RTL综合中FPGA片上RAM工艺映射
2016-12-09张东晓
李 艳,张东晓,于 芳
(1.中国科学院微电子研究所,北京 100029; 2.北京飘石科技有限公司,北京 100080)
RTL综合中FPGA片上RAM工艺映射
李 艳1,张东晓2,于 芳1
(1.中国科学院微电子研究所,北京 100029; 2.北京飘石科技有限公司,北京 100080)
RAM(Random-Access-Memory,随机存储器)是FPGA(Field Programmable Gate Arrays)片上最重要的宏单元之一,RTL(Register-Transfer-Level)综合对FPGA开发中RAM的有效利用起至关重要作用.本文针对RTL综合中RAM源描述和目标结构多样化带来的技术难题,提出了一种RAM工艺映射方法,即建立工艺无关的RAM统一模型,在模型基础上通过建模、模式匹配、造价计算、绑定四步实现.该方法应用于RTL综合,可以将多种RAM源描述有效地映射到最佳类型和数量的FPGA片上RAM资源.实验数据表明采用该方法实现的RAM工艺映射效果和主流FPGA综合工具——Synplify和XST相当,该模块已经集成在自主开发的RTL综合工具——Hqsyn中并实现商用.
现场可编程门阵列;寄存器传输级综合;片上随即存储器;工艺映射
1 引言
FPGA广泛地应用在各种电子系统中,几乎所有系统均涉及大数据量处理和存储,当前主流FPGA厂商如Altera、Xilinx、Lattice等公司的FPGA芯片都内嵌片上RAM资源,片上RAM已经成为大规模FPGA至关重要的结构[1].FPGA设计流程包括RTL综合、布局布线、码流产生,其中RTL综合作为设计流程中的第一步,对整个电路实现的性能起着至关重要的作用,特别在决定RAM资源的有效利用方面起关键作用.
至今,对于RAM存储器的综合研究,在学术界,研究主要分为三个分支:第一分支主要研究存储器的高级综合[2,3],着眼于高级综合中的多层次存储器架构生成,主要面向ASIC(Application Specific Integrated Circuit),探讨生成何种RAM描述,而没有涉及具体实现;第二分支主要研究RTL级存储器翻译转化成逻辑存储器[4~8],没有工艺映射的研究;第三分支主要研究逻辑存储器映射到基于目标工艺库的存储器,即存储器的工艺映射[9~13],本文的工作属于该分支.其中[9~12]研究不同面积规模的逻辑存储器到目标存储器的映射,不考虑读写类型等工作模式,[13]研究的存储器工艺映射涉及不同种类、不同面积规模的目标存储器的映射,但种类只包含端口有无读写功能,实用性不强.本文提出的存储器工艺映射主要面向实用数字电路中的RAM存储器,涵盖各种类型和各种面积规模的存储器,并且重点在类型上做系统研究,类型主要包括:(1)分布式RAM[14](Distributed-RAM,DRAM)和块式RAM[14](Block-RAM,BRAM);(2)单端口[14](Single-Port)RAM和双端口[14](Dual-Port)RAM;(3)RAM端口的读写操作,即只有读、只有写、有读有写;(4)端口工作模式,即读模式、写模式、写读模式;(5)端口管脚类型;(6)RAM存储规模等.在工业界,FPGA片上RAM的工艺映射已广泛集成于FPGA RTL综合工具中,这类技术被国外Synopsis、Xilinx等少数几家国外公司所垄断,用户只能获得RAM RTL级描述的用户手册信息[15,16]具体映射实现的技术实现细节不公开.
本文在调研学术理论、RAM各种类型特点和多家FPGA综合工具的基础上,针对RAM工艺映射中多源和多目标带来的技术难题,提出基于Verilog HDL语言描述的RAM工艺映射技术和实现方案——Rsyn,采用C++语言实现,最终实现多种RAM源描述有效地映射到最佳类型和数量的FPGA片上RAM资源,产生EDIF(Electronic Design Interchange Format)格式的电路网表,其正确性在Xilinx的多个系列FPGA上得到充分验证,Rsyn已经集成在自主开发的RTL综合工具——Hqsyn,并实现商用.
2 技术难点
RAM工艺映射的技术难点主要在于RAM源描述的多样性、FPGA片上RAM的多模式以及由此造成的多源RAM匹配对多目标RAM映射困难.
FPGA片上RAM(下文RAM均指FPGA片上RAM),主要分为两类:DRAM和BRAM,图1所示为Xilinx Virtex2 FPGA器件上RAM资源的分布情况[14],DRAM分布在逻辑单元中,用逻辑单元内部结构实现,BRAM是FPGA片上专有单元.
DRAM和BRAM分别具有不同的特性,包括端口数量、端口有无读写操作、端口工作模式,即读模式、写模式、写读(read-during-write)模式,管脚类型(如图1左图中RAM的WE、WCLK、D、A0等),以及存储规模等,每一种RAM都是可以由这几种特征描述.其中最为复杂的是写读模式,用于控制RAM处于写入状态时读端口数据与存储单元数据以及写数据之间的关系,主要分为先读(read-first)、先写(write-first)、保持(no-change)三种模式[15].
