基于Hadoop的校园网视频流量访问偏好分析
2017-01-03许闻秋雒江涛杨军超
许闻秋,雒江涛,杨军超
(重庆邮电大学 电子信息与网络工程研究院,重庆400652)

基于Hadoop的校园网视频流量访问偏好分析
许闻秋,雒江涛,杨军超
(重庆邮电大学 电子信息与网络工程研究院,重庆400652)
针对传统视频用户访问日志的偏好分析方法存在数据客观性差和用户关联分析困难等问题,在传统偏好分析方法的基础上,面向互联网数据原始流量,提出一种基于主流大数据平台技术Hadoop的校园网视频用户访问偏好分析方案。该方案利用网络爬虫和深度包检测技术,对视频访问内容进行精细化识别,进而研究了校园网视频流量的访问偏好,并对比了MySQL和Hive的查询效率。结果表明,文化层次的差异导致了视频用户群体的不同需求,低成本硬件环境下对大数据的处理Hive更显健壮性。另外,该方案能稳定可靠地实现对校园网视频流量访问的偏好分析,捕捉用户网络舆情,制订定向营销方案并提供个性化视频推荐服务。经现网测试验证,设计的视频访问偏好分析方案达到了预期的效果。
校园网视频;偏好分析;Hadoop;网络爬虫;深度包检测
0 引 言
互联网的发展使得视频业务占据网络流量的绝大部分,而通过视频网站访问视频的方式逐渐成为主流[1]。互联网视频流量承载了视频用户的访问数据,对其深度挖掘是用户偏好分析的一个有效途径。同时,校园网视频流量分析将对校园网络维护、拥塞控制及用户管理等领域带来研究价值[2]。视频访问偏好分析将有助于捕捉用户网络舆情、制订定向营销方案,且为个性化视频推荐提供依据。然而,以视频用户访问日志为主的传统偏好分析方法存在数据客观性差,用户关联分析困难,用户相关信息提取不易等问题。
结合深度包检测(deep packet inspection,DPI)技术的流量识别方法有助于视频用户访问偏好的分析,但精度不高。原因有:①传统的数据挖掘算法对TB/PB量级的数据存储和运算存在局限性;②视频HTTP(hyper text transfer protocol)请求的统一资源定位符(uniform resource locator,URL)无法直接获取视频详细信息[3-4]。为此,融合网络爬虫(web crawler)技术并建立视频网站产品信息库的视频流量识别方法能提高分析精度。
本文面向互联网流量数据,基于Hadoop提出一种通过视频流量识别与统计从而对用户访问偏好进行分析的方案;融合DPI及网络爬虫技术,通过分析校园网实时流量,得到不同维度下的用户访问偏好,验证方案可行性并提高分析精确度;与传统数据库方法对比,验证了大数据下Hive的高效性;最后,本文为校园网流量监管、拥塞控制,校园网用户视频推荐提供了依据。
1 相关工作
