基于社交网络和协同过滤的微博好友推荐算法
2016-12-13汪毓铎黄太波
汪毓铎,黄太波
(北京信息科技大学 信息与通信工程学院,北京 100101 )
基于社交网络和协同过滤的微博好友推荐算法
汪毓铎,黄太波
(北京信息科技大学 信息与通信工程学院,北京 100101 )
微博作为近年来用户数量较多的社交应用,其用户的信息压力也相对较大,推荐技术对于微博用户的体验和推广有很明显的帮助.本文将针对微博平台的好友推荐进行研究,分别采用基于社交网络分析和基于协同过滤技术的推荐算法.经过两种算法的实验对比得出结论:基于协同过滤的好友推荐算法具有较好的性能,在推荐好友数量较多的情况下依然具有较高的综合评价指标,提高了好友推荐的质量.
推荐技术;微博;社交网络;协同过滤
随着微博用户人数的增加,用户发布的微博量更是不计其数,信息量的急剧增长导致人们越来越难获取到自己真正感兴趣的内容,这就是所谓的信息过载效应[1].解决信息过载的手段主要有搜索技术和推荐技术.相比搜索技术,推荐技术具有更好的过滤效果、灵活性及推广能力,因此被广泛应用于各大电商门户网站及手机APP,如国内的淘宝网、京东网及国外的Amazon等.互联网和移动终端设备的飞速发展,导致用户对于社交网络服务的需求也呈现急剧增长的趋势.网络社交已经成为人们日常生活中的重要组成部分.在国外著名的社交网站主要有Facebook和Twitter等;在国内著名的社交网站主要有新浪微博、腾讯微博和人人网等.目前新浪微博的用户总数量和用户活跃数量均为国内同类产品之最,本文选择新浪微博作为好友推荐的研究平台.
在微博社交网络中,用户获取自己感兴趣的用户主要有以下几种方式:1)通过自己感兴趣的微博内容来关注发布此内容的用户,但在海量的信息中,通过这种方式来寻找自己感兴趣的用户并不容易;2)通过设置不同特征条件对所有微博用户进行检索,这种方式往往会返回大量的结果,使用户无法进行甄别和选择;3)由微博运营平台推荐好友,目前主要的推荐方式为给目标用户推荐其好友最近关注的用户,这种推荐方式相对比较简单和盲目,其效果并不理想.因此,如何从海量的微博用户中,挖掘出目标用户感兴趣的用户,并精准地推荐给目标用户,是微博推荐系统中的一个很有意义的研究内容.在微博推荐领域,已有许多人展开研究并获得一定成果.比如根据用户关注的群体来推测用户的偏好,或者根据用户的评论和参与的话题来预测用户的关注点,然后为其推荐可能感兴趣的用户及话题[2-3].
在具有社交功能的应用场景里,用户推荐是很重要的功能之一.目前微博用户的推荐方法主要有以下几种: 1)社交网络推荐一般都是通过对用户好友的关注关系网进行分析并推荐,由于用户与其好友的关系建立并不都是基于共同兴趣,因此推荐准确率较低;2)基于内容的推荐不依赖于用户的评分数据,而是根据用户的历史行为来判断是否对用户进行推荐,在动态预测推荐方面具有优势;3)协同过滤推荐是推荐系统中最常用的方法,通过用户之间的评分数据来进行相似度计算进行推荐,具有良好的操作性及推荐效果,被广泛应用于各大网站;4)混合推荐将多种推荐算法应用于推荐系统中,可以使不同推荐算法的优点结合起来进行推荐,具有良好的推荐效果.
协同过滤是利用与用户兴趣行为相似的最近的邻居的偏好信息向当前用户产生推荐结果,以解决用户所面临的信息过载的问题[4].协同过滤这一概念最先由Goldberg[5]等提出,并将其应用于基于协同过滤的推荐系统Tapestry中,这是一个邮件处理系统,用来帮助用户从每天接收的大量邮件中筛选和分类邮件.在协同过滤推荐算法中,有很重要的一个步骤,就是根据目标用户对于目标项目的评价行为找出与其兴趣相似的用户.尽管根据用户对项目的评价行为确实可以在一定程度上找出兴趣相似的用户,但这种做法却忽略了用户之间的社交关系[6].在社交网络上往往越靠近的用户越具有相同的兴趣爱好[7],所以将用户之间的社交关系融入到协同过滤算法当中来是非常有必要的,这就要利用到社交网络分析的知识.