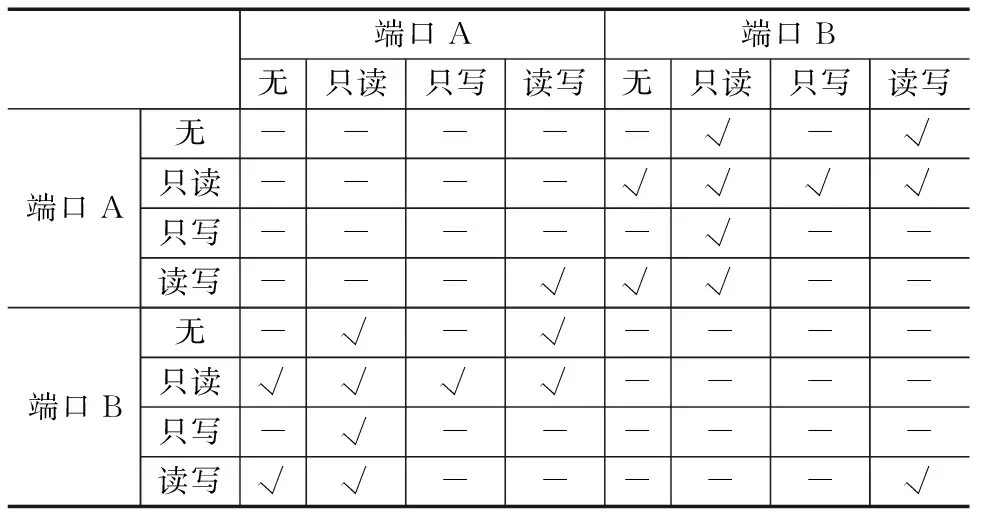
表1 两个端口RAM读写操作模式表
表1是针对端口数为2、只考虑端口读写操作的可能RAM类型,表中显示共有20种RAM结构.如果考虑工作模式、同步异步、不同管脚类型、存储规模,以及交叉端口的写读模式[17]等情况,则可能的结构类型更多,实现难度会更大.上文介绍目标RAM的多样性和复杂性,同样RAM源描述方面,一种功能结构的RAM可以有多种不同的描述方式,以图2为例,图中上部分是用Verilog HDL语言描述的三种不同RAM源描述,它们功能等价,均描述了读写模式为“先写”的RAM.
实现上述“先写”RAM源描述的RAM结构也有多种选择,图中下部分的三种结构是针对功能等价的“先写”RAM的三种不同实现方式,而图例中一个“先写”模式的RAM源描述到目标结构的实现就有9种不同的映射匹配目标,如果考虑端口读写操作、同步异步、不同管脚类型、存储规模,以及交叉端口的写读模式,匹配的目标RAM会有更多种结构.
3 RAM的工艺映射
针对第2节提出的技术难点,提出解决方法:建立工艺无关的RAM统一模型.该模型统合了RAM的各种特征,以便于实现包含建模、模式匹配、造价计算、绑定等步骤的RAM工艺映射.
3.1 工艺无关的RAM模型
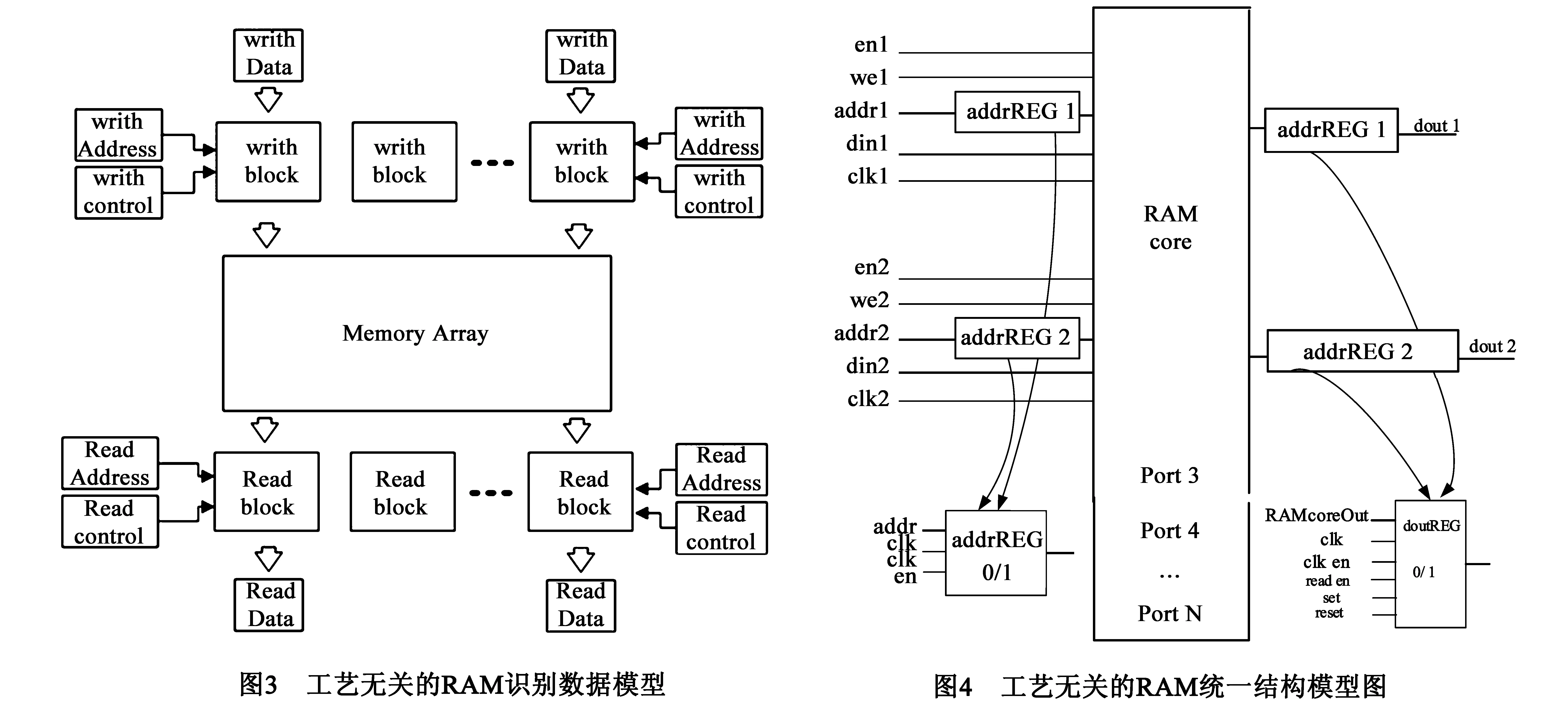
各种电子应用系统的RAM结构可以抽象成包括Memory Array,Write block,Read block,Write control,Read control,Write address,Read address,Write data和Read data模块的电路,基于此,对于多样性RAM源描述,可建立图3所示的识别数据结构模型,实现去多样性目的.该数据结构会转化成图4工艺映射统一结构模型.图4模型与工艺无关,是RAM工艺映射实现的关键,涵盖常用RAM结构.统一模型中RAM的特征通过表2中六个关键性特征属性描述,即端口模式、管脚类型、地址模式、写模式、读模式和写读模式,各种源和目标RAM结构都从该六种属性描述.
