大数据计算的基础理论探究∗
2016-12-19许道云
许道云
(贵州大学计算机科学与技术学院,贵州省公共大数据重点实验室,贵州贵阳550025)
大数据计算的基础理论探究∗
许道云∗
(贵州大学计算机科学与技术学院,贵州省公共大数据重点实验室,贵州贵阳550025)
在经典计算中,对前端输入数据的复杂性不做分析。在大数据计算中,前端输入数据的复杂性分析反而成为大数据计算和分析的重点。本文讨论大数据计算的基础理论问题,将大数据计算问题分为目标任务型和内容认知型。大数据计算形式上依赖于一个外部信息源,从计算的有效性,将大数据计算的讨论限制在对数空间复杂类,涵盖了并行计算复杂类。基于带Oracle的图灵计算模型,限制在对数空间内图灵可计算,并且外部信息源能够用一个对数空间可计算的递归函数枚举,引入了大数据可计算的计算模型和大数据可计算性、可判定问题等概念。
大数据计算;对数空间可计算性;并行可计算性;带Oracle图灵机;大数据可计算性
阿兰.图灵(A.Turing)在1936年提出计算机的数学模型——图灵机以后,20世纪40年代,数理逻辑学家冯.诺依曼以通用图灵机为原型,设计了第一台现代通用计算机EDVAC(电子离散变量自动计算机)。随着现代计算机的出现,计算机可以解决的问题越来越多,计算量越来越大,同时对于科学计算的要求也越来越高(如:高效、正确、安全等)。
一个问题是可解的,是指存在求解该问题的一个算法。根据丘奇(Church)论题,一个可以用算法描述求解的问题,都有一台图灵机(Turing Machine)求解。在计算理论中,计算机器和程序是等同的。因此,一个问题是可解的,通常是指存在一台图灵机求解[1-4]。
研究发现,诸多的计算模型尚未突破图灵计算模型,很多经典的计算模型从“计算能力”来讲,与图灵计算模型等价[1-4]。如:随机存取机器模型(RAM),也称无穷寄存器机器(URM),RAM模型是算法分析与计算复杂性理论中重要的串行计算模型,引进RAM是为了便于从理论上分析计算机串行程序所耗费的时间、空间等资源,现代计算机高级语言设计的数学原型来自于RAM。
在RAM计算模型中,只用到如下4类基础指令[1]:
1.置零Z(n):将第n个寄存器中的内容置为0;
2.后继S(n):将第n个寄存器中的内容加1;
3.变换T(m,n):将第m个寄存器中的内容替换第n个寄存器中的内容;
4.转移J(m,n,q):如果第m个寄存器中的内容与第n个寄存器中的内容相同,则转向第q条指令,否则顺序执行下一条指令。
在可计算性与计算复杂性中,关注两个基础问题:一是判定问题是否可交给机器来完成(即是否可解)?二是如果可以用机器判定,则计算代价(时间和空间复杂性)如何估计?
希尔伯特(Hilbert)曾经想建立一个大一统的数学理论(称为Hilbert计划),使一切事物和问题都可以数学地认知和求解。Hilbert计划企图完成一个宏伟蓝图,任何算术问题都是可解的。但是,后来的情况不是这样。哥德尔(Gödel)证明了:在含有一阶谓词逻辑和初等算术(Peano算术)的形式系统中,存在这样的命题,在该系统中,既不能证明该命题为真,也不能证明它为假。这就是著名的哥德尔不完全第一定理[1]。哥德尔不完全定理否定了Hilbert计划,从而人们开始关注问题的可解与不可解。
实际上,问题的可解是相对的,不可解是绝对的。意思是指:问题的可解性依赖于形式规则,没有通用的规则系统求解一切问题。或者说,给定的形式规则系统下,都存在不可解问题。例如:仅用直尺和圆规不能三等分任一个角[5,6]。但是,如果适当修改规则是可以做到的[6]。
一个问题(命题)是可判定的,是指存在一台图灵机判定它是真还是假。哥德尔不完全定理解释了不可判定问题的存在性。在可计算性理论中,由通用图灵机的存在性,借助康托(Cantor)对角线方法,证明了著名的停机问题是不可解问题[1-4]。以此为种子,利用归约技术,构造了许多不可判定问题,其中包括著名的Hilbert第十问题(整系数多项式是否有整数根)[3,4]。
一个问题(命题)是半可判定的,是指存在一台图灵机,如果该问题为真命题,则机器在有限步内停机并输出“真”;如果命题为假,则机器可能不停机。在可计算性理论中,允许机器计算不停机(从而无输出)。
计算复杂性理论只考虑可判定问题的计算时间和空间复杂性,由于空间可重复使用,而时间是不能重复的。因此,复杂性理论中,重点研究时间复杂性。
在可判定问题的计算复杂性研究中,P类和NP类是两个核心研究对象[7,8]。NP类以外的问题统称为NP难问题。
一个可判定问题在P类中(简称P-问题),如果存在一台确定型图灵机,在多项式时间内停机,并输出结果。一个可判定问题在NP类中(简称NP-问题),如果存在一台非确定型图灵机,在多项式时间内停机,并输出结果。显然P类是NP类的一个子类。著名的“P与NP问题”是指:P是否等于NP。该问题至今是计算机科学中尚未解决的问题。
1 经典有效计算下看大数据计算
在计算复杂性理论和算法设计中,一般认为:如果一个问题有多项式时间算法求解,就认为该问题是易解的(tractable)。这里多项式时间是指:相对于输入问题实例的规模大小n,算法能在多项式p(n)时间内停机,并有结果输出。
多项式时间的算法被认为是“有效”算法。但是,这里对n的大小却没有计较,也不考虑输入的结构!
