基于证候要素的二阶证实性因子分析在R语言lavaan包中的实现*
2017-01-09薛芳静许碧云申春悌陈启光陈炳为
黄 灏 薛芳静 许碧云 申春悌 陈启光 陈炳为△
基于证候要素的二阶证实性因子分析在R语言lavaan包中的实现*
黄 灏1薛芳静1许碧云2申春悌3陈启光1陈炳为1△
目的探索高血压阴虚夹湿证的证候要素,并介绍R语言lavaan包在结构方程模型中的应用。方法介绍lavaan包的语法,然后利用lavaan包中的二阶证实性因子分析对1280例高血压的阴虚夹湿证进行分析,以得到高血压阴虚夹湿证的证候要素。结果阴虚夹湿证包含3个证候要素,病位主要在肝与肾、病性主要为虚与湿。结论利用R语言lavaan包实现结构方程模型是十分方便的。二阶证实性因子分析方法可用于中医证候分类及证候要素提取和命名。
lavaan包 二阶证实性因子分析 证候要素
辨证论治是中医学的精髓,证候是指内外环境变化所导致的机体病理生理整体反应状态,是疾病发生和演变过程中某一阶段病理本质的反映,它以一组相关的症状和体征为依据,从不同程度揭示出患者当前的病机综合而成。证候要素是指组成“证候”本质的基本构成单位,是指组成证候的主要元素。本文利用二阶证实性因子分析对中医证候中的阴虚夹湿证进行证候要素分解[1]。
二阶证实性因子分析属于结构方程模型(structural equation model,SEM)的一种[2]。目前市场有很多软件可用于拟合SEM模型,如R、LISREL、Mplus、EQS、Stata和AMOS等。其中R是一款免费的、开源的统计编程语言和计算环境[3]。R中有多个SEM的包,包括:lavaan、sem、lava和OpenMx[4]。目前使用较多的有lavaan包和sem包,本文以中医证候要素的提取为实例介绍R语言lavaan包中结构方程模型的实现。借助R语言中lavaan包中的二阶证实性因子分析对中医证候中的阴虚夹湿证进行证候要素的分解。
结构方程模型及lavaan包简介
1.结构方程模型简介
在SEM中包括了两种子模型,第一个为测量模型(measurementmodel),它是确定观察变量与潜在变量之间关系;另一为结构模型(structuralmodel),是表示潜变量与潜变量之间关系的模型。它用公式表达如下:
测量模型:X=ΛXξ+δ与Y=Λyη+ε
结构模型:η=Bη+Γξ+ζ
其中ΛX是外生显在变量(可观测变量)X在外生潜在变量ξ上的因子载荷矩阵,ΛY是内生显在变量Y在内生潜在变量η上因子载荷矩阵。δ、ε、ζ分别表示误差[1]。下面以4个内生显在变量及4个外生显在变量,2个内生潜在变量及2个外生潜在变量来说明,其通径关系如图1。
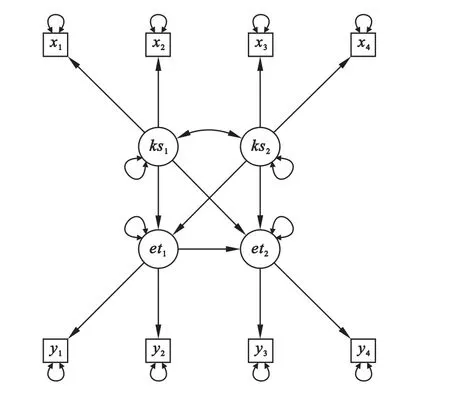
图1 一个假设的结构方程的路径图
2.lavaan包简介
对于R语言的lavaan包中需先对模型进行定义,在模型定义中主要用到一些符号与关键字,将其列出如表1。
在R语言中,首先需要安装lavaan包,安装程序如下:
install.packages(“lavaan”)#安装lavaan包
library(“lavaan”)#调用lavaan包
lavaan包中结构方程模型的分析主要从以下几步考虑:
(1)模型指定:以图1的模型来说明,生成模型代码(mymodel)如下:
mymodel<-′ks1=~x1+x2#ks1由变量x1与x2度量
ks2=~x3+x4#ks2由变量x3与x4度量
et1=~y1+y2#et1由变量y1与y2度量
et2=~y3+y4#et2由变量y3与y4度量
et1~ks1+ks2#ks1与ks2预测et1
et2~ks1+ks2+et1#ks1、ks2与et1预测et2
ks1~~ks2′#ks1与ks2相关
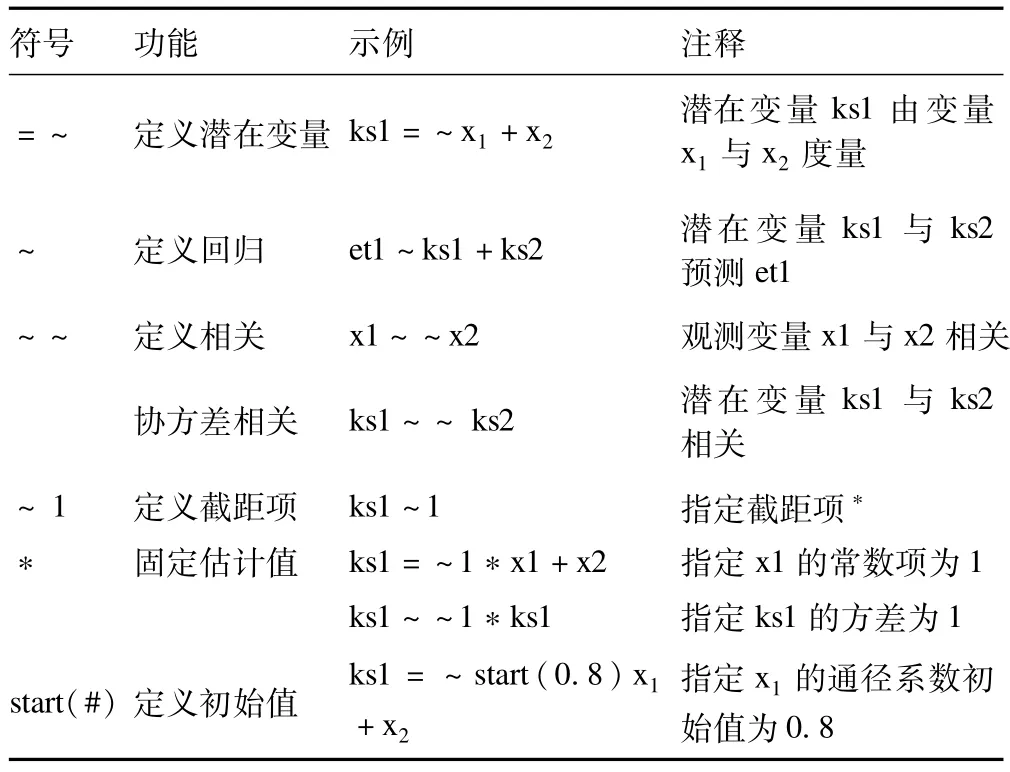
表1 R语言中lavaan包中主要命令
(2)模型运行:当完成结构方程模型设置后,可运行如下程序。
fit<-sem(model=,data=,meanstructure=,sample.nobs=,sample.mean=,sample.cov=,group=,bootstrap=,estimator=)
当模型为结构方程模型时,采用sem命令;当模型为证实性因子分析时,采用cfa或sem命令;当模型为潜在生长曲线模型时,采用grow th或sem命令。model用于指定模型名称,如前面自定义的模型名称为mymodel。对于结构方程模型一般考虑协方差矩阵来估计参数,但有些模型需要指定常数项,如潜在生长曲线模型,这时除了协方差矩阵外,还需要均数向量,这时模型的meanstructure指定TRUE,默认为不考虑均数向量。对于分析的数据有两种格式,第一种是原始数据,则可用data选项,其中数据集为R语言的frame格式。如果数据形式为协方差矩阵时,则可用sample.nobs=样本例数,sample.cov=样本协方差矩阵的名称(协方差的格式为下三角阵形式),sample.mean=样本均数向量的名称。如果模型中需要考虑多个组的结构方程模型,则选项group=组别变量名;如果需要进行bootstrap抽样,则bootstrap=抽取的次数;estimator选项是指定模型估计的方法,对应的选项有ML、GLS、WLS、ULS、DWLS等,即采用最大似然估计、广义最少二乘估计、加权最二乘估计、不加权最少二乘估计及对角线加权最少二乘估计等。R语言统计分析将结果都存在一个fit的对象(object)里面。
(3)结果输出:
R语言在分析执行结束后并不显示任何结果,但可以有选择地从结果中提取感兴趣的部分[5]。可以通过以下的命令来提取结果。
①summary(fit,standardized=,fit.measures=,rsquare=)
summary对模型拟合情况进行描述,给出模型拟合的卡方值、自由度和P值,同时给出统计量的方差。Standardized选项值为TRUE时输出标准化回归系数,否则默认不输出。fit.measures=TRUE时输出模型拟合的CFI、TLI、AIC、BIC、RMSEA及其95%可信区间、SRMR等拟合度的指数,默认时只输出卡方、自由度及P值。rsquare=TRUE给出每个变量(可观测变量及潜在变量)的复相关系数。
②modindices(fit,sort.=,minimum.value=,maximum.number=)