中国互联网络信息中心,通过计算机辅助电话访问和抽样调查的方法,调研了国内网络视频的用户规模及用户行为[5]。但是,该方法对参与的人力物力资源配置要求较高,不易实现。艾瑞咨询通过第3方监测软件iVideoTracker,收集固定样本签约用户的网络视频行为日志,分析了国内主流视频媒体收视情况及收视人群分布[6]。但是,该方法所需的用户视频访问日志不易获取,且调研样本单一,不具有普适性。
文献[7]提出了一种在Hadoop下执行解析IP(internet protocol),TCP(transmission control protocol),HTTP层MapReduce任务的网络流量分析方案,验证了Hadoop下流量分析的可行性。文献[8]结合DPI技术,提出了一种移动端视频应用用户行为分析方案;文献[9]通过对Web日志挖掘,提出了一种针对移动互联网视频用户的流量分析方法;文献[10]提出了一种考虑视频用户偏好的视频内容质量评估方法。文献[11]在Apache Pig,Apache Hive和MySQL集群下,分别对不同大小的数据集进行查询效率测试,验证了Hive方法的优越性。然而,上述文献却存在用户访问信息及用户偏好提取困难的问题。为此,文献[12]进一步提出了基于Hadoop的电商网站流量识别与DPI系统,对电商用户的行为和偏好进行提取和分析。本文应用主流的开源大数据平台Hadoop,通过MapReduce提供的并行运算编程模型,Hadoop分布式文件系统(hadoop distributed file system,HDFS)提供存储基础,Hadoop的数据仓库Hive实现统计分析[13-17]。结合视频网站及用户特点,提出了一个针对校园网视频流量用户访问偏好的分析方案。
2 视频流量访问偏好分析方案
2.1 视频流量识别和DPI
本文结合DPI及网络爬虫技术,通过解析校园网视频流量,识别视频提供商及视频类别,借助爬虫建立的产品信息库,确定视频具体文件,统计分析视频用户访问偏好。
2.1.1 视频服务提供商识别
用户通过视频网站,向视频服务提供商的服务器发送一次HTTP请求,服务器随即回送响应,通过浏览器解析响应中的HTML(hyper text mark-up language),得到相应视频网页。本文通过解析网页视频请求流量,重组HTTP请求,提取视频关键信息,从而实现视频服务提供商的识别。
本文采用基于特征字匹配的DPI数据包解析方法,通过对在应用层协议头或应用层负荷中特定位置的视频特征字段的识别来实现对视频业务数据包的检测和解析,从而得到一个包含视频特征字段与特征值的DPI视频特征库。其中,视频特征值具体包括:数字特征值(视频ID)、HTTP GET请求中的Host域名特征、Referer特征及URL等字符特征值。
