果,算法比较不稳定.所以这里对K-Means算法稍作改进,假设聚类的个数为K个,改进后的K-Means算法伪代码如下所述.
Input:
All records with property values of name, age, gender, ID and disease
Output:
Kclusters and records in each cluster
Find two records with the longest distance
The number of clusterm=2
Make the two records be the cluster center ofmclusters
WhileK>m
Find one record has the longest distance to themcluster centers
m++
Make the record be center of new cluster
While the clusters are changing
Make each record belong to its nearest cluster center
Change the cluster centers
returnKclusters and records in each cluster
改进的K-Means算法改变了传统K-Means算法对初始聚类中心的选择,不是随机选取K个对象作为聚类中心,而是首先选择两个距离最远的对象作为初始的两个聚类中心,接着找到第3个距离这两个对象最远的对象作为第3个聚类中心,依此类推,直到找到K个聚类中心为止.这样的初始聚类中心的选择可以最大程度地保证聚类中心分配的合理性,得到整体最优解.
2.2 特征分析方法
对于每一个聚类的特征分析方法的实现,利用文档频度的方法统计治疗方案,得出Top 3的治疗方案作为聚类的共同特征.
文档频度(document frequency, DF)方法[7]是用来统计一个特征词在一个类别中出现次数的方法,该方法的实现简单且算法复杂度低,所以选用此方法来进行特征分析.数据库表中每种治疗方案均为字符串表示,比如“人工关节置换”“长期青霉素注射”等,然后利用文档频度统计的方法,列出每一个聚类中出现的所有治疗方案,对这些治疗方案进行统计,统计每种治疗方案出现的次数,见式(2)所示.
C=(〈TERM1,DF1〉,〈TERM2,DF2〉,…, 〈TERMi, DFi〉,…,〈TERMn, DFn〉)
(2)
其中:C为统计的集合;〈TERMi, DFi〉为第i个治疗方案字符串;DFi为第i个治疗方案出现的次数. 现根据DFi的大小进行排列,找出前3个DFi值最大的TERMi,这3个TERM即为找到的Top 3的治疗方案,可以将其作为每一个聚类的共同特征.
2.3 实例类别匹配方法
实例类别匹配利用数值聚类的结果,将一个新的记录匹配到某一个类别中.
(1) 第一步:一个新加进来的数据库记录,包括了病人的基本信息以及诊疗信息,同样地,抽取病人的姓名、年龄、性别、身份证号和疾病信息,形成一个新的记录.
(2) 第二步:新记录类别确定.利用式(1)计算这个新记录与各个聚类中心的距离,将该记录分配到与其距离最小的聚类中.
2.4 诊疗记录补全方法
诊疗记录补全阶段则利用实例类别匹配结果,判断同名病人是否为同一个人来补全诊疗记录.这里利用新生成关联表的方法来进行同一个病人的不同诊疗记录的融合.这里给出如下两个定义.
定义1 对于每一组相同病人的不同诊疗记录,在不同记录中时间属性值最早的那条记录定义为主记录,这条记录的主键定义为主主键.
定义2 对于每一组相同病人的不同诊疗记录,除了时间属性值最早的那条记录,其余记录均称为从属记录,这些记录的主键均定义为从属主键.
(1) 第一步:找出相同病人的不同诊疗记录.首先找出所有同名病人的诊疗记录,对于这些同名的病人,若是属于同一个类别中,则可以将其认为是相同的病人;若不属于同一个类别中,则认为是不同的病人.
(2) 第二步:相同病人诊疗记录的融合.对于在上一步中找到的相同病人的诊疗记录,对于同一个病人,取出其所有的诊疗记录,找到其中的主记录和从属记录、主主键和从属主键,建立主主键和从属主键之间的关联表.
3 案例分析和讨论
3.1 案例分析
通过分析某医院的真实诊疗数据,对本文提出的个人健康档案补全方法进行了验证.
(1)首先分析数据库中的每一张表的含义以及表中每一个属性的含义,得出关于病人信息方面的表有两张,分别是病人的基本信息表和病人的诊疗信息表.在此数据库中体现为两个表,分别是dbo.ab表(病人基本信息表)和dbo.cb表(病人诊疗信息表),如图2和3所示.
(2) 结合本文所提出的数值聚类的方法,建立空间多维坐标系,接着利用改进的K-Means算法对数据库中500条记录进行聚类,最终聚类的结果为4个类别.这里用传统的K-Means算法和改进后的K-Means算法进行聚类结果的比较.
传统的K-Means算法首先选取前4条记录作为初始聚类中心,经过多次迭代,得到4个聚类和每个聚类中的记录.

图2 dbo.ab表Fig.2 Table of dbo.ab
图3 dbo.cb表Fig.3 Table of dbo.cb
改进后的K-Means算法首先选取距离分别最远的4条记录作为初始聚类中心,这4个初始聚类中心分别为:S1(姓名:**,年龄:12,性别:男,身份证号:**,疾病:骨折),S2(姓名:**,年龄:35,性别:女,身份证号:**,疾病:腰肌劳损),S3(姓名:**,年龄:58,性别:男,身份证号:**,疾病:强直性脊柱炎),S4(姓名:**,年龄:74,性别:女,身份证号:**,疾病:骨质疏松).经过多次迭代,得到4个聚类和每个聚类中的记录.
