基于MSVR和Arousal-Valence情感模型的表情识别研究
2017-01-03黄文波金裕成顾西存
杨 勇,黄文波,金裕成,顾西存
(1. 重庆邮电大学 计算智能重庆市重点实验室,重庆400065;2.韩国仁荷大学 情报通信工学部,仁川402-751; 3. 重庆邮电大学 图形图像与多媒体实验室,重庆 400065)

基于MSVR和Arousal-Valence情感模型的表情识别研究
杨 勇1,2,黄文波1,金裕成2,顾西存3
(1. 重庆邮电大学 计算智能重庆市重点实验室,重庆400065;2.韩国仁荷大学 情报通信工学部,仁川402-751; 3. 重庆邮电大学 图形图像与多媒体实验室,重庆 400065)
通常的表情识别方法是对基本情绪进行表情分类,然而基本情绪对情感的表达能力有限。为了丰富情感的表达,研究采用Arousal-Valence情感模型,从心理学的角度对Arousal-Valence模型中Arousal维度和Valence维度之间的相关性进行了分析,并用统计学方法对AVEC2013,NVIE和Recola 3个数据集进行研究,实验结果表明它们之间具有正相关关系。为了利用Arousal-Valence之间的相关性,采用多输出支持向量回归(multiple dimensional output support vector regression,MSVR)算法作为表情的训练和预测算法,并结合特征融合和决策融合提出了一种基于MSVR的两层融合表情识别方法。实验结果表明提出的表情识别方法比传统的方法能取得更好的识别效果。
表情识别;Arousal-Valence情感维度;相关性;多输出支持向量回归(MSVR)
0 引 言
随着人工智能的发展,在人机交互中,人们越来越希望计算机能够理解人类的情感。表情作为人类情感表达的主要方式早已被证实对情感的表达具有55%的贡献率[1]。近年来,表情识别已在人机交互、驾驶员疲劳检测、医院病人看护等方面得到了很大的发展。
在表情识别研究领域,通常采用Ekman的基本情绪理论[2],该情绪理论把情感分为6种基本类型,即高兴、厌恶、吃惊、悲伤、生气和恐惧。因此,基于该理论的表情识别从本质上说是分类问题。但是基本情绪理论在表情识别中有一定的局限性,主要表现在:①对情感的表达能力有限,对基本表情之外的其他表情不能有效地表达;②不能表达不同情感之间的关系;③不能表达出情感的强度。比如高兴可以分为一般高兴、中等高兴、特别高兴,基本情绪理论不能表达出表情的这种强弱关系。
鉴于基于基本情绪理论的情感分类具有以上缺点,近年来国外很多情感计算领域的研究者开始尝试采用基于维度的情感模型来研究情感[3]。维度理论采用多维空间,从激励、愉悦等不同的角度来描述情感,常见的情感模型有Mehrabian提出的PAD(pleasure, arousal, dominance)情感模型[4]、Cowie提出的EAP(evaluation, activity, power)情感模型[5]、 Russell提出的A-V(arousal, valence)情感模型[6]等。在众多情感模型中,由于Arousal和Valence维度最能体现出人的情感变化[7],广泛地被情感计算领域的学者所采用。所以,本文基于Russell的A-V情感模型对表情识别进行了研究,图1是该情感模型的一个简单示意图。
从图1可以看到,不同的情感分布在空间中的不同位置,位置越接近的情感表明它们代表的情绪越接近。在A-V情感空间中,Arousal代表的是激活度(activation),Valence代表的是愉悦度(pleasantness)。通常二者的取值是[-1,1]。
对A-V空间上的表情识别研究,通常的方法都是把Arousal和Valence维度分开,采用回归的方法单独识别,显然这些传统的方式没有利用到2个输出维度之间的关系。鉴于此,本文从Arousal维度和Valence维度之间的关系入手,研究了利用A-V之间的相关关系进行表情识别。本文的主要贡献有:①研究并发现了Arousal和Valence两个维度之间具有正相关的相关关系;②利用A-V之间正相关的关系,结合特征融合和决策融合提出了一种基于多输出支持向量回归(multiple dimensional output support vector regression, MSVR)的两层融合表情识别方法。