在大数据计算中,输入实例的规模大小n和结构表示变成了主要问题。从算法的角度讲,无论是什么样的算法,总要阅读完输入实例。问题就在这里:如果实例的规模大小n很大,实例的结构很复杂,这势必给计算带来了额外的开销。
按1个字节(Byte)具有8位(bit),(1千字节) 1 KB=1024 B,(1兆字节)1 MB=1024 KB,(1千兆字节)1 GB=1024 MB,(1太字节)1 TB=1024 GB,(1拍字节)1 PB=1024 TB,(1艾字节) 1 EB=1024 PB。按这样的1024级指数递增,1 EB=9.2234e+18位。可以看出,数据的描述开销是惊人的。
在经典的计算复杂性中,数据的度量单位是以“位”为单位。计算对象的0、1码字符串长度n作为计算对象的规模大小。大数据如果以PB级计量,由前面的换算关系,1 PB 具有 n=8796093022208位。因此,对于大数据的计算,除了要考虑算法本身的计算复杂性外,更大的挑战要考虑数据本身的描述复杂性,简称数据复杂性。如果将问题限制在多项式算法的可解类(即P类),对于大数据计算问题,主要的任务是将“压缩”大数据到整个求解问题的时间能够承认的范围内。否则,理论上算法有效,但实际上无效。
在大数据计算中,数据的复杂性变成了主要问题!
大数据本身远比经典的计算对象复杂,虽然至今没有给出大数据的标准数学定义,但从公认的表象上看具有如下4个特征(简称4V特征):第一,数量(Volume),即数据量巨大,从TB级别跃升到PB级别;第二,多样性(Variety),即数据类型繁多,结构复杂,不仅包括传统的结构化数据,还包括来自互联网的网络日志、视频、图片、地理位置信息等非结构化数据;第三,速度(Velocity),即处理速度要求快,数据动态变化大;第四,真实性(Veracity),即追求高质量的数据。
鉴于大数据的4V特征,我们得考虑如下基本问题:
(1)如何规定大数据可计算?
(2)如何处理量“大”的问题?
(3)如何处理“非结构化”问题?
(4)如何处理动态数据流的在线和离线计算问题?
(5)既要兼顾可计算,又要保证真实性,这一对矛盾如何处理?
当然,单从计算上讲,重点是在处理大数据的表示(数据结构)问题、以及对量的压缩处理。对量的压缩处理使得计算时间可承受,大数据的表示主要用于分析压缩处理计算后的误差承受。
从计算的角度看,经典的问题求解形式上是设计一个算法,将需要求解的问题按一定的数据结构进行编码后作为算法的输入,算法的输出作为问题的求解结果。
大数据计算问题与经典算法形式上有所不同。粗略地说,大数据计算问题是依赖于一个外部信息源Q的计算。
需要求解的问题可以分为两类:
目标任务型:给定一个任务x,依赖数据集Q,寻求问题x的目标对象y,或解决问题x的目标方案。这类计算问题的目标是:基于数据集Q,给定一个任务描述x,算法输出任务x的目标方案(或结果)y。如:数据库查询问题。
内容认知型:算法本身无任务输入,仅依赖数据集Q,通过机器学习方式,在数据集中寻求知识和知识关联。这类计算问题的目标是:分析数据集Q的整体(或局部)数据关联特征,以某种知识表示的方式给出数据集Q所蕴含知识的抽象描述。
实际应用中,大数据的计算并不是将整个数据集Q作为算法的输入,在计算中只需要对Q进行局部访问。因此,这样的Q实际上是算法的外部信息源。
一般,静态的大数据的计算依赖于一个庞大的数据集Q。这个数据集Q可以是虚拟的(指:数据集边缘用户不需要知道,或无法知道。如:互联网数据,云端数据等),也可以是现实存在的(指:数据集边缘用户可知道。如:已知数据库);可以是当地的,也可以是异地。
鉴于此,我们有理由引入一种带Oracle的图灵机作为大数据计算的计算模型。其中,Oracle译文为“神谕”。意指:有一个超强的外部装置在协助机器进行计算。
本文研究大数据计算的基础理论,分析了大数据计算的基本问题:
(1)大数据计算问题实质上是“基于某个外部数据源Q”的计算问题;大数据分析问题是对“外部数据源Q”的认知问题。
(2)经典算法对输入x只计大小n,不计算x的结构,有效算法是指关于n的多项式时间算法,多项式时间可解问题类称为P类。大数据计算中,算法的输入x是任务的描述,x的大小n可能很大(如:指数级)。因此,大数据可计算问题限制在P的子类中讨论,P类以外的计算问题“大数据不可计算”。
(3)并行计算是大数据计算的自然选择。从理论上讲,作为并行计算模型的NC电路可以作为大数据可计算的计算模型,NC类作为P的一个子类。对数空间可计算类作为NC的子类,对数空间可计算函数作为NC归约的转换器。
(4)从实际计算和应用选择上讲,将带Oracle的图灵机限制在对数空间可计算,对应到带外部信息源的并行算法。鉴于整个计算有效性的要求,外部数据源Q被假设为用一个对数空间可计算的递归函数枚举。
本文引入的大数据可计算的计算模型是带Oracle(外部信息源)的图灵计算模型。其中要求: (a)图灵机本身是对数空间可计算;(b)对外部信息源的访问可以在对数空间可计算内完成。即,对外部信息源集Q可以用一个对数空间可计算的递归函数枚举。这种计算模型称为“双对数”计算图灵计算模型。简称为LL-型图灵计算模型。
2 大数据计算的基本问题
从数学的角度说,谈到计算必须弄清楚两个基本问题:一是计算对象,即对什么进行计算?二是计算的任务,即计算的目的是什么?