社交网络分析是数据挖掘的一个分支学科,它是一种链接分析技术,意在分析社交网络中的结构和行为[8].在社交网络上,学者们已经对利用社交关系进行个性化推荐做出了各种尝试.Spertus[9]等使用了不同的相似度计算策略在在线社区Orkut上进行个性化推荐.Geyer[10]等在网络社区上根据社交网络信息实现的话题推荐被证实比基于内容的推荐具有更好的效果.
综上所述,社交网络分析对于个性化好友推荐是一个非常重要的方法和影响因素.而协同过滤算法则是推荐系统中经典且高效的推荐算法.本文作者将采用基于社交网络分析和基于协同过滤两种算法来对于微博平台上的好友推荐进行研究.
1 基于社交网络分析的好友推荐算法
基于社交网络分析的微博好友推荐算法.利用目标用户的关注关系数据,统计出每个用户的关注用户和粉丝用户数据,计算用户的相似群体,根据相似度排序向用户做好友推荐.
1.1 算法步骤描述
算法的具体步骤描述如下:1)从数据集中提取出所有用户关系的子数据集,并对子数据集进行预处理;2)计算预处理后的子数据集中所有用户间的相似性;3)对用户相似群体进行相似度排序,获取目标用户的相似群体;4)取相似群体中相似度最高的前N个用户的关注对象来对目标用户进行推荐.
1.2 相似性度量
社交网络中没有评分数据,但却包含着非常丰富的用户社交关系数据.在微博的社交网络中,用户关注的好友并不是在现实生活中熟悉的朋友,很大程度上是因为对其某些言论的认同或者兴趣才建立的社交关系.这种社交关系包括互相关注关系和单向关注关系.
常见的用户相似性度量方法,如余弦相似度、Pearson相关系数及修正的余弦相似度等,对于用户项目的评分向量比较依赖.考虑到微博中并没有用户评分机制,故这里采用不同用户节点的“出度”和“入度”来进行相似度计算.这里的“出度”指的就是目标用户的关注用户集合,“入度”指的是目标用户的粉丝用户集合.
具体的相似性度量方法为:假设用户u的出度为out(u),入度为in(u);用户v的出度和入度分别为out(v)和in(v).则用户u与用户v的相似性sim(u, v)的计算有以下几种方法.
1)in方法,计算公式为
(1)
2)out方法,计算公式为[11]
(2)
3)采用in方法和out方法,计算公式为
(3)
2 基于协同过滤的好友推荐算法
协同过滤推荐算法分为两种,分别为基于内存和基于模型.基于内存的协同过滤算法也分为两种,分别为基于用户和基于项目[12].本文研究的是微博平台的好友推荐,故采用基于用户的协同过滤算法来对目标用户进行好友推荐.
基于用户的协同过滤算法的原理为,根据当前用户的邻居用户的偏好信息来对当前用户进行推荐.所谓邻居用户,指的是对于某些项目的评分与目标用户比较接近的用户.基于用户的协同过滤算法可分为:表示阶段、计算邻居用户阶段和推荐结果生成阶段3个阶段[13].
1)表示阶段.C(n ,m)是一个n×m阶矩阵.协同过滤推荐算法所要处理的数据形式就是与此类似的用户-项目评分矩阵[14],用下式表示为
(4)
式中:n表示用户数;m表示项目数;矩阵元素cij表示用户i对项目j的评分;与喜欢程度成正比.评分可以采用不同的分制,如用1和0分别表示喜欢和不喜欢,或者用10分制来度量喜欢的程度.
利用协同过滤算法在进行微博好友推荐时,表示阶段的矩阵应为用户-用户评分矩阵,矩阵的每个元素是由对应用户间的关注关系量化而来的评分数据,比如,当用户i和用户j的关系为相互关注时,对应的矩阵元素cij为1,否则cij为0.
2)计算邻居用户阶段.计算邻居用户阶段是基于用户的协同过滤算法中的关键阶段.在此阶段中,算法通过计算不同用户关注关系的相似度来衡量不同用户兴趣的相似度.相似度的取值范围为[-1,1],其大小表示用户的邻近程度.因此相似度越接近1表示用户兴趣越相似,即为邻居用户.
在表示阶段,已经将用户的关注关系量化为评分形式的用户-用户评分矩阵.矩阵的每一个行向量表示对应用户对集合中所有用户的评分.则用户之间的相似度可以用余弦相似度进行计算.设I为所有用户的集合,向量u和v分别表示用户u和v在I上的所有评分信息.于是,用户u和v之间的余弦相似度表示为
(5)
式中,Rui和Rvi分别表示用户u对项目i的评分和用户v对项目i的评分.