图1 Arousal-Valence情感空间Fig.1 Arousal-Valence emotion space
1 Arousal和Valence之间的相关性
在从情感计算的角度研究情感维度之间相关性的研究中,Pantic教授团队从五维(valence, arousal, power, expectation, intensity)情感空间中任选四维预测另一维时取得了不错的实验效果,他们的研究表明了各情感维度之间是相互关联的[8]。Cristian等[9]在用生理信号脑电图(electroencephalogram, EEG)、眼动电图(electrooculogram, EOG)和(electromyogram, EMG)研究情感时尝试了利用Arousal和Valence维度之间的相关性,取得了不错的效果,他们的研究表明了利用Arousal和Valence之间的相关性能取得更好的效果。然而,以上研究仅表明A-V之间存在相关性,并没有对二者的相关性进行深入的分析。Kuppens[10]等人总结并分析了几种常见的A-V相关性模型,指出了A-V之间的相关性存在个体差异性。Sánchez-Lozano[11]等人在特定数据集上通过实验计算出A-V之间的皮尔逊相关系数为0.25。
心理学研究结果表明人对Arousal和Valence维度的响应是由大脑中的不同组织部位控制的[7,12]。大脑中的眼窝前额皮质(orbitofrontal cortex)和亚属皮质(subgenual cortex)主要负责响应Valence维度;大脑中的岛叶(insula)、基底神经节(basal ganglia)和杏仁核(amygdala)主要负责响应Arousal维度。并且,这些大脑组织对Arousal和Valence的响应都有一定的独立性。但是大脑中有些部位则会对Arousal和Valence都产生响应,比如扣带回膝上部(subgenual cingulate)。这些能同时响应Arousal和Valence维度的脑部位表明了A-V之间是相互联系的。Lewis等[12]在用机能性磁共振成像技术研究大脑不同部位对Arousal和Valence的响应时发现当大脑中的扣带回膝上部对Valence维度的响应变强烈时,其对Valence维度的响应程度也会相应的加强。以上心理学研究结果表明:A-V之间存在一定的相关性,而且表现为正相关。
为了从情感计算的角度验证上述心理学研究结果,本文从统计学上的皮尔逊相关系数入手对Arousal和Valence之间的相关性进行了研究。皮尔逊相关系数(COR)的定义为
(1)
(1)式中:cov表示2个变量的协方差;σx,σy分别为x,y的标准差;COR表示2个变量的相关性,其取值为[-1,+1],若其绝对值越接近1,表示2个变量之间的相关性越强;若越接近0,表示两者的相关性越弱;若为0表示则两者不相关。相关系数若为正,说明一个变量随另一个变量增减而增减,即变化方向相同;若为负,表示一个变量增加另一个变量减少,即变化方向相反。
本研究从2013年音频/视觉情感挑战赛(audio/visual emotion challenge, AVEC2013)提供的数据集上选取1 100张表情图片,从远程协作情感交互(remote collaborative and affective interactions, RECOLA)数据集上选取840张表情图片,从中科大自然可见与红外面部表情(natural visible and infrared facial expression, NVIE)数据集上选取1 278张表情图片进行实验。对应地,每一张图片都有一对A-V标签。最后,通过计算3个数据集的Arousal和Valence之间的皮尔逊相关系数得出了如表1所示的结果。

表1 3个数据集上A-V之间的相关系数
