一种自主星图识别算法
2016-12-29贾蒙杨
贾蒙杨
(中国空间技术研究院通信卫星事业部,北京 100094)
一种自主星图识别算法
贾蒙杨
(中国空间技术研究院通信卫星事业部,北京 100094)
为了改善星敏感器系统的星图识别实时性和可靠性,文章在研究现有的星图识别相关技术基础后,提出了基于特征向量投影法的算法核心,并在这一核心的基础上完成了星图识别算法和导航星图数据库的改进设计。最后编写仿真测试软件对此算法程序进行了性能测试,测试结果表明,文章提出的自主星图识别算法在星图识别实时性和可靠性方面都较以往算法有了提高。
星敏感器;星图识别;特征向量投影法
1 引言
星敏感器系统是实现航天器自主姿态控制的关键系统,它依靠自主星图识别技术实现对航天器姿态的实时自主监测。随着航天技术的不断发展,航天器的任务也随之越来越多样化,许多新的航天任务如空间交会对接、空间激光通信[1]等都对航天器进行姿态控制实时性提出了更高的要求。因此,在现有星敏感器系统的技术基础上,需要发展可靠性和运行效率更高的自主星图识别技术。
从地球或附近某一点向宇宙空间中任意方向看去,不论观察点如何移动或变换姿态,两颗任意恒星间的角距总是不变的,这就使得天球上的一对恒星具有了一定的特征性,自主星图识别技术就是利用这种特征性,设计星图识别算法程序和导航星数据库,事先对恒星图像的自主模式识别。经过近几十年的发展,星图识别算法和导航星图数据库都有了多种设计思路,用以满足不同的任务需求。
导航星库是利用特征性并根据星图识别算法的需求,从全天恒星中经过删选和优化设计而得到的一种星图数据库。在这个数据库中,恒星数量必须尽可能少,以保证导航星库不会过大,可以适应硬件容量并能支持算法快速高效运行。但恒星数量也不能过少,必须保证数据库对天球的均匀覆盖,并且还需满足相机任意视场中的恒星数量足够多这一要求。
目前对导航星图数据库的设计方法,国内外都有研究。主要的研究方向是优化数据结构,缩减数据库容量等,如自组织导航星选择方法[2]、二维精简索引法[3]、字符串制定法[4]等。下面简要介绍2种通用性较高的基础性设计。
(1)星等加权方法[5]是基于恒星越亮被星敏感器捕获到的概率越大这一前提提出的。根据恒星的星等给每颗恒星赋予不同的权值。对低星等的恒星赋予较高的权值,使星等低的恒星被选作导航星的概率较大。在挑选导航星时,先从标准星表中选出有可能成为导航星的恒星构成候选导航星表,然后按星等大小由低到高依次将导航星按其原有的位置信息追加到导航星表中。但在实际使用中,由于空间相机视场范围有限,而整个星库的加权值又是固定的,很可能在一个视场图像中不能获取足够数量的导航星,导致匹配识别失败,而在下一视场中恒星数量过多,又会导致运算量过大失去实时性,简而言之,用该方法设计的数据库无法兼顾覆盖率和实时性,用途受限。
(2)回归选取方法[5]将传统星等阈值过滤算法中的静态阈值用动态星等阈值代替。结果表明,用该方法所选取的导航星表导航星数量少、分布均匀性好,同时还能适应多种任务的导航星选取要求,具有较强的通用性。但这种方法本身比较复杂,所需的参数较多,且对参数选择的敏感性较大,不容易得到最优结果,使导航星库设计难度较大。
以上2种思路都是基于对恒星的数量进行筛选达到优化数据库容量的目的,但是对恒星数量做出过多删减,会影响恒星数据的覆盖性。因此如何最大化地兼顾导航星图数据库的容量和覆盖性,是本文研究工作的目标之一。
星图识别算法的工作原理是,通过相机视场中的数颗恒星所具有的模式唯一的特征来匹配星图数据库中的恒星特征,继而解算出相机当前指向和姿态。目前比较通用的星图识别算法是三角形匹配算法[6]及其改进算法[7-8]。
