基于频谱建模合成技术的自动音调修正系统*
2016-12-13杨楠
杨 楠
(华中科技大学电子信息与通信学院 武汉 430074)
基于频谱建模合成技术的自动音调修正系统*
杨 楠
(华中科技大学电子信息与通信学院 武汉 430074)
保留音色的音调修正问题一直是困扰音乐类应用发展的技术难题。论文结合自动修音的应用需求,实现了一套基于频谱建模合成(Spectral Modeling Synthesis,SMS)技术的自动音调修正系统。它通过清浊音判决和音调检测来实时提取歌声的音调(音高),并与正确的参考音调(乐谱)进行对比,确定需要修正的跑调部分,最后采用论文提出的一种基于SMS技术的合成方法对歌声进行音调修正,通过保留其原有的频谱包络来确保修正后音色不变。论文对系统的清浊音判决算法和音调检测算法进行了客观评价,对歌声音调修正效果进行了主观听音评价,均达到了良好的效果。
音调修正; 频谱建模合成; 清浊音判决; 音调检测
Class Number TN912.33
1 引言
中国互联网络信息中心2015年报告显示,网络音乐目前是中国网民的第四大网络应用。在各种音乐类应用中,以“唱吧”、“全民K歌”等为代表的K歌类移动应用异军突起,并在短期内发展到上亿用户规模。但是,与国外同类应用(如:“Sing for Singapore”、“Vocal Transformer Karaoke”)相比,国内的应用仅提供去噪、混响等简单的声音修饰功能,普遍缺少音调修正这样的高级功能。由于保留音色的音调修正问题一直是该领域的技术难题,本文结合自动修音的应用需求,提出了一种基于SMS技术的合成方法,并实现了一套融合清浊音判决、音调检测、音调修正与合成等环节的自动音调修正系统。
早期的音调修正主要有时域和频域两类方法[1]。时域方法以时域基音同步叠加(Time Domain Pitch Synchronous Overlap and Add,TD-PSOLA)为代表,它是由Charpentier和Stella在1986年提出[2],主要用于语音合成,但也可以用于修改音调。它是通过调整时域中帧与帧的重叠范围来改变声音的基音周期长度,从而起到调整音调的效果。由于时域中原始信号的大部分形状得以保留,所以音色特征在音调修正后基本保持不变。但是,由于帧与帧重叠范围的变化会引起时延的改变,连续帧间各频率分量的相位连续性会被破坏,音调变化较大时会出现比较明显的回声效应。此外,降调幅度足够大时,各帧信号不再重叠,会破坏信号的连贯性。
音调修正的频域方法主要是改进相位声码器(Modified Phase Vocoder)方法,它是由Laroche和Dolson在1999年提出[3],主要通过频谱搬移对声音进行修改,同时调整各频率段的相位以保持相位连续性。与时域方法相比,它允许较大幅度的音调修正。但是,改进相位声码器方法的一个显著的缺点是它改变了音色,被修正后的声音与演唱者的声音会有一定的差异。