以优酷视频的特征识别为例,当用户访问某视频时,Host域名(youku)和GET请求URI同时构成了用户视频请求HTTP数据包中的Full Request,其中,URI则带有视频数字特征,即视频ID。通过正则表达式匹配同时包含Host域名和带有“/v_show”和“.html”的校园网用户GET请求数据包,匹配Host字段,由此识别该视频请求流量的服务提供商为优酷网。
2.1.2 视频访问事件识别
本文应用视频网站爬虫技术,根据配置规则,定向抓取特定视频网站资源,并把抓取结果存储到视频网站产品信息库中。数据包解析得到视频服务提供商信息和视频ID,通过与视频网站产品信息库匹配,与对应视频文件建立映射关系。结果录入数据库,并将该视频请求流量转化为用户的一次视频访问事件。
以优酷网产品信息为例,表1是对优酷网建立的产品信息表,包括:视频网站、视频ID、视频名称Name、视频频道、视频二级频道等信息。其余视频类网站结构及其分析过程与之类似。确认视频文件后,得到视频名称,即“视频Name”。与优酷网产品信息表匹配,即可辨认对应的视频类别,其中包括:视频频道、二级频道等相关信息。

表1 优酷网产品信息
2.2 统计与偏好分析
2.2.1 流量识别与DPI
每条时间记录下用户视频访问事件的累计,能反映群体用户的视频偏好。因此,对校园网视频用户偏好的分析,通过对视频流量的识别与DPI,最终被转化为对视频访问事件的统计。
为了能直接统计解析后的网页视频请求流量,同时避免对数据库的重复建表和海量数据操作,本文采用Hadoop生态系统中的数据仓库Hive作为统计工具。解析后的校园网视频流量直接存入HDFS,并建立元数据库存入MySQL中,从而构建数据映射关系。对Hive运行查询语句(hive query language,HQL),快速简单地实现MapReduce统计。整个分析过程,同时输入MapReduce分布式运算模型,最终完成对校园网视频用户的偏好统计分析。
2.2.2 数据表建立
用户视频访问事件以文本形式保存在HDFS中。其中,每行代表视频访问的一次记录,每条记录以行分隔符(“ ”)分隔,每条记录中的各个字段以逗号(“,”)分隔。Hive通过元数据存储机制,将HDFS中的文件映射到数据表中,数据表的信息即元数据(metadata),元数据存储在底层关系型数据库MySQL中。
鉴于Hive外部表的安全性,能避免误操作所带来的损失。本文通过EXTERNAL关键字来指定创建外部表;通过LOCATION关键字来指定表数据存放在HDFS中的位置;通过STORED AS TEXTFILE指定加载的文件数据是纯文本格式;ROW FORMAT DELIMITED关键字设置创建的表加载数据时支持列分隔符;COMMENT关键字给字段和表注释。在Hive中创建名为Video的数据库,并创建外部表VideoTable描述视频节目识别模块得到的校园网用户视频访问记录。