两种算法的结果比较如表1所示.
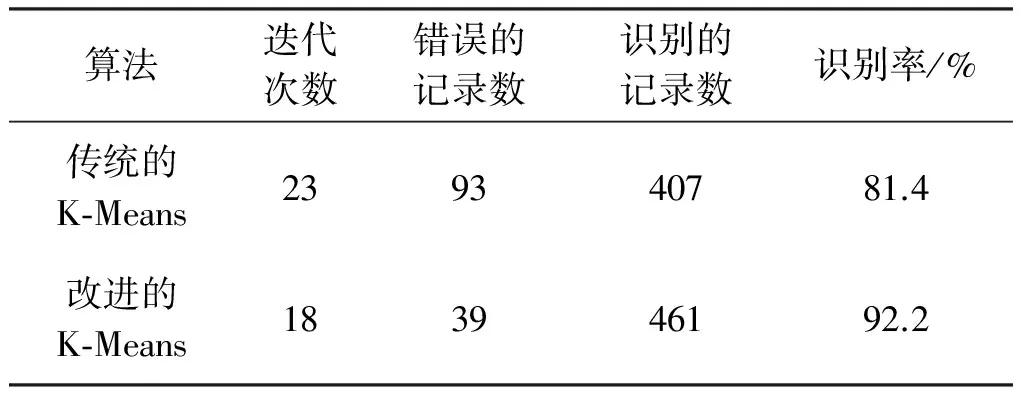
表1 两种算法结果比较
由表1可以看出,两种算法的迭代次数都比较多,但是改进后的K-Means聚类算法明显提高了聚类的准确率.
(3) 对于聚类得到的4个类别,分析类别特征利用上述的文档频度的方法得出每个类别的Top 3治疗方案:类别1(Top 1:手术,Top 2:仪器固定,Top 3:长期青霉素注射),类别2(Top 1:手术,Top 2:射频靶点热凝术,Top 3:牵引),类别3(Top 1:人工关节置换,Top 2:打石膏,Top 3:中医刺穴疗法),类别4(Top 1:运动疗法,Top 2:中医刺穴疗法,Top 3:手术).
(4) 通过之前的聚类和得到的聚类结果,对于新加入数据库的诊疗记录,可以利用式(1)计算该新诊疗记录属于哪一个聚类,并赋予其相应聚类的共同特征.
(5) 最后,进行诊疗记录补全方法的实现.找出所有诊疗记录中的同名病人,发现有17组同名病人,如图4所示.

图4 同名病人分组结果Fig.4 Grouping result of patients with the same name
在这17组同名病人中,有16组均是两条相同姓名的记录,有1组是3条相同姓名的记录,将这17组中的姓名进行标号,姓名从A到Q依次排列,共有17组相同姓名的记录,其中A与A是相同的姓名,B与B是相同的姓名,依此类推.同时,发现这17组记录中,并不是所有的记录均提供身份证号信息,因身份证号信息缺省,无法直接利用身份证号信息识别相同的病人,所以利用上述提出的诊疗信息补全方法进行识别相同病人并补全诊疗信息.找出这17组记录所属的聚类,发现记录A、F、O均属于聚类1,记录C、H、J、M、P、Q均属于聚类2,记录D、E、G、I、L均属于聚类3,记录K、N均属于聚类4.同属于一个聚类,并且姓名相同,可以认为这是同一个人,所以聚类1中的A、F、O分别对应的是同一个人,即两条姓名为A的记录为同一个人的记录,两条姓名为F的记录为同一个人的记录,两条姓名为O的记录为同一个人的记录,其余3个聚类中的记录同理可得.但是还有一个相同姓名的两条记录,即为姓名B,其中一条记录在聚类3中,一条记录在聚类4中,不在同一个聚类中,这样可以认为这两条记录对应的不是同一个人,并且通过验证姓名B的两条诊疗记录的其他信息发现,这两条诊疗记录对应的确实不是同一个人,说明本文的识别方法是有效的.接着利用关联表将对应的同一个人的记录进行融合,即实现相同病人诊疗记录的补全.
针对查准率和查全率两项评价指标,分别用本文方法、代码集迁移[8]以及PRAWN[9]方法进行试验,比较结果如表2所示.