大数据的计算是依赖于一个庞大的数据集Q,计算并非将整个数据集Q作为算法的输入,在计算过程中只需要对Q进行局部访问。这样的Q实际上是算法的外部信息源。因此,大数据计算本质上归类为带外部信息源的计算问题类。
大数据指的是这个庞大的数据集Q,而不是一个单一的数据对象。早期的数据库Q关注的是“存储”、“查询”、以及某些应用统计。这里的Q一般是静态的,或动态变化(维护)频率不是那么高。
大数据计算问题与经典算法形式上有所不同。一般,静态的大数据的计算依赖于一个庞大的数据集Q。这个数据集Q可以是虚拟的,也可以是现实存在的;可以是当地的,也可以是异地。
除了量的变化和数据元素的结构类型上异构以外,大数据计算更加注重:
(1)给定一个计算任务,依赖于数据集Q寻求问题的解(或解决方案);
(2)数据集Q本身内部蕴藏的数据之间的关联性所提供的额外信息(知识);
(3)数据集Q不再是“静”的,这种动态变化形成的数据流所提供的额外信息;
(4)面对数据量大和时间效率要求的矛盾冲突,寻求解决方案。
因此,我们将大数据计算归为两类:目标任务型和内容认知型。
如果大数据按行业分类,目标任务按应用类型划分,我们可以直观用地用二维座标表示:其中,横座标表示行业x,纵座标表示任务y,交叉点代表(x,y)表示任务y基于数据集x的计算。
(1)用y=0代表不带任务输入的计算。此时(x,0)表示对数据集x的内部关联结构的分析和计算。
(2)对于固定的y,集合{(x1,y),……,(xn,y)}代表任务y依赖于多个行业数据集x1,……,xn的计算。
(3)对于固定的x,集合{(x,y1),……,(x,ym)}依赖于行业数据集x对多个任务y1,……,ym的计算。
(4)所谓块数据计算是指:多个任务y1,……,ym依赖于多个行业数据集x1,……,xn的计算。有关块数据的介绍,请参考文献[9,10]。
我们需要注意的是:在大数据计算中,我们并不需要(也不可能)完全知道外部信息源Q。我们只需要知道面对给定任务x,如何去访问Q,使之基于Q下,得到问题的解。另一类问题是从整体(或局部)分析Q能提供什么样的关联信息。
由于大数据的计算并不是将整个数据集Q作为算法的输入,在计算中只需要对Q进行局部访问,这样的Q它并不是算法规则部分。因此,我们称其为算法的外部信息源。
我们认为:大数据计算问题实质上是“基于某个外部数据源Q”的计算问题;大数据分析问题是对“外部数据源Q”的认知问题。
本文重点考虑前者的计算理论问题。
3 可计算性与计算复杂性基本概念
设Σ为一个有穷字母表(如:Σ={0,1}),用Σ∗表示Σ上有穷字符串集合(含空串)。对于一个可有限描述的对象(如:自然数,有理数等),在某种编码方式下,可以用Σ∗中的元素编码表示。基于通常图灵计算模型引入的能行计算理论只能处理Σ∗上串函数的可计算性,由此建立了自然数集上能行计算理论——递归论[1,2]。
形式上,一个函数f:Σ∗→Σ∗是可计算函数,如果存在一台图灵机M,对于任意一个输入x∈Σ∗,在有限步内,机器M输出函数值y=f(x)。Σ∗的一个子集A称为一个语言,A的特征函数χA: Σ∗→{0,1}定义为χA(x)=1⇔x∈Σ∗。一个语言A(作为集合)对应一个判定问题:对任意给定的x∈Σ∗,判定x是否在A中?因此,称一个判定问题是可判定的(或称可解的),如果函数 χA: Σ∗→{0,1}是一个可计算函数。这等价于:存在一台图灵机M计算χA。直观上,存在一个算法,对任意一个输入x∈Σ∗,在有限步内给出判定结果(Yes/No)。例如,整系数线性方程组是否有整数解是一个可判定问题。因为一个整系数线性方程组可以有限编码成一个0、1串,将有解整系数线性方程组对应的编码串构成集合A。因此,对于任意一个输入x∈Σ∗,如果x不是某个整系数线性方程组的编码,则直接回答No;如果是,则解码还原出该整系数线性方程组,然后利用消元法(或其它方法)求解,最终可以确定该方程是否有整数解。如果有解,则回答Yes,否则回答No.可以看出,上述过程在有限步内能完成。
在具体判定问题的描述过程中,可以不考虑编码、解码,并且将程序用算法替代。例如,整系数线性方程组判定问题可以描述为:是否存在一个算法,判定任意给定的一个整系数线性方程组是否有整数解?如果有整数解,算法输出Yes,否则输出No。
著名的停机问题是指:是否存在一个算法A,判定“对于任意给定的一个算法B及一个输入x,B对x的计算在有限步内是否停止?”由引言中的陈述,停机问题是不可判定问题。即,这样的算法A不存在。
计算复杂性理论只研究可判定问题。即对于可判定问题,只对判定算法的时间和空间复杂进行研究。从分类上看,主要研究P类,NP类,NP难类。
对于Σ∗的一个子集A,规定一个问题。对于x∈Σ∗,用x的串长度|x|度量x的规模大小。
一台确定型图灵机M称为多项式时间图灵机,如果存在一个多项式p:N→N,对任意的x∈Σ∗,M关于x的计算,在p(|x|)时间步内停机并有输出。这里N是自然数集。图灵机的确定型是指机器只带一个变迁函数,由上一步到下一步的计算由此变迁函数唯一确定,计算过程是唯一路径。非确定型图灵机所带的变迁函数有两个,上一步到下一步的计算选择其中一个变迁函数决定,所有计算可能的过程展开表现为一棵树,从树根到叶的一条路径代表一种计算可能,只要有一种计算完成对x的计算,则称对x可计算。
从现在开始,我们所指的问题都是可判定问题,重点关注计算时间。
一个问题A在P类中(记为A∈P),如果存在一台多项式时间图灵机M计算A的特征函数。一个问题A在NP类中(A∈NP),如果存在一台非确定型图灵机,在多项式时间内停机,并输出结果。问题A在NP类中等价定义是:存在一台带两个串变量的多项式时间图灵机M(x,y)、以及一个应该证据长度控制多项式q(m),使得:对任意的x∈Σ∗,x∈A⇔(∃y∈{0,1}q(|x|))(M(x,y)= 1)。其中y称为支持x∈A的证据,且证据y的长度受一个多项式q控制,M称为验证机。
多项式归约是经典计算复杂性理论中作为问题转换分析的一种重要而基础的技术。问题A可以多项式归约问题B(记为A≤PB)是指:存在一个多项式时间可计算的转换函数f:Σ∗→Σ∗,满足关系:对任意的x∈Σ∗,x∈A⇔f(x)∈B。直观上,判定x是否在A中,可以先将x在多项式时间内转换为y=f(x),则用y是否在B中来回答x是否在A中。
显然,我们有这样的关系:如果A≤PB,并且B∈P,则A∈P。
例如1:路径问题PATH是一个P问题。所谓路径问题是指:给定一个图G,以及两个结点s,t,判定在图G中是否有一条从s到t的路径。
例如2:欧拉(Euler)问题是P问题。即判定一个无向图是否为Euler图是多项式时间可以判定的。因为由图论知识知道,一个无向图G是Euler图的充分必要条件是图G连通,并且每个结点的度数为偶数[11]。这两个条件的验证可以在多项式时间内完成,其中以图G中的结点数n度量G的大小。
一个问题B称为NP-难的,如果对于任意的A∈NP,有A≤PB。一个问题B称为NP-完全的(简称NPC问题),如果B是NP-难的,并且B∈NP。
合取范式公式的可满足问题简称可满足性(SAT)问题,自Cook证明著名的SAT问题是NPC问题以来,以此为种子,发现很多NPC问题。如,哈密尔顿(Hamilton)问题是NPC问题[3]。(注: Hamilton问题是判定一个无向图是否为Hamilton图?)