从表1中的结果可以看到,3个不同数据集中A-V之间的相关系数都为正,即都表现为正相关的相关关系。由此,本文从情感计算的角度,采用统计学的方法,得出A-V 2个维度之间存在正相关的相关关系。并且这一结论和心理学的研究结果相互吻合。除此之外,从表1中可以看到,不同数据集之间的A-V相关性大小不一致,AVEC2013和RECOLA上的正相关性强度较大,而NVIE上的正相关性强度则较小。这主要是由于NVIE数据集的A-V标签是通过视觉模态标定的,而AVEC2013和RECOLA数据集的A-V标签标定时用到了视觉模态和听觉模态。标定时用到的模态越多,标定的准确性就会越高。此外,不同的心理学家对A-V维度的标定方法存在不一致性,不同的人对Arousal和Valence的标定也存在一定的主观性。
2 基于MSVR的表情识别
2.1 本文提出的表情识别框架
采用A-V情感模型进行表情识别,由于A、V 2个维度不再是一个具体的分类标签,而是连续值,因此,表情识别不再是模式分类的问题,而是一个具有多输出的回归问题。本文结合特征融合和决策融合提出的基于多输出支持向量回归的两层融合表情识别方法框架如图2所示。
在表情识别中,首先需要从图片中检测人脸区域。对于人脸区域的特征提取,采用了表情识别领域最常用的3种特征,即局部二值模式(local binary pattern, LBP),Gabor小波滤波和局部相位变换(local phase quantization,LPQ)。
为了提高表情识别的效果,本文对LBP,Gabor,LPQ 3种基本特征进行了两两组合的串行特征融合。假设样本空间Ω中存在样本ξ∈Ω,其对应有2组特征数据α∈A和β∈B。那么对应的串行组合特征γ描述如下
γ=(α,β)T
(2)
若特征向量α为m维,β为n维,则串行组合特征γ的维数为m+n维。
在多输出回归的研究中,通常采用的方法是对每一个输出维度单独训练和预测。比如,大部分的研究采用的回归方法都是支持向量回归(support vector regression, SVR),它是SVM(support vector machine)在回归领域的应用,其基本思想是将低维空间中的非线性数据通过映射转换到高维空间中的线性数据,然后在高维空间中对数据进行分类或回归处理[13]。但是传统SVR的输出只有一个维度,在处理多维输出的问题时,通常是将它转化为多个一维输出的问题来处理,即对每一个输出维度用SVR单独训练和预测。显然,对于A-V情感空间中的回归,如果采用上述的SVR就不能有效地利用Arousal维度和Valence维度之间的相关关系。
为了充分利用输出维度之间的关系,本文在表情识别领域首次采用MSVR作为回归器。
同时,为了充分利用特征融合后的3种串行特征,本文在第1层特征融合的基础上增加了决策融合作为第2层融合。具体地,先用MSVR对3种串行特征组合进行训练和预测并得到3组Arousal和Valence的值,最后通过取平均值的融合方式来得到最终的Arousal和Valence值。

图2 基于MSVR的两层融合表情识别框架图Fig.2 Framework of the two-level fusion for facial emotion recognition based on MSVR
2.2 MSVR简介
为了解决多输出回归的问题,Pérez-Cruz等[14-15]提出了MSVR。MSVR的核心思想是通过修改原始SVR的损失函数使之能考虑到各输出分量的误差。这样,MSVR在训练回归器时就能同时考虑到不同维度之间的关系。因此,从理论上讲它要优于将多个输出维度分离开来单纯处理的方法。
MSVR用定义在超球上的损失函数代替了SVR定义在超立方体上的损失函数。设样本集D={(xi,yi)|i=1,2,…,l},xi∈Rd,yi∈Rm,构造回归函数
f(x)=φ(xi)TW+B
(3)
(3)式中:φ(x)为映射函数,将低维空间中的非线性特征数据xi转化为高维空间中的线性数据;W和B分别为权向量和偏置,W=[w1,…,wm]T,B=[b1,…,bm]T。因此,(3)式可以转化为(4)式的约束优化问题
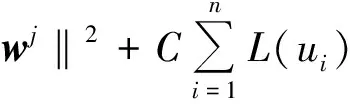
(4)
s.t. ‖yi-φ(xi)Twj+bj‖≤ε+ui,i=1,…,n

(5)