语音学中,共振峰表示声道声学共振产生的频谱最大值的频率范围,共振峰频率和带宽的细微变化反映了歌手声道的物理特征和歌手的个人音色[4]。因此,在保留音色的前提下对音调进行修正的问题可以转化为这样一个抽象问题:保持声音信号共振峰不变的前提下,修正各谐波分量的频率并保证相位的连续性。
频谱建模技术可以有效解决上述问题,它将声音建模为频率分量的和,且用振幅和频率函数来实现声音信号的参数化描述,从而可以更直观、灵活地操纵各频率分量的频率、相位以及振幅。加法合成技术和SMS技术是此类方法的代表。加法合成技术是将信号建模为一系列正弦的和,但是不适用于表示类噪声信号。Serra和Smith 1989年提出的SMS技术加入了表示噪声的随机分量[5],更符合人声建模。Di Federico和Drioli 1998年首次提出将SMS技术应用于音调修正的设想,但是未见其实现细节[6]。此外,Azarov等在2013年还提出了能进一步描述子谐波分量的GUSLY模型[7],该模型对频谱的建模更加细致,实现起来也比SMS复杂得多。
综合可行性和复杂度等因素的考量,本文采用SMS技术来实现自动音调修正功能,并设计了一套完备的系统实现框架。该框架主要包括音调分析和音调修正两部分,系统框架图如图1所示。

图1 自动音调修正系统框架图
2 频谱建模合成技术
SMS技术是音调修正功能的核心,它是一种基于确定加随机模型的声音分析/合成技术,它具体包含确定加随机模型、分析以及合成等三个组成部分。
2.1 确定加随机模型
SMS技术假定输入的声音由确定分量加随机分量组成。其中,确定分量限定为一系列准正弦信号的和,每个正弦建模声音信号的一个窄带分量,随机分量即噪声信号。因此,声音信号被表示为
(1)
其中,Ar(t)和θr(t)分别为第r个正弦分量的瞬时振幅和瞬时相位;e(t)为t时刻的噪声分量。瞬时相位是瞬时频率ωr(t)的积分:
(2)
2.2 分析部分
SMS技术的分析部分是将声音信号用一系列模型参数描述,其中确定分量的参数是在频域估计得到的。确定分量的分析流程如图2所示: 1) 对输入的声音信号分帧、加窗、进行傅里叶变换,得到各帧信号的频谱; 2) 峰值检测,即提取信号幅值频谱中的显著局部最大值; 3) 峰值延续,即将检测到的峰值的子集组成一系列峰值轨迹,每个轨迹表示输入的声音信号中一个稳定的正弦分量。
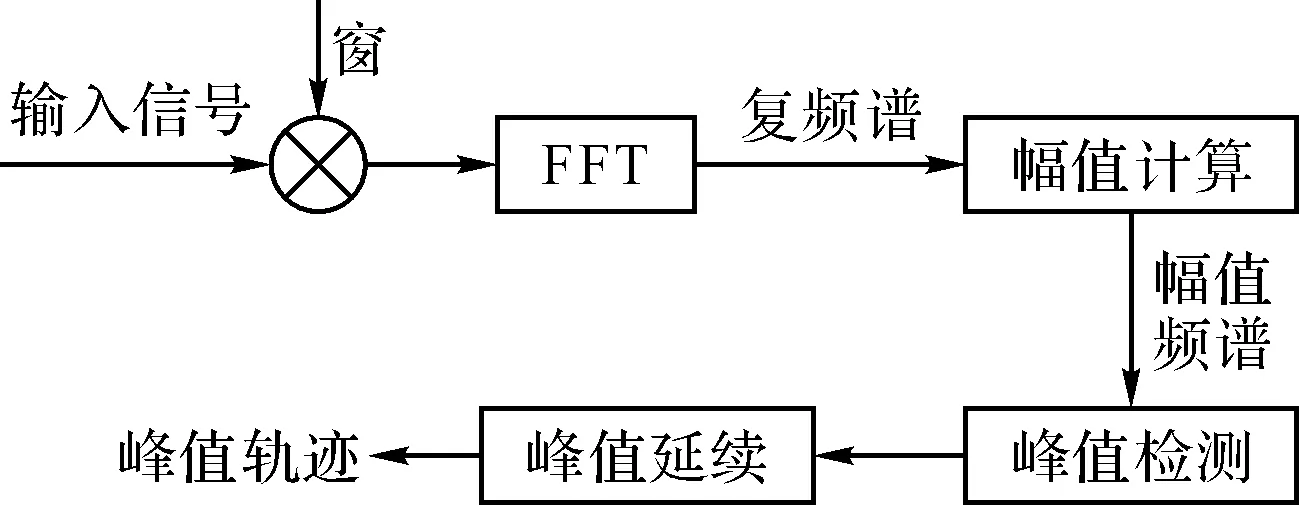
图2 确定分量分析流程图
•峰值检测