三角形匹配算法的基本原理是,利用恒星对角距的特征性,在导航星库中匹配同一视场下3颗恒星组成的三角形的角距。星三角形的角距特性应该是模式唯一的[6],导航星库中有唯一的对应星三角形,根据这个对应关系就可判定相机的观测姿态和指向。三角形匹配算法的缺点是运算量较大且特征维数只有一维,在测量误差较大时,冗余匹配导致星图识别成功率迅速降低[9-11]。
针对上述缺陷,参考文献中提出了一种增加特征维度的改进算法[11],该算法将恒星亮度作为第二个特征加入了匹配算法。在算法运行过程中先匹配亮度再匹配角距,此法对运算量没有明显的增加。但这种方法局限性很大,因为根据现有相机的成像能力,无法对恒星进行准确的亮度计量,误差一般会达到0.5星亮度左右,造成新的冗余匹配,降低了匹配结果的可靠性。此外,三角形算法的运算量较大,影响了星图识别的实时性。
另一种改进思路是提高三角形匹配的效率。在三角形匹配的过程中原本是对星对角距的比对,一个星三角形至少需要比对3个数值才能完成匹配。作为改进,T算法[9]构造了一个特征量T=b+k×ln(a+ca),其中a,b,c为三角形的三边长,k为常系数。T值具有旋转、平移不变性。这样,匹配一个三角形只需要比对一个数值T,大大提高了匹配速度。未来如能进一步建立索引进行快速T值搜索,这种算法的效率就会更高。此算法要求星图数据库中也有对应的星三角形T值,因此这种算法需要与星图数据库并行设计。此外,T算法虽然精简了运算量,但在实际应用中存在测量误差的情况下,其可靠性并不能保证,需要做进一步优化。
以上两种思路,分别从提高识别可靠性和识别速度的角度出发,对三角形算法做了一定的改进。然而在未来多样化的航天任务中,可能需要一种兼顾速度和可靠性的新算法,这也是本文研究工作的目标之一。
2 星图识别程序的改进思路
以工作在地球同步轨道的星敏感器为应用平台,本章尝试设计出一套适用的星图识别程序。以现有的三角形星图匹配算法及其配套导航星图数据库为基础,使用一套核心优化算法对这两部分进行联合优化设计,达到同时提高星图匹配可靠性及匹配速度的目的。
在仿真验算和三个方法性能比较中,取星敏感器的识别范围为赤经0°~360°,赤纬-54°~54°,视场范围定为10°×10°。根据SAO标准星表,此范围内共记录恒星258 997颗。一般用于星敏感器的空间相机可以记录亮度在6.0星等以上的恒星,在此亮度范围内共有5103颗恒星。
在实际工程应用中,星图识别算法与星图数据库两者的关系是密不可分的,对于特定的一种星图识别算法,往往需要专门设计一种优化的星图数据库,以保证程序运行效率尽可能高。
本文在三角形匹配算法的基础上,使用一套基本算法思路,同时完成导航星图数据库和星图识别算法的改进设计,使程序的两部分运行在统一的核心算法下,达到速度、可靠性和硬件资源利用率的最大化优化。
2.1 导航星图数据库设计
导航星图数据库的主要设计目标是,使星图数据库达到覆盖率高、数据量小、模式唯一等3个指标。基于典型的航天器硬件环境以及星敏感器系统的任务场景,导航星图数据库应达到如下指标。
(1)覆盖率:任意观测姿态和视轴指向下,相机视场中的恒星数目不小于4颗的概率大于99%,不小于5颗的概率大于98%;
(2)数据量:星图数据库的总容量小于1 Mbyte;
(3)模式唯一性:在构建的所有导航三角形中,每个三角形的形态特征都可以用一组特征数据作唯一的表达。
为了寻求导航恒星三角形的形态特征,现对这5103颗恒星进行如下两步处理:①导航星三角形的选取;②特征星表构建。
2.1.1 导航星三角形的选取
为了缩减导航星数据库的规模,需要对星三角形的数量进行筛选。对于一个视场下的恒星,任选其中3颗组成三角形,可以得到这3颗恒星在天体坐标系下的单位方向矢量r1,r2,r3,其中|r1|=1,|r2|=1,|r3|=1,设r1r2夹角为α,r2r3夹角为β,r1r3夹角为γ,如图1所示,由r1,r2,r3所构建的平面三角形边长a、b、c为