由(5)式可知,当ε=0,该问题退化为对每一个输出分量yi做最小二乘回归;当ε≠0时,在求解每一个输出函数的回归量时会同时兼顾到其他输出分量的拟合效果,所以,这样得到的解将会是一个整体拟合最优的解。
根据目标函数及约束条件,可以得到(6)式的拉格朗日函数
(6)
在函数的极值点,对于变量wj,bj,ui,αi,其偏导数为0,于是可得
(7)
(7)式中:φ=[φ(x1),…,φ(xn)]T;Dα=diag{α1,α2,…,αn};α=[α1,α2,…,αn]T;I表示单位矩阵;1=(1,1,…,1)T。
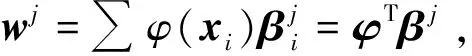
(8)
(8)式中:(K)ij=κ(xi,xj)。若求出βj,则对于每个x可得yj=φT(xi)φ(xj)βj,定义β=[β1,β2,…,βm],则m个输出可表示为
y=φT(x)φ(x)β=Kxβ
(9)
对于βj的求解,可采用迭代的方法,具体步骤如下[15-16]
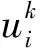



可以看到,MSVR求解(4)式时采用的是迭代求解的方法,且在求解的过程中还用到了回溯法来求步长,这样必然会增加循环的次数,从而在一定程度上增加了时间开销。
3 实 验
3.1 实验设置
人脸检测采用OpenCV自带的Haar特征分类器实现。图像的预处理统一采用文献[17]中提供的裁剪方法。裁剪后统一所有的图片尺寸为120×120,并进行直方图均衡化。预处理完成后对所有图片进行3×3分块处理,把图片划分为9个不重叠的子块,然后对每个子块求其LBP,Gabor,LPQ特征,最后把每个子块的特征级联在一起。
为了降低特征空间的维数,所有特征提取完后都通过主成分分析(principal components analysis, PCA)进行了特征降维,降维时PCA主成分贡献率统一设置为0.96。最后,再用通过PCA降维后的LBP,Gabor,LPQ特征进行特征融合。
实验中,本文采用了AVEC2013数据集、RECOLA数据集和中科大NVIE数据集。
AVEC2013数据集[18]是一个基于视频的表情数据集。该数据集的公开部分包含训练和验证2个部分共100个视频,本研究选用了其中的11个视频,并在每个视频中抽 取了100张表情图片(共1 100张表情图片)进行实验。
RECOLA数据集[19]也是一个基于视频的多模情感数据集,该数据集包含了从27个志愿者中采集到的34个视频。本研究选用了其中的11个视频,并从中抽取了共840张表情图片作为实验。
中科大NVIE[20]数据集包括自发表情库和人为表情库,本实验采用其中的自发表情库。自发表情库是通过特定视频诱发并在3种光照下(正面、左侧、右侧光照)采集的表情库,其中正面光照103人,左侧光照99人,右侧光照103人。每种光照下,每人有6种表情(喜悦、愤怒、哀 伤、恐惧、厌恶、惊奇)中的3种以上,每种表情的平静帧以及最大帧都已挑出。本文一共选用了3种光照条件下的共1 278张图片作为实验。
3.2 实验评价方式
对于回归结果的评价方式,本文采用了该领域最为常用的3种评价方式,即:相关系数(correlation coefficient, COR)、均方根误差(root mean squared error, RMSE)和平均绝对误差(mean absolute error, MAE)。COR的定义在(1)式中已经给出。
设有两个n维向量X,Y,则它们之间的RMSE和MAE分别定义为
(10)
(11)
在上述3个评估方式中,COR表示的是预测的值和标定的值之间的相关性,COR越大表示回归的效果越好;RMSE描述的是预测值和标定值之间的均方差误差,误差的值越小表示预测值与标定值之间越接近;MAE描述的是预测值和标定值之间的绝对值误差,值越小表示误差越小。
在计算实验结果时,本文采用了十折交叉验证的方式,通过计算十折的平均COR,RMSE,MAE作为最后的实验结果。
3.3 实验与结果分析
3.3.1 实验1(不同回归方法的对比实验)