modindices给出模型的修正指数MI值,为模型修正提供依据。sort.=TRUE,按MI值从大到小排序,默认不进行排序。minimum.value=m,只保留MI≥m的修正结果,maximum.number=n,列出前n个较大MI值。
③fitMeasures(fit,“拟合指数名称”)
fitMeasures函数计算了各种模型拟合的指数。默认给出所有的衡量指标,包括:CFI、TLI、GFI、AGFI、SRMR、RMSEA等。若只需要单个指标,只需要单个指标加入函数中即可,如fitMeasures(fit,“cfi”)。
④standardizedSolution(fit,type=)
standardizedSolution描述潜变量模型的标准化系数。type默认为“std.all”,即对显变量和潜变量的分别进行标准化,若选项为“std.lv”,则只对模型中潜变量的进行标准化。因此,type大部分情况采用“std.all”的选项。
实例分析
资料来自2006年7月至2008年12月在常州、南京、沈阳和珠海四个地区五个三级甲等中医院收集到的高血压病例共计1280例。证候为阴虚夹湿的中医四诊信息有:目涩(x1)、耳鸣(x2)、目痒(x3)、目胀(x4)、耳聋(x5)、健忘(x6)、视物模糊(x7)、迎风流泪(x8)、足痛(x9)、尿后余沥(x10)、小便不畅(x11)、便秘(x12)、小便清长(x13)、身重(x14)、口粘腻(x15)、夜间多尿(x16)、白苔(x17)、口咽干燥(x18)、浮肿(x19)、舌紫(x20)、四肢麻木(x21)指标,数据集称为GHKX。
对于结构方程模型初始模型的建立有两种方法,第一种方法是采用探索性因子分析来探索包含几个因子;第二种方法是根据专业的知识构造初始模型。先采用因子分析得到阴虚夹湿包含三因子,并根据因子载荷系数构建二阶证实性因子分析初始模型(mymodel):


构建初始模型后,采用cfa或sem命令对数据进行拟合:
fit<-cfa(mymodel,data=GHKX)
summary(fit,standardized=TRUE,fit.measures=TRUE)
modindices(fit,sort.=TRUE,minimum.value=10)
采用summary对结果进行输出,得到部分拟合度指数、载荷系数、方差及协方差等。利用modindices列出模型的修正指数MI值,根据每一步的MI值大小,对模型进行调整。模型修正中x10与x11间的相关系数MI最大,其值为78.114,它是模型修正值。因此,在初始模型中加入“x10~~x11”重新拟合模型。如此循环反复,直到所有的MI值在5~10之间则停止修正,从而得到最终的模型。最终模型利用summary、fit-Measures与standardizedSolution得到拟合度、载荷系数及标准化系数。

表2 模型整体拟合度评价指标
模型拟合度中CFI、TLI、GFI、AGFI越大说明模型拟合越好[6]。Hu和Bentler(1998)推荐SRMR小于0.08认为模型可以接受[7]。RMSEA(近似误差均方根)<0.05拟合好;0.08~0.10拟合一般;>0.10拟合不好。表2中x/df=1.596<3,CFI、TLI、GFI、AGFI均大于>0.90,SRMR与RMSEA均小于0.05,可见最终模型的拟合较好。