(1)
对于参考星表中的5103颗恒星,分别以每颗恒星为主星m,以主星位置为视轴,在10°×10°的视场内提取恒星,被提取的恒星作为从星s,如图2所示,根据公式组1可以计算出主星与视场中任意从星的距离Dm-s,由于视场大小约束,主星与从星的最大夹角为5°,由于星敏感器焦面成像分辨率的限制,主星与从星的最小夹角设定为0.6°。这样计算出的主从星间距离将会很小,不方便后续计算,为此,将所求得距离乘以100(不影响后续恒星识别)。这样处理后,当主从星的夹角为0.6°时,Dm-s≈1.047;当主从星的夹角为5°时,Dm-s≈8.728。导航三角形的构造规则是:首先筛选出与主星距离Dm-s满足1≤Dm-s≤8.728的从星,然后将筛选出的从星到主星的距离排序,保留距离主星最近的四颗恒星(不够四颗恒星的全部保留)s1、s2、s3、s4分别与主星m构成导航三角形:m-s1-s2,m-s1-s3,m-s1-s4,m-s2-s3。剔除重复的三角形后,在全部目标天区一共构造出9803个导航三角形,且覆盖了所有5103颗恒星。

图1 恒星矢量示意图Fig.1 Vectors from observation point to target star
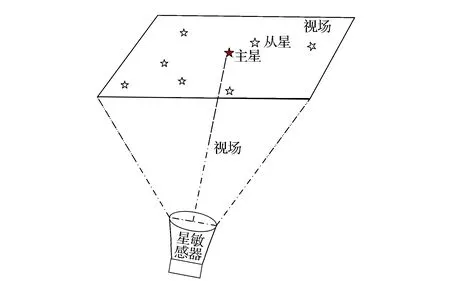
图2 恒星提取示意图Fig.2 Selection of master/slave stars
2.1.2 特征星表的构建
传统的平面三角形匹配法,是使用相机图像中的观测星三角形与星图数据库中的导航三角形进行边长比对,每个三角形需要比对三条边的边长,典型情况下,需要比对3~6次。典型的相机图像含有5~10颗恒星,按照上文的三角形构建法,将含有很多个观测三角形,比对次数则将达到数十次。如果能把每个观测三角形比对次数缩减为1次,那么匹配时间将大大缩短。为了达到这一目的,需对刚才构建的9803个导航三角形进行主成分分析。
对于2.1.1节中构建的导航三角形,取其中任意一个,可以用一个标志向量ti来唯一标识,ti=[aibici]T,其中ai,bi,ci为三角形的三边长,1≤i≤9803,所有导航三角形标志向量可构造矩阵M=[t1t2… tn],M为3×n矩阵,n=9803,对矩阵M进行主成分分析,步骤如下:
(2)构造零均值矩阵Q=[φ1φ2… φn],φi=ti-t,1≤i≤n,n=9803;
(3)计算协方差矩阵C=QQT的特征值,取最大特征值对应的特征向量umax,该向量代表矩阵M的主成分方向,本文称其为投影直线,记为L。
对于2.1.1节中构建的任意一个导航三角形标志向量,在投影直线上的特征投影值可用以表示为
(2)
式中:pi为第i个导航三角形标志向量在投影直线上的投影值,1≤i≤9803。
对于每一个导航三角形,它的标志向量在投影直线L上有唯一的投影值,将所有导航三角形的投影值按从小到大排序编号并建立索引,设定索引值为f。表1为特征星表中的一部分,其中f为索引值,p为标志向量的特征投影值,i1、i2、i3为星号,a、b、c为导航三角形三边长。

表1 特征值索引表(部分)

图3 特征向量空间分布图
Fig.3 Distribution of eigenvector
图3为2.1.2节中所构建的导航三角形标志向量ti的空间分布情况,红色直线为投影直线。图4为直角坐标系中特征投影值与索引值的对应关系示意,从图3,4可以看出,每一个导航三角形对应的标志向量在投影直线中都有且只有唯一的特征投影值与之对应。从表1可以看出,即使有的特征投影值很接近,但它们对应的索引值不同。由此满足了导航星库的模式唯一性要求。

图4 特征向量投影值平面分布
Fig.4 Distribution of eigenvalue