为了验证MSVR多输出回归算法在表情识别上的有效性,本实验在回归时采用了基于维度的表情识别中最常用的单输出回归算法SVR和相关向量机(relevance vector machine, RVM)作为对比。本实验分别在LBP,Gabor,LPQ 3种特征上进行了对比实验。实验结果如表2、表3和表4所示。同时,为了对比MSVR的计算开销,本文统计了3个回归算法在NVIE数据集上进行十折交叉验证的平均训练时间和对测试集中127张表情图片进行预测的平均时间,统计结果如表5所示。
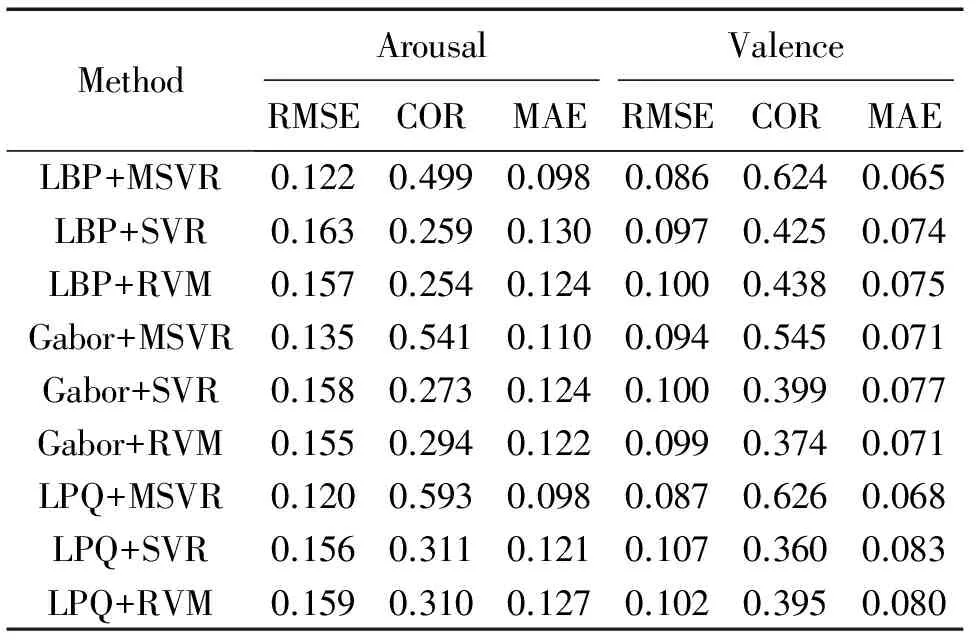
表2 AVEC2013数据集上不同特征和回归算法组合时的实验结果
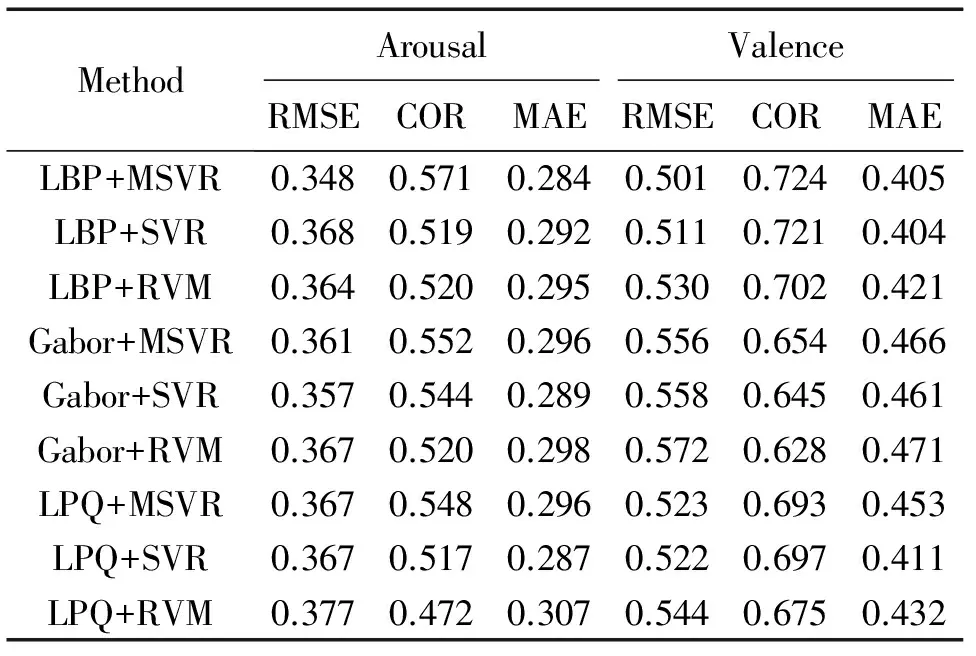
表3 NVIE数据集上不同特征和回归算法组合时的实验结果
表4 RECOLA数据集上不同特征和回归算法组合时的实验结果
Tab.4 Experimental results on RECOLA dataset using different features and regression methods
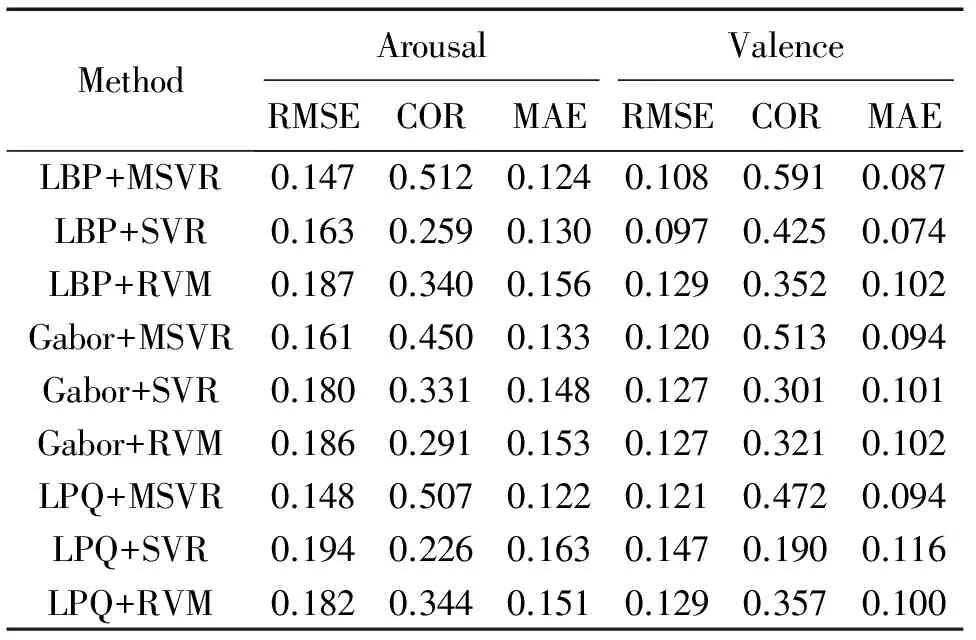
MethodArousalValenceRMSECORMAERMSECORMAELBP+MSVR0.1470.5120.1240.1080.5910.087LBP+SVR0.1630.2590.1300.0970.4250.074LBP+RVM0.1870.3400.1560.1290.3520.102Gabor+MSVR0.1610.4500.1330.1200.5130.094Gabor+SVR0.1800.3310.1480.1270.3010.101Gabor+RVM0.1860.2910.1530.1270.3210.102LPQ+MSVR0.1480.5070.1220.1210.4720.094LPQ+SVR0.1940.2260.1630.1470.1900.116LPQ+RVM0.1820.3440.1510.1290.3570.100
从表2-表4可以看到,对于同一种特征,MSVR总能取得比SVR和RVM更好的实验结果。此外,在NVIE和RECOLA数据集上,3种特征中LBP特征的实验效果最好。但对于AVEC2013数据集,LPQ特征在Arousal维度上能取得比LBP更好的效果。可见特征的提取对数据集也有一定的依赖性。由表5可以看到,3种回归算法中,SVR的训练时间最短,RVM的训练时间最长。对于预测,MSVR和SVR的时间都低于2 ms,能较好地满足实际应用的实时性要求。
进一步分析MSVR在3个数据集上的实验结果可以发现,当数据集的Arousal和Valence标签之间的皮尔逊相关系数越高时,使用MSVR能取得越好的实验效果。由表1可知,AVEC2013数据上Arousal和Valence之间的相关系数是0.459,比NVIE数据集的0.147高0.312。从实验结果看,对于评价方式COR,使用MSVR后,AVEC2013数据集在Arousal和Valence 2个维度上都比SVR和RVM平均提升了0.2左右,而对于NVIE数据集,MSVR对比于SVR和RVM却只提升了不到0.1。由此可以得出结论:当数据集上A-V之间的相关性越高时,使用MSVR能取得更显著的效果。
表5 NVIE数据集上3种回归算法的平均训练时间和预测一张图片的平均时间
Tab.5 Average training time on NVIE and average predicting time of one image by three regression methods
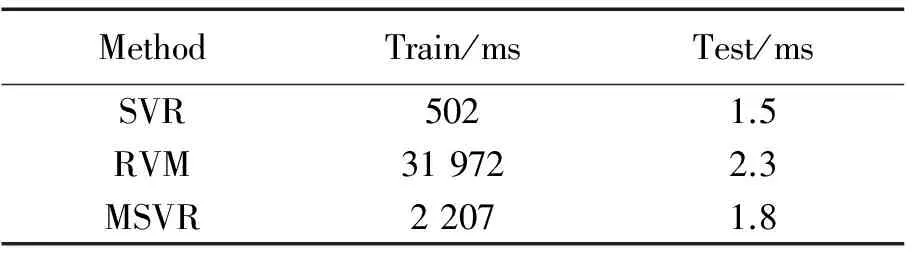
MethodTrain/msTest/msSVR5021.5RVM319722.3MSVR22071.8
3.3.2 实验2(提出的方法与传统基于特征融合方法的对比)
为了验证如图2所提出的基于两层融合的表情识别方法的可行性,该方法与传统的基于特征融合的方法进行了对比。对提取到的LBP,Gabor,LPQ特征,在对比实验室中,分别把它们融合为LBP+Gabor,LBP+LPQ,LPQ+Gabor,LBP+LPQ+Gabor 4种特征作为对比对象,在回归时统一采用基于多输出回归的MSVR算法。实验2的结果如图3-图5所示。