根据信号频谱分析的原理,幅值频谱中的各显著峰值近似对应信号中的各正弦分量。由于DFT的栅栏效应,各显著峰值对应的频率是信号中实际正弦分量频率的近似值。一种标准的解决方案是对峰值附近幅值最大的三个点(一般取峰值及其左右相邻点)进行抛物线拟合,并用抛物线顶点(最大值)对应的频率作为正弦分量频率的估计值。已知信号为一个纯正弦波、分析窗为高斯窗、幅值频谱用dB表示时,该方案能得到精确的正弦分量频率。
•峰值延续
峰值延续可以理解为线检测问题。对于谐波结构的声音,如果检测到当前帧的基频,寻找距离基频对应的各次谐波频率最近的显著峰值,从而确定每一帧中各峰值轨迹上的峰值。
随机分量的分析流程如图3所示: 1)根据确定分量分析得到的峰值轨迹,利用加法合成技术,合成确定分量; 2) 计算确定分量的频谱,计算方法与原始声音的相同; 3) 采用频域减法,从原始声音的幅值频谱中减去相应的确定分量的幅值频谱,得到残余部分的幅值频谱; 4) 采用线段逼近方法,获取残余部分幅值频谱的包络。随机分量即用这些频谱包络表示。

图3 随机分量分析流程图
2.3 合成部分
SMS技术的合成部分与分析部分的功能相反,它通过确定加随机模型的参数合成出新的声音信号。具体流程如图4所示: 1) 根据各峰值轨迹的振幅、频率参数,采用加法合成技术生成各帧信号的确定分量的时域表示; 2) 根据随机分量的频谱包络合成其幅值频谱,并用随机数生成器产生其相位谱,合成复频谱,并采用逆傅里叶变换生成各帧信号的随机分量的时域表示; 3) 利用重叠相加技术合成完整的信号。
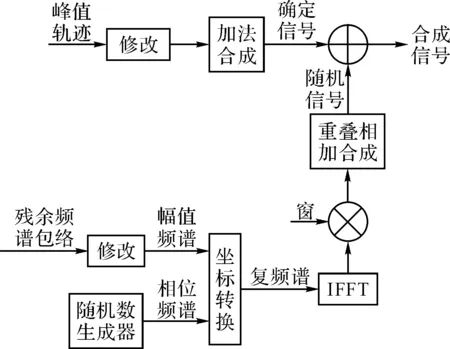
图4 SMS技术合成部分流程图
3 音调修正系统
一个完整的音调修正系统框架如图5所示。一个完整的音调修正系统除了音调修正部分以外,音调分析部分也同样重要。它先通过清浊音判决算法从音频信号中提取出有效的浊音信号(浊音信号才有音调,清音信号没有音调),然后对浊音信号进行音调检测,并将分析结果与歌曲的标准音调(乐谱)进行对比,从而驱动后续的音调修正功能。

图5 自动音调修正系统流程图
3.1 标准音调
标准音调是自动判别歌声跑调的参考依据。由于一首歌的旋律是固定的,所以可以根据歌曲的乐谱人工制作标准音调数据,记录各音符的信息。它们可以以规定的文件形式存储,并由音调修正系统在初始化时载入。标准音调的文件格式一般是一行对应一句歌词,行内格式为
[TSi,DSi]〈TWi1,DWi1,Pi1〉字i1…〈TWij,DWij,Pij〉字ij…
(3)
其中,TSi、DSi分别为第i句歌词的开始时刻和持续时间,TWij、DWij、Pij、字ij分别为第i句歌词中第j个音符的开始时刻、持续时间、标准音调MIDI值和对应的歌词,时间的单位均为ms。如张震岳的《爱我别走》中第一句歌词可以记录为