2.2.3 用户偏好统计分析
对不同性别的校园网视频用户进行不同维度的偏好统计。具体包括:不同性别用户对主流视频网站、频道和节目的统计。根据统计结果,给出Top-N视频推荐列表,并分析校园网流量视频用户的偏好。
2.3 MapReduce并行运算模型
图1是MapReduce提供的并行编程运算模型,通过分发任务,解析网络视频流量,完成校园网视频用户访问偏好的统计和分析。
2.3.1 Job 1视频服务提供商识别
从HDFS中读取PcapIputFormat格式的Pcap数据包,同时,Map1的输入为

图1 MapReduce编程模型Fig.1 MapReduce programming model
2.3.2 Job2视频文件确定
通过视频Host和ID,与视频网站爬虫信息库进行匹配,确定视频文件,包括:视频名字Name、视频频道和视频类型等。依据校园网规划,宿舍楼栋号与网络端口号一一对应,从而获悉用户性别信息。最终得到以用户性别为key、以视频对应具体信息为value的Reduce2输出。
2.3.3 统计与偏好分析
Hive将HQL转化为对应MapReduce任务,查询和统计HDFS中的数据,最终实现校园网视频用户不同维度下的偏好统计及视频Top-N推荐列表。
3 实验结果与分析
3.1 实验环境与数据采集
Hadoop集群实验平台搭建在单位网络中心,该集群硬件配置:普通双核CPU的PC机,其中一个NameNode配备8 GB内存和500 GB硬盘,5个DataNode均配备4 GB内存和500 GB硬盘,交换机连接各节点;软件配置:Hadoop 1.1.2、Hive 0.9.0,MySQL 5.1.73和 JDK1.7.0_45。数据采集配置Hcap-224F千兆采集卡。
实验随机抽取校园内5幢学生宿舍作为流量数据采集对象,对照校园网网管中心机房端口映射关系,将采集数据保存为pcap格式离线文件。数据采集时间从每天8:00—24:00,2013年12月9日至2013年12月12日,总计采集校园网流量数据2 020 GB。
3.2 实验结果
3.2.1 校园网视频访问偏好分析
通过Hive统计不同维度下校园网视频用户的访问偏好,与国内同期发布的权威报告相关数据和结论对比,分析了校园网用户的视频偏好特点。
图2是校园网用户对主流视频网站的偏好统计。男生偏好优酷网,其次是土豆网、搜狐网和乐视网,最后是迅雷看看。女生同样偏好优酷网,其次是搜狐网和乐视网,二者几乎持平,接着是爱奇艺,访问量明显高于男生,最后是迅雷看看。
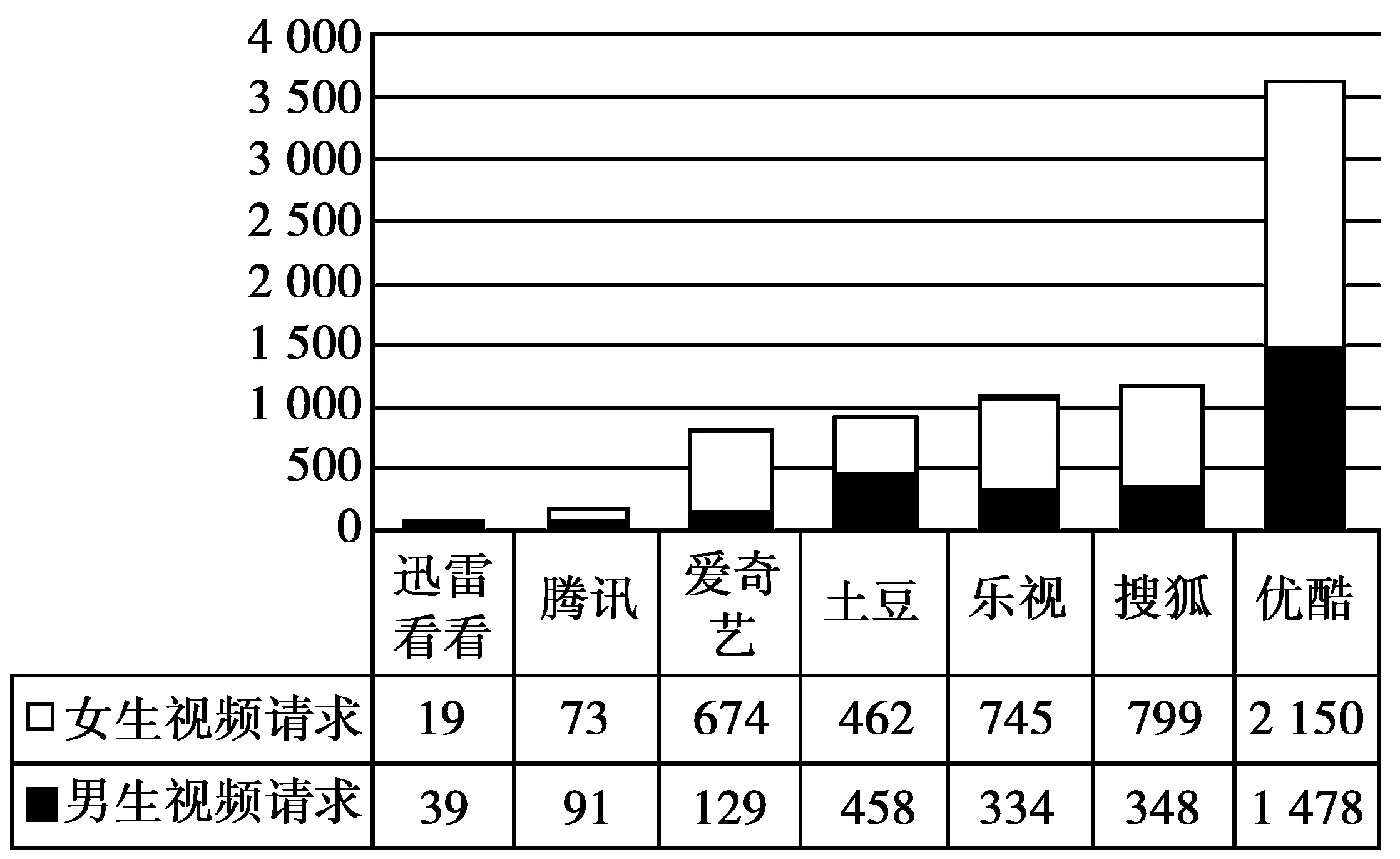
图2 视频网站偏好统计Fig.2 Video website preference statistics