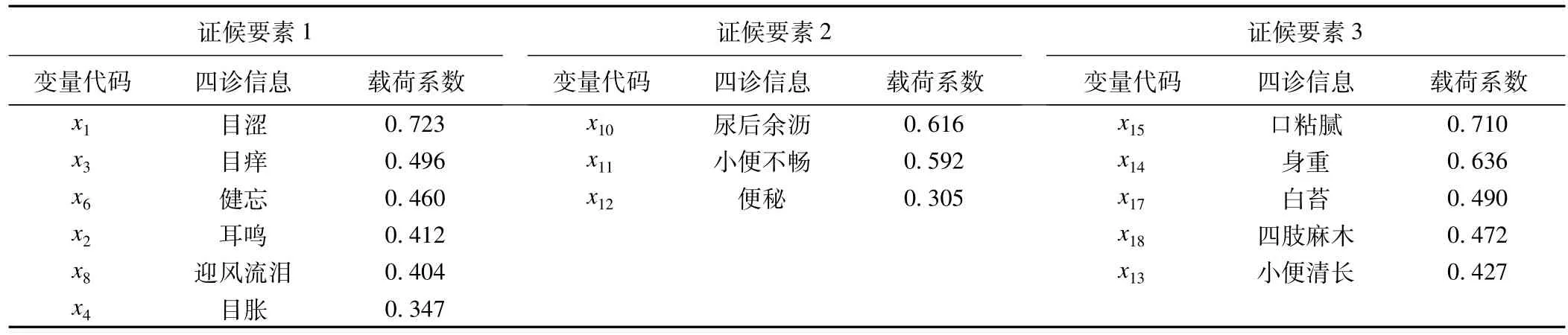
表3 二阶证实性因子分析最终模型的标准化系数
结果分析可见,阴虚夹湿证包含3个证候要素,证候要素1包含6个指标,其中5个指标(目涩、目痒、健忘、耳鸣、迎风流泪)标准化系数高于0.4,证候要素1可以解释为病位在肝,病性为气虚;证候要素2包含3个指标,其中2个指标(尿后余沥、小便不畅)标准化系数高于0.4,证候要素2可以解释为病位在肾,病性为阴虚;证候要素3包含5个指标,标准化系数都高于0.4,证候要素3可以解释为病性为湿。由此可见,阴虚夹湿证与筛选出的14个指标间有高度相关性,成功实现了中医的证候要素的提取。
讨 论
证候要素的提取便于中医证候的命名,及中医上的诊疗,因此将证候分解成中医的证候要素有重要临床意义。目前应用较多的实现潜在变量模型的软件有LISREL、Mplus及AMOS,以上三个软件均为商业版,R语言是一款免费的统计软件包,在医学研究中目前应用越来广泛,每个软件都有各自的优缺点。AMOS可以通过通径图来构建模型,也可通过程序,而R语言、LISREL、M plus是利用编程得到的。然而在模型修正时,选择基于编程语言的软件如R和LISREL比点击式操作的软件更具有系统性和便利性。
[1]陈炳为,陈启光,许碧云.潜在变量模型及其在中医证候中的应用概述.中国卫生统计,2009,26(5):535-538.
[2]Oberski DL.Lavaan survey:an R package for complex survey analysis of structural equation models.Journal of Statistical Software,2014,57(1):1-27.
[3]Fox J.Teacher′scorner:Structural equation modeling with the sempackage in R.Structural equation modeling:A Multidisciplinary Journal,2006,13(3):465-486.
[4]Song YE,Stein CM,Morris NJ.Strum:an R package for structural modeling of latent variables for general pedigrees.BMCgenetics,2015,16(1):1-2.
[5]汤银才.R语言与统计分析.高等教育出版社,2008.
[6]秦浩,陈景武.结构方程模型原理及其应用注意事项.中国卫生统计,2009,23(4):367-369.
[7]侯杰泰,温忠麟,成子娟.结构方程模型及其应用.北京:教育科学出版社,2004.
(责任编辑:邓 妍)
国家自然科学基金(81273190)
1.东南大学公共卫生学院流行病与卫生统计系(210009)
2.南京大学医学院附属鼓楼医院
3.南京中医药大学附属常州中医院
△通信作者:陈炳为,E-mail:drchenbw@126.com
