不平衡数据集上的Relief特征选择算法*
2016-12-23菅小艳韩素青崔彩霞
菅小艳 韩素青 崔彩霞
(太原师范学院计算机系,晋中,030619)
不平衡数据集上的Relief特征选择算法*
菅小艳 韩素青 崔彩霞
(太原师范学院计算机系,晋中,030619)
Relief算法为系列特征选择方法,包括最早提出的Relief算法和后来拓展的ReliefF算法,核心思想是对分类贡献大的特征赋予较大的权值;特点是算法简单,运行效率高,因此有着广泛的应用。但直接将Relief算法应用于有干扰的数据集或不平衡数据集,效果并不理想。基于Relief算法,提出一种干扰数据特征选择算法,称为阈值-Relief算法,有效消除了干扰数据对分类结果的影响。结合K-means算法,提出两种不平衡数据集特征选择算法,分别称为K-means-ReliefF算法和K-means-Relief抽样算法,有效弥补了Relief算法在不平衡数据集上表现出的不足。实验证明了本文算法的有效性。
特征选择;Relief算法;ReliefF算法;不平衡数据集
引 言
分类系统的好坏取决于所利用的特征是否能够很好地反映所要研究的分类问题。特征选择即从输入的p个特征中选择d 不平衡数据集是指一个数据集中,某一类的样本数目明显大于另一类的样本数目。由于在不平衡数据集上采样的悬殊,传统方法往往得不到很好的分类效果。目前用于处理不平衡数据集分类问题的方法可以分为两类:(1)从数据集入手,通过改变数据的分布,将不平衡数据变为平衡数据;或者通过特征选择,选出更能表达不平衡数据集的特征。(2)从算法入手,根据算法应用在不平衡数据上所体现的缺点,改进算法,提高正确率[5,6]。本文从数据集入手,通过改变随机选择样本的策略,利用Relief算法,研究有干扰数据集的分类问题,以及通过将K-means算法和抽样机制与ReliefF 和Relief算法巧妙结合起来,利用KNN分类算法,研究不平衡数据集的分类问题。 (1) 式中:xi(j)表示样本xi关于第j个特征的值;d(·)表示距离函数,用于计算两个样本关于某个特征的距离;m是随机抽取样本的次数。 (1)如果xi和NMi关于某个特征的距离大于xi和NHi关于该特征的距离,说明该特征对区分同类和不同类的最近邻是有益的,则根据式(1)该特征的权重增加,反之,该特征的权重减少。 (2)距离函数定义 当特征为非数值型特征时,定义 (2) 当特征为数值型特征时,定义 (3) 其中max(j),min(j)分别表示第j个特征所取值中的最大值和最小值。 ReliefF算法是Knonenko在1994年对Relief作的扩展,可以用于处理多类别问题[9]。ReliefF算法每次从训练样本集中随机取出一个样本xi,然后从与xi同类的样本中找出xi的k个近邻样本NHi,同时从每个与xi不同类的样本中也找出k个近邻样本NMi,然后根据以下规则更新每个特征的权重[9],有 (4) 式中:class(xi)表示样本xi所属的类别;c表示某个类别,p(c)表示类别c的先验概率[10,11]。 Relief算法不仅算法原理比较简单,运行效率高,而且对数据类型没有限制,因此获得了广泛的应用。然而在实际应用中,该算法却存在一些局限性,比如不适合处理有干扰的数据,也不适合处理不平衡数据。 2.1 干扰数据分类问题 Relief算法首先需要从样本集中随机选择一个样本作为训练样本,这种随机选择样本的方式,很可能取到不具有代表性的样本,或干扰样本,这意味着训练得到的特征可能不具有代表性,从而影响分类结果。针对上述问题,本文提出一种新的样本选取方法。首先计算样本集中每个样本与各自类中心的距离,将距离小于某一阈值的样本生成一个样本集D′,然后再从D′中随机选择一个样本,这样得到的样本可以比较好地排除干扰样本和不具有代表性的样本。 算法1(阈值-Relief算法) 输入: 样本集D,特征集F,类别集C,取样次数m,阈值δ 输出: 特征权重向量W 过程: (a)特征权值初始化:W(i)=0; (b)计算与每个类中心距离小于某一阈值δ的样本集合D′; (c)从过滤后的样本集D'中随机选取一个样本xi,同时从D与xi同类的样本集中选取最近邻的样本NHi,从异类样本集中选取最近邻的样本NMi; (d)利用式(1)更新特征权重; (e)重复(c,d)m次; (f)输出特征权重向量W。 2.2 不平衡数据分类问题 在不平衡数据集上,利用Relief算法选择的特征有可能出现权重值伪偏大。因为在随机选择样本时,样本数目较多的类别中样本被选中的概率要大,而样本较少的类别中样本被选中的概率要小,因而影响分类的效果。本文首先利用K-means算法对大类样本集中的样本进行聚类,然后在多类数据集上,分别基于K-means-ReliefF算法和K-means-Relief抽样算法解决数据不平衡带来的问题[12,13]。 2.2.1K-means-ReliefF算法 首先将大类集聚类得到一些新的类别集,从而使得样本类别集基本平衡;然后采用ReliefF算法进行特征选择。 