源RAM经过Rsyn的识别建模,可以转化成统一模型的数据结构,目标RAM(库单元中的RAM)描述也基于统一模型的数据结构,这样保存了源RAM和目标RAM转化成的数据结构都是统一模型的子集.不同种源和目标RAM就可以按照特征配置,有相同的RAM标准模型结构,使得复杂的RAM工艺映射成为可能.
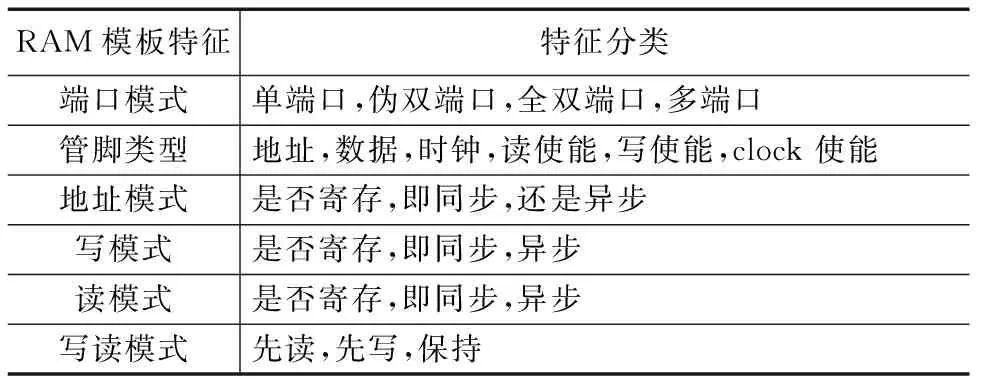
表2 RAM工艺映射模板特征表
引入该模型使得源RAM和目标RAM的多样、多模式统一化,进而使RAM工艺映射难题得以解决.由于该模型与工艺无关,基于不同系列FPGA器件RAM的工艺映射,只需把器件RAM结构按照图4统一模型结构描述库文件,就可以实现面向各种不同FPGA的移植.以Xilinx Virtex、Virtex2系列FPGA的RAM映射为例.Virtex2系列FPGA的RAM与Virtex的RAM有相同的端口模式、管脚类型、地址模式、写模式、写读模式,唯一不同的是Virtex的RAM只有先写工作模式,而Virtex2的RAM有先写、先读、保持三种工作模式,这点在工艺映射库文件中,通过写读工作模式属性设定.这样识别出的RAM结构按照其各RAM特征属性,便可以映射到库中RAM.
3.2 RAM工艺映射实现
工艺映射过程主要分为建模、模式匹配、造价计算、绑定等四个步骤,下面依次介绍四个步骤,其中建模是整个过程的核心,也是本文的介绍重点.
3.2.1 建模
建模是通过分析源RAM(srcRAM)结构和相关逻辑特征,建立RAM统一模型的过程,主要包括预处理、端口压缩、规模判断、建模和后处理五个步骤,算法实现的伪代码如下:

其中1~4行是预处理,1~3行是端口压缩,4行是规模判断,5~12建模,13是后处理.
1~3行端口压缩,在工艺映射前,从Verilog HDL中识别出的RAM存在多个端口情况,其RAM功能可能只是单端口或者是双端口RAM,为此可以按照地址控制和读写操作特点,合并多端口为单端口或双端口,这样可以达到RAM工艺映射、提高RAM资源利用率的效果.
第4行是规模判断,判断映射目标选择DRAM还是BRAM的过程,目的是为了使源RAM映射到最佳类型和数量的FPGA片上RAM资源.由于多个DRAM加额外逻辑可以实现和BRAM一样的功能,因此源RAM既可以映射到BRAM,也可映射到DRAM加辅助逻辑,但是这两种映射方案在电路性能和片上资源利用率方面均有所不同,因此需要合理选择映射目标,以避免大规模RAM采用DRAM造成FPGA片上逻辑资源浪费,性能降低;又或者小规模RAM采用BRAM造成BRAM资源浪费的问题.具体实现主要是筛选出可以用BRAM实现的大规模RAM,以目标器件FPGA中BRAM的存储空间(tgtSize)作为筛选标准,当srcRAM的存储空间小于tgtSize时,用DRAM实现,不经过下面的建模处理;反之,经过下面建模处理,用BRAM实现.
其中5~12行是建模的核心算法,依次遍历源RAM的每一个端口,按照RAM的三种工作模式——write-first、read-first、no-change作为建模处理的三个主分支,而后考虑管脚类型、地址模式、写模式、读模式的特征,把源RAM和可能相关逻辑单元重构为统一模型结构.以图2中提到多目标映射的单端口同步读且write-first工作模式为例说明的建模原理,设定三个例子中RAM的存储规模都是4096X4(地址深度X数据位宽),如图4,第一步先从直译出的电路网表中识别出某种模式的RAM以及相关联逻辑单元.图2中虽然write-first2和write-first3的描述不同,但是直接翻译出的电路结构相同,所以三个描述归为两种.然后建模,源RAM和相关逻辑单元结构,从端口模式、管脚类型、地址模式、写模式、读模式和写读模式六个方面,通过结构重组、配置成RAM统一模型,如图5,把源RAM和相关的寄存器、与门、选择器逻辑单元重构为右图结构.
