一种变粒度的规则提取算法
2017-01-03胡帅鹏张清华姚龙洋
胡帅鹏,张清华,2,姚龙洋
(1. 重庆邮电大学 计算智能重庆市重点实验室,重庆 400065;2. 重庆邮电大学 理学院,重庆 400065)

一种变粒度的规则提取算法
胡帅鹏1,张清华1,2,姚龙洋1
(1. 重庆邮电大学 计算智能重庆市重点实验室,重庆 400065;2. 重庆邮电大学 理学院,重庆 400065)
属性约简和值约简是粗糙集理论中知识获取的重要组成部分。通常,在知识获取的过程中先进行属性约简,然后在其基础上进行规则提取。但在实际应用中,属性约简在简化信息系统与提高规则提取效率的同时,原始信息系统中有些重要的条件属性可能被丢弃,从而导致属性约简后对信息系统进行知识获取得到的规则其数量与简化程度并不占优。针对上述问题,提出一种基于粒度变化的规则获取算法,通过属性粒度从粗到细的变化,直接从原始信息系统中提取规则;采用该方法得到的规则与属性约简后得到的规则相比,它们的数量与平均每条规则包含的特征属性数相对较少。最后,在理论分析的基础上,通过实例验证了算法可行性,并通过实验验证了算法的正确性和高效性。
粗糙集;属性约简;规则提取;多粒度
0 引 言
由波兰数学家Z.Pawlak在1982年提出的rough sets[1],能有效地分析和处理不精确、不一致、不完整等各种不完备信息,并从中发现隐含的知识,揭示潜在的规律。经过三十余年的发展,该理论已渗透到各个行业,在工业控制、医学卫生及生物科学、交通运输、农业科学、环境科学与环境保护管理、安全科学、社会科学、航空、航天和军事等领域中得到了广泛应用[2]。
知识获取是粗糙集的理论研究中的一项核心内容,主要是通过对原始决策表的约简,在保证决策表的决策属性和条件属性之间的依赖关系不发生变化的前提下,对决策表进行约简,包括属性约简和值约简。目前国内外学者针对属性约简和值约简的算法进行了大量的研究,其中,属性约简有基于代数观、信息观和正区域的约简算法[3-12];值约简有基于可辨识矩阵、逻辑运算以及启发式的约简算法[13-17]。这些方法往往专注于某一项,从而忽视了属性约简对值约简的影响,从而导致约简效果并不理想。如文献[13]中,属性约简的结果有多种,需要值约简的结果来判定;文献[14-15]并没有有效地对规则进行简化;文献[16]虽然在规则的简化程度上取得明显效果,但在规则的数量上没有明显降低。从目前的研究看来,知识约简是知识获取的关键步骤,研究者往往给出某种启发式信息,然后设计某种启发式约简算法,在知识空间中按照自顶向下或自底向上的方式实现约简。知识约简的主要目的是在保持信息系统分辨能力不变的前提下,删除冗余属性。这存在一个关键性问题,在知识约简的过程中,条件属性的删除,主要基于主观的启发式方法,而不是基于是否对获取规则有利。这就导致了某些信息系统在约简后获取的规则在其数量与简化的程度上并不是最优的。本文通过实例验证了某些信息系统直接获取的规则优于对其属性约简后获取的规则。针对一致信息系统,本文提出了一种新的获取规则的算法,从正面直接获取规则。在该算法中,提出了一种判定条件属性是否是规则原理,即条件属性对论域的划分的标记是否相同,并对原理给予了证明。该算法主要基于粒计算的粗糙集模型[18-22],在条件属性粒度由粗到细[23]变化的过程中,直接选取满足要求的最优的规则。
1 基本概念
为了更好地描述问题,首先介绍相关的概念。