算法2(K-means-ReliefF算法) 输入:大类集L,小类集S(L和S同时表示类标签)和聚类数q(q为大类集与小类集中的样本数之比取整) 输出:特征权重向量W 过程: (a)利用K-means算法对样本集L聚类,得到q个新类集S1,S2,…,Sq,与S一起构成q+1个基本平衡的数据类集; (b)利用ReliefF算法在q+1个类集上计算特征权重; (c)输出特征权重向量W。 2.2.2K-means-Relief抽样算法 首先将大类集聚类,得到一些新类,在每个类内抽取样本,组成新的集合,代表大类集,然后采用Relief算法计算特征权重[14]。 算法3(K-means-Relief抽样算法) 输入:大样本集L,小样本集S(L和S同时表示类标签)和聚类数q(q为大类集与小类集中的样本数之比取整) 输出:特征权重向量W 过程: (a) 利用K-mean算法对样本集L聚类,得到q个新的类集S1,S2,…,Sq; (c)利用Relief算法在L′和S上计算特征权重; (d)输出特征权重向量W。 3.1 数据集 本文采用的数据集均来自UCI数据集。为了实验的需要,在原始数据集上做了人为的修改。首先,为了得到有干扰样本的数据集,修改了原始数据集中一些样本的类别标签;其次,为了得到不平衡数据集,删除了原始数据集中的一些样本。具体数据见表1。 表1 3个数据集 3.2 实验与结果分析 实验利用Relief算法或ReliefF算法进行特征权重计算,以KNN做分类器(K=3),为了得到更可靠的实验结果,采用5折交叉验证法,即将数据集平均分成5份,随机选择其中1份作为测试数据,其余的作为训练数据,并且取5次的平均值作为最终的结果。结果表明,选择原始数据特征数的20%进行分类效果最佳(以ionosphere为例,选择权重较大的7个特征进行分类效果最佳)。 2.2.1 实验1 实验中,迭代次数m取训练集中的样本数。表2为在ionosphere数据集上随机选择样本和阈值选择得到的权重较大的7个特征以及它们的权重;图1为在ionosphere数据集上两种方法选择样本得到各特征权重值。表3为3个数据集上的分类正确率。 表2 Relief算法与阈值-Relief算法在ionosphere数据集上获得的前7个特征的权重 图1 Relief算法与阈值-Relief算法在ionosphere数据集上各特征权重值比较Fig.1 Comparison of feature weights of Relief algorithm and Threshold-Relief algorithm in ionosphere表3 Relief算法与阈值-Relief算法在3个数据集上的分类正确率 %Tab.3 The classification accuracy of Relief algorithm and threshold -Relief algorithm in three data sets 算 法ionospherewdbcBreastRelif算法88.390.389.5阈值⁃Relief算法909293.3 从表2和图1可以看出,在ionosphere数据集上,Relief算法与阈值-Relief算法得到的特征排序和权重并不相同。由表3可知,在3个数据集上,阈值-Relief算法的分类正确率均比Relief算法的分类正确率要高,说明干扰点确实是Relief算法的消极因素,而改进后的阈值-Relief算法,可以有效地避开干扰点,选出更能代表类别的特征。该方法同样也适用于不平衡数据。 3.2.2 实验2 表4为在ionosphere的不平衡数据集上使用Relief算法、K-means-ReliefF算法(K=10)和Kmeans-Relief抽样算法得到的权重较大的7个特征的排序、特征权重以及小类别的分类正确率和总的分类正确率。图2为在Ionosphere数据集上3种方法得到的各特征权重。 表4 3种抽样算法在Ionosphere数据集上的前7个特征权重及分类正确率 图2 Relief算法、Kmeans-ReliefF算法和Kmeans-Relief抽样算法在ionosphere数据集上各特征权重Fig.2 Feature weights of Relief algorithm, Kmeans-ReliefF algorithm and Kmeans-Relief sampling algorithm in ionosphere 通过表4和图2可以看出,Relief,K-means-ReliefF算法和K-means-Relief抽样算法在ionosphere数据集上得到的前7个权重较大的特征及其特征权重,同时可以看到,在小类别的分类正确率上有了明显的提高。表5给出了Relief算法、K-means-ReliefF算法和K-means-Relief抽样算法在不同数据集上分类正确率的比较。实验结果显示,大类集聚类后,无论是利用ReliefF算法在多类上进行特征选择,还是利用Relief算法通过从多个类别中抽取样本进行特征选择,都可以有效弥补不平衡数据带来的不足。在wdbc数据集上表现不明显的原因是由于数据集的特征较少,抽取的特征有限,可能丢掉了一些相对重要的特征。 表5 Relief算法、K-means-ReliefF算法和K-means-Relief抽样算法在3个数据集上的分类正确率 % 本文提出的阈值Relief算法,可以有效消除干扰数据集中干扰点对分类准确率的消极影响,提高分类精度。