对于大数据计算问题,一个自然假设是在“有效”时间内可计算。如果用多项式时间刻画“有效”,那么,对于大数据可计算问题自然限制在P类问题中讨论。
另一方面,对于NPC或NP难以上的可判定问题,在计算复杂性中,处理有效性的办法是寻求近似算法。近似算法主要对付求优问题中的NP难类,近似算法本身自然要求是多项式时间算法,刻画近似算法的优劣是靠算法的近似度。即,问题本身的最优解的代价函数与近似算法产生的解的代价函数之间的比值界[12]。
因此,我们可以对判定问题作如下简单分类[13]:
判定问题:分为可判定与不可判定;
可判定问题:分为NP难以上问题(简称难解问题)与多项式时间可解问题(简称易解问题,对应P类问题);
难解问题:分为可近似问题与不可近似问题[7,8,12];
可见,对于大数据计算问题,基于算法本身多项式时间的要求,我们只能考虑如下两个类中的大数据可计算与不可计算问题:一类是P类,另一类是可近似问题类。
以下,我们重点讨论P类中大数据的可计算与不可计算问题。
对数空间可计算在本文中是一个基本假设。对数空间可计算类涵盖有效并行可计算类,它是P类的一个子类。
4 对数空间复杂类与对数空间归约
度量一个算法的计算代价从时间复杂性和空间复杂性加以考虑。在上一节中,我们简单介绍了时间复杂性的一些基本概念。对于时间复杂性,时间是不可重用的,“确定”与“非确定”有本质区别,因此才有P与NP问题的讨论。
在图灵计算模型中,“空间”计量为计算过程中所用到的工作磁带上的方格数,在随机存取计算模型(RAM)中,用计算过程中所用到的寄存器数计量。
对于空间复杂性而言,由于空间是可重复使用,“确定”与“非确定”对于多项式的限制显得不重要。萨维奇(Savitch)定理告诉我们[3,7,8]:用非确定性图灵机判定的问题可以用一台确定型图灵机来完成,其空间代价级别只差一个平方关系。因此,如果限制在多项式空间下分类,“确定”与“非确定”没有本质区别。
基于上述理由,我们考虑对数空间复杂类[7,8]。
一个问题A在对数空间L=Space(log(n))类中(记为A∈L),如果存在一台对数空间确定型图灵机M计算A的特征函数。即,对于任意的x∈Σ∗,机器M在计算过程中,其工作带上至多用到O(log|x|)个方格数。类似地,一个问题A在NL=NSpace(log(n))类中(记为A∈NL),如果存在一台对数空间非确定型图灵机M计算A的特征函数。可以证明:NL类是P的一个子类。
对数空间足以求解许多有趣计算问题,而且其数学性质具有丰富的吸引力。如:当机器模型和输入的编码方法改变时保持稳健性。此外,指向输入的指针可以在对数空间内表示,所以考虑对数空间算法计算能力的一种方式是考虑固定数目的输入指针的计算能力[4]。
限制在对数空间可计算,类似引入对数空间归约[3,7]:
问题A可以对数空间归约问题B记为(A≤LB),是指:存在一个对数空间可计算的转换函数f: Σ∗→Σ∗,满足关系:对任意的x∈Σ∗,x∈A⇔f(x)∈B。
可以想象一个对数空间转换器M是这样的一台图灵机:它带有一条只读输入带,一条只写输出带,一条工作带。将x放在输入带上,机器计算的结果写入输出带。设n=|x|,计算过程只用到工作带上O(log(n))个方格。
同样,如果A≤LB,并且B∈L,则A∈L。类似可以定义NL完全。一个问题B称为NL-完全的,简称为NLC问题,如果B∈NL,并且对于任意的A∈NL,有A≤LB。
在文献[3]中己经证明:路径问题PATH是NLC问题。一个自然的推论是NL⊆P。即,NL类是P的一个子类。
注意:多项式归约与对数空间归约不一样。可以证明:A≤LB⇒A≤pB(因此得到NL⊆P)。反之不一定成立。
我们曾经假设:在大数据计算中只考虑P类问题。现在考虑以布尔电路作为计算模型下P的子类。
5 多项式时间产生的一致电路族与P语言类的关系
我们现在考虑布尔电路作为计算模型下P类问题的另一个可计算特征。本节的主要概念和结论来自于文献[7]。
定义5.1(布尔电路) 对于任意给定的n,一个具有n-输入,单输出的布尔电路C是带有n个源点(sources)、1个沉点(sink)的有向无环图。所有的其它非源点称为门(gates),并以三种逻辑运算符∨,∧,¬之一分别标记每一个非源点,分别对应逻辑或、逻辑与,逻辑非运算,其中∨,∧的扇入为2,¬的扇入为1。
电路C的规模大小以它所含的结点数定义,记为|C|。如果C为一个电路,x∈{0,1}n是一个输入,则C关于x的输出记为C(x)。
注意:对∨,∧的扇入量的无界和有界限制,对计算复杂性计量有本质差异。本文只考虑有界扇入。
定义5.2(电路族与语言识别) 设T:N→N是一个规模控制函数,一个T(n)-规模的电路族是一列布尔电路{Cn}n∈N,其中Cn带有n个输入和一个输出,并且|Cn|≤T(n)。
一个语言A∈SIZE(T(n))(可判定语言类),如果存在一个T(n)-规模的电路族{Cn}n∈N,使得对于任意的x∈{0,1}n,x∈A⇔Cn(x)=1。
直观上,不同长度的输入调用不同电路,同一长度的不同输入利用同一个电路Cn,且电路规模受一个函数控制(|Cn|≤T(n))。自然,T(n)取不同的函数类(如:n的多项式)就可以定义不同语言类。
自然想到,这样的电路族{Cn}n∈N能否用一台加工机器一致地统一加工生成。