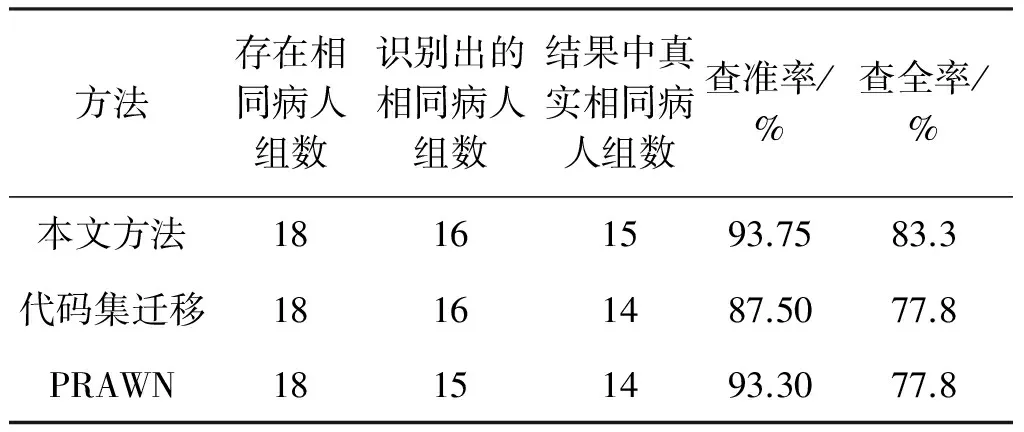
表2 试验结果对比
由表2可以看出,本文提出的方法在查全率和查准率指标上都要高于另外两种方法,说明本文方法比较好.
3.2 对比与讨论
有不少学者针对识别和集成不同数据源的数据做了很多努力. 文献[8]提出了一个代码集迁移的方法来融合某一个患者的所有历史诊疗记录.文献[9]提出了一个叫PRAWN的方法可以集成不同时间维度的数据,可以解决数据之间的冲突问题. 本文方法与上述两种方法之间的比较如表3所示.

表3 几种方法的比较
由表3可以发现,本文方法具有高可用性、较高查准率与查全率等优点.
4 结 语
本文针对相同病人在不同的诊疗机构会形成多条诊疗记录,这些同一个病人的诊疗记录难以融合而导致病人的个人健康档案信息不完全的问题,在部分诊疗数据缺省的情况下提出了个人健康档案补全方法,利用数值聚类、特征分析和诊疗记录补全等方法,实现了对相同病人不同诊疗记录的识别与融合,继而实现了病人个人健康档案的补全.
下一步的研究将考虑如何在复杂数据环境下增强算法的容错性,重点研究数据缺失或数据有误的情况下,如何进行相同病人识别和诊疗记录补全问题.
[1] 李娇,刘全,傅启明,等.分布式数据库中基于局部CON模型的记录匹配方法[J].通信学报, 2011, 32(7): 196-202.
[2] 沈忱,曾卫明,吴爱华.融合修复代价的不一致关系数据中相似重复记录识别[J].现代计算机(普及版), 2015(6): 3-9.
[3] LEE J S, OLAFSSON S. Data clustering by minimizing disconnectivity[J]. Information Science, 2011, 181(4): 732-746.
[4] IENCO D,PENSA R G,MEO R. From context to distance: Learning dissimilarity for categorical data clustering[J]. ACM Transactions on Knowledge Discovery from Data, 2012, 6(1): 1-25.
[5] RONG S, NIU X, XIANG E W, et al. A machine learning app-roach for instance matching based on similarity metrics[C] //The Semantic Web-ISWC 2012. 2012: 460-475
[6] NOWAK T, NAJGEBAUER P, RYGAL J,et al. A novel graph-based descriptor for object matching[C] //Artificial Intelligence and Soft Computing. 2013: 602-612.
[7] 龚静,曾建一.文本聚类中的特征选择方法[J].吉首大学学报(自然科学版), 2008, 29(2): 39-41.
[8] MCGLOTHLIN J P,KHAN L. Managing evolving code sets and integration of multiple data sources in health care analytics[C] // Proceedings of the 2013 International Workshop on Data Management and Analytics for Healthcare. 2013: 9-14.
[9] ALEXE B, ROTH M, TAN W C. Preference-aware integration of temporal data[C] //Proceedings of the VLDB Endowment. 2014: 365-376.
Research and Implementation of Personal Health Records Completion Method Based on Clustering
JIJin-xin,JIANGLi-hong,CAIHong-ming
(School of Software, Shanghai Jiao Tong University, Shanghai 200240, China)
Medical records are useful to both patients and doctors. However, the same patient may go to hospital for treatment at different times with different identification information and the patient’s medical information will be distributed in different records. So doctors can not determine whether the medical records are from the same patient. In order to solve this problem, a novel personal health records completion method is proposed. Numerical clustering, feature analyzing, instance matching and medical records fusion methods are used to identify different records of the same patient and realize the completion of personal health records. Finally, an experiment is taken in the database of a specific hospital to verify the usability of the proposed method.
medical records; personal health records completion; numerical clustering; feature analyz-ing; instance matching; records fusion
2015-11-27
国家自然科学基金资助项目(71171132,61373030);上海市自然科学基金资助项目(13ZR1419800)
季金鑫(1991—),男,江苏启东人,硕士研究生,研究方向为数据分析. E-mail: jijinxin@sjtu.edu.cn 蔡鸿明(联系人),男,副教授,E-mail: hmcai@sjtu.edu.cn
TP 391
A