而结合K-means聚类算法提出的K-means-ReliefF算法和K-means-Relief抽样算法,可以有效避开Relief算法在随机选择样本时在不平衡数据集上表现出来的不足。实验结果表明,在不降低大类样本的正确率的基础上,有效地提高了小类样本的正确率。本文还存在一定的不足之处,希望能在下面几方面加以改进:(1)首先干扰点和不平衡样本集是人工构造,存在一定的随机性,下一步的工作希望能在真实的不平衡数据集上去验证算法的有效性;(2)数据集中特征偏少,这样可能在少量的特征上,每个特征都是比较重要的特征,故实验结果不是很明显。今后的工作重点是将该算法应用在不同的更大规模的真实地数据集上测试,针对数据集的不同改进算法。 [1] 张学工.模式识别(第三版)[M].北京:清华大学出版社,2010. Zhang Xuegong. Pattern recognition (Third Edition) [M]. Beijing: Tsinghua University Press, 2010. [2] 钱宇华,梁吉业,王锋.面向非完备决策表的正向近似特征选择加速算法[J].计算机学报,2011,31(3):435-442. Qian Yuhua,Liang Jiye,Wang Feng. A positive-approximation based accelerated algorithm to feature selection from incomplete decision tables[J]. Chinese Journal of Computers, 2011,31(3):435-442. [3] 刘全金,赵志敏,李颖新.基于特征间距的二次规划特征选取算法[J].数据采集与处理,2015,30(1):126-136. Liu Jinquan,Zhao Zhimin,Li Yingxin. Feature selection algorithm based on quadratic programming with margin between features[J]. Journal of Data Acquisition and Processing,2015,30(1):126-136. [4] 李嘉.语音情感的维度特征提取与识别[J].数据采集与处理,2012,27(3):389-393. Li Jia. Dimensional feature extraction and recognition of speech emotion[J]. Journal of Data Acquisition and Processing,2012,27(3):389-393. [5] Chawla NV, Japkowicz N, Kotcz A. Editorial: Special issue onlearning from imbalanced data sets[J]. SIGKDD Explorations Newsletters,2004,6(1): 1-6. [6] Abe N, Kudn M. Non-parametric classifier-independent feature selection[J]. Pattern Recognition,2006,39(5):737-746. [7] Kira K, Rendell L. A practical approach to feature selection[C]//Proc 9th International Workshop on Machine Learning. San Francisco: Morgan Kaufmann, 1992: 249-256. [8] Kira K, Rendell L. The feature selection problem: Traditional methods and new algorithm[J]. Proc AAAI′92. San Jose, CA:[s.n.],1992:129-134. [9] Knonenko I. Estimation attributes: Analysis and extensions of Relief [C]//Euopean Conference on Machine Learning. Catania: Springer Verlag, 1994: 171-182. [10]Sun Yijun. Iterative Relief for feature weighting:Algorithms,theories,and applications[J]. IEEE Trans on Pattern Anslysis and Machine Intelligence, 2007,29(6):1035-1051. [11]Sun Y, Wu D. A Relief based feature extraction algorithm [C]//Proceedings of the 8th SIAM International Conference on Data Mining. Atlanta,GA,USA:[s.n.],2008:188-195. [12]Liang Jiye, Bai Liang, Dang Chuangyin, et al. The K-means-type algorithms versus imbalanced data distributions[J]. IEEE Transactions on Fuzzy Systems, 2012, 20(4):728-745. [13]黄莉莉.