定义1(决策表信息系统)[24]决策表信息系统可以表示为S=(U,A,V,f),其中,U是对象全集,也称为论域,它是非空有限的对象集合;A=C∪D是属性全集,子集C和D分别称为条件属性集和决策属性集,且C∩D=∅;V是属性值的集合,即属性集A的值域;f:U×A→V,f为一个信息函数,表示每个实例对象的每个属性赋予一个信息值。
定义2(不分明关系(Indiscernible relations))[24]设S=(U,A,V,f)是一个信息系统,R是一个属性子集且R⊆A,决定了一个不可区分二元关系:IND(R)={(x,y)|(x,y)∈U2,∀b∈R(b(x)=b(y))}。
不可区分二元关系IND(R)构成了U的划分,记为U/IND(R),且U/IND(R)={[x]R|x∈U},其中,[x]R={y|∀a∈R,f(x,a)=f(y,a)}。

定义4(知识颗粒)[19]设S=(U,A,V,f)是一个信息系统,其中A={c1,c2,…,cm}是属性集,任给一个属性子集R(R⊆A),我们可以得到论域U的一个划分U/IND(R)。U/IND(R)的每个元素[x]R([x]R表示对象的等价类) 表示一个知识颗粒。
属性子集R包含属性越多,知识颗粒越大;它与知识的粒度的变化趋势相似,都随着属性子集R的多少由粗到细变化。
定义5(决策属性划分标号) 设S=(U,A,V,f)是一个信息系统,U是论域,A是属性集,且A=C∪D。决策属性对论域的划分为U/IND(D)={Y1,Y2,…,Yi,…,Yk},1≤i≤k,即决策属性把论域划分为k个等价类,第i个等价类包含论域对象序号标记为i,记为g(Yi)=i。
定义6(条件属性子集划分标号)S=(U,A,V,f)是一个信息系统,U是论域,A是属性集,且A=C∪D。任给一个条件属性子集B(B⊆C),U/IND(B)={X1,X2,…,Xl},根据定义5中决策属性划分的论域对象标号,依次填入等价类Xj,(j=1,2,…,l)中,并记Xj所对应的标号集合为Ej={p|∀x∈Xj∧x∈Yi,p=g(Yi)},其中,p表示Xj中元素的标号,x表示论域的对象。
决策属性的等价类划分使论域中每个个体都有一个标号,且每个Yi中标号统一为i;在条件子集的等价类Xj中,标号不同,即∃pb∈Ej,pc∈Ej(pb≠pc);标号完全相同,即∀pb∈Ej,pc∈Ej(pb=pc)。当等价类Xj中的标号相同时,且为i,记N(j)=i。
定理1当且仅当N(j)=i成立时,条件属性子集B(B⊆C)对应的条件属性值是等价类Yi的子集的一个规则。
证明:设S=(U,A,V,f)是一个信息系统,U/IND(D)={Y1,Y2,…,Yi,…,Yk}是决策属性集对论的划分,第i个划分子集对应的标号记为i。条件属性子集B对论域的划分记为U/IND(B)={X1,X2,…,Xj,…,Xl},Xj中的标号由Yi对论域的标记而来。
1)当N(j)=i时,由定义6知Xj对应的论域对象是Yi对应的论域对象的子集,因此Xj⊆Yi成立。因为U/IND(B)={X1,X2,…,Xj,…,Xl},所以用条件属性子集B可以区分出Xj对应的论域对象,即B对应的条件属性的值为Xj对应的论域对象的一个规则。且Xj⊆Yi,所以集合B对应的条件属性值是等价类Yi的子集的一个规则。
2)当条件子集B对应的条件属性值是等价类Yi的子集的一个规则时:集合B对论域形成划分为U/IND(B)={X1,X2,…,Xj,…,Xl},则至少存在一个等价类是Yi对应论域的一个子集,不妨设为Xj。如果Xj对应的论域对象不是Yi对应的论域的子集,则它们至少分属在2个子集中,即∃p≠q,p,q∈{1,2,…,k}(Xj∩Yp≠∅,Xj∩Yq≠∅),所以该论域对象不可区分,即条件子集B对应的条件属性值不能形成规则。所以Xj对应的论域是Yi对应的论域的子集,Xj⊆Yi成立。由于Yi对应的论域标号为i,所以Xj对应的论域也标号为i,即有N(j)=i。