经过本节所述的数据处理,完成了特征向量投影法导航星库的构建,导航星库由两部分组成:第一部分是导航三角形及其特征投影值索引库,第二部分是全体导航三角形的主成分向量umax及其所在的投影直线L。由于经过2.1.1节导航三角形的筛选,限制了导航三角形的总数,由此达到了缩减数据库容量的目的,编程结果显示数据库容量为0.743Mbyte,符合预期指标。
2.2 星图识别算法设计
在星敏感器拍摄获得任一幅星图后,将根据所拍星图中的恒星来构建观测三角形,获取其标志向量的投影值,并与星图数据库中的特征投影值进行比对。
星图识别过程由两部分组成:第一部分是从星敏感器拍摄的星图中获取观测三角形向量投影值;第二部分是用求解的投影值与导航星库中的特征投影值比对,完成观测三角形的匹配识别。
2.2.1 求取观测三角形的投影值
星敏感器拍摄星图后,按照2.1.1节给出的方法,在图像内构建观测三角形。
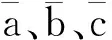
(3)
(4)
由此可以得到相机拍摄的观测三角形的特征投影值,简称为观测投影值。
2.2.2 匹配识别
(5)
3 算法程序性能测试
使用C++语言和openCV视觉运行库实现星图识别算法程序,并编写程序用以生成仿真相机图像。使用仿真图像模拟了相机在各种成像条件下拍摄的星图,并加入了一定的干扰。用10 000帧随机仿真图像作为输入,测试了本文特征向量投影(EPM)算法的星图识别成功率和识别速度,并引用了传统平面三角形匹配法和P向量算法(一种目前较先进的星图识别算法,使用了另一种三角形标志向量作为对比参数,并使用恒星星等数据作为第二个参考维度)的测试结果进行对比。
3.1 星图数据库覆盖性验证
图5是对导航星图数据库覆盖性的测试结果统计。可以看出,由于本文提出的数据库设计方法并未对恒星数量做出任何删减,所以恒星在全天区的覆盖性较好。在10 000帧随机图像中,含有7颗或以上恒星的概率为95%,含有5颗或以上恒星的概率为98.5%,含有4颗或以上恒星的概率为99.5%。

图5 单一视场恒星数量统计
Fig.5 Probability distribution of star’s contents in single-frame
3.2 视场中恒星个数对识别率的影响
如图6所示的恒星个数对识别率的影响曲线可以看出,在恒星数目较少的情况下,平面三角形算法的识别率高于本文算法和P向量算法,而本文算法识别算法明显优于P向量算法,当视场中恒星数目为5颗的时候,平面三角形算法识别率97.3%,本文算法识别率为87.2%,而P向量的识别率为68.1%;当视场中恒星数目为7的时候,平面三角形算法的识别率为99.2%,本文算法的识别率为95.3%,而P向量的识别率为90.6%;当恒星数目大于7颗的时候,本文算法和P向量算法识别率趋于100%,而平面三角形算法的识别率存在小幅度的跳跃,然后慢慢趋于100%。而一个视场中恒星数目大于7的概率为95%以上。在大多数情况下,本文算法的目标识别率与平面三角形算法和P向量算法十分接近,均趋近于100%。

图6 恒星个数对识别率的影响曲线Fig.6 Relationship between recognition rate and number of stars
3.3 恒星位置偏移对识别率的影响
随机产生10 000帧星图,分别为其加上随机方向0~2个像素的位置偏移,统计在不同的位置偏移情况下(统计视场内恒星个数为5颗以上的星图),这3种算法的识别率变化情况,图7为3种算法在不同位置偏移情况下识别率的比较曲线。从图中可以看出,在加入0~2个像素的位置偏移的过程中,3种算法识别率均呈现出下降趋势;具体从各个算法上分析,本文算法识别率从99.3%下降为96.7%,P向量算法识别率从98.9%下降为96.2%,平面三角形算法受位置偏移影响较大,识别率下降幅度最大,识别率从99.1%下降到94.1%。