图3是校园网用户对视频频道的偏好统计。男生视频频道Top-5:生活、新闻资讯、娱乐音乐、原创和动漫;女生视频频道Top-5:电视剧、综艺、教育、电影和动漫。区别于文献[6]中电影、电视剧、综艺节目名列前三的结果,反映了校园网视频用户对频道选择的差异性。
表2是校园网用户对视频节目的偏好的Top-10排序。文献显示国内同期大众视频频道偏好依次为:电视剧、电影、综艺节目和动漫节目[1,5-6]。电视节目偏好依次为:剧情剧《大丈夫》、爱情剧《来自星星的你》和喜剧《天真遇到现实》。通过与校园网流量视频用户偏好分析对比,可以看出,由于受教育程度、文化水平、用户年龄的不同,造成校园网用户群体对视频的偏好与需求的差异。校园网流量视频用户的偏好特征:首选优酷网,偏爱电视剧或综艺节目,并且男女生反映出较大偏好差异。

图3 视频频道偏好统计Fig.3 Video channels preference statistics
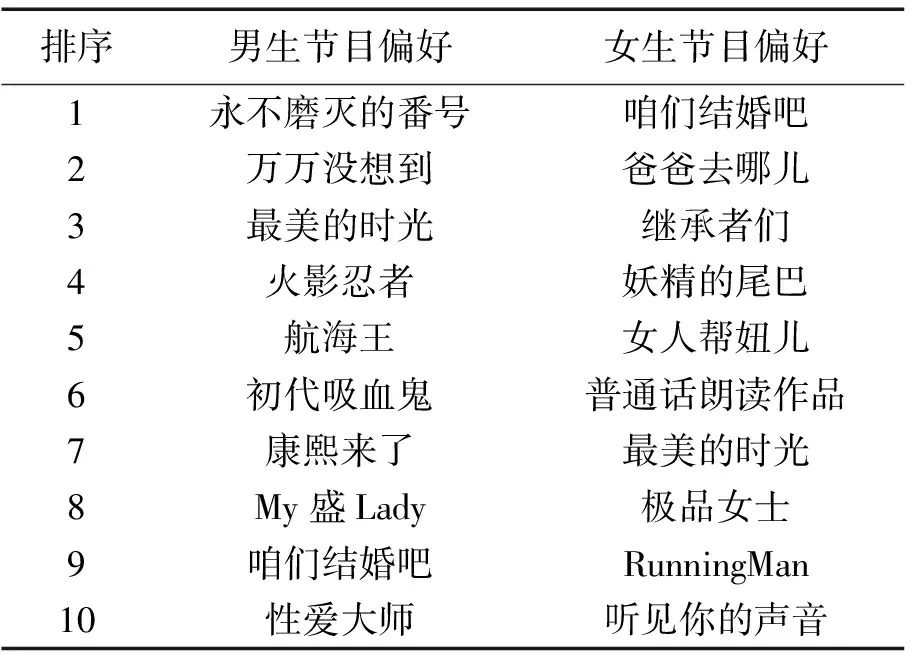
排序男生节目偏好女生节目偏好1永不磨灭的番号咱们结婚吧2万万没想到爸爸去哪儿3最美的时光继承者们4火影忍者妖精的尾巴5航海王女人帮妞儿6初代吸血鬼普通话朗读作品7康熙来了最美的时光8My盛Lady极品女士9咱们结婚吧RunningMan10性爱大师听见你的声音
对群体用户偏好和需求的分析,需要识别和统计群体内各个用户的特征。面向群体的不同兴趣或偏好分布,不仅为用户提供个性化服务,还能为内容提供商提供定向策略的依据。通过以上分析,验证了本文所提方案对于视频用户访问偏好深度挖掘的可行性和有效性。
3.2.2 Hive和MySQL查询效率对比
查询效率受3个方面影响:①数据集大小(有多少行);②查询语句;③查询平均时间。为验证Hive统计在本文实验环境下的高效性,本文设计以下实验:利用3个不同大小的数据集,在相同MapReduce编程模型下,分别在Hive和MySQL上执行相应的7条查询语句,每条查询语句执行5次并记录平均执行时间,对比查询效率。
MySQL平均查询时间随着数据量的增长骤然增加。存储引擎结构以及查询执行机制从根本上限制了MySQL的查询效率。MySQL通过主键方式访问数据,查询语句执行需要所有数据节点参与数据检索。当跨越数据节点访问MySQL服务器和各表数据时,获取所有数据节点数据会造成网络接入延迟。
Hive查询数据以分布式、cvs格式纯文本文件存储在HDFS中,不同于MySQL数据存储于查询机制,Hive只需对作为主键的元数据进行存储调度,并指定文件存储位置。查询时仅读取文件索引,而非整个文件,使Hive快速查询得以实现。