图3 3个数据集上特征融合和决策融合的COR实验结果Fig.3 COR experimental results on three datasets using feature fusion and decision fusion
从实验1和实验2的对比中可以看到,当采用MSVR作为回归算法时,2种特征融合后能取得比单特征更好的实验效果。比如把LBP和Gabor特征融合后的实验效果比单独的LBP或Gabor特征所取得的实验效果要好。从实验2中的特征融合实验结果可以看到,当同时融合LBP,Gabor和LPQ 3种特征时,实验效果并没有得到明显的提升,甚至在某些评价指标上还有性能退化的表现。如在Recola数据上,采用LBP+Gabor+LPQ特征融合后的实验结果还没有仅融合LBP和LPQ的实验效果好。这主要是由于当融合的特征越来越多后,会产生特征数据的冗余,从而在训练时导致实验效果的退化。所以,从实验结果来看并不是融合的特征越多越好。鉴于此,本文在决策融合时只选用了LBP+Gabor,LBP+LPQ,LPQ+Gabor 3种融合特征。采用本文所提出的基于MSVR的特征融合加决策融合的方法后,RMSE,COR和MAE在3个数据集上较传统的特征融合方法都有了进一步的提升,特别是MAE。如,在AVEC2013数据集,使用本文的方法后,MAE在Arousal和Valence维度上都可以降低到0.01(见图5)。
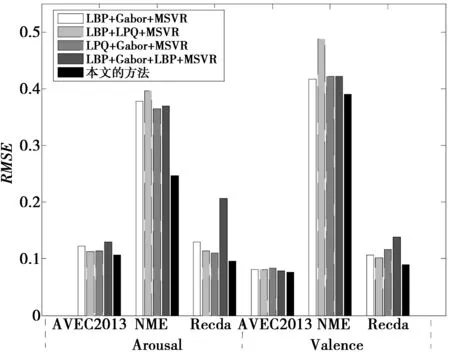
图4 3个数据集上特征融合和决策融合的RMSE实验结果Fig.4 RMSE experimental results on three datasets using feature fusion and decision fusion
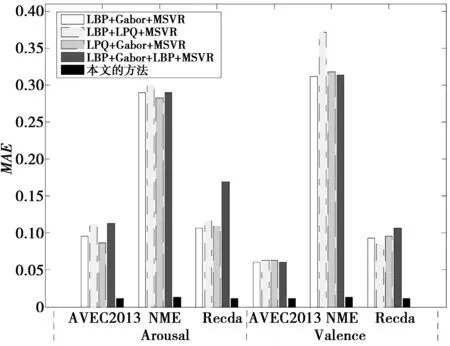
图5 3个数据集上特征融合和决策融合的MAE实验结果Fig.5 MAE experimental results on three datasets using feature fusion and decision fusion
由以上分析可知,本文提出的方法要优于只采用特征融合的方法,此外,本方法对MAE有非常显著的提升效果
同时为了验证本文所提出方法的时间开销,本文在NVIE数据集上统计了十折交叉验证的平均训练时间,并对127张测试集图片进行预测并计算平均测试时间,表6是时间开销的统计结果。从表6中可以看到,采用本文所提出的表情识别方法训练时间和预测时间均比其他方法要高,这主要是由于本文要训练3个回归器。预测时也要通过3个回归器进行预测。可以看到本方法预测一张图片表情的平均时间为6.8 ms,该时间能较好地满足实际应用场景。
表6 NVIE数据上不同融合方法的平均训练时间和预测一张图片的平均时间
Tab.6 Average training time on NVIE and average predicting time of one image by different fusion methods

MethodTrain/msTest/msLBP+Gabor+MSVR30152.5LBP+LPQ+MSVR29501.8LPQ+Gabor+MSVR30452.3LBP+Gabor+LPQ+MSVR44562.9本文方法90896.8
4 总结和展望
基于维度的表情识别目前在国内的研究很少,本研究采用了当前最为常见的Arousal-Valence二维连续情感模型。本文首先从心理学入手研究了A-V之间的相关性,并得出了A-V之间存在正相关的关系。为了利用A-V维度之间的相关性,本文在A-V情感空间上提出了基于MSVR的两层融合表情识别方法。在实验中采用了AVEC2013,NVIE和Recola 3个数据集。实验时,为了验证MSVR的实验效果,本文采用了单输出回归中最常使用的SVR和RVM作为对比的回归算法;同时,本方法还与传统的特征融合方法进行了对比。 实验结果表明,本文提出的方法能取得更好的实验效果,且预测表情的时间能满足实际应用场景。通过实验本文还发现了当输出维度之间的相关性越好时,使用MSVR能取得更好的实验效果。