图7 位置噪声对识别率影响曲线Fig.7 Location-bias’s effect on the recognition rate
3.4 星等误差对识别率的影响
对上述随机产生的10 000帧星图,分别为其加上0到0.5的星等误差,加上星等误差后的恒星星等小于0星等记为0星等,大于6星等记为6星等,统计在不同的星等误差情况下(统计视场内恒星个数为5颗以上的星图)这3种算法的识别率变化情况,图8为3种算法在不同星等下识别率的比较曲线,从图中可以看出,本文算法和平面三角形算法对于星等误差均不敏感,均能够保证高识别率,原因在于两种算法利用的都是导航星所构成三角形的形态特征来进行星图识别。
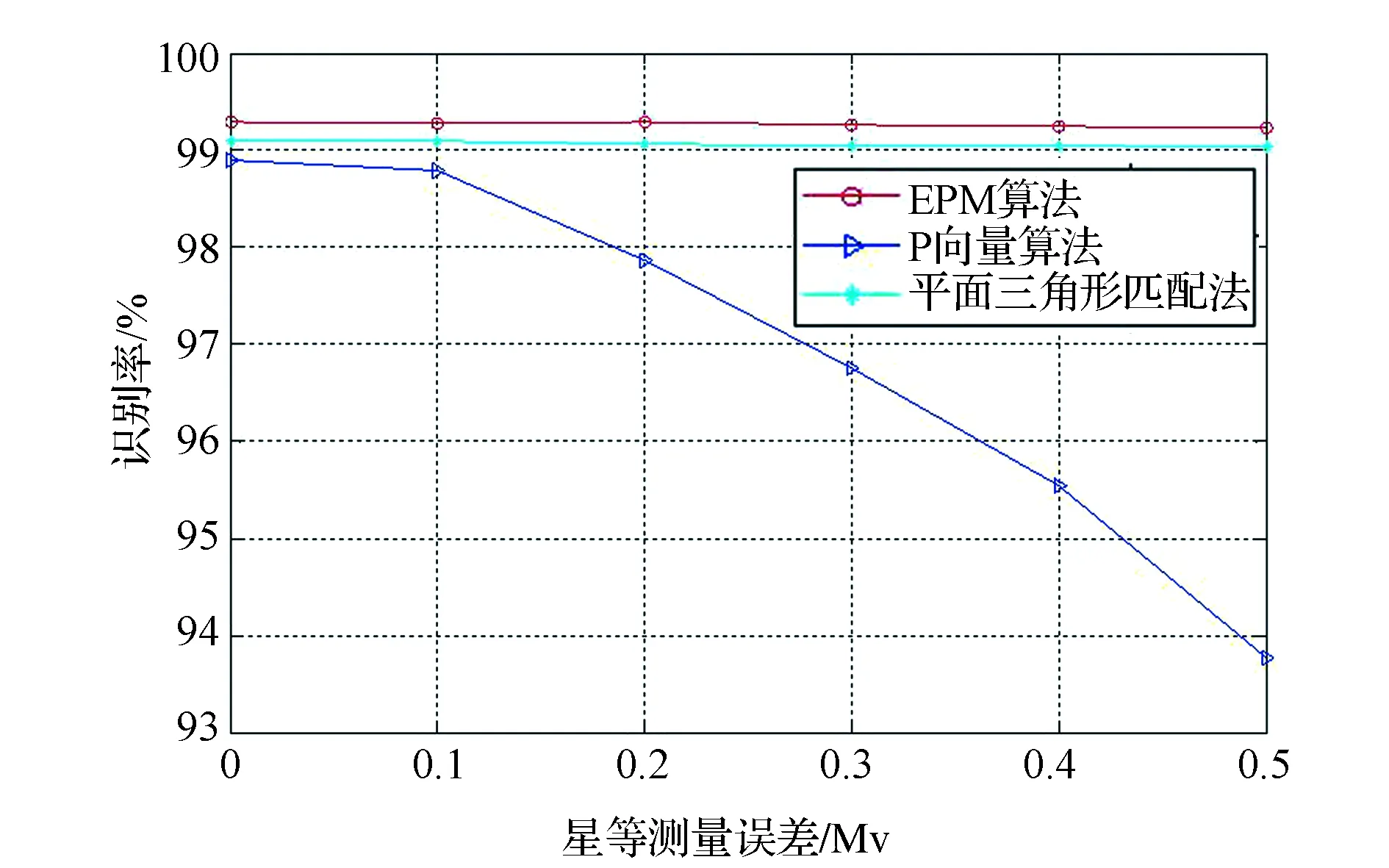
图8 星等测量误差对识别率影响曲线Fig.8 Recognition rate effected by star magnitude’s diviation
3.5 假星干扰对识别率的影响
对上述随机产生的10 000帧星图,对上述星图分别添加0~6个假目标,统计在不同的数目的假目标干扰下(统计视场内恒星个数为5颗以上的星图)这3种算法的识别率变化情况,图9为3种算法在不同数目的假目标影响下识别率的比较曲线。随着添加的假目标数目的增加,3种算法识别率均呈现出下降趋势,平面三角形算法的识别率下降最为明显,当假目标数目为0时,其识别率为99.1%;当假目标数目为1时,其识别率仅为56.8%,由此看出,在有假目标存在的情况下,平面三角形算法鲁棒性很差。在假目标数目从0增加到6颗时,本文算法识别率由99.3%下降为91.6%,P向量算法则从98.9%下降为82.7%,由此可见,在有假目标干扰的情况下,本文算法鲁棒性明显优于其他两种算法。

图9 假目标对识别率的影响曲线Fig.9 Recognition rate effected by fake target
3.6 平均识别时间
使用10 000帧随机星图对3种算法的识别速度进行测试,统计其总识别时间并计算每帧图像的平均识别时间。测试结果为:平面三角形算法平均识别时间为1.12 s,P算法7.63 ms,本文算法7.48 ms,本文算法识别速度最快。
3.7 综合指标对比
随机产生10 000帧星图,对上述星图分别添加2个随机位置假目标,统计3种算法的识别率和平均识别时间,如表2所示。
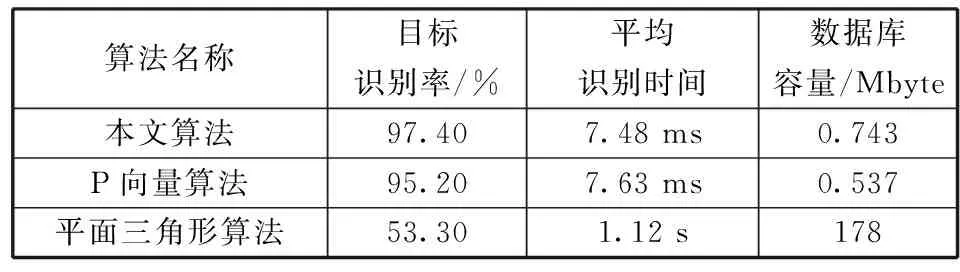
表2 综合测试结果汇总
本文算法的识别率97.4%,P向量的识别率为95.2%,平面三角形的识别率为53.3%。对于平面三角形算法,其星图数据库由于存储了每颗导航星所能组成的所有三角形数目,即使加入了视场约束条件,容量也达到178 Mbyte,远远大于前2种算法所需的存储空间,本文算法所需的存储空间比P向量算法的存储空间多38.3%,但是识别时间略短于P向量算法,本文算法实时性和可靠性较优。
4 结束语
本文通过一种基于特征向量投影法的设计方法,同时对平面三角形识别算法和导航星图数据库进行改进,设计了一种新的星图识别程序算法。经仿真测试验证:本文算法导航星库具有全天99.5%的覆盖率,且容量小于1 Mbyte;无噪声和干扰情况下,在95%的全天视场中识别率接近100%;在有位置噪声、星等噪声和假星干扰情况下,本文算法鲁棒性优于传统三角形匹配法和P向量算法;平均识别时间为3种算法中最短。此算法具有更高的匹配速度,在复杂干扰条件下有更好的抗干扰性能,且数据库容量小,达到了兼顾实时性、适用性和可靠性的设计目的。
References)
[1]谢木军,马佳光,傅承毓, 等. 空间光通信中的精密跟踪瞄准技术[J]. 光电工程,2000,27(1): 3
