说话人识别中语速鲁棒性研究
2016-12-23朱紫阳彭亚雄
朱紫阳,贺 松,彭亚雄
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
说话人识别中语速鲁棒性研究
朱紫阳,贺 松,彭亚雄
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
如今,说话人识别技术已经比较成熟,但依然有很多因素影响说话人识别系统的稳定性。本文针对说话速度对说话人识别的影响进行了一系列的研究工作。通过模型空间分布可视化和语音频谱观察两方面来分析不同语速语音的差距。然后,提出了最大似然线性回归(MLLR)和Constraint MLLR(CMLLR)的方法对模型和特征进行变换,使训练端和测试端的语音特征互相接近匹配。通过实验发现,MLLR和CMLLR能较好地提高说话人识别系统中语速鲁棒性。
说话人识别;语速鲁棒;模型空间分布可视化;MLLR;CMLLR
1 不同语速对系统识别率的影响分析
训练集和测试集的语音语速不同是否会对说话人识别系统鲁棒性造成影响,造成的影响大不大,本节将分别从模型特征和语音频谱方面对不同语速进行分析。这里把语速分为普通语速、快语速和慢语速三种。
1.1 语音特征分布具象化
说话人识别[1]是生物模式识别[2]的一种,是根据语音特征进行识别的方法。语音特征是按帧提取的,这些特征在音素空间上的分布就表征了一个人的语音信息。所以,通过音素空间的不同分布,可以描述人在语音上的不同。GMM-UBM模型[3]是用很多高斯混合来拟合特征的分布,每一个混合表示了一个特征聚类分布,而且这个混合的均值μ就表示特征分布的中心。因此,不同语速在特征上的区别对说话人区分造成的影响就可以用模型均值向量在空间上的偏移来表达。
在GMM-UBM系统中,三种语速都取同一个高斯混合(这里都取第二个混合),用t-sne非线性降维方法[4]将提取的混合的均值向量从高维降到二维平面,可以说是把模型对特征的描述能力压缩,然后用python的画图模块使语音特征分布具象化,如图1所示。
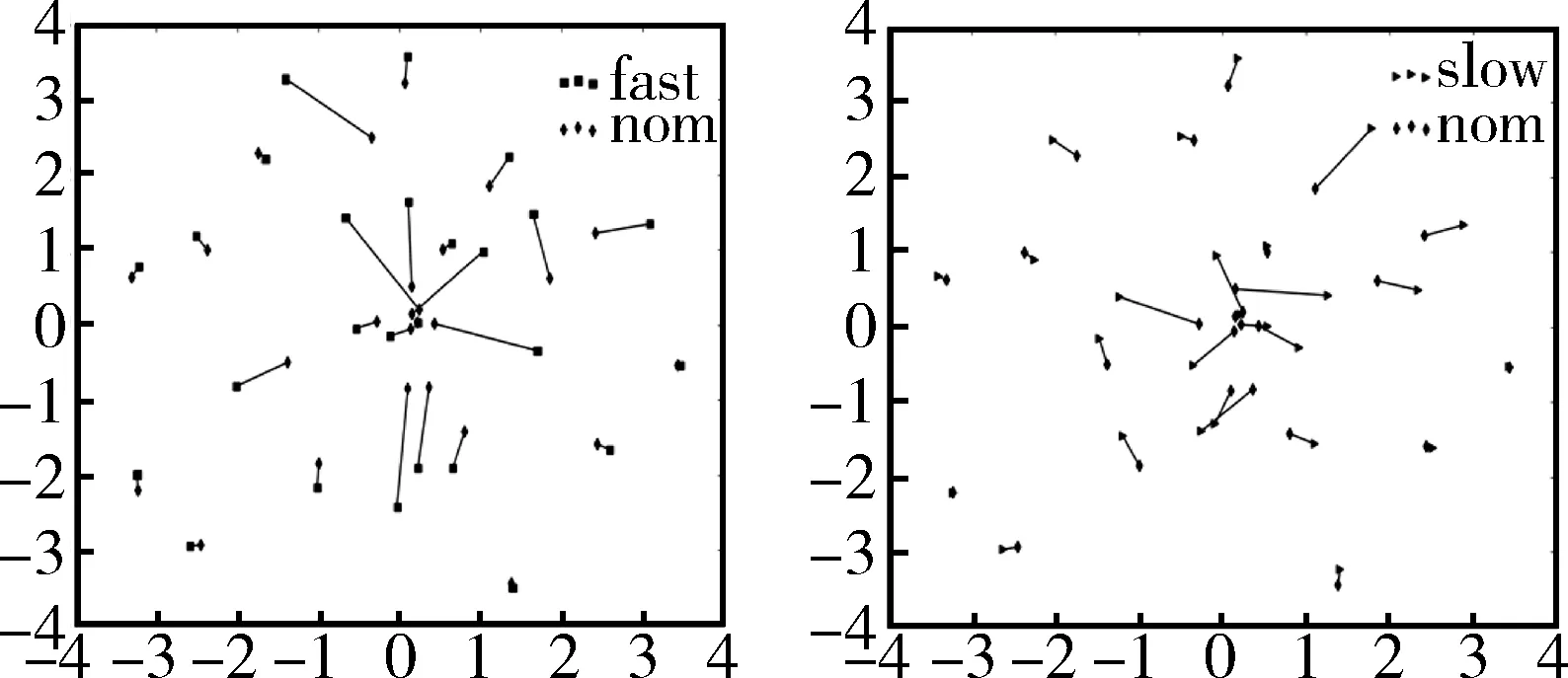
图1 快语速(左)和慢语速(右)相对于普通语速的偏移
在图1中,两张子图分别表示了快语速和慢语速相对普通语速的偏移。同一个人的不同语速模型由一根线条进行连接,这根线条的长短就表示了模型偏移的距离。从图中可以看出,快、慢语速相对普通语速有着明显的偏移。当然每个人偏移的距离各不相同,这是因为不同的人其语速的快慢程度也不同。总的来说,从图中可以看出,语速对说话人识别系统有着很大的影响,这从后面实验的baseline可以看出。
1.2 语音频谱图
上面的内容总体分析了不同语速下模型的偏移,很直观地描述了语速对系统的影响。本节针对语音信号层面进行观察和分析,寻找不同语速下语音信号发生的变化并总结规律。
选择同一个人在不同语速下的同一个数字语音片段,将这三段语音用praat[5]进行频谱绘制,结果如图2所示。
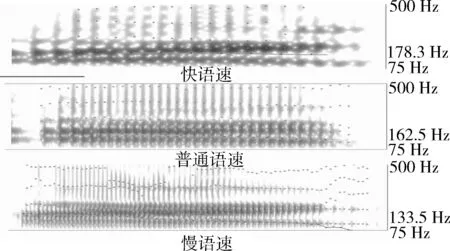
图2 不同语速下同一个数字‘2’的频谱图
从图2可以看出3个频谱具有明显的区别:
(1)图中底部的横线代表基频(pitch),最右侧中间数字则是计算出来的平均基频。可以看出快语速的平均基频要大于普通语速,而慢语速的平均基频则小于普通语速。并且慢语速的基频在句尾有明显的下降趋势。
(2)图中分布点表示共振峰,可以看出相较于慢语速,普通语速和快语速的共振峰结构更加有规律,慢语速的共振峰结构相对比较混乱。