定义5.3(多项式一致生成电路族,P-一致电路族)
一个电路族{Cn}n∈N称为多项式一致的,简称P -一致,如果存在一台多项式时间图灵机M,对于每一个给定的自然数n,以串1n作为M的输入,机器M输出Cn的描述编码(即用机器M生产布尔电路)。
注:通过适当的编码机制,一个电路Cn可以用0、1串编码,称为Cn的描述编码,记为 <Cn>。定理5.4[7]一个语言A由一个P-一致电路族{Cn}n∈N可计算当且仅当A∈P(即A在P类中)。
在大数据计算中,并行计算是一种常见处理方式。我们现在考虑与并行计算相关联的问题类。
6 NC类与并行算法
我们现在开始触及到与大数据计算紧密相联的计算模型和问题类。将并行计算与布尔电路相关联。类似于定义树的高度,一个电路C的深度(记为depth(C)),是指从输入结点到输出结点的最长有向路径的长度。
定义6.1(NC类) 对于一个自然数d,一个语言A在NCd类中,如果A可以由一个电路族{Cn}n∈N判定,其中Cn的规模受n的一个多项式界(即存在某个自然类k,|Cn|=O(nk)),并且depth(Cn)=O(logd(n))。
定义语言类NC=∪d≥1NCd。一个语言A∈NC是指:存在一个自然数d,A∈NCd。
类似地,我们可以定义一致的NCd类,但对应的是对数空间一致性:一个电路族{Cn}n∈N称为对数空间一致的(简称Log S一致),如果存在一台对数空间图灵机M及一个自然数d,对于每一个给定的自然数n,以串1n作为M的输入,机器M输出Cn的描述编码。其中,Cn的规模受n的一个多项式界,并且depth(Cn)=O(logd(n))。
更一般地,一个Log S-一致的NC电路是指:一台对数空间图灵机M,输入串1m=1<n,k,d>,机器M输出 Cn的描述编码,其中 |Cn|=O(nk),depth(Cn)=O(logd(n)),这里m=<n,k,d>为三个自然数n,k,d的编码。有关自然数组编码为一个整数、一个整数解码为一个给定维数的自然数组的编码和解码函数,参见文献[1]。
我们有类似于定理5.4的结论。
定理6.1 一个语言A由一个LogS-一致电路族{Cn}n∈N可计算,当且仅当A∈NC。
基于此,可以仿定义5.1定义一个并行计算模型:
一个带有n个输入节点的并行计算机是由O(nk)节点组成的有向网络图N,每个非源节点对应一个处理器(一个处理器可以视为具有常数界的小型布尔子电路),每个处理器只有常数个扇入,除沉点外的每个处理器的输出端连接到另一个处理器的输入端,对某个自然数d,depth(N)=O(logd(n))。
我们有如下结论:
定理6.2[7]一个语言A可以由一个有效并行算法判定,当且仅当A在NC类中。
一个语言B是P-完全的,简称PC语言,如果B在P语言类中,并且对于任意的P语言A,A≤LB(对数空间归约)。
由于一个对数空间可计算的函数f:Σ∗→{0,1}可以由一个Log S-一致的NC电路模拟计算。因此,计算对数空间归约又称为NC归约。记为A≤NCB。
NC电路形式上是具有多项式级个数的并行处理器,对数多项式级的深度,深度刻画了并行机的计算步数(作为时间复杂性)。因此,NC语言类是P的一个子类。
大数据计算离不开并行计算。因此,NC机可以作为大数据计算的一个基本模型。
但是,实际计算中,并行处理器的个数是一个常数c,即使除去计算过程中的通信时间代价,c台处理器的并行计算系统比串行计算至多提高常数倍效率。
基于这样的分析,我们认为:大数据计算的核心问题是数据复杂性。如何处理数据体量大、结构复杂的问题才是至关重要的环节。
7 带外部信息源的图灵计算模型
经典的问题求解形式上是设计一个算法,将需要求解的问题按一定的数据结构进行编码后作为算法的输入,算法的输出作为问题的求解结果。
在第一节中,我们对大数据计算的基本问题作过简要介绍。对于大数据计算问题,需要求解的问题可以分为两类:任务型和认知型。
大数据的计算是数据集Q作为算法的外部信息源。
鉴于此,我们有理由引入一种带Oracle的图灵机作为大数据计算的计算模型。其中,Oracle译文为“神谕”。意指:有一个超强的外部装置在协助机器进行计算。
形式上,带Oracle的图灵机可由一台图灵机M改造:
(1)在图灵机M上增加一条磁带(称为Oracle带),将外部信息B置放在Oracle带上;
(2)在图灵机M中允许使用“询问”状态,当计算进入询问状态时,机器向外部信息源B询问形如“y∈B?”这样的问题,机器根据给出的回答结果1(Yes)或0(No)进入下一步计算。
改造后的图灵机称为带Oracle的图灵机。
具体一点,如果B被固化在机器上,这样的机器记为MB。注意:B的位置是可以用其它集合替换的。好比一台计算机外挂一个数据库,机器在计算时可以访问数据库。
显然,在实际计算中,对于具体的计算任务x,我们并不需要整个数据库参与计算,只需要访问数据库,根据访问结果参与计算。计算过程中,我们只需要访问方法和地址计算就可以完成计算。
不难理解,这类机器的能力与如下两个因素密切相关:
(1)所带的Oracle B;
(2)计算过程中询问次数控制。
在经典的带Oracle图灵机的计算复杂性中,一次询问“y∈B?”只计一个单位时间。然而,在大数据计算中,这才是真正耗费时间的地方!