Xie Mu Jun, Ma Jia Guang, Fu Cheng Yu, et al. Precision tracking and pointing technologies in space optical communication[J]. Opto-Electronic Engineering, 2000,27(1),3 (in Chinese)
[2]Hye-Young K,Junkins J L.Self-organizing guide star selection algorithm for star tracker: thinning method[C]// IEEE on Aerospace Conference Proceedings. New York: IEEE, 2002
[3]郑万波,刘智,郝志航. 二维精简索引分层导航星库的构造[J]. 吉林大学学报(信息科学版),2003,21(2): 123-127
Zheng Wan Bo, Liu Zhi, Hao Zhi Hang. Construction of delaminating guide star data base with 2-D condensed index [J]. Journal of Jilin University (Information Science Edition), 2003, 21(2): 123-127 (in Chinese)
[4]许士文,李葆华,张迎春, 等.用字符匹配进行星图识别的导航库存储方法[J]. 哈尔滨工业大学学报, 2005,37(6): 819-821
Xu Shi Wen, Li Bao Hua, Zhang Ying Chun, et al. A storing navigation star database method for star map recognition using character match[J]. Journal of Harbin Institute of Technology, 2005, 37(6): 819-821 (in Chinese)
[5]郑胜,吴伟仁,田金文.一种新的导航星选取算法研究[J]. 宇航学报,2004,25(1): 35-40
Zheng Sheng, Wu Weiren, Tian Jinwen. A novel regression selection algorithm of guide star[J]. Journal of Astronautics,2004,25(1): 35-40 (in Chinese)
[6]刘朝山,马瑞平,肖称贵. 星图匹配制导中的关键技术[J]. 宇航学报,2006,27(1): 31-35
Liu Chaoshan, Ma Ruiping, Xiao Chenggui. Star pattern matching for celestial guidance[J]. Journal of Astronautics, 2006,27(1): 31-35 (in Chinese)
[7]C Padgett, Kreutz-Delgado, S Udomkesmalee. Evaluation of star identification techniques[J]. Journal of Guidance Control and Dynamics, 1997, 20(2): 259-267
[8]M S School. Star-field identification for autonomous attitude determination[J]. Journal of Guidance Control and Dynamics, 1997, 18(1): 61-65