3)推荐结果生成阶段.在对用户的相似度进行排序后即可得到目标用户的邻居用户集合.不同于为相似用户推荐项目,这里并不需要进行目标项目的评分计算.采用的推荐方式为给当前用户推荐与兴趣最相似的N个邻居用户有互相关注关系的用户.
3 实验与结果分析
3.1 实验数据
本文实验数据来自于数据堂,数据集为63 641个用户的新浪微博数据集,包括微博信息、微博转发关系、用户信息和用户好友关系等数据.本文主要利用用户的互相关注数据来对用户进行相似度计算和好友推荐,故实验采用的数据为用户好友关系数据.
3.2 数据预处理
原始数据为两列用户的uid数据(每一个用户拥有一个唯一的身份识别码),表示第1列用户关注第2列用户,故需要对原始数据进行预处理和过滤操作.
1)在基于社交网络分析的推荐算法实验中,由于微博用户存在好友数量异常的垃圾用户及粉丝过多的认证用户,这些用户对于实验对象的一般性有所影响,故在原有数据集中去除这部分用户.原始数据中用户的关注关系数据共有1 391 718条,从这些关注关系数据统计得到有关注的用户为61 972个,有粉丝用户为24 890个.为了提高实验的准确性和用户的普遍性,选取了关注人数大于20且小于500,粉丝人数大于20人且小于5 000的用户作为研究目标用户,最终的目标群体为3 104位用户.
2)在基于协同过滤的推荐算法实验中,为了提高实验的精度,从用户数据集中选取了互相关注人数大于10的用户,共有1 044位用户作为最终的研究目标,与这一群体有关注关系的用户共有5 311位.由于微博平台中并没有用户对于用户的评分,所以本文将用户之间的相互关注关系作为评分来构建用户-用户评分矩阵.在本实验中,则是根据1 044位用户和涉及到的5 311位用户的互相关注关系来构建一个1044×5311用户-用户评分矩阵.矩阵的某一行为对应用户对于集合中所有用户的评分向量.
3.3 评价指标
采用Top-N推荐中的准确率(Precision)、召回率(Recall)和F度量(F-measure)作为衡量算法的评价指标[15].通过基于社交网络的好友推荐算法(in法和out法)和基于协同过滤的好友推荐算法进行准确率、召回率和F值的比较来对算法进行评价.
准确率定义为
(6)
召回率定义为
(7)
式中:U表示所有用户合集;R(u)表示推荐算法生成的推荐列表;T(u)表示用户实际的好友列表.
将准确率P和召回率R值融合成一个度量值,就是F度量.其定义为
(8)
式中,α为参数,当α=1时,则认为准确率和召回率的权重是一样的.常用的F度量为F2和F0.5.F2表明召回率具有更高的权重,F0.5则表明准确率具有更高的权重.在微博好友推荐场景下,推荐的准确率应该比召回率更加重要,这时就应该调整参数α的取值.本实验中取α=0.5.
3.4 结果分析
使用了两种推荐算法分别在数据集上进行实验,并进行实验结果的对比.第1种是基于社交网络的好友推荐算法,其中采用了两种不同的相似度计算方法(in方法和out方法)进行比较,在实验中分别被简称为SN-in方法和SN-out方法.第2种是基于协同过滤的好友推荐算法(简称CF方法).
1)给出了基于社交网络的推荐算法的SN-in方法和SN-out方法的准确率与召回率对比如图1所示.
图1中从准确率对比可以看出:1)SN-in方法的准确率和召回率均相对高于SN-out方法.2)随着推荐人数的增加,准确率逐渐下降,相反召回率则逐渐上升,且两个指标最终都趋于平稳.由此说明,准确率和召回率是一对相互制约的评价指标,而且推荐人数增加到一定数量时,准确率和召回率都不再变化,算法同时也达到极限.
2)给出了SN-in方法和SN-out方法的F值对比如图2所示.
从图2中可以看出,随着推荐人数的增加,F值达到峰值后略微下降,最终趋于平稳.SN-in方法在平均推荐人数为50人时,F值达到峰值0.193 8.SN-out方法在平均推荐人数为60人时,F值达到峰值0.152 9.这里可以看到,SN-in方法的F值始终高于SN-out方法,所以根据微博用户的粉丝群体相似度计算来进行推荐的效果要好于根据用户的关注群体进行推荐.
3)给出了基于协同过滤的好友推荐算法(CF方法)的准确率、召回率及F0.5度量与推荐邻居数的对应关系,如图3所示.通过对数据集的计算,在不同邻居数的情况下,1 044位用户分别可以得到长度不同的用户推荐列表.为了便于进行不同算法的推荐性能对比,实验中使邻居数不变,将所有用户的推荐人数相加后做平均计算即可得到邻居数与实际推荐人数的对应数据.如表1所示.