图4对比了MySQL和Hive的平均处理时间,数据量越大,MySQL占用内存越多,处理效率越低。在本实验环境下,约在69.6 MB数据量时,二者查询效率出现转折点,Hive逐渐显现出查询优势。验证了在低成本硬件设备环境下,对于大数据的处理,Hive比MySQL的查询效率更高、健壮性更好。
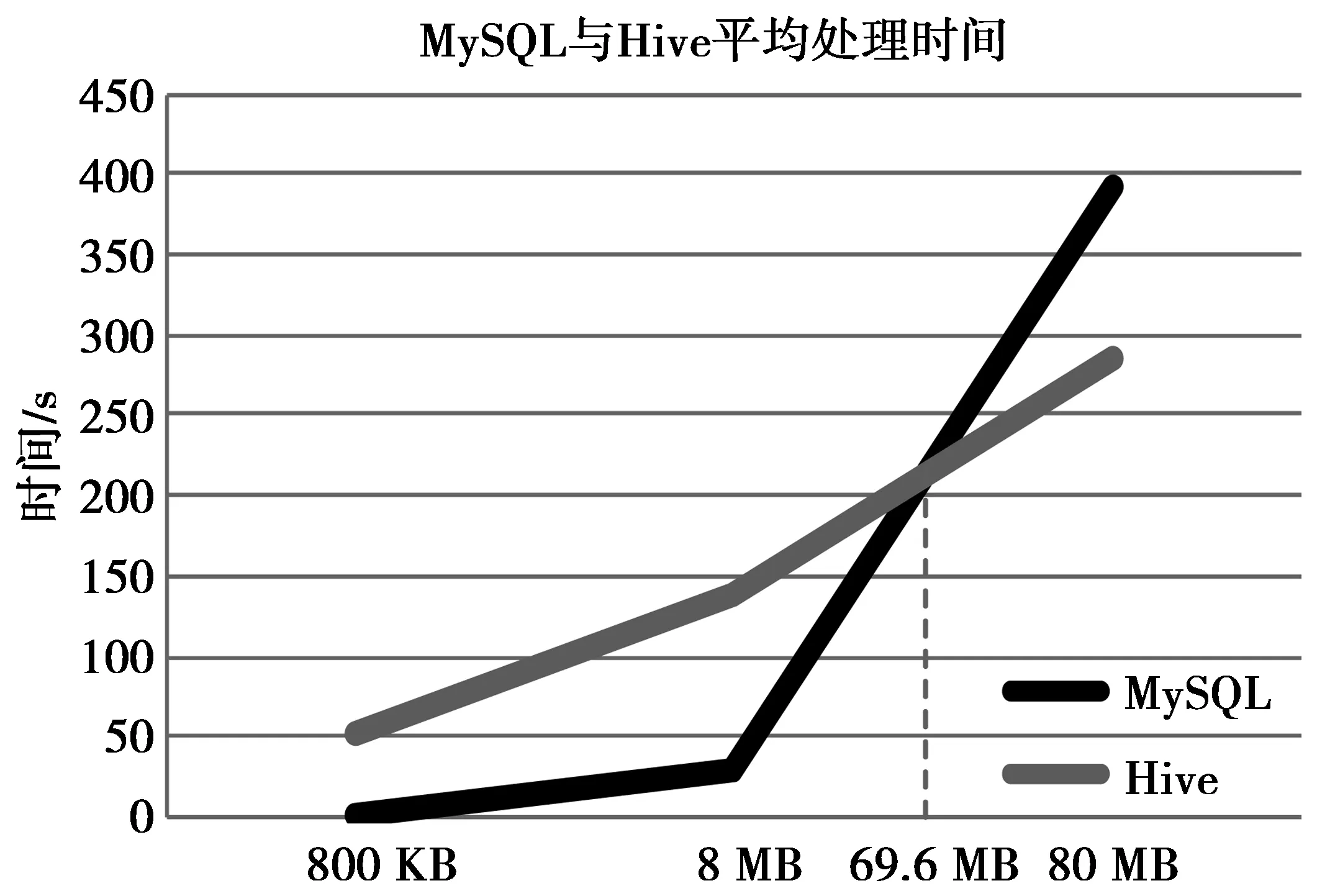
图4 MySQL和Hive平均处理时间Fig.4 Mean processing time of MySQL and Hive
4 结束语
本文面向互联网数据原始流量,提出了一个基于Hadoop的校园网视频流量访问偏好分析方案。它利用网络爬虫和深度包检测技术,完成了主流视频网站产品信息库的建立、视频访问事件特征提取和识别,最后利用Hive数据库完成了偏好统计分析,并对MySQL和Hive查询效率进行对比。结果表明,由于文化层次的差异,不同用户群体的视频需求存在较大的差异性;在低成本硬件设备环境下,对于大数据的处理,Hive比MySQL查询效率更高,随着数据量的增大,Hive有更好的健壮性。本方案能稳定、可靠地实现校园网视频流量访问偏好分析,将有助于捕捉用户网络舆情、制定定向营销方案以及提供个性推荐服务。
在未来实际应用工作中,还可对硬件环境进行改善,执行更复杂的查询语句。对除MySQL外的关系型数据库,如Oracle,联合Hive,Pig等Hadoop统计模型,进行相关性能的测试,以便使分析结果更接近实际。
[1] 中国互联网络中心. 第36次中国互联网络发展状况统计报告[EB/OL]. [2015-07-01]. http://www.cnnic.net.cn/hlwxzbg/hlwtjbg/201507/P020150723549500667087.pdf. CNNIC.The 36th Report of China Internet Network Development State Statistic[EB/OL].[2015-07-01].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201507/P020150723549500667087.pdf.
[2] WU Haitao,FENG Zhenqian, GUO Chuanxiong, et al. ICTCP: Incast congestion control for TCP in data-center networks [J]. IEEE/ACM Transactions on Networking (TON), 2013, 21(2): 345-358.