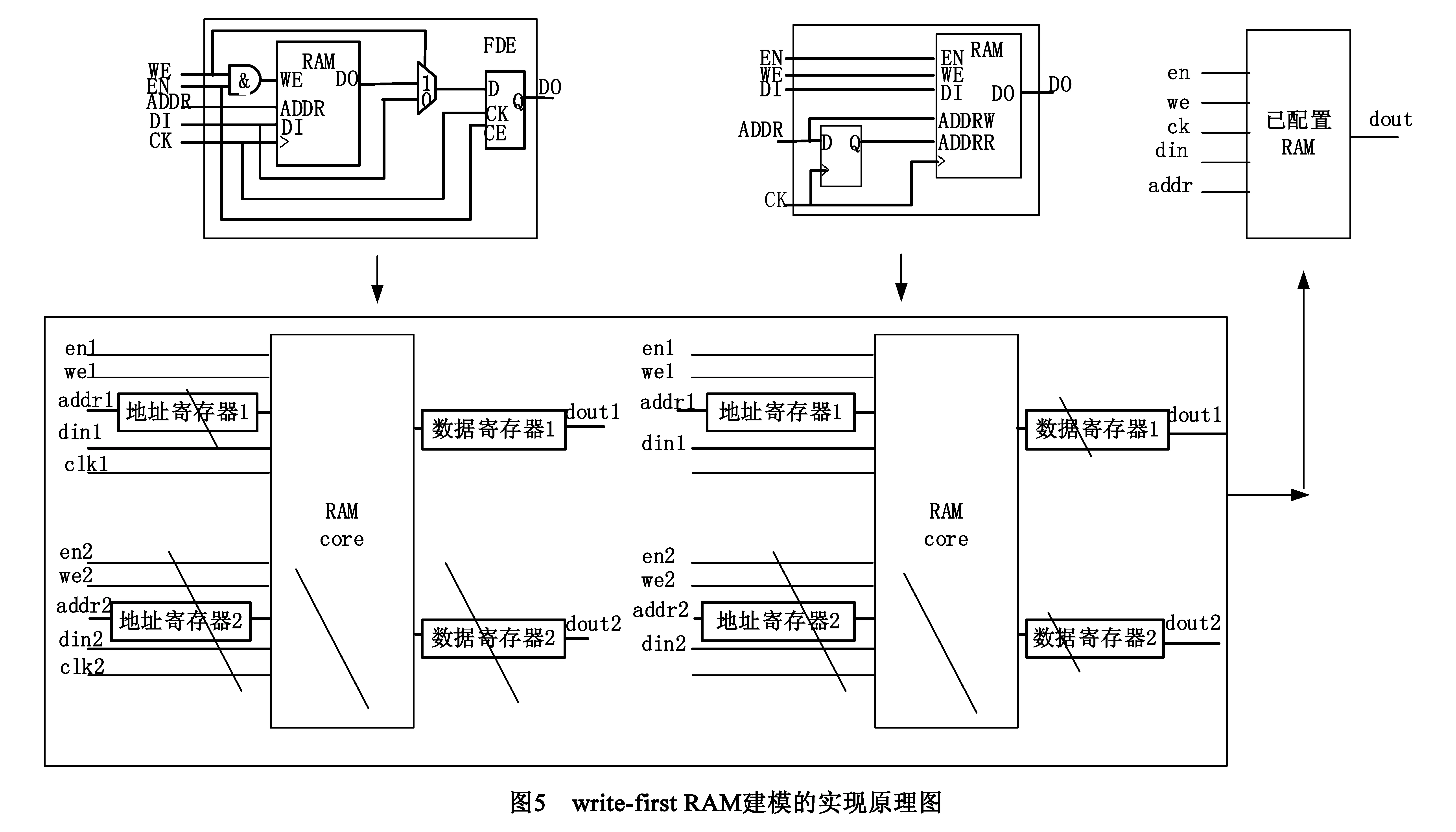
第13行的后处理过程主要处理一些不满足第5~12行处理要求,但又不能直接映射到FPGA片上RAM的情况,比如一个规模小的RAM,两个端口写同步,读异步,读端口连接寄存器,这类RAM和连接的寄存器单元由于RAM规模较小,只能放在后处理,即通过统一模型重构,再实现工艺映射.
3.2.2 模式匹配
模式匹配是指配置成RAM统一模型结构的源RAM,按照RAM六个特征属性,在工艺映射库中选择属性匹配的RAM库单元作为目标RAM的过程.工艺映射库中包含某系列FPGA片上的各种RAM单元,为源RAM提供映射目标RAM单元,其中映射库中的RAM单元都以RAM统一模型描述.匹配过程包括:精准匹配、模糊匹配.匹配原理公式如下:
Source(pm,pt,adm,w,r,wr)<= Target(pm,pt,adm,w,r,wr);
其中pm、pt、adm、w、r、wr分别表示RAM的端口模式、管脚类型、地址模式、写模式、读模式、写读模式,Source()和Target()分别表示源RAM和目标RAM模式匹配函数,包含了精准匹配和模糊匹配.精准匹配要求目标RAM的管脚类型、地址模式、写模式、读模式、写读模式等特征和源RAM的完全一致.模糊匹配则需要目标RAM特征和源RAM的特征满足包含关系.在匹配的过程中,先执行精准匹配,对于不满足精准匹配的情况,才进行模糊匹配.以图6所示为例,先精准匹配,得到单端口、同步读、先写的RAM4096X1、RAM2048X2、RAM1024X4可以匹配,单端口、异步读RAMD16X1不匹配,再通过模糊匹配得到双端口、同步读、先写的RAM1024X4也可以匹配,最后得到在映射工艺库中共有4个目标RAM满足匹配条件.