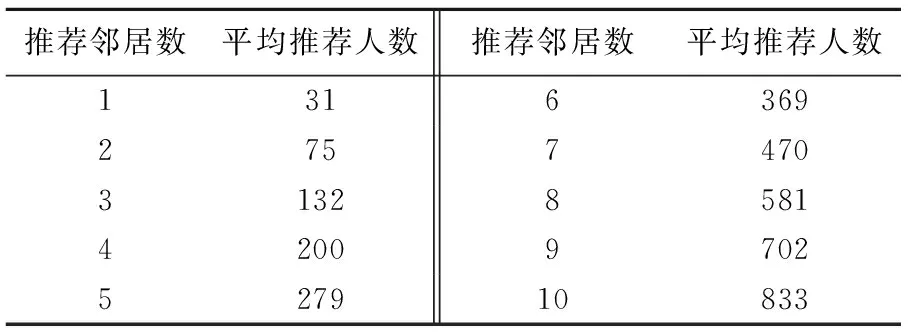
表1 推荐邻居数-平均推荐人数对应表Tab.1 Corresponding data between recommendation and actual average recommendation number
结合表1和图3可以看出,CF方法在推荐人数较多的情况下,F值依然没有趋于恒定.
由于SN-in方法和SN-out方法推荐好友的方式是根据用户与其关注或粉丝群体中个体的相似度进行计算和排序,然后选择最相似的前K个用户进行推荐,而CF方法则是直接计算某用户与邻居用户之间的相似度并排序,然后将与邻居用户互相关注的用户推荐给该用户,具体推荐人数的多少与推荐邻居数的多少并不成正比例关系.
4)在对比这3种方法时,根据CF方法不同邻居数对应的推荐人数取出了前两种方法在同样推荐人数下的F值数据来进行对比.给出了SN-in、SN-out和CF方法在推荐人数统一的情况下的F值对比如图4所示.
结合表1和图4可以看出,在推荐人数比较多的情况下,SN-in和SN-out方法的F值均不再变化,算法在曲线趋于恒定的临界点上达到推荐人数的极限.CF方法在同样的情况下,依然具有变化的F值,不仅没有达到算法的极限而且CF方法的F值在临界点之前都高于SN-in和SN-out方法.
由此可以看出,CF方法的性能要优于其他两种算法,而且在推荐人数较多的情况下,CF方法将拥有比其他两种方法更加优秀的推荐质量.
4 结语
1)对于基于用户的协同过滤算法进行适用于好友推荐的改进,把传统方法中的用户-项目(user-item)评分矩阵转换为用户-用户(user-user)关系描述矩阵,使得用户之间的关注关系量化为矩阵中的对应元素,用户相似度的计算量化为矩阵行向量的余弦相似度计算.从大量的用户关系数据中进行挖掘和计算来获取推荐结果,推荐结果全面且不失个性化.
2)在数据集上进行实验,通过实验和对比可以看到基于协同过滤的好友推荐算法(CF算法)具有较好的性能.由图4可以看出,在推荐好友数量为75时,SN-in、SN-out和CF方法的F度量值分别为0.190 6、0.152 7和0.238 9,此时SN-in和SN-out方法的推荐效果都已达到最佳,但是F度量值均小于CF方法.实验结果说明,在推荐人数较少时,CF方法具有更好的性能.同样由图4可以看到,在推荐好友数量较多的情况下,CF方法依然具有较高的综合评价指标,比传统的基于社交网络的好友推荐算法有着更好的推荐效果,在一定程度上提高了好友推荐的质量.在研究过程中遇到数据集不够完美,算法实验难以进行统一度量对比等问题.但在信息急剧膨胀的时代,本文的研究具有一定的积极意义.
[1] BAWDEN D, HOLTHAM C, COURTNEY N. Perspectives on information overload[C]. Aslib Proceedings, 2013, 51(8): 249-255.
[2] 王晟, 王子琪, 张铭. 个性化微博推荐算法[J]. 计算机科学与探索, 2012, 6(10): 895-902. WANG Sheng, WANG Ziqi, ZHANG Ming. Personalized recommendation algorithm on microblogs[J].Journal of Frontiers of Computer Science and Technology, 2012, 6(10): 895-902.(in Chinese)
[3] 郑志娴. 微博个性化内容推荐算法研究[J]. 电脑开发与应用, 2012, 25(12): 23-25. ZHENG Zhixian.A personalized recommendation algorithm on microblogs[J].Computer Development & Applications, 2012, 25(12): 23-25.(in Chinese)
[4] 杨博, 赵鹏飞. 推荐算法综述[J]. 山西大学学报:自然科学版, 2011, 34(3): 337-350. YANG Bo, ZHAO Pengfei. Review of recommendation algorithms[J]. Journal of Shanxi University: Nat Sci Ed, 2011, 34(3): 337-350.(in Chinese)
[5] GOLDBERG D, NICHOLS D, OKI B M, et al. Using collaborative filtering to weave an information tapestry[J]. Communications of the ACM, 1992, 35(12): 61-70.