[3] ZHAO D, TRAORE I, SAYED B, et al. Botnet detection based on traffic behavior analysis and flow intervals[J]. Computers & Security, 2013, 39: 2-16.
[4] RICHARD S W. TCP/IP Illustrated Volume 3: TCP for Transactions, HTTP, NNTP and the UNIX Domain Protocols [M]. USA: Addison-Wesley, 2002:129-165.
[5] 中国互联网络中心. 2013年中国网民网络视频应用研究报告[EB/OL]. [2014-06-09]. http:// www.cnnic.net.cn/hlwfzyj/hlwxzbg/spbg/201406/t20140609_47180.htm. CNNIC. 2013 Study Report of Chinese Internet Video Network Users Applications[EB/OL]. [2014-06-09]. http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/spbg/201406/t20140609_47180.htm.
[6] 艾瑞咨询. iVideoTracker视频媒体用户行为分析报告[EB/OL]. [2015-09-15]. http:// news.iresearch.cn/zt/254353.shtml. I Research. IVideoTracker Video Media User Behavior Analysis Report[EB/OL]. [2015-09-15]. http:// news.iresearch.cn/zt/254353.shtml.
[7] LEE Yeonhee, LEE Youngseok. Toward scalable internet traffic measurement and analysis with hadoop [J]. ACM SIGCOMM Computer Communication Review,2013,43(1):5-13.
[8] FUKUMOTO Norihiro, ANO Shigehiro, GOTO Shigeki. A practical behavior analysis of video application users on smart phones[C]// Computer Software and Applications Conference (COMPSAC), 2013 IEEE 37th Annual. Kyoto: IEEE, 2013: 288-289.