因此,如果将大数据计算问题类限制在P类(多项式时间类)中讨论,询问次数自然是多项式界的。对询问“y∈B?”的计算时间度量才是真正要考虑的主要问题。
对于大数据计算问题,目标放在对外部信息源Q的访问和如何访问上。
基本方法和思路:
(1)假想存在一个映射f,将外部信息源Q映射到一个压缩空间Q';
(2)设计访问Q'的方法和计算访问地址;
(3)评价访问代价和误差代价;
(4)评价算法的可靠性。
对于外部信息源Q如何映射到一个压缩空间Q',稀疏表示和特征提取是一种有效途径。原因在于:大数据中真正能为目标任务服务的部分所占比例非常低。如:在压缩感知识中,图像数据在Fourier变换下,较大值座标系数所占比例不到5%[14]。
这里,我们再次重申:大数据是指外部信息源Q。因此,大数据计算问题实质上是“基于某个数据源Q”计算问题。
8 大数据的稀疏表示与特征提取
大数据计算对象数字化编码后表现为一个高维向量x,压缩表示形式上是一个函数f:Rn→Rk,其目的是将高维空间中的对象映射到低维空间,通过映像在研究低维空间中的关系、特征、性质等,去推断原始对象在高维空间中的关系、特征和性质。
一个n维向量是稀疏的,如果它的分量中非零元个数相对于n而言非常小。如:只有O(log(n))个非零元。具体地说,一个高维向量称为k-稀疏的,如果它的非零分量个数不超过 k个,其中k<<n。稀疏向量通常用于近似表示高维向量,直观上是高维向量的特征提取。
对于一个n维向量x→,可以引入不同范数‖x→‖,常用的范数有如下几类:
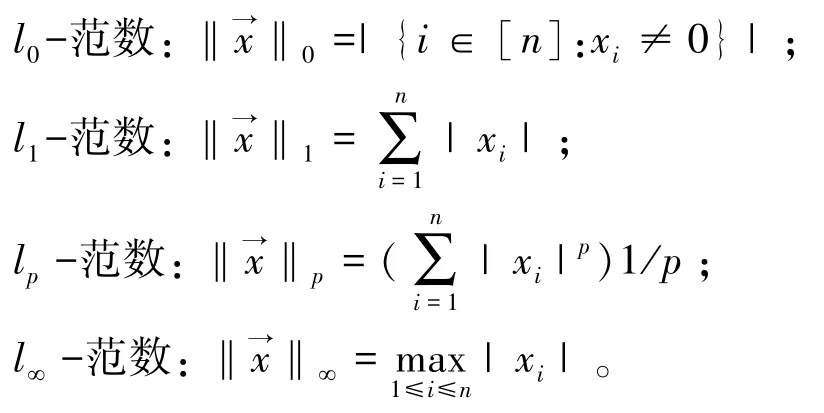
假定A为m×n矩阵(m<<n),b为m维非零向量。如果方程Ax=b有解,则必为非零解。直观上,矩阵A定义一个线性算子A:Rn→Rm(Ax=y),对于b∈Rm,b的一个原像x称为b的一个表示。如果‖x‖0≤m+O(1),则称x为b的一个稀疏表示。
对于矩阵A,定义Spark(A)为满足齐次线性方程组Ax=0非零解中最小l0-范数值,即
Spark(A)=min{‖x‖0:Ax=0,x≠0}。
其实,Spark(A)为A中列向量最小线性相关向量集的大小。事实上,设A=(A1,……,An),如果{Ai1,……,Aik}为A中列向量最小线性相关向量集,由线性相关性,存在一组不全为0的数c1,……,ck,使c1Ai1+……+ckAik=0。由最小性,c1,……,ck均不为0。由c1,……,ck可以生成Ax=0的一个解c,且‖c‖0=k。
容易验证:如果A为一个m×n矩阵A(m<<n),则Spark(A)≤m+1。事实上,设A=(A1,……,An),A中列向量集中任意m+1个向量必定线性相关。从而,Spark(A)≤m+1。
定理8.1 对于给定的A,b,假定x为b的一个稀疏表示,且‖x‖0<,则x为b的唯一稀疏表示。
事实上,假定存在两个b的一个稀疏表示X1,X2(X1≠X2),则A(X1-X2)=AX1-AX2=0。但是,‖X1-X2‖0≤‖X1‖0+‖X2‖0<Spark(A)。此与最小性矛盾。
定理8.2 设A为一个m×n矩阵A(m<<n),b为一个m维向量,如果存在b的表示,则必有稀疏表示存在。
证明:假定b的表示存在,即,方程Ax=b有解。从而,Rank(A,b)=Rank(A)≤m。于是,A中任意m列向量与b构成的向量集必线性相关。设A=(A1,……,An),不妨假定A1,……,Am,b线性相关,则必有m+1个不全为0的数c1,……,cm,cm+1使c1A1+…… +cmAm+cm+1b=0。
进一步,由Rank(A,b)=Rank(A),可以假定cm+1≠0,再由b为非零向量,c1,……,cm中至少有一个不为0。于是,取(c1,……,cm,0,....., 0),x为b的一个表示,且x为b的一个稀疏表示。
注:定理8.2提供了一个寻找稀疏表示的一种方法。
定理8.3 设A为一个m×n矩阵A(m<<n),b为一个m维向量,如果Rank(A)=m,则存在b的稀疏表示。
证明:设Rank(A)=m,则m维向量集中(A1,……,An)有 m个向量线性无关。不妨设 (A1,……,Am)线性无关,则(A1,……,Am,b)必定线性相关,并且b可由(A1,……,Am)线性表示。即,方程Bx=b有非零解c,其中B=(A1,……,Am)。由c生成b的一个解x,且‖x‖0≤m。从而x为b的一个稀疏表示。
经典的稀疏向量的求优问题有三两类:
稀疏问题(Sparse Problem)(简称SP问题): min‖x‖0subject to Ax=b。
基追踪(Basis Pursuit)(简称BP问题):
min‖x‖1subject to Ax=b。
Lasso问题:
min‖Ax-b‖1subject to‖x‖1<λ。
SP问题是一个NP难问题,有关稀疏表示的基础理论和应用,请参见文献[14,15]。
大数据满足稀疏表示的假设:利用少量分量足以表示(或近似表示)原始对象。如何获取这部分少量的“有用”分量具有很多成熟的方法。如:统计学习方法[16],深度学习方法[17]等。
大数据特征提取的目标是想用少量数据表达复杂数据,数据挖掘则是寻求数据间的特征关联性。无论出于什么样的目的,都是在为计算和分析提供小数据表达。
大数据计算的前期预处理必须解决如下两个基本问题:
(1)数据从“大”到“小”的预处理;
(2)数据的“非结构”到“结构”的预处理。
对于问题(2)主要是给出一种规范的数字编码技术。从计算的角度而言,主要针对问题(1)。
因此,大数据可计算的核心问题是:如何将数据从“大”到“小”进行处理,使得算法在时间上可承受,而又不丢失原始数据所表达的信息。
定义8.4 设x为一个n维向量,0<ε<1,k<<n,如果‖x-x'‖p≤ε,x'是一个k-稀疏的n维向量,则称x'是在p-范数下x的(k,ε)-稀疏。
一个n维向量x在p-范数下可以(k,ε)-稀疏的,如果存在一个k-稀疏的n维向量x',使得‖x-x'‖p≤ε。
特别,取p=2,简称向量x是可以(k,ε)-稀疏的。更进一步,如果k=O(logi(n))(对某个正整数i),ε是某个约定的充分小的数。我们简称x是可对数稀疏的。