3.2.3 造价计算与绑定
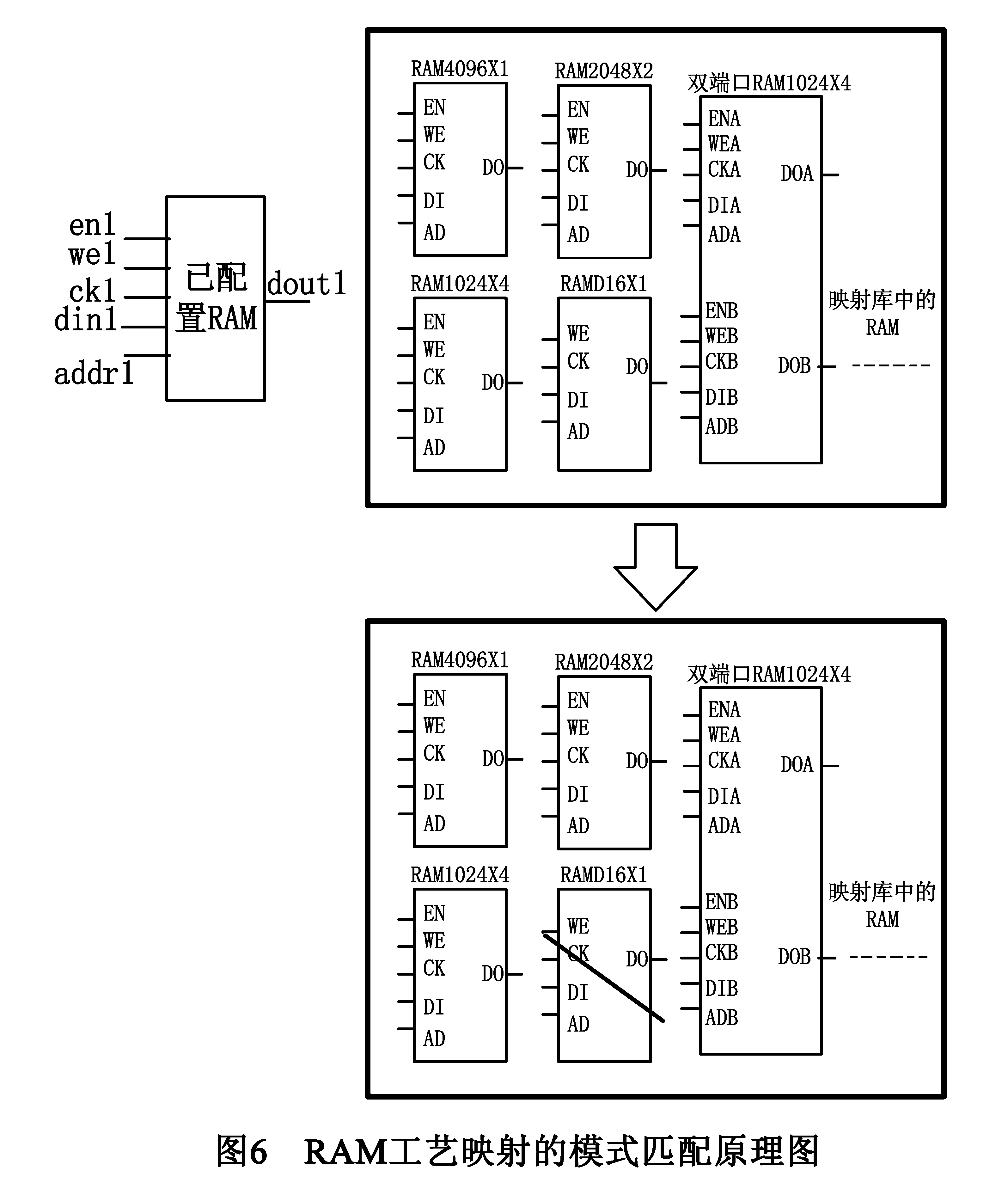
如图6所示,由于经模式匹配后,映射库中仍存在4种可以匹配源RAM的目标RAM单元,因此需要进一步找到最优匹配的目标RAM单元,以达到FPGA片上RAM资源的高利用率.实现方法:采用造价计算算法,计算出源RAM映射到每一个匹配目标RAM需要付出的造价值,经比较后,选取需要付出最小造价的目标RAM作为最优映射目标.造价计算公式如下:
cost=T(area)*(sWid/tWid)*(sDep/tDep)+f(MUX)+f(FF);
公式中,T(area)表示采用目标RAM实现所需要占用FPGA的面积;sWid、sDep、tWid、tDep分别代表源RAM与目标RAM的数据宽度和存储空间数量;f(MUX)和f(FF)两个函数表示造价值的补偿因子;f(MUX)是针对源RAM深度大于目标RAM而言的,这类RAM需要经过拆分才可以映射到目标RAM中,因拆分产生的地址逻辑MUX(Multiplexer,选择器)需要计入考虑;f(FF)是针对同步读的源RAM映射到异步读的目标RAM而言的,这种情况下需要增加新的FF(Flip-Flop,触发器)实现源RAM的同步读功能,所增加的FF面积同样需计入考虑.