[24333,2334]〈24333,334,67〉我〈24667,333,67〉到〈25000,333,67〉了〈25333,334,67〉这〈25667,333,67〉个〈26000,333,67〉时〈26333,334,67〉候
虽然人工制作标准音调文件比较费时,但是操作起来简单有效。当然还有其它提供标准音调的方法,如从MIDI文件读取或用MIDI音序器写入、从专业歌手演唱的相同歌曲的音频中提取等,这又属于另外的研究领域,这里不做赘述。
3.2 清浊音判决
清浊音判决又被称为浊音/清音/无声分类,它是后续音调分析及修正的前提。清浊音判决方法有很多,常见的清浊音判决方法大多将语音信号的特征参数作为判决的标准。常用的特征参数包括短时过零率、短时能量以及线性预测编码得到的参数。
本文采用结合信号的短时平均过零率和短时平均能量进行清浊音判决。浊音信号的能量主要集中于3kHz以下,平均过零率相对较低;清音信号的能量主要集中于较高频率,平均过零率相对较高。因此,过零率可用于清浊音判决。另外,浊音段的短时平均能量一般比清音段的或背景噪声的大得多。
将短时平均过零率Zn和短时平均能量En分别单独作为特征参数进行清浊音判决时,两种方法各有优缺点。将两个参数结合起来,可以提高清浊音判决的准确性[8]:对于一帧语音信号,如果Zn和En值都为零或者都很小,判定该帧为无声信号;如果Zn值较小,但是En值较大,判定该帧为浊音信号;如果Zn值较大,但是En值较小,判定该帧为清音信号。
此外,需要先设置清浊音判决时短时平均过零率和短时平均能量的阈值。对于浊音语音,短时平均过零率的均值约为14过零/ms;对于清音语音,约为49过零/ms。对于短时平均能量,一种阈值设置方法是以整段音频的短时平均能量均值作为参考。
3.3 音调检测
音调检测的相关研究也有许多,为了控制系统整体的计算量,本文采用了双向错位(Two-WayMismatch,TWM)基频估计方法[9]。TWM基频估计方法是基于信号的短时频谱分析实现的。它的原理为:基于输入的歌声信号的准谐波假设,对于每个基频候选,在一个固定的泛音的子集上,计算对应的各次谐波理想频率和实际测量得到的各泛音频率的差异,即错位误差。选取使错位误差最小的基频候选作为基频的估计值。此外,为了避免基频估计值为实际基频的约数或整数倍,进行双向错位误差计算。
双向错位误差的计算公式为
(4)
其中,Errm-p为检测-预测错位误差,Errp-m为预测-检测错位误差。
检测-预测错位误差的计算公式为
×[q×Δfk×(fk)-p-r]
(5)
其中,K为测量得到的泛音(包括基频)的数目,Δfk为第k次泛音与理想谐波频率序列中频率最近值的差值,fk和ak分别为第k次泛音的频率和振幅,Amax为测量得到的各泛音振幅的最大值,p、q、r分别为0.5、1.4、0.5。