[9] YAMAKAMI T. Mobile video user revisit analysis based on multi-day visiting patterns [C]// Advanced Communication Technology (ICACT), 2010 The 12th International Conference on. [s.L.]: IEEE, 2010, 2: 1435-1439.
[10] RODRIGUEZ D, ROSA R, ALFAIA Costa, et al. Video quality assessment in video streaming services considering user preference for video content [J]. Consumer Electronics, IEEE Transactions on, 2014, 60(3): 436-444.
[11] FUAD A, ERWIN A, IPUNGH H. Processing performance on Apache Pig, Apache Hive and MySQL cluster[C]// Information, Communication Technology and System (ICTS), 2014 International Conference on. Surabaya: IEEE, 2014: 297-302.
[12] LUO Jiangtao, LIANG Yan, GAO Wei, et al. Hadoop based Deep Packet Inspection system for traffic analysis of e-business websites[C]// Data Science and Advanced Analytics (DSAA), 2014 International Conference on. Shanghai:IEEE, 2014: 361-366.
[13] Apache. Hadoop[EB/OL]. [2015-09-30]. http://hadoop.apache.org.
[14] WHITE T. Hadoop: The definitive Guide. [M]. 2nd. USA: O’Reilly, 2012.
[15] LUO Yifeng, LUO Siqiang, GUAN Jihong, et al. A RAMCloud storage system based on HDFS: Architecture, implementation and evaluation [J]. The Journal of Systems and Software, 2013, 86(3): 744-750.
[16] Apache. Hive.[EB/OL]. [2015-10-01]. https://cwiki.apache.org/confluence/display/Hive/Home
[17] CAPRIOLO E, WAMPLER D, RUTBERGLEN J. Hive Programming [M]. USA: O’Reilly, 2013.

许闻秋(1990-),云南昆明人,女, 硕士研究生,主要研究方向网络流量分类与识别、数据挖掘。E-mail:xuwenqiu_xenia@163.com。

雒江涛(1971-),男,教授/博导,主要研究方向为新一代网络技术和移动互联网数据挖掘。E-mail:luojt@cqupt.edu.cn。 杨军超(1988-),男,博士研究生,主要研究方向大数据。E-mail: 262256660@qq.com。
(编辑:魏琴芳)
Hadoop based analysis of access preference for campus video traffic
XU Wenqiu, LUO Jiangtao, YANG Junchao
(Electronic Information and Networking Research Institute, Chongqing University of Posts and Telecommunications,Chongqing 400065,P.R. China)
There are poor objectivity of data and difficult association analysis in traditional user preference analysis approach with video access log. To solve this problem, the Hadoop based scheme of video user access preference analysis in campus network is proposed by using the original traffic from internet in this paper. The scheme was designed to refine identification of video access content by using the technology of web crawler and deep packet inspection. And the access preference for campus video traffic is analyzed in further. The query efficiency was compared between MySQL and Hive at the same time. The results demonstrate that the difference level of culture leads to the variation of video needs among user groups, and under the low cost hardware environment, Hive is robust for the processing of large data. The scheme is stable and reliable to realize the analysis of access preference for campus video traffic, capturing user network public opinions, working out customized marketing plans and providing service of personalized video recommendation. Through testing in current network environment, the scheme of video user preference analysis proposed in this paper works well as what is expected.
campus network video; preference analysis; Hadoop; web crawler; deep packet inspection
10.3979/j.issn.1673-825X.2016.06.024
2015-09-23
2016-08-31
许闻秋 xuwenqiu_xenia@163.com
重庆市应用开发计划资助项目(cstc2013yykfA40006);2013重庆高校创新团队建设计划(KJTD201312)
Foundation Items:The Application Development Foundation Project of Chongqing (cstc2013yykfA40006); The Innovation Teams Building Program of Chongqing Universities in 2013 (KJTD201312)
TP391;TN929.5
A
1673-825X(2016)06-0897-06