定理1表明,在信息系统S=(U,A,V,f),U/IND(D)={Y1,Y2,…,Yi,…,Ym}为决策属性集对论的划分;条件属性子集B(B⊆C),子集B对论域的划分为U/IND(B)={X1,X2,…,Xj,…,Xk},当N(j)=i成立时,属性子集B可以正确区分决策属性的等价类Yi对应的论域U中的对象。

定义8(规则选取顺序) 在进行规则选取时,不能盲目的进行,应按照一定的顺序,这可以降低规则选取难度,加快规则选取的效率。规则选取的一般顺序如下:
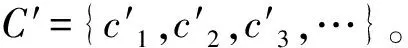
这一步选择是为了保证剩下的任何一个论域都至少对应2条规则。
2)在上一步2的基础上,根据剩余的论域对象,比较区分度δ的大小,优先选取区分度δ较大的规则;同时把新的条件属性加入C′中。
3)如果区分度相同,优先选取规则所对应的条件属性在C′中;并把新的条件属性加入C′中。
它的主要目的是在粒度相同的条件下,用最少的规则数区分出最多的未出现的对象。它的基本原理是,每选取一条规则,都尽量多的区分未识别对象。
2 问题引入
在粗糙集中,知识获取的最终目的是规则获取。这些得到的规则是对整个信息表的高度概括,应包括整个信息表所要表达的完整信息。知识获取的一般步骤是先进行属性约简,然后再做值的约简,最后得到规则。这是因为属性约简后得到的信息表往往可以大幅度改善值约简的时间和空间复杂度。在属性约简时,某些条件属性对信息表而言可以删除,而对规则获取来说是一个不错的选择,如果删除它们,得到的规则可能不是最优。
表1的信息系统1中记录的是某件产品测试的具体信息,共有6个对象。条件属性a,b,c分别表示3项测试项目的测试结果;决策属性Y表示是否合格。
根据文献[12]中提出基于差别矩阵的属性约简方法,得出该信息系统的3种属性约简结果,分别是{a,b}、{a,c}和{b,c}。用这3种属性约简的结果进行规则获取,得出的规则如下所示。
1)以{a,b}为条件属性得到的规则如下,记为规则集1:
①(a,1),则Y=R;
②(b,2),则Y=N;
③(a,2)且(b,1),则Y=P;
④(a,3)且(b,3),则Y=P;
2)以{a,c}为条件属性得到的规则如下,记为规则集2:
①(a,1),则Y=R;
②(c,3),则Y=P;
③(a,2)且(c,1),则Y=N;
④(a,3)且(c,2),则Y=N;
3)以{b,c}为条件属性得到的规则如下,记为规则集3:
①(b,2),则Y=N;
②(c,3),则Y=P;
③(b,1)且(c,1),则Y=R;
④(b,3)且(c,2),则Y=R;
规则集1~3的规则数量都为4,包含的特征属性最大值为2,平均每条规则包含的特征属性数为1.5。
4)但以原始信息系统{a,b,c}为条件属性得到的规则如下,记为规则集4:
①(a,1),则Y=R;
①(b,2),则Y=N;
②(c,3),则Y=P;
规则集4的规则数量为3,包含的特征属性均为1,平均每条规则包含的特征属性数为1。
分别根据规则集1~3与规则集4进行测试时,无论是在规则数量、或者包含的特征属性最大值以及规则的简化程度上后者都优于前者。每个对象的最差测试量(最坏情况下,得出最终结果需要测试的特征属性个数)前者比后者高50%。

表1 信息系统1
为了从上述3方面得出较优的规则,下文从原始信息系统出发,提出了一种基于变粒度的标记法进行规则提取。