预测-检测错位误差的计算公式为
×[q×Δfn×(fn)-p-r]
(6)
其中,N为最大理想谐波次数,Δfn为第n次谐波的理想频率与测量的泛音频率序列中频率最近值的差值,fn为第n次谐波的理想频率,an为与第n次谐波的理想频率最近的测量的泛音频率对应的振幅。
对于各帧信号,将给定的歌声最小基频值和最大基频值间的各频谱峰值的频率作为基频候选。如果连续帧的基频相对稳定,可以进一步缩小基频候选的频率范围以减少计算量。此外,为了减少非浊音帧对邻近浊音帧音调检测结果的影响,将歌声信号划分为多个浊音段,对每个浊音段分别进行音调检测。
3.4 音调修正
将SMS技术应用于音调修正,主要是修改SMS技术分析得到的歌声信号的振幅、频率和相位参数,然后合成音调修正了的歌声信号。为了尽可能地保留音色,音调修正过程中要保持共振峰及频谱包络不变。具体步骤如下:
1) 修改频率参数,使各峰值轨迹上峰值的频率为目标音调的理想谐波频率。
2) 为尽量保留原始歌声的音色不变(各帧的频谱包络不变),各峰值频率变换后,需要对其振幅进行修正。用幅值频谱中各峰值轨迹上的峰值线性连接表示频谱包络。对于变换后得到的各峰值,在原始信号的频谱包络上线性插值得到对应的振幅。
3) 为了保持音调修正后各次谐波的相位在帧间的连续性,修改各峰值的相位。对于信号中的第一帧,各峰值的初相位取0~2π间均匀分布的随机数即可。对于后续各帧信号,使连续帧间各峰值的初相位满足相位连续。
算法实现过程中发现,如果对每一段需要音调修正的连续帧分别进行音调修正,由于修音段与未修音段衔接处的不连续性,会产生较为明显的人为噪声。而如果对整段音频进行音调修正,因为SMS技术需要较为复杂的分析、合成计算,系统整体的计算量会比较大,处理时延会显著增加。为减小上述不连续性的影响,选择对每一个包含需要音调修正的帧的浊音段进行音调修正。
4 系统评测
本文采用了业内普遍使用的方法对自动音调修正系统进行了全面评测:在音调分析的部分,采用标准的误差指标客观评价清浊音判决算法和音调检测算法的准确性;在音调修正的部分,采用主观评价方法[7]评价修正后的音色效果。
4.1 客观评价
选用MIR-1K for MIREX数据集,从中随机选取10个音频,并采用四个标准的误差指标清浊音判决误差(Voicing Decision Error,VDE)、严重音调误差(Gross Pitch Error,GPE)、正确音调平均误差(Mean Fine Pitch Error,MFPE)和基频帧误差(F0 Frame Error,FFE)[10]进行客观评价,结果如表1所示。
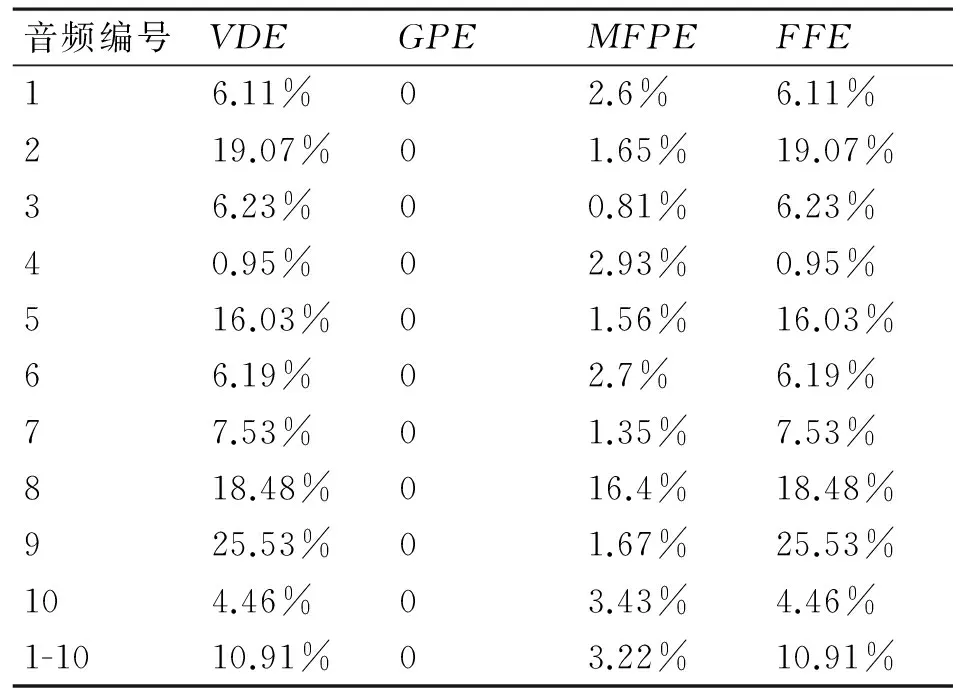