(3)慢语速的能量分布在低频部分非常密集且在高频部分也有明显的能量分布。普通语速与快语速的能量基本都分布在低频部分,并且普通语速在低频段的能量分布相对于快语速要更加明显一些。
这些差异性在其他的语速语音中也存在,所以此处假设语速对语音频谱的影响是有一定的共同特点的。本文把3种不同的语速特征当做3个独立的子空间来描述。
从频谱图中的区别可以看出,语速对语音频谱带来了明显变化,可以认为快语速和慢语速携带了清晰的语速区分性信息,这些信息会混淆说话人的区分性信息。用普通语速训练的模型覆盖不了这些语速区分性信息,当测试语音中含有语速区分性信息时,必然造成匹配性变差,从而影响系统的识别性能。
2 语速的特征和模型转换
2.1 语速的区分性信息
从上节得出一个假设,语速特征是一个独立的子空间,并且和普通语速空间存在一定的对应关系。那么语速区分性信息实质上是两个不同子空间的偏移。因此,可以通过一组语速依赖的线性变换来进行两个特征空间的相互投影,以此来学习这种语速区分性信息。一般来说有两种方案进行映射。
(1)把普通语速训练的模型投影到两种语速空间,让其携带语速的区分性信息,提高模型对语速的表达能力。对于模型M(s,r)来说,其中s表示说话人,r表示语速,在训练模型M(s,r)时,提出一种语速依赖的转变方法,其定义如下:
M(s,r)=Lr(M(s))
其中,Lr是通过分离出的开发集的语速数据训练出来的,所以与参加测试的说话人没有关系。
(2)把携带语速区分性信息的测试语音特征经过映射后,变换到普通语速(中性)的空间,削弱这些特征中的语速区分性信息,相对地增强对说话人的区分性信息的描述能力。对于特征Xt(s,r)来说,t是特征的序号。训练一个语速无关的变换,定义如下:
Xt(s,r)=Lf(Xt(S))
其中Lf和Lr一样是一个与说话人无关的线性变换,且它们拥有同样的训练过程。本文选用MLLR方法实现语速特征空间的相互转化,用一种简单的线性模型来模拟语音中对语速区分性信息的分离及添加过程。
2.2 线性语速空间变换
MLLR[6-7]最早由剑桥语音小组提出,用来解决信道不匹配下的语音识别。这个方法可以用比较少的训练数据学习出两组数据之间共性特征的不同之处。通过MLLR可以减小两组数据因共性特征不同所致的数据分布偏移。
在对模型进行变换时,用MLLR计算一组语速依赖的线性变换Lr,然后把普通语速的GMM-UBM说话人模型变换到语速依赖的模型M(s,r)上。这样模型就可以引入语速的区分性信息,最终减小训练语音和测试语音由于语速差距带来的不匹配。在GMM-UBM模型中,最能体现说话人区分性的是各种混合中的均值向量,所以在对模型变换时只研究均值向量的变化,认为协方差矩阵不变。根据MLLR方法,可以得到:
(1)
其中,μr是指第r个高斯分量的均值向量,ξr是与μr相对应的扩展的均值向量。L是涉及偏移的三角矩阵,代表了语速的变换。然后用最大似然方法来优化L得到最终的偏移矩阵。
上面的方法中,只对模型的均值向量进行了更新,然而这并不全面,此处还要加上一定的约束条件,即实现模型均值和方差的同步更新,这就是Constraint MLLR(CMLLR)[8]方法。CMLLR方法认为说话人模型的均值和方差是用同样的变换矩阵进行变换的,这样的变换就等价于在特征空间对特征进行变换。本文就是把带有语速区分性信息的特征投影到普通语速空间,以削弱特征中语速的信息。
2.3 语速空间的投影矩阵训练
对模型进行变换的MLLR和对特征进行变换的CMLLR具有同样的训练过程,差别在于使用时,前一个用于变换训练端的普通语速模型,后一个用于变换测试端的语速特征。训练过程如图3所示。

图3 变换矩阵训练过程