3 算法描述
属性约简的算法,一般是按照自顶向下设计启发式算法,逐渐增加重要属性,直到得到约简的结果为止;或是按照自底向上设计启发式算法,逐渐删除不重要属性,直到得到约简的结果为止。它们都是通过侧面逼近的方法进行约简,而规则获取是在其基础上进行的,获取的规则存在限制,难免有些许不如意的地方。本文提出一种正面选取规则的算法。算法主要先对论域标号,再从条件属性的粒度由粗至细变化的过程中对论域的划分中选取标号相同的项,直接提取其对应的规则,并组合成完整论域的规则。
3.1 算法步骤
算法的流程图如图1所示。
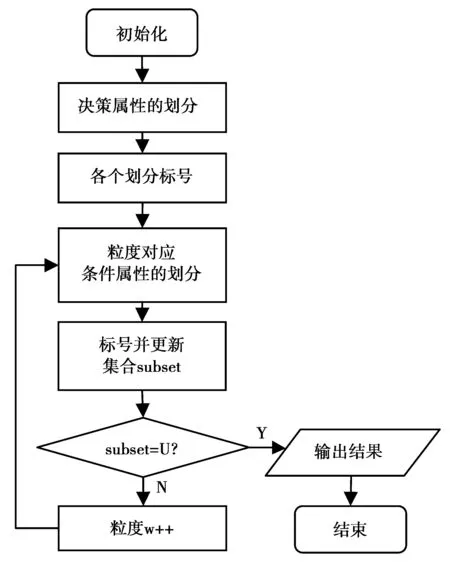
图1 流程图Fig.1 Flowcharting
输入:信息系统S=(U,A,V,f)。
输出:该信息系统规则获取的结果。
Step 1 首先初始化原始信息系统,设论域U={x1,x2,…,xn},对象数量为|U|=n。条件属性C={a1,a2,…,am},条件属性个数|C|=m,可区分对象集subset=∅,粒度w=1。
Step 2 其次,再求决策属性D对论域划分,U/IND(D)={Y1,Y2,…,Yi,…,Yk}。
其中Yi={xi1,xi2,xi3,…}对应包含的对象序号。
Step 3 根据定义5,对每个对象进行标号:
for(i=1;i<=k;++i)
for(j=1;j<=n;++j)
if(xj∈Yi)xj←i
Step 4 粒度由粗到细变化,即条件属性的个数由少到多递增时,求取其对论域的划分:while(w≤m)
U/IND(aw)={X1,X2,…,Xl}
Step 4.1 把Step 3得到的标号填入Xl中;
Step 4.2 根据定理1,首先找出所有Xl中标号相等的等价类,它所对应的是当前可以区分的对象,然后把不重复的对象加入subset中,并记录subset={xw1,xw2,…,xwt}。
Step 4.3 根据定义8规则的选取顺序,找出所有不重复的规则。
Step 4.4 ifU=subset,end;elsew=w+1,继续执行Step 4。
算法说明:①算法以U=subset为结束条件,所以规则确定的论域与原始论域相同,即规则可以覆盖整个论域。②算法在执行时,以包含的条件属性数从少到多逐步的递增,当规则最长为length(length正整数,表示规则包含条件属性的个数,且1≤length≤card(C))时,不能完全覆盖整个论域,才验证包含长度为length+1的规则长度。所以,获得的规则包含的特征属性数一定是最小的。③为了满足①与②所述的特征,即保证所求规则对论域的覆盖率为100%,且规则数最少和平均每条规则包含的特征属性数最小,需要粒度从粗到细逐步变化,所以导致算法的时间复杂度较高。但是,由于不同粒度之间计算相互独立,互不影响,所以采取了并行运算方式,可以把算法的时间复杂度降低到与计算条件属性对论域的划分相当。
3.2 算法举例
如表2所示的信息系统,其中论域U={1,2,…,15},C={a1,a2,a3,a4},D={d}。
Step 1 论域中对象的数量|U|=l=15,条件属性个数|C|=n=4。
Step 2U/IND(d)=Y={{1,2,6,8,14},{3,4,5,7,9,10,11,12,13,15}}。
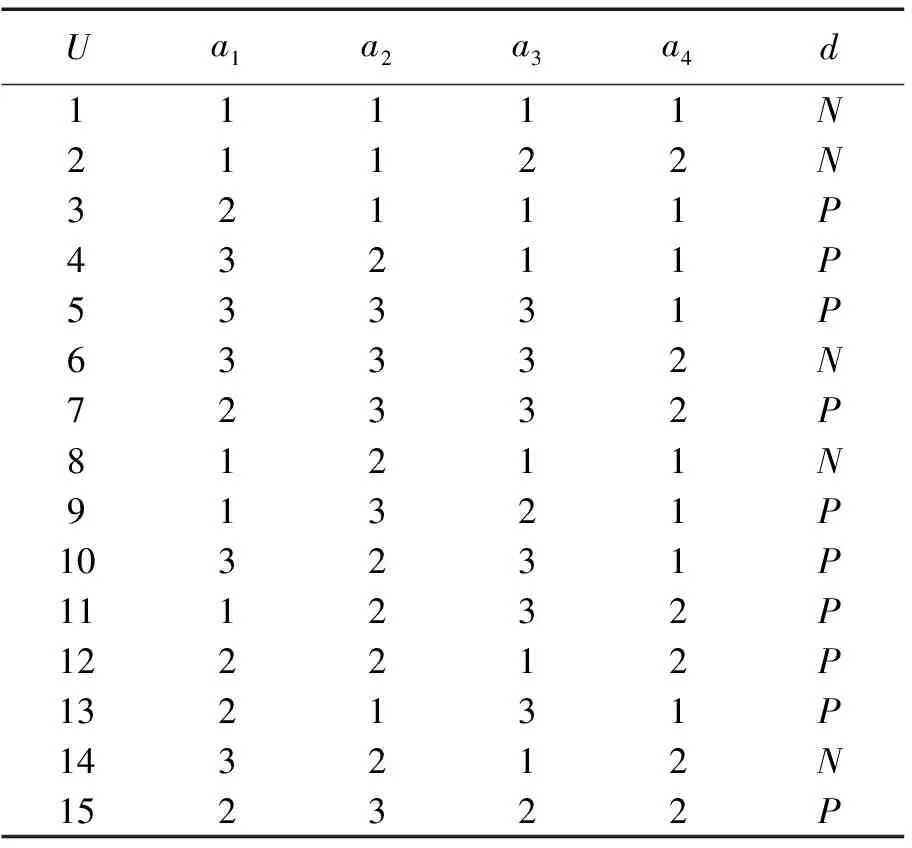
表2 信息系统2
Step 3 根据定义5进行标号,标记后为:{{1(1),2(1),6(1),8(1),14(1)},{3(2),4(2),5(2),7(2),9(2),10(2),11(2),12(2),13(2),15(2)}}。