表情识别的本质是模式识别,本文研究的发展在很大程度上依赖于机器学习的发展。MSVR只是众多机器学习算法中能利用Arousal和Valence维度之间相关性的一种算法,在未来的研究中还可以尝试探索其他能利用输出相关性的机器学习算法。
[1] MEHRABIAN A. Communication without words[J]. Psychology Today, 1968, 2(4): 53-56.
[2] EKMAN P, FRIESEN W V. Constants across cultures in the face and emotion[J]. Journal of Personality Social Psychology, 1971, 2(17): 124-129.
[3] GUNNES H, PANTIC M. Automatic, dimensional and continuous emotion recognition[J]. International Journal of Synthetic Emotions, 2010, 1(1): 68-99.
[4] MEHRABIAN A. Pleasure-Arousal-Dominance: a general framework for Describing and measuring individual differences in temperament [J]. Current Psychology, 1996, 14(4): 261-292.
[5] COWIE R, DOUGLAS C E. Emotion recognition in human-computer interaction[J]. IEEE Signal Process, 2001, 18(1): 32-80.
[6] RUSSEL J A.A circumplex model of affect[J].Journal of Personality & Social Psychology,1980,39(6):1161-1178.
[7] ANDERS S,LOTZE M,ERB M,et al.Brain activity underlying emotional valence and arousal:a response-related fMRI study[J].Human Brain Mapping,2004,23(4):200-209.
[8] MIHALIS A, NICOLAOU S Z, PANTIC M. Correlated-spaces regression for learning continuous emotion dimensions[C]//Proceedings of the 21st ACM international conference on Multimedia. Barcelona, Spain: ACM Press, 2013: 773-776.
[9] CRISTIAN A, MAURICIO A, A LVAREZ, et al. Mutiple-output support vector machine regression with feature selection for arousal/valence space emotion assessment[C]// Engineering in Medicine and Biology Society (EMBC), 36th Annual International Conference of the IEEE. Chicago, USA: IEEE Press, 2014: 970-973.
[10] KUPPENS P,TUERLINCKX F,RUSSELL J A,et al.The relation between valence and arousal in subjective experience[J].Psychological Bulletin,2013,139(4):917-940.