[6] KAUTZ H, SELMAN B, SHAH M. Referral Web: combining social networks and collaborative filtering[J]. Communications of the ACM, 1997, 40(3): 63-65.
[7] 秦继伟, 郑庆华, 郑立德,等.结合评分和信任的协同推荐算法[J]. 西安交通大学学报, 2013, 47(4): 100-104. QIN Jiwei, ZHENG Qinghua, ZHENG Lide, et al. Collaborative recommendation algorithm based on rating and trust[J].Journal of Xi'an Jiaotong University, 2013, 47(4): 100-104.(in Chinese)
[8] 韩慧, 王建新, 孙俏,等. 数据仓库与数据挖掘[M]. 北京: 清华大学出版社, 2009. HAN Hui, WANG Jianxin, SUN Qiao, et al. Data warehouse and data mining[M]. Beijing: Tsinghua University Press, 2009.(in Chinese)
[9] SPERTUS E, SAHAMI M, BUYUKKOKTEN O. Evaluating similarity measures: a large-scale study in the Orkut social network[C]. Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, 2005: 678-684.
[10] GEYER W, DUGAN C, MILLEN D R, et al. Recommending topics for self-descriptions in online user profiles[C]. Proceedings of the 2008 ACM Conference on Recommender Systems, 2008: 59-66.
[11] 贺银慧, 陈端兵, 陈勇,等. 一种结合共同邻居和用户评分信息相似度算法[J]. 计算机科学, 2010, 37(9): 184-204. HE Yinhui, CHEN Duanbing, CHEN Yong, et al. Similarity algorithm based on user's common neighbors and grade information[J]. Computer Science, 2010, 37(9): 184-204.(in Chinese)
[12] 邓爱林, 朱扬勇, 施伯乐. 基于项目评分预测的协同过滤推荐算法[J]. 软件学报, 2003, 14(9): 1621-1628. DENG Ailin, ZHU Yangyong, SHI Bole.A collaborative filtering recommendation algorithm based on item ratingprediction[J]. Journal of Software, 2003, 14(9): 1621-1628.(in Chinese)
[13] 吴振慧. 推荐技术的比较研究[J]. 计算机光盘软件与应用, 2011(19): 44-45. WU Zhenhui. Comparative study of the recommendedtechniques[J]. Computer CD Software and Applications, 2011(19): 44-45.(in Chinese)
[14] 张超. 结合社交网络分析和协同过滤技术的推荐算法研究[D]. 吉林: 吉林大学, 2013. ZHANG Chao.Research on recommendation algorithm based on social network analysis and collaborative filtering[D]. Jilin: Jilin University,2013.(in Chinese)
[15] 石丽丽. 面向微博用户的内容与好友推荐算法研究与实现[D]. 北京: 北京邮电大学, 2014. SHI Lili.Research and implementation of content and friend recommendation algorithm for microbloggingusers[D]. Beijing: Beijing University of Posts and Telecommunications,2014.(in Chinese)
Recommendation algorithm of microblogging friends based on social networking and collaborative filtering
WANGYuduo,HUANGTaibo
(School of Information and Communication Engineering, Beijing Information Science and Technology University, Beijing 100101, China)
As a social application that has a large number of users in recently years, the information pressure of microblogging users is relatively powerful. Recommendation technology is helpful to user experience and promotion of microblogging. The paper studies on the friend recommendation on the microblogging platform, and the recommendation algorithms based on social network analysis and collaborative filtering are respectively introduced. After experimental comparison of the two algorithms, it comes to conclusion that friend recommendation algorithm based on collaborative filtering has better performance and has good evaluation index under the large number of friend recommendation. It also can improve the quality of friend recommendation.
recommendation technology; microblogging;social network; collaborative filtering
2016-06-02
汪毓铎(1960—),男,辽宁北镇人,教授.研究方向为数据采集与信号处理. email: wangyuduo@bistu.edu.cn.
TP391
A
1673-0291(2016)05-0070-06
10.11860/j.issn.1673-0291.2016.05.012