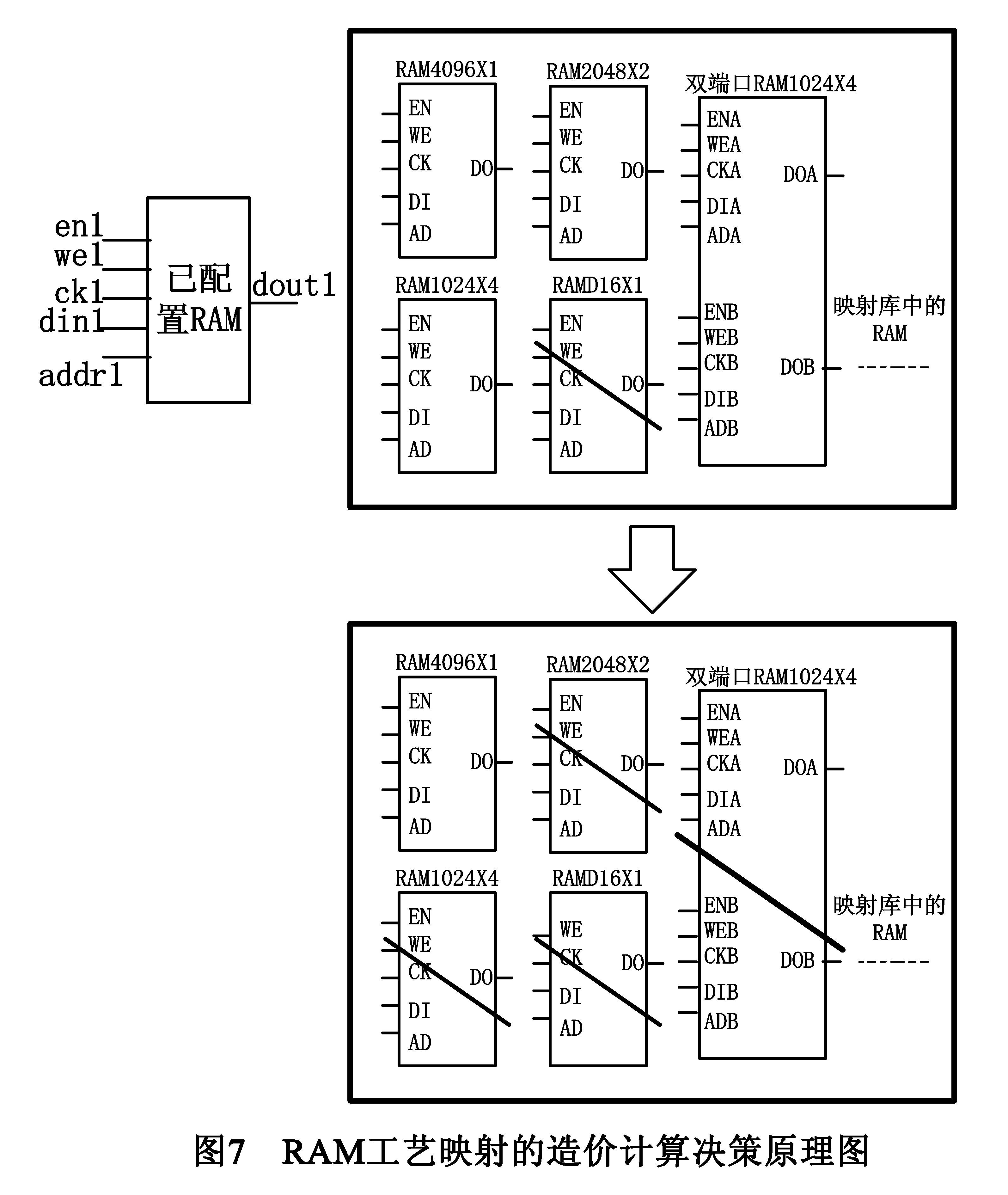
图7中,源RAM为RAM4096X4,匹配中的4个cost值分别为:
cost(RAM4096X1)=4096*(4/1)*(4096/4096)=16384
cost(RAM2048X2)=4096*(4/2)*(4096/2048)+16(f(MUX))=16400
cost(RAM1024X4)=4096*(4/4)*(4096/1024)+32(f(MUX))=16416
cost(双端口RAM1024X4)=2*(4096*(4/4)*(4096/1024)+32(f(MUX)))=32382
经造价计算后,RAM4096X1被选取为最优映射目标.
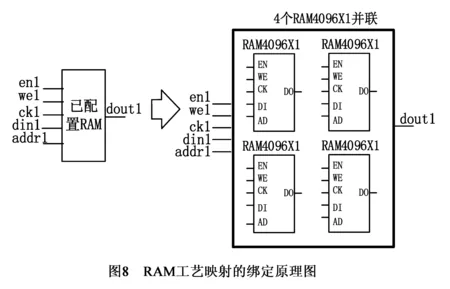
绑定指将源RAM的连接和属性绑定到最优目标RAM单元上的过程,如果需要分裂的,则按照地址和数据宽度分裂源RAM,以保证既可以映射到目标RAM中,又可以达到对RAM资源使用率最小.如图8所示,需要把源RAM分裂成4个,分别绑定到4个并联的最优匹配——RAM4096X1.
4 验证分析
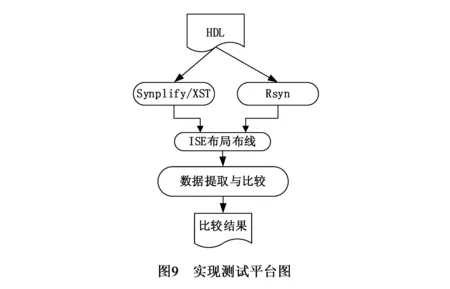
验证在Linux系统下进行,同时嵌入到图9的自动化测试平台中,最终输出比较结果,如表3.对比实验的目标器件为Xilinx Virtex和Virtex2[14]系列芯片,是项目支持的器件.对比实验的测试用例为OC Verilog[18]测试集中抽取的10个用例,均采用Verilog HDL语言描述,含有不同结构的RAM描述,LUT数占用规模在几千到几万不等.本文提出的工艺映射方法实现为Rsyn,参与对比的综合工具分别为Synplify-pro2012和Xilinx的XST10.1(其中XST10.1是Xilinx ISE软件系列中能支持Virtex及Virtex2器件的最高版本).