Step 4 粒度由粗到细变化,首先当w=1时,G1={{a1},{a2},{a3},{a4}},Xa1={{1,2,8,9,11},{3,7,12,13,15},{4,5,6,10,14}},Xa2={{1,2,3,13},{4,8,10,11,12,14},{5,6,7,9,15}},Xa3={{1,3,4,8,12,14},{2,9,15},{5,6,7,10,11,13}},Xa4={{1,3,4,5,8,9,10,13},{2,6,7,11,12,14,15}}。
Step 4.1 根据定义6得对应映射值如下:VXa1={(1,1,1,2,2),(2,2,2,2,2),(2,2,1,2,1)},VXa2={(1,1,2,2),(2,1,2,2,2,2),(2,1,2,2,2)},VXa3={(1,2,2,1,2,1),(1,2,2),(2,1,2,2,2,2)},VXa4={(1,2,2,2,1,2,2,2),(1,1,2,2,2,1,2)}。
Step 4.2,4.3 只有VXa1的N(2)=2,说明只用属性a1的值就能正确区分第二个等价类,即{3,7,12,13,15},subset={3,7,12,13,15}。此时条件属性集合为a1,所以选取规则得:
规则1:(a1,2),则Class=P;
Step 4.4 因为subset={3,7,12,13,15}≠U,所以++w,返回继续执行step 4。
Step 4 粒度进一步细分,变更为w=2,得G2={{a1a2},{a1a3},{a1a4},{a2a3},{a2a3},{a3a4}}。
Step 4.1 根据定义6得对应映射值为VXa1a2={(1,1),(2,2),(2,2,1),(2,1),(2,2),(1,2),(2),(2)},VXa1a3={(1,1),(1,2),(2,2),(2,1),(2,1,2),(2,2),(2),(2)},VXa1a4={(1,1,2),(1,2),(2,2),(2,2,2),(1,1),(2,2,2)},VXa2a3={(1,2),(1),(2,1,2,1),(2,1,2),(2,2),(2,2),(2)},VXa2a4={(1,2,2),(1),(2,1,2),(2,2),(1,2,2),(2,2,1)},VXa3a4={(1,2,2,1),(1),(2,2,2),(1,2,2),(2,2),(2,1)}。
Step 4.2 所有满足N(p)=q的不重复subset={1,2,3,4,5,6,7,8,9,10,11,12,13,14,15}。
Step 4.3 根据定义8,由于论域中第4项与第8项为唯一的,首先选择规则:
规则2:(a1,1) 且 (a3,1),则Class=N;
规则3:(a1,3) 且 (a4,1),则Class=P;

规则4:(a1,3) 且 (a4,2),则Class=N;
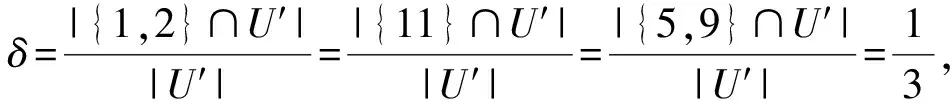
规则5:(a1,1)且(a2,1),则Class=N;
规则6:(a2,2)且(a3,3),则Class=N;
规则7:(a2,3)且(a4,1),则Class=P。
Step 4.4:此时,subset=U,结束。
同时,分析表2,{a1,a2,a4}与{a1,a3,a4}是其属性约简的结果。如果单独用{a1,a2,a4}或{a1,a3,a4}进行规则获取,最长的规则都为3,但是,用{a1,a2,a3,a4}进行规则获取时,用2个条件属性形成的规则,足够区分整个论域。 这充分体现出了在进行规则提取时,完整的信息系统优于约简后的信息系统性。