[9]李立宏,林涛. 一种改进的全天自主三角形星图识别算法[J]. 光学技术,2000,26(4): 372-374
Li Lihong, Lin Tao. Improved all-sky autonomous triangle star-field identification algorithm [J]. Optics and Precision Engineering, 2000,26(4): 372-374 (in Chinese)
[10]郑胜,吴伟仁,田金文.一种新的全天自主几何结构星图识别算法[J]. 光电工程,2004,31(3): 4-7
Zheng Sheng, Wu Weiren, Tian Jinwen. A novel all-sky autonomous triangle-based star map recognition algorithm[J]. Opto-Electronic Engineering, 2004, 31(3): 4-7 (in Chinese)
[11]贺鹏程.一种改进的三角形识别算法[J]. 舰船电子工程,2012,32(4): 42-44,61
He Pengcheng. An improved triangle matching recognition algorithm[J]. Ship Electronic Engineering, 2012, 32(4): 42-44, 61 (in Chinese)
(编辑:张小琳)
An Algorithm for Autonomous Star Field Identification
JIA Mengyang
(Institute of Telecommunication Satellite, China Academy ofSpace Technology, Beijing 100094, China)
Researches on several existing star pattern recognition technologies are carried out in this article. To improve the efficiency and reliability of star sensor system, a new advanced star pattern match algorithm—based on the essential algorithm named Eigenvector Projection Method(EPM)—is designed, programmed, and tested in this article. This algorithm is designed to reduce data capacity of the star database and to improve the speed of processing. According to the test results, this new algorithm has successfully improved the efficiency and reliability of the star map recognition system.
star tracker;star pattern matching;EPM
2016-11-04;
2016-11-22
贾蒙杨,男,硕士,工程师,研究方向为图像处理。Email: kerr_1@126.com。
TP75
A
10.3969/j.issn.1673-8748.2016.06.016