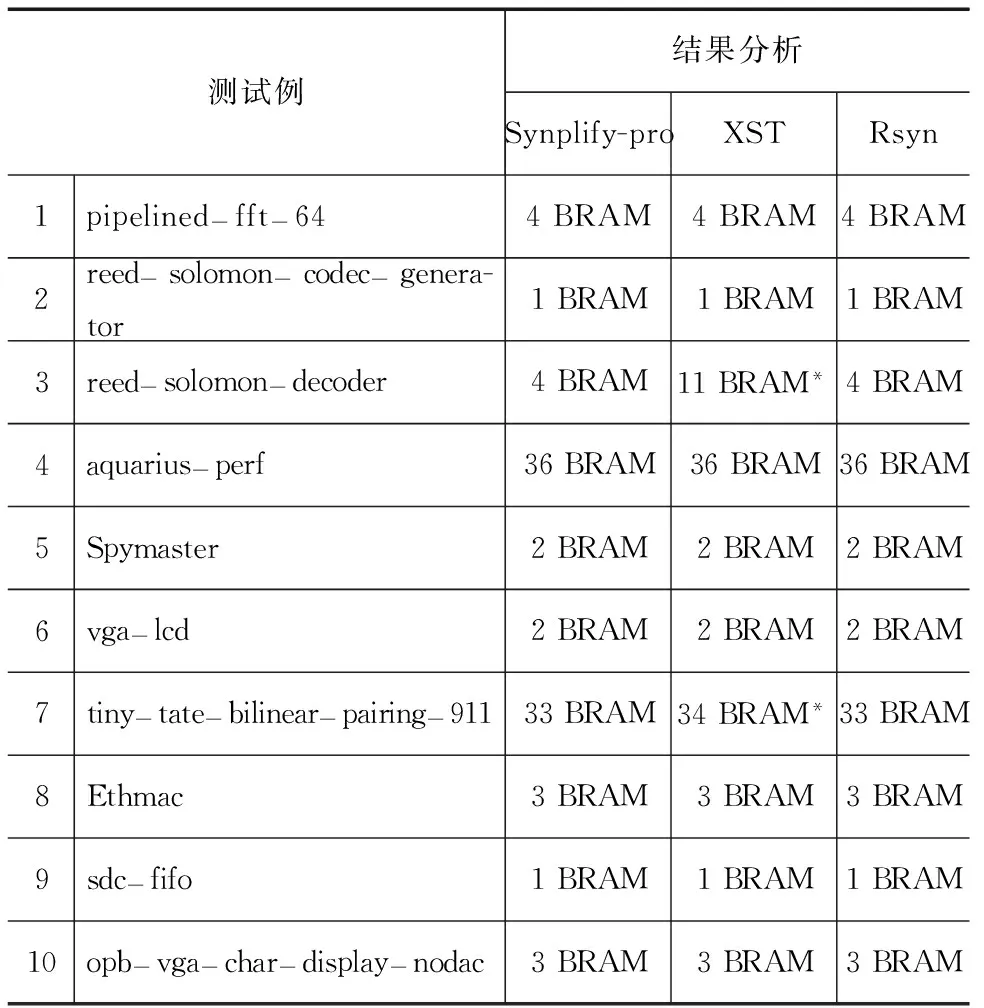
表3 Rsyn与Synplify和XST的RAM工艺映射效果对比列表
表3显示Synplify、XST、Rsyn综合处理RAM的效果对比情况,Rsyn实现RAM工艺映射和Synplify效果相同;10个和XST实现RAM工艺映射效果相同,其中对于reed-solomon-decoder和tiny-tate-bilinear-pairing-911,XST分别比Rsyn多产生7个和1个RAMB,是用来实现ROM功能的.
表4是面向Virtex和Virtex2系列FPGA的RAM工艺映射结果对比表.由于Virtex的BRAM是4Kb规模,且只有先写工作模式,而Virtex2的BRAM是16Kb规模、有先写、先读、保持等工作模式,因此实现的结果有差别,如表4所示,reed-solomon-codec-generator、reed-solomon-decoder、aquarius-perf、spimaster和ethmac中的存储模块,在virtex器件中用DRAM实现;而在Virtex2中用BRAM实现.sdc-fifo中的存储模块,在virtex器件不支持;而在Virtex2中,可以用BRAM实现.本文的RAM工艺映射技术可以适用到不同厂商、不同系列FPGA中的RAM,如Altera和Xilinx,Virtex、Virtex2、Virtex7等,只需要更新某FPGA中RAM各种工作模式在工艺映射库中的描述.
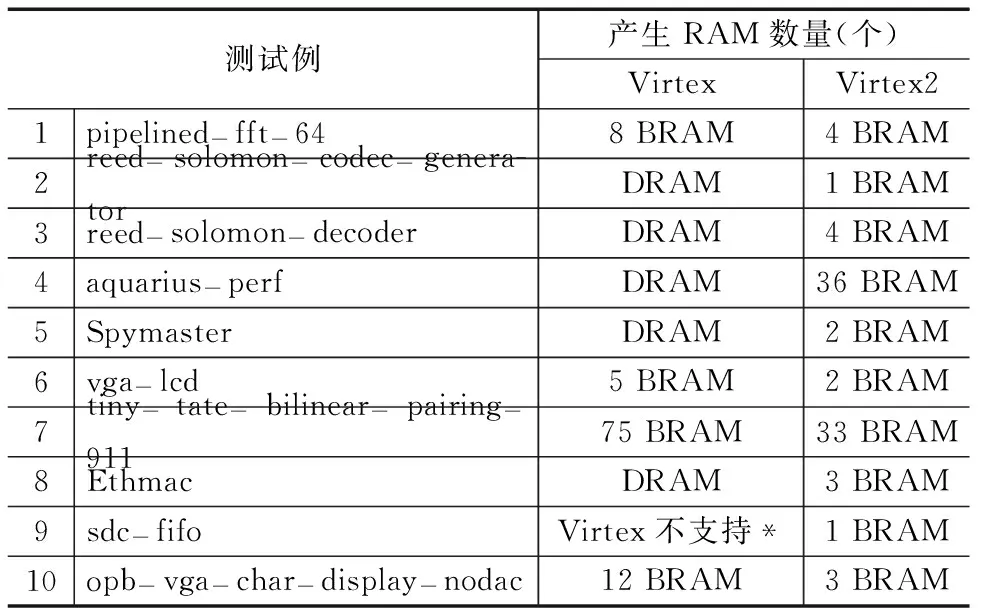
表4 面向Virtex和Virtex2 FPGA器件的RAM工艺映射对比表
5 总结
针对实用电子系统存储器和其描述多样性带来的RTL综合实现困难,且关键技术垄断在几家国外公司而不公开的现状,本文提出并系统介绍了RTL综合中FPGA片上RAM工艺映射方法,建立了一套工艺无关的RAM统一模型,把各种源和目标RAM按照端口模式、管脚类型、地址模式、写模式、读模式和写读模式配置到统一RAM模型上,解决了多种模式的源RAM映射到多种模式目标RAM的难题,该模块已经集成在自主开发的Hqsyn综合工具中,并已经商用,具有较高实用价值.实验结果验证了本方法的有效性,即在产生RAM性能方面,可以和主流综合工具——Synplify和XST处于接近水平.本文验证是通过Xilinx,Virtex、Virtex2,系列FPGA提到的RAM工艺映射技术可以适用到不同厂商、不同系列FPGA中的RAM,如Altera和Xilinx,Virtex、Virtex2、Virtex7等,只需要更新某FPGA中各种工作模式的RAM在工艺映射库中的描述即可.