[11] SáNCHEZ L E, LOPEZ O P, DOCIO F L, et al. Audiovisual three-level fusion for continuous estimation of Russell’s emotion circumplex[C]//Proceedings of the 3rd ACM international workshop on Audio/visual emotion challenge. Barcelona, Spain: ACM Press, 2013: 31-40.
[12] LEWIS P A,CRITCHLEY H D,ROTSHTEIN P,et al.Neural correlates of processing valence and arousal in affective words[J].Cerebral Cortex,2007,17(3):742-748.
[13] VAPNIK V N. An overview of statistical learning theory[J]. IEEE Transactions on Neural Networks, 1999, 10(5): 988-999.
[14] PéREZ C F, CAMPS V G, SORIA E, et al. Multi-dimensional function approximation and regression estimation[C]//Proc. of the ICANN. Madrid, Spain: Springer Press, 2002: 757-762.
[15] SáNCHEZ F, CUMPLIDO M D. SVM multiregression for nonlinear channel estimation in multiple-input multiple-output systems[J]. IEEE Transactions on Signal Processing, 2004, 52(8): 2298-2307.
[16] 胡蓉. 多输出函数回归的SVM算法研究[D]. 广州:华南理工大学, 2005. HU Rong. Research on multi-dimensional regression of SVM[D]. Guangzhou: South China University of Technology, 2005.
[17] FRANK Y, CHAO F C. Automatic extraction of head and face boundaries and facial features[J]. Information Science, 2004, 158: 117-130.
[18] VALSTAR M, SCHULLER B, SMITH K. 2013: the continuous audio/visual emotion and depression recognition challenge[C]// Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge. Barcelona, Spain: ACM Press, 2013: 3-10.
[19] FABIEN R, ANDREAS S, JUERGEN S, et al. Introducing the RECOLA multimodal corpus of collaborative and affective interactions[C]//10th IEEE Int'l conf. and workshops on automatic face and gesture recognition. Shanghai, CN: IEEE Press, 2013: 1-8.
[20] WANG Shangfei, LIU Zhilei, LV Siliang, et al. A Natural Visible and Infrared Facial Expression Database for Expression Recognition and Emotion Inference[J]. IEEE Transactions on Multimedia, 2010, 12(7): 682-691.

杨 勇(1976-):男,云南大理人,副教授,博士,硕士生导师。主要研究方向为人工智能与模式识别、情感计算、数据挖掘等。E-mail:yangyong@cqupt.edu.cn。

黄文波(1989-):男,四川自贡人,硕士研究生,主要研究方向为图像处理与模式识别。E-mail:schwbo@163.com。

金裕成(1963-),男,韩国仁川人,韩国仁荷大学博士生导师,主要研究方向为多媒体数据挖掘,大数据,智能视频监控等。E-mail:yskim@inha.ac.kr。
(编辑:张 诚)
Facial expression recognition method based on MSVR and Arousal-Valence emotion model
YANG Yong1,2, HUANG Wenbo1,KIM Yoosung2,GU Xicun3
(1. Chongqing Key Laboratory of Computational and Intelligence, Chongqing University of Posts and Telecommunications,Chongqing 400065, P.R. China; 2. Department of Information and Communication Engineering, Inha University, Incheon 402-751, Korea; 3. Laboratory of Graphics Image and Multimedia, Chongqing University of Posts and Telecommunications, Chongqing 400065, P.R. China)
The most commonly used facial emotion recognition method is classitying basic emotions. However, the basic emotion theory has a limited leval of ability to express emotion. To enrich emotion expression, the arousal-valence continuous emotion space model is adopted in this paper. Firstly, the correlation between arousal and valence is discussed from the perspective of psychology and researched based on the statistics. The experimental results on AVEC2013, NVIE and Recola datasets indicate the correlation is positive. Then, in order to use the correlation between arousal and valence, MSVR(multiple dimensional output support vector regression) is adopted to train and predict facial emotion, and a new facial emotion recognition method based on MSVR and two-level fusion is proposed, which combines feature fusion and decision fusion.The contrast experimental results show that the proposed method can get better recognition result than the traditional methods.
facial expression recognition; arousal-valence emotion dimensions; correlation; multiple dimensional output support vector regression(MSVR)
10.3979/j.issn.1673-825X.2016.06.015
2015-12-10
2016-06-10
杨 勇 yangyong@cqupt.edu.cn
韩国科学与信息科技未来规划部2013年ICT研发项目(10039149);重庆市自然科学基金项目(CSTC,2007BB2445);2015年重庆市研究生科研创新项目(CYS15174)
Foundation Items:The MSIP Ministry of Science, ICT & Future Planning(MSIP) of Korea in the ICT R&D Program 2013(10039149); The Natural Science Foundation Project of CQ(CSTC, 2007BB2445); The Graduate Research and Innovation Project of CQ(CYS15174)
TP181
A
1673-825X(2016)06-0836-08