4 实验结果
为了验证本文中的算法,我们在Pentium(R) CPU3.00 GHz,RAM=4 GB微机上,Visual studio 2013上的C++ 环境下,采用UCI机器学习数据库中的数据集进行测试。为证明其效果,我们用Rosetta软件作了对比测试:在试验中,除了monks(采用Rosetta自带的genetic algorithm算法进行约简)外,都是采用Rosetta自带的Dynamic reduction算法进行约简,再采用Rosetta自带的值约简算法进行规则的获取,保证它们在该约简算法中的得到的属性个数与规则数相对最好,得出的测试结果如表3所示。从表3中可知,和Rosetta软件相比,本文算法得到的决策规则在规则数量上与平均每条规则包含的特征属性个数都比Rosetta软件得到的少,同时对测试集的分类正确识别数也与Rosetta软件得到的结果相当。因此,本文算法是有效和可行的。

表3 实验结果
5 结束语
属性约简与值约简是知识获取的核心,但算法大多集中于属性约简,对属性值的约简研究相对较少。本文提出一种基于变粒度的规则提取算法,主要是解决了对于某些信息系统进行规则提取时,有些重要的条件属性在属性约简中可能丢失,从而导致规则提取时提取的规则不是最优这一问题。该算法从正面直接选取合适的规则,直到没有剩余区分项,因此获得规则可以覆盖整个论域。且粒度从粗到细变化,保证规则的长度最短。该算法为规则提取提供了一种新的方法。由于该算法比较适用信息系统较小的情况下,在下一步的研究中,将在并行计算与增量式的方向进行研究,来改善算法的执行效率。
[1] PAWLAK Z.Rough Set[J].International Journal of Computer and Information Science,1982,11(5):341-356.
[2] 王国胤,姚一豫,于洪.粗糙集理论与应用研究综述[J].计算机学报,2009,32(7):1229-1246. WANG Guoyin,YAO Yiyu, YU Hong. A survey on Rough Set theory and applications[J]. Chinese Journal of Computers, 2009, 32(7):1229-1246.
[3] HU Xiaohu, CERCON N. Learning in relational databases: a rough set approach[J]. Computational Intelligence, 1995, 11(2):323-338.
[4] 王国胤,于洪,杨大春.基于条件信息熵的决策表约简[J].计算机学报,2002,25(7):759-766. WANG Guoyin,YU Hong,YANG Dachun. Decision table reduction based on conditional information entropy[J].Chinese Journal of Computers,2002,25(7):759-766.
[5] WANG Guoyin. Rough reduction in algebra view and information view[J]. International Journal of Intelligent Systems, 2003, 18(6):679-688.