先从语音数据中提取出一部分语音作为开发集,用来训练出语速空间投影矩阵的参数。开发集中的这些数据不参与最后的测试,并且把快慢两种语速分开进行训练,最后得到两个变换矩阵。开发集中的普通语速语音为每个说话人训练一个对应的模型,对于快慢两种语速,基于得到的普通语速说话人模型,采用快慢语速特征来训练两个对应的线性变换矩阵。
在测试集上进行识别的过程中,一种是基于MLLR的模型投影方法,用训练得到的变换矩阵将普通语速说话人模型和UBM模型投影到对应的语速空间上,使其带上语速区分性信息,然后对带语速区分性信息的测试语音进行识别。另一种是基于CMLLR的特征变换,把带语速区分性信息的测试语音通过变换矩阵投影到普通语速空间,然后在普通语速的模型上进行识别。两种不同方案如图4所示。

图4 变换矩阵的应用
3 实验
实验数据选用已经录制好的语速数据库,共30人,其中男女各15人,包含了3种语速,每种语速22句话,12句用来训练说话人模型,10句用来测试识别。说话人识别系统基于经典的GMM-UBM模型设计。特征为13维MFCC特征加上其一阶导数和二阶导数共39维。同时用倒谱均值和方差归一化方法来减少信道、背景噪音等造成的影响。
作为baseline,说话人以不同语速的语音直接在普通语速GMM-UBM模型上进行测试。由于要选出10人做开发集训练线性变换矩阵,所以选取20个说话人进行全交叉测试,经过识别打分后,用EER来衡量系统的性能。
为了测试MLLR和CMLLR方法,用10人训练变换矩阵。然后用变换矩阵对剩余20人的语音特征或模型进行变换,最后用变换后的模型或特征进行识别打分。
Baseline和MLLR/CMLLR方法的实验结果如表1。

表1 baseline、MLLR和CMLLR实验结果
实验结果验证了语速特征可以当成一个独立子空间的假设,因此可以用线性模型去学习这种语速空间之间的偏移。从表1可以看出,快语速在MLLR方法上EER相对baseline下降了0.1%,在CMLLR方法上EER相对baseline下降了0.19%。慢语速在MLLR方法上EER相对下降了0.13%,在CMLLR方法上EER相对下降了0.21%。可见这种模型和特征的线性变换起到了比较大的作用。而且,CMLLR对系统性能的提高比MLLR更明显。这是由于MLLR在引入语速区分性信息时也在一定程度上降低了说话人的区分性能力。
4 结束语
本文通过MLLR和CMLLR对语速特征及模型进行了线性变换,然后用变换所得的模型及特征进行识别打分,目的在于解决说话人识别中语速鲁棒性问题。从实验结果看出,MLLR/CMLLR对系统的鲁棒性有很好的提高。但是,当有语速语音预留时,训练模型的阶段并没有充分利用这些语速语音。因此,后面研究可以把语速语音经过投影矩阵变换后再和普通语速语音结合,以训练出更具表述能力的模型。
[1] 吴朝晖,杨莹春. 说话人识别模型与方法[M] . 北京:清华大学出版社,2009.
[2] 王雨晴,谢晓尧.基于生物模式识别的网络身份认证研究[J] .微型机与应用,2014,33(18):42-44.
[3] 熊振宇.大规模、开集、文本无关说话人辨认研究[D] . 北京:清华大学,2005.
[4] MAATEN L V D,HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research , 2008(9): 2579-2605.
[5] 叶志腾.应用Praat软件分析成人嗓音声学参数[D] . 福州:福建医科大学,2009.
[6] LEGGETTER C J,WOODLANG P C. Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models[J]. Computer Speech & Language, 1995(9): 171-185.