表1 客观评价结果
表中最后一行是所有测试音频的综合评价结果。总体来看,所有测试的GPE为0且MFPE较小,仅为3.22%,说明本文实现的音调检测算法的准确性较好。由于GPE为0,所以评价音调分析的整体误差的FFE与清浊音判决误差VDE相等,说明本文音调分析的整体性能主要由清浊音判决的算法决定。而本文选用的清浊音判决算法VDE值比较大,并且对于不同的音频文件VDE值波动较大,说明该算法还不是很理想,后续还有很大的改善空间。
4.2 主观评价
对于音调修正效果的评价一般采用主观评价方法,本文采用的是主观对比平均意见得分(Comparison Mean Opinion Score,CMOS)方法。选用两首中文流行歌曲,分别由一位男性非专业歌手和一位女性非专业歌手多次录制,得到纯人声音频。从中挑选测试片段,以评价不同音调修正幅度下该系统的性能。对于男声演唱的歌曲,由于其音调一般相对较低,为达到较为明显的观察效果,分别选取包含偏离标准音调2个半音或3个半音的音符的片段。对于女声演唱的歌曲,由于其音调一般相对较高,分别选取包含偏离标准音调1个半音或2个半音的音符的片段。因此,一共有8个测试片段。各个测试片段中包含的需要音调修正的音符与标准音调的偏差如表2所示。

表2 测试片段信息
分别邀请四个受过专业音乐培训的同学和四个非专业的同学参与主观评价。对于各测试片段,将基于SMS技术的自动音调修正系统的输出音频分别与源音频和改进相位声码器算法的输出音频进行对比。对于两音频A和B,要求各同学对比A和B后决定“A比B好很多/好/好一点/几乎相同/差一点/差/差很多”,其对应的得分分别为3、2、1、0、-1、-2和-3。实验结果如表3所示。
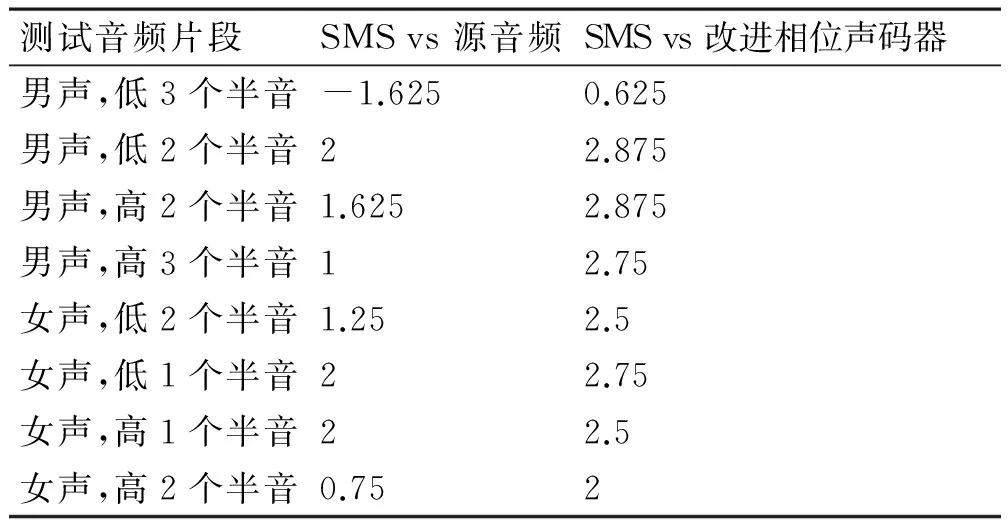
表3 主观评价结果
表3结果表明:基于SMS技术进行音调修正后,得到的歌曲音频一般比源音频要好听一些(由于音调修正的缘故),但是变调幅度较大时,音调修正效果的评价也在降低,但评分仍然维持在正数区间。此外,在大部分情况下,基于SMS技术的音调修正算法要比改进相位声码器算法的修正效果好,与前面的理论分析结果一致。
5 结语
本文实现了一套基于SMS技术的自动音调修正系统。它通过清浊音判决和音调检测来实时提取歌声的音调,并与人工制作的标准音调文件提供的音调信息进行对比,最后采用本文提出的一种基于SMS技术的合成方法对跑调部分进行音调修正并保持其原有音色不变。实验结果表明,该系统能提供较好的音调修正效果。
[1] Peimani M A. Pitch Correction for the Human Voice[D]. Santa Cruz: Thesis of California University, 2009.