[6] 刘少辉,盛秋戬,吴斌,等.Rough集高效算法的研究[J].计算机学报,2003,26(5):524-529. LIU Shaohui, SHENG Qiujian, WU Bin, et al. Research on efficient algorithms for Rough Set methods[J]. Chinese Journal of Computers, 2003, 26(5):524-529.
[7] 冯琴荣,苗夺谦,程昳.决策表属性约简的相对划分粒度表示[J].小型微型计算机系统,2008,29(12):2305-2308. FENG Qinrong, MIAO Duoqian, CHENG Yi. Presentation of relative partition granularity of attributes reduction for decision table[J]. Mini-Micro Systems, 2008, 29(12):2305-2308.
[8] 杨明.一种基于一致性准则的属性约简算法[J].计算机学报,2010,33(2):231-239. YANG Ming. A novel algorithm for attribute reduction based on consistency criterion[J]. Chinese Journal of Computers, 2010, 33(2):231-239.
[9] XU Zhangyan, ZHANG Wei, WANG Xiaoyu, et al. A quick attribute reduction algorithm based on knowledge granularity[C]//Fuzzy Systems and Knowledge Discovery (FSKD), 2012 9th International Conference on. Chinese: IEEE, 2012:220-223.
[10] ZHANG Tengfei,YANG Xingxing,MA Fumin.Algorithm for attribute relative reduction based on generalized binary discernibility matrix[C]∥Control and Decision Conference(2014 CCDC).Chinese:IEEE,2014:2626-2631.
[11] 苗夺谦,胡桂荣.知识约简的一种启发式算法[J].计算机研究与发展,1999,36(6):681-684. MIAO Duoqian, HU Guirong. A heuristic algorithm for reduction of knowledge[J]. Journal of Computer Research and Development, 1999, 36(6):681-684.
[12] 马希骜,王国胤,于洪.决策域分布保持的启发式属性约简方法[J].软件学报,2014,25(8):1761-1780. MA Xi’ao,WANG Guoyin,YU Hong.Heuristic method to attribute reduction for decision region distribution preservation[J].Journal of Software,2014,25(8):1761-1780.
[13] 常犁云,王国胤,吴渝.一种基于Rough Set理论的属性约简及规则提取方法[J].软件学报,1999,10(11):1206-1211. CHANG Liyun,WANG Guoyin,WU Yu.An approach for attribute reduction and rule generation based on Rough Set theory[J].Journal of Software,1999,10(11):1206-1211.[14] 梁吉业,王俊红.基于概念格的规则产生集挖掘算法[J].计算机研究与发展,2004,41(8):1339-1344. LIANG Jiye, WANG Junhong. An algorithm for extracting rule generating sets based on concept lattice[J]. Journal of Computer Research and Development, 2004, 41(8):1339-1344.
[15] 文香军,蔡云泽,谭天乐,等.基于粗糙属性向量树的规则提取快速矩阵算法[J].电子学报,2006,34(1):66-70. WEN Xiangjun, CAI Yunze, TAN Tianle, et al. Fast matrix computation algorithms based on RAVT for rules extraction[J]. Chinese Journal of Electronic, 2006, 34(1):66-70.
[16] 鄂旭,邵良杉,张毅智,等.一种基于粗糙集理论的规则提取方法[J].计算机科学,2011,38(1):232-235. E Xu, SHAO Liangshan, ZHANG Yizhi, et al. Method of rule extraction based on Rough Set theory[J]. Computer Science, 2011, 38(1):232-235.
[17] QIAN Wenbin, YANG Bingru, XIE Yonghong, et al. A rule extraction algorithm based on compound attribute measure in decision systems [C]//Fuzzy Systems and Knowledge Discovery (FSKD), 2013 10th International Conference on. Chinese: IEEE, 2013: 407-411.
[18] 苗夺谦,徐菲菲,姚一豫,等.粒计算的集合论描述[J].计算机学报,2012,35(2):351-363. MIAO Duoqian, XU Feifei, YAO Yiyu, et al. Set-theoretic formulation of granular computing[J]. Chinese Journal of Computers, 2012, 35(2):351-363.