[1]Steven J E.Wilton.Heterogeneous technology mapping for area reduction in FPGA’s with embedded memory arrays[A].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems[C].San Jose CA US:IEEE Trans,2000.19:56-68.
[2]M Milford,J McAllister.Valved dataflow for FPGA memory hierarchy synthesis[A].IEEE International Conference on Acoustics,Speech and Signal Processing[C].Kyoto Japan:IEEE Press,2012.1645-1648.
[3]Wang Yuxin,Zhang Peng,Cheng Xu,Jason Cong.An integrated and automated memory optimization flow for FPGA behavioral synthesis[A].Asia and SouthPacific Design Automation Conference-ASP-DAC[C].Sydney,Australia:IEEEPress,2012.257-262.
[4]T Kim,Liu C.Utilization of multiport memories for hierarchical data streams[A].ACM/IEEE Design Automation Conference[C].Dallas,Texas,US:IEEE Trans,1993.298-302.
[5]L Ramachandran,D Gajski,V Chaiyakul.An algorithm for array variable clustering[A].European Design and Test Conference[C].Paris France:EDAC,1994.262-266.
[6]P Marwedel,B Landwehr.Exploitarion of component information in a RAM-based architectural synthesis system[A].Logic and Architectural Synthesis,G.Saucier(Ed.)[D].Chapman & Hall Britain,1995.1-11.
[7]P Lippens,J Van Meerbergen,W Verhaegh,A Van Der Werf.Allocation of multiport memories for hierarchical data streams[A].Proceedings of the IEEE International Conference on Computer-Aided Design[C].Santa Clara,CA US:IEEE Trans,1993.728-735.
[8]F Balasa,F Catthoor,H De Man.Data-driven memory allocation for multi-dimensional signal processing systems[A].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems[C].San Jose CA US:IEEE Trans,1994.31-34.
[9]D Karchmer,J Rose.Definition and solution of the memory packing problem for field-programmable systems[A].IEEE/ACM International Conference On Computer-aided Design[C].San Jose CA US:IEEE Trans,1994.20-26.
[10]H Schmit,D Thomas.Array mapping in behavioral synthesis[A].Proceedings of the 8th international symposium on System synthesis[C].Cannes,France:ACM,1995.90-95.
[11]周海峰,林争辉.RTL级综合中存储器工艺映射算法的研究[J].微电子报,2001,31(6):410-413.
Zhou Haifeng,Lin Zhenghui.Memory mapping algorithms in synthesis[J].Microelectronics,2001,31(6):410-413.(in Chinese)
[12]S Bakshi,D Gajski.A memory selection algorithm for high-performance pipelines[A].Proceedings of the conference on European design automation[C].Los Alamitos,CA,US:IEEE Computer Society,1995.124-129.
[13]P K Jha,N D Dutt.Library mapping for memory[A].Proceedings of 1997 European Design and Test Conference[C].Washington,DC,US:IEEE Computer Society,1997.288.
[14]Xilinx,Inc.Datasheet:Virtex-II and Virtex-IIE FPGA Family[M].San Jose,CA,US,2008.
[15]Synopsis,Inc.Datasheet:Synplify Reference Manual[M].Mountain Veiw,CA,U.S.2012.
[16]Xilinx,Inc.Datasheet:XST Reference Manual[M].San Jose,CA,US,2008.
[17]Altera,Inc.User Guide:Internal Memory (RAM and ROM)[M].San Jose,CA,US,2013.
[18]Verilog hdl and VHDL opencores[M/OL].http://opencores.org/projects.2010-08.

李 艳 女,1981年出生于内蒙古巴彦淖尔市,博士研究生,助理研究员,主要研究领域为FPGA架构和FPGA EDA的设计.
E-mail:liyan-ic@163.com
张东晓 男,1972年出生,北京人,博士,FPGA EDA领域专家,主要研究领域为EDA、VHDL/Verilog Hdl语言、高级综合和相关算法;2007年作为CEO,联合创办北京飘石科技有限公司,从事FPGA软件开发与服务,提供通用平台化FPGA软件解决方案,目前已经被国内多家FPGA单位所使用.
E-mail:zdx@uptops.com.cn
Technology Mapping of FPGA on-Chip-RAM in RTL Synthesis
LI Yan1,ZHANG Dong-xiao2,YU Fang1
(1.InstituteofMicroelectronicsofChineseAcademyofSciences,Beijing100029,China;2.UptopsDesignTechnologies,Inc.,Beijing100080,China)
RAM is one of the most important macro-cells of FPGA,and RTL synthesis plays a critical role on the effective use of RAM resources in FPGA development.For the difficulty of multi-resources and multi-targets in RAM technology mapping of RTL synthesis,this paper presents a method of technology mapping for FPGA on-chip RAM.In this method,an unified technology-independent RAM model is proposed,and based on this model,RAM technology mapping is performed through a series of steps,including model set-up,mode-matching,cost calculation,and binding.When applied in RTL synthesis,this method is capable of mapping various styles of RAM RTL descriptions into the most appropriate type and number of FPGA on-chip RAM resources.Experimental result shows that this method achieves comparable RAM mapping results as the mainstream FPGA RTL synthesis tools-Synplify and XST,this technology has been integrated into the self-developed RTL synthesis-Hqsyn and has been applied into the FPGA market.
FPGA(Field Programmable Gate Arrays);RTL(Register-Transfer-Level)synthesis;on-chip RAM;technology mapping
2015-03-17;
2015-06-25;责任编辑:马兰英
国家重大专项02专项(No.Y1GZ212002)
TN47
A
0372-2112 (2016)11-2660-08
��学报URL:http://www.ejournal.org.cn
10.3969/j.issn.0372-2112.2016.11.014