[2] Charpentier F J, Stella M G. Diphone synthesis using an overlap-add technique for speech waveforms concatenation[C]//Acoustics, Speech, and Signal Processing, IEEE International Conference on ICASSP’86. IEEE,1986,11:2015-2018.
[3] Laroche J, Dolson M. Improved phase vocoder time-scale modification of audio[J]. Speech and Audio Processing, IEEE Transactions on,1999,7(3):323-332.
[4] Kim Y E. Singing voice analysis, synthesis, and modeling[M]. New York: Handbook of Signal Processing in Acoustics, Springer,2008:359-374.
[5] Serra X, Smith J. Spectral modeling synthesis: A sound analysis/synthesis system based on a deterministic plus stochastic decomposition[J]. Computer Music Journal,1990,14(4):12-24.
[6] Di Federico R, Drioli C. An integrated system for analysis-modification-resynthesis of singing[C]//Systems, Man, and Cybernetics, 1998. 1998 IEEE International Conference on. IEEE,1998(2):1254-1259.
[7] Azarov E, Vashkevich M, Petrovsky A. Instantaneous harmonic representation of speech using multicomponent sinusoidal excitation[J]. Analysis,2013,2(3):3.
[8] 刘波,聂明新,向俊涛.基于短时能量和过零率分析的语音端点检测方法研究[J].2007. LIU Bo, NIE Mingxin, XIANG Juntao. Research on endpoints detection of speech signal based on short-time energy and zero-crossing counts [J]. 2007.
[9] Maher R C, Beauchamp J W. Fundamental frequency estimation of musical signals using a two-way mismatch procedure[J]. The Journal of the Acoustical Society of America,1994,95(4):2254-2263.
[10] Babacan O, Drugman T, d’Alessandro N, et al. A comparative study of pitch extraction algorithms on a large variety of singing sounds[C]//Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on. IEEE,2013:7815-7819.
An Automatic Pitch Correction System Based on Spectral Modeling Synthesis Technique
YANG Nan
(School of Electronic Information and Communication, Huazhong University of Science and Technology, Wuhan 430074)
Pitch correction with preservation of timbre has been a difficult technical issue that hinders the development of music applications. To address this problem, a spectral modeling synthesis (SMS) based automatic pitch correction system is proposed. It extracts the pitch contour in real time with voiced/unvoiced decision and pitch detection. The extracted pitch contour is then compared with the reference pitches such that the detuned parts can be determined. Finally, the proposed SMS based method is applied to the voice to correct the pitches, preserving the timbre by preserving the spectral envelop. Experimental results suggest that the proposed system can provide good pitch correction effect.
pitch correction, spectral modeling synthesis, voiced/unvoiced decision, pitch detection
2016年5月3日,
2016年6月27日
“十二五”科技支撑计划项目(编号:2014BAK15B04)资助。
杨楠,女,硕士研究生,研究方向:音频信号处理。
TN912.33
10.3969/j.issn.1672-9722.2016.11.016