[19] 王国胤,张清华.不同知识粒度下粗糙集的不确定性研究[J].计算机学报,2008,31(9):1588-1598. WANG Guoyin, ZHANG Qinghua. Uncertainty of Rough Sets in different knowledge granularities[J]. Chinese Journal of Computers, 2008, 31(9):1588-1598.
[20] 王国胤,张清华,马希骜,等.知识不确定性问题的粒计算模型[J].软件学报,2011,22(4):676-694. WANG Guoyin, ZHANG Qinghua, MA Xi’ao. Granular computing models for knowledge uncertainty[J]. Journal of Software, 2011, 22(4): 676-694.
[21] YAO J T, VASILAKOS A V, PEDRYCZ W. Granular computing: perspectives and challenges[J]. Cybernetics, IEEE Transactions on, 2013, 43(6):1977-1989
[22] 周如旗,冯嘉礼.基于属性粒计算的认知模型研究[J].计算机科学,2014,41(7): 68-73. ZHOU Ruqi, FENG Jiali. Research on cognitive model base on attribute granular computing[J]. Computer Science, 2014, 41(7):68-73.
[23] 陈泽华,谢刚,谢珺,等.粒矩阵及其在知识约简中的应用[J].计算机科学与探索,2010,4(3):283-288. CHEN Zehua, XIE Gang, XIE Qun, et al. BGRM and its application in knowledge reduction[J]. Journal of Frontiers of Computer Science and Technology, 2010, 4(3):283-288.
[24] 王国胤.Rough集理论与知识获取[M].西安:西安交通大学出版社,2001. WANG Guoyin.Rough Set Theory and knowledge Acquisition[M].Xi’an:Xi’an Jiao tong University Press,2001.
[25] 张清华,王国胤,刘显全.基于最大粒的规则获取算法[J].模式识别与人工智能,2012,25(3):388-396. ZHANG Qinghua, WANG Guoyin, LIU Xianquan. Rule acquisition algorithm based on maximal granular [J]. Pattern recognition and artificial intelligence, 2012, 25(3):388-396.

胡帅鹏(1989-),男,河南平顶山人,硕士研究生,主要研究领域为粗糙集, 粒计算等。E-mail: hushpe@163.com.

张清华(1974-),男,重庆市人,教授,博士,主要研究领域为粗糙集,粒计算等。主持国家自然基金1项等。

姚龙洋(1989-),男,河南洛阳人,硕士研究生,主要研究领域为粗糙集,粒计算等。
(编辑:张 诚)
An algorithm for rule extraction based on changing granularity
HU Shuaipeng1, ZHANG Qinghua1,2, YAO Longyang1
(1.Chongqing Key Laboratory of Computational Intelligence, Chongqing University of Posts and Telecommunications, Chongqing 400065, P.R. China;2.School of Science, Chongqing University of Posts and Telecommunications, Chongqing 400065, P.R. China)
The attribute reduction and value reduction are two important parts of knowledge acquisition in rough set. Generally, the method of knowledge acquisition is based on rule extraction of attribute reduction. But in the actual application, attribute reduction simplifies the information system and improves rule extraction’s efficiency. At the same time, some important condition attributes may be discarded. So it has the direct result that the numbers and simplification of rules are not necessarily good. Therefore, in this paper, an algorithm based on changing granularity is presented, and with this method we can obtain rules step by step when the granularity is changed from coarse to fine. The rules can extracted from the original information system. Compared with the results after attribute reduction, the numbers and simplification of rules are better. Theoretical analysis and experimental result show that the algorithm of this paper is feasible. Finally, experimental results show that the new algorithm is not only accurate but also efficient.
rough set; attribute reduction; rule extraction; multi-granularity
10.3979/j.issn.1673-825X.2016.06.018
2014-12-24
2016-06-11
胡帅鹏 hushpe@163.com
国家自然科学基金项目(61472056,61309014);重庆邮电大学科研训练计划项目(A2014-45)
Foundation Items:The National Science Foundation of China(61472056,61309014);The Research Training Program of Chongqing University of Posts and Telecommunications (A2014-45)
TP181
A
1673-825X(2016)06-0856-07