基于多标签ReliefF的特征选择算法[J].计算机应用,2012,32(10):2888- 2890,2898. Huang Lili. Feature selection algorithm based on multi-label ReliefF[J].Journal of Computer Applications,2012,32(10):2888-2890,2898. [14]林舒杨,李翠华.不平衡数据的降采样方法研究[J].计算机研究与发展,2011,48(S):47-53. Lin Shuchang, Li Cuihua. Under-sampling method research in class-imbalanced data[J].Journal of Computer Research and Development,2011,48(S):47-53. 菅小艳(1975-),女,讲师,研究方向:数据挖掘,机器学习,E-mail:jianxiaoyan@tynu.edu.cn。 韩素青(1964-),女,副教授,研究方向:数据挖掘,机器学习,E-mail:hansuqing@tynu.edu.cn。 崔彩霞(1974-),女,副教授,研究方向:数据挖掘,机器学习,E-mail:cuicaixia@tynu.edu.cn。 Relief Feature Selection Algorithm on Unbalanced Datasets Jian Xiaoyan, Han Suqing, Cui Caixia (Department of Computer Science, Taiyuan Normal University, Jinzhong, 030619, China) Relief algorithm is a series of feature selection method. It includes the basic principle of Relief algorithm and its later extensions reliefF algotithm. Its core concept is to weight more on features that have essential contributions to classification. Relief algorithm is simple and efficient, thus being widely used. However, algorithm performance is not satisfied when applying the algorithm to noisy and unbalanced datasets. In this paper, based on the Relief algorithm, a feature selection method is proposed, called threshold-Relief algorithm, which eliminates the influence of noisy data on classification results. Combining with the K-means algorithm, two unbalanced datasets feature selection methods are proposed, called K-means-ReliefF algorithm and K-means-relief sampling algorithm, respectively, which can compensate for the poor performance of Relief algorithm in unbalanced datasets. Experiments show the effectiveness of the proposed algorithms. feature selection; Relief algorithm; ReliefF algorithm; unbalanced datasets 国家自然科学基金(61273294)资助项目;山西省科技基础条件平台(2014091004-0104)资助项目。 2015-05-26; 2015-07-22 TP18 A1 Relief和ReliefF算法
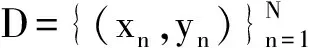
2 干扰数据和不平衡数据分类

3 实验结果







4 结束语