定义8.5 设Q为一个n维向量的数据集,如果Q中任一个向量都是可对数稀疏的,则称Q是可对数稀疏的。
有关高维数据处理与分析的理论和方法,请参见文献[18]。
9 大数据的可计算性
我们现在开始触及大数据的可计算性问题,并回答什么才叫大数据可计算?
从计算理论的角度,可计算性依赖于一个给定的计算模型。由于我们己经界定大数据的可计算限制在P类中讨论。因此,大数据的可计算性还与复杂类选择相关。
基于前面几节中对大数据计算的特点讨论。我们引入“带Oracle的图灵机,对数空间可计算”作为大数据的计算模型。
本节从引入任务型大数据计算的概念出发,引入大数据可计算和大数据可判定问题。直观上,我们要求对外部信息源Q(Q⊆Σ∗)的访问必须满足两个条件:
(1)对Q的访问是能行的。
(2)对Q的访问能在对数空间可计算内完成。
为此,对于条件(1),假定Q是一个递归可枚举集[1],即有一个递归函数q(·)枚举Q中的元素;对于条件(2),还要求枚举函数q(·)在对数空间内可计算。
我们称满足条件(1)(2)的外部信息源Q为对数空间可枚举集。记为:LogS.r.e.集。
本节的Q均假设为LogS.r.e.集。
定义9.1 设Q(Q⊆Σ∗)为一个LogS.r.e.数据集,x∈Σ∗(|x|=n),如果存在一台带Oracle的图灵机M,以Q作为Oracle(外部信息源)附着在M上,以x为输入,机器MQ在n的对数空间内能够完成对x的计算,则称任务型实例 <Q,x>大数据可计算。简称 <Q,x>为BD可计算。
基于定义9.1,对一个任务描述x,可以引入“对x的大数据可计算”概念如下:
定义9.2 设x∈Σ∗,如果存在一个LogS.r.e.数据集Q⊆Σ∗,使得 <Q,x>BD可计算,则称x大数据可计算。简称x为BD可计算。
基于定义9.2中BD可计算概念,对一个任务集A,引入“对A的大数据可计算”概念。
定义9.3 设A⊆Σ∗为一个语言(用于描述一个任务集),如果对任意的x∈A,x大数据可计算,则称A大数据可计算。
请注意,在定义9.3中,不同的x可能关联调用不同的外部信息源Q,也有可能启用不同的图灵机M。为此,我们引入如下一致计算概念。
定义9.4(外部信息源一致的大数据可计算) 设A⊆Σ∗为一个语言(用于描述一个任务集),Q⊆Σ∗为一个LogS.r.e.数据集,如果对任意的x∈A,<Q,x>大数据可计算,则称A关于外部信息源Q是一致大数据可计算。简称A是Q一致大数据可计算。
此隐含:即使外部信息源Q是公用的,但不同的x还有可能调用不同的机器M(算法,软件)。
进一步,我们引入一个更强的一致性。不但关于外部信息源一致,而且要求关于机器M(算法,软件)一致。
定义9.5(一致的大数据可计算) 设A⊆Σ∗为一个语言(用于描述一个任务集),如果存在一个公共的LogS.r.e.数据集Q,以及一台带Oracle的图灵机M,使得对任意的x∈A,<Q,x>在公共图灵机M下大数据可计算,则称A是一致的大数据可计算。
至此,我们可以引入大数据可判定问题。
一个函数f:Σ∗→Σ∗是大数据可计算函数,如果存在一台带Oracle的图灵机M,以及一个LogS. r.e.外部信息源Q,对于任意一个输入x∈Σ∗,机器MQ在对数空间内对x进行计算,并输出函数值y=f(x)。特别注意:这里的对数空间只计图灵机的工作带上的空间。
定义9.6(大数据可判定问题) 设A⊆Σ∗为一个语言(对应一个判定问题),如果其特征函数χA: Σ∗→{0,1}是大数据可计算函数,则称语言A是大数据可判定的。
换言之,如果存在一台公共的带Oracle的图灵机M和一个公共的对数空间可枚举的外部信息源Q,机器MQ在对数空间内对x进行计算,并对x是否在A中作出回答。
在本文中,我们以“对数空间可计算的带Oracle的图灵机”作为模型给出了大数据可计算和大数据可判定概念。
在实际应用中,为处理输入端的描述、以及对外部信息源的访问计算,可以对图灵机加以改造、变形,以适应实际问题的解决。如:概率计算模型(BPP机,RP机),概率可验证模型PCP机计算模型等,对其加以“对数空间计算”的限制,都可以得到应用。有兴趣的读者可以参见文献[7,8]。
此外,可以将对数空间可枚举的外部信息源Q区分为静态数据源和动态数据流,考虑大数据的离线计算和在线计算等问题。
10 结语
本文从计算理论的角度讨论了大数据计算的某些基础理论问题。大数据计算远比经典计算复杂,在经典计算中,重点是在研究算法及其时间复杂性,对前端输入的数据复杂性不做分析,而大数据计算中,前端输入的数据复杂性反而成为大数据计算的主要问题。
追加数据复杂性带来的额外时间开销,考虑整个算法时间上的承认能力,大数据计算限制在经典计算复杂性意义下的多项式时间复杂类中考虑。对数空间复杂类作为成为多项式时间复杂类的一个重要子类,它涵盖了并行计算复杂类,从而大数据计算体现的并行计算要求自然也在其中。
大数据计算问题实质上是依赖于一个对数空间可枚举(LogS.r.e.)外部信息源Q的计算,我们将需要求解的问题分为两类:目标任务型和内容认知型。本文重点讨论了前者,并引入了大数据可计算概念:基于带外部数据源,并在对数空间内的图灵可计算。
本文引入的大数据可计算的计算模型是带Oracle(外部信息源)的图灵计算模型。其中要求:
(1)图灵机本身是对数空间可计算;
(2)对外部信息源的访问可以在对数空间可计算内完成。形式上,外部信息源集Q可以用一个对数空间可计算的递归函数枚举。
这种计算模型称为“双对数”图灵计算模型,简称为LL-型图灵计算模型。
基于大数据可计算的基本概念,我们引入了大数据可计算性和大数据可判定问题。当然,更多的工作还需要更深入细致的研究,特别是“指数级压缩、对数级算法”方面的具体算法的设计与分析是我们下一步的努力方向,部分数学工具可能会用到量子计算的理论和方法[19,20]。
[1]N Cutland.Computability——An Introduction to Recursive Function Theory[M].Cambridge:Cambridge University Press,1980.