[7] STOLCKE A,KAJAREKAR S S,FERRER L,et al. Speaker recognition with session variability normaliization based on MLLR adaptation transforms[J]. Audio, Speech, and Language Processing, IEEE Transactions on. 2007, 15(7): 1987-1998.
[8] 别凡虎.说话人识别中区分性问题的研究[D]. 北京:清华大学,2015.
Research on speaking rate robustness in speaker recognition
Zhu Ziyang, He Song, Peng Yaxiong
(Big Data and Information Engineering Institute, Guizhou University, Guiyang 550025, China)
Recently, speaker recognition has been matured, but there are still so many factors impact the sability of speaker recognition system.This paper mainly researches the influence of speaking rate on speaker recognition. Through making distribution of model space visualization and observing the print of frequency spectrum to analyse gap of the different speed voice. Then, we propose the method of Maximum Likelihood Leaner Regression (MLLR) and Constraint Maximum Likelihood Leaner Regression (CMLLR) to transform the model and feature. It is aimed at making training and testing mutual match. Through the experiment, we find that the MLLR and CMLLR can improve the robustness in speaker recognition with different speaking rate.
speaker recognition; speaking rate robustness; model space visualization; MLLR; CMLLR
TN 912.34
A
1674-7720(2016)07- 0054- 03
朱紫阳,贺松,彭亚雄.说话人识别中语速鲁棒性研究[J].微型机与应用,2016,35(7):54-56.
2015-12-01)
朱紫阳(1990-),男,硕士研究生,主要研究方向:语音识别、说话人识别。
贺松(1974-),通信作者,男,硕士,副教授,主要研究方向:信号处理。E-mail:814919860@qq.com。
彭亚雄(1963-),男,副教授,主要研究方向:信号处理。