[2]R ISoare.Recursively Enumerable Sets and Degrees——A Study of Computable Functions and Computably Generated Sets[M].Berlin Heidelberg:Springer-Verlag,1987.
[3]M Sipser.可计算理论导引[M].张立昂,等译.北京:机械工业出版社,2000.
[4]M Davis.可计算性与不可计算性[M].沈泓,等译.北京:北京大学出版社,1984.
[5]E Artin.Galois理论[M].李同孚,译.哈尔滨:哈尔滨工业大学出版社,2011.
[6]R柯朗,H罗宾.什么是数学(第三版)[M].左平,等译.上海:复旦大学出版社,2012.
[7]S Arora,B Barak.Computational Complexity——A Modern Approach[M].Cambridge:Cambridge University Press,2009.
[8]堵丁柱,葛可一,王浩.计算机复杂性导论[M].北京:高等教育出版社,2002.
[9]连玉明.块数据[M].北京:中信出版集团,2015.
[10]连玉明.块数据2.0[M].北京:中信出版集团,2016.
[11]耿素云,屈婉玲.离散数学[M].北京:高等教育出版社,2004.
[12]D PWilliamson,D B Shmoys.The Design of Approximation Algorithms[M].Cambridge:Cambridge University Press,2011.
[13]陈国良,陆克中,毛睿.大数据计算理论基础(PPT报告) [EB/OL].http://wenku.baidu.com,2014.
[14]SFoucart,H Rauhut.AMathematical Introduction to Compressive Sensing[M].Heidelberg,Dordrecht London:Springer New York,2010.
[15]徐勇,范自柱,张大鹏.基于稀疏算法的人脸表示[M].北京:国防工业出版社,2014.
[16]T Hastie,R Tibshirani,JFriedman.统计学习基础[M].范明,等译.北京:电子工业出版社,2007.
[17]IGoodfellow,Y Bengio,A Courville.Deep Learning[EB/OL]. http://www.deeplarningbook.org.
[18]JHopcroft,R Kannan.Computer Science Theory for the Information Age[M].上海:上海交通大学出版社,2013.
[19]M A Nielsen,IL Chuang.量子信息与量子信息[M].赵千川,译.北京:清华大学出版社,2004.
[20]李士勇,李盼池.量子计算与量子优化算法[M].哈尔滨:哈尔滨工业大学出版社,2009.
(责任编辑:周晓南)
Investigation of Basic Theory in Big-Data Computations
XU Daoyun∗
(College of Computer Science and Technology,Key Lab of Public Big Data of Guizhou Province,Guizhou University,Guiyang 550025,China)
In classical computations,it don'tneed to analyze the data complexity of inputs in algorithms,butanalyzing data complexity of inputs in big-data computations becomes key problems.Some basic theories of big-data computationswere investigated,and computations were classified into objective-task and context-recognition types.The big-data computations depend formally on some external information sources.For effectiveness of computations,restrict complexity of big-data computations was restricted to classes of computable problems in logspace,which contains the class of parallel computations.The computationmodel,big-data computability and decidability were introduced based on Turingmachine with oracles in log-space,where the information sources as oracle is a recursive enumerable set that is computable in log-space.
big-data computation;computability in log-space;parallel computability;turingmachine with oracles;computability for big-data
O171
A
1000-5269(2016)04-0001-11
10.15958/j.cnki.gdxbzrb.2016.04.01
2016-06-08
国家自然科学基金项目资助(61262006)
许道云(1959-),男,教授,博士生导师,研究方向:可计算性与计算复杂性,分析中的可计算性,算法设计与分析,Email:dyxu@gzu.edu.cn.
∗通讯作者:许道云,Email:dyxu@gzu.edu.cn.
