DBugHelper:分布“系统Debug协助工具
2016-11-29张燕飞张春熙李宇明张蓉
张燕飞,张春熙,李宇明,张蓉
(华东师范大学数据科学与工程研究院上海高可信计算重点实验室,上海200062)
DBugHelper:分布“系统Debug协助工具
张燕飞,张春熙,李宇明,张蓉
(华东师范大学数据科学与工程研究院上海高可信计算重点实验室,上海200062)
对于大规模分布式系统的开发而言,其开发周期比较漫长,包括前期的开发、过程中的Debug、后期的维护和测试等.在整个开发周期中,Debug是一个非常关键和重要的环节,如何才能在短时间内找到最可靠的方法来解除bug成为一个重要的挑战.对于系统开发人员来说,bug报告能非常有效地帮助其了解bug的所有特征信息,并找到能修复bug的方法.通过研究发现,许多大规模分布式系统之间具有较强的相关性和相似性,因而其bug的产生情况和修复方法也具有类似特征.开发人员可以利用已存在的修复bug的方案来协助修复与其一致或相近的bug.本文提出一个适用于大规模分布式系统的Debug协助工具——DBugHelper,能为某些大规模分布式系统的开发人员的bug修复提供比较有效、正确的帮助.DBugHelper将最新的bug报告进行文本处理,形成查询向量,并将大量已被修复的bug及其相关信息进行离线处理和缓存,从而为在线查询提供索引机制.通过将大量已修复的bug报告进行离线处理并同时减少在线处理的数据量,从而使其准确并快速地为系统开发人员提供必要的Debug协助工作,以此减少系统开发的周期与成本.
大规模分布式系统;Debug;bug报告;协助
0 引言
Debug是软件系统开发周期中十分重要的一个环节,其所消耗的时间、人力往往与系统开发阶段相当甚至所占比重更大.特别是对大规模分布式系统而言,其项目开发复杂度大、开发周期长、开发成本高;并且分布式系统特别是基于开源框架的此类系统之间存在着功能相关和代码相似的性质.其中,相关性是指所开发的系统是基于或兼容其他大规模分布式系统,而相似性是指某些大规模分布式系统的整体架构或思想属于同一种类,例如: Spark、HBase、Cassandra等系统与Hadoop密切相关;CouchDB和MongoDB同属于文档型数据库等.大规模分布式系统的bug具有依赖性、传递性等特殊性质,Debug工作更加繁琐和复杂.因此,近些年工业界一直研究如何降低系统开发周期和成本的问题,而现阶段最直接有效的方法就是降低系统Debug成本.目前系统Debug通常由bug的预测、定位、发现、分析、修复、测试等环节组成,对每个环节所使用的方法进行优化,从而降低Debug成本.
在系统开发的各个阶段会生成与系统相关的很多文件资料,例如bug报告、日志信息、源码文件、交流档案、测试案例以及版本信息等.如何利用这些文件信息,挖掘此类文件信息所蕴含的有利于bug定位、分析、修复等工作的有价值信息是当前Debug研究的关注点.Kim S[1]等人研究挖掘bug报告的相关信息,对bug进行预测的工作;Zhou J[2], Nguyen A[3]等人研究通过挖掘出bug报告和源码文件之间所隐藏的紧密联系,并利用此关系有效和快速地为系统开发人员进行bug定位的方法.
在众多支持Debug操作的数据信息中,bug报告是用于发现和修复系统bug的重要参考文献,其记录了来自于系统开发人员、测试人员以及最终用户所提交的关于bug的状态信息、重要等级、标签信息、描述信息、交流信息、附件信息等[3-4].
通常大规模分布式系统在其开发周期内会产生大量的bug报告,其状态包括公开、正在修复中、再次公开、关4、可用补丁、已修复等6种.其中已修复的bug报告包含bug修复方案及相关补丁,同时记录关于bug修复的所有交互信息.例如,目前APACHE官方网站所公布的其所收录的bug总数为39 365,已修复的bug为28 602个[5];其中关于MapReduce的bug数达3 898,包括已修复bug为1 435个,公开的bug为711个[5].
一旦一份bug报告被系统开发人员所接收和确认,项目团队就要对此bug报告进行分析,从bug报告中抽取出此bug的主要特征,并搜索与其相关和类似的bug的解决方案,期望从已经修复的bug中获取和解决bug的思路.然而,面对众多的大规模分布式系统以及其所包含的大量bug信息,想要找到与当前所遇到的bug一致或非常类似的bug并非易事,因为bug描述简短、专业性强,并且其关键词抽取自动化比较困难.
近年来,已有一些研究运用信息检索技术对bug报告进行分析,再对bug报告进行基于特征的分类[6];或者利用机器学习算法根据bug报告的影响力进行分类[7];也可以基于正交缺陷分类(Orthogonal Defect Classification,ODC)的方法,定义基于数据和控制流缺陷、结构缺陷和非功能缺陷类型,通过提取缺陷报告和源代码的特征,对缺陷报告进行自动分类[8].当前所存在的这些bug分类方法,都是利用较少的bug报告的信息结合源码信息、测试信息等分类算法进行分类.Bug报告本身具有的特征信息、描述内容中的关键信息(例如,bug的概要描述、详细描述)、bug的修复交互信息以及相关的bug修复方案及其附件通常容易被忽略,而这些信息中包含大量bug特征.因此,本文的研究问题是:“如何利用bug相关信息协助开发人员修复bug,以支持大规模分布式系统的开发?”由此关键问题,也ß生出两个子问题:
Q1:如何挖掘bug报告所隐含的bug的特征信息以及关联信息?
Q2:如何利用已修复bug的相关信息对新的bug进行修复方案推荐?
本文针对上述问题进行了研究,包括:
(1)特征提取:基于词集的bug特征定义和抽取忽视描述词间潜在的关联关系.本文提出利用Latent Dirichlet Allocation(LDA)模型[9-10],基于bug相关文档,从而构造基于潜语义的词集;
(2)噪音过滤:通过LDA模型获取词在主题上的分布,根据此分布过滤掉与主题相关度低的词,从而降低Vector Space Model(VSM)模型的输入规模;
(3)多层次聚类:发现bug之间的关联关系.
分别利用LDA模型和VSM模型对bug报告进行分类的工作已经存在,但其最终结果并不理想:仅利用LDA模型,只考虑bug报告的主题分布,利用基于主题的低维度向量进行相似度分析,必然会导致大量信息的丢失,且已有的工作大多利用bug报告的短文本,同样会降低准确性;只利用VSM模型,其利用bug报告的词频所建立的文本向量会丢失大量的语义信息,而高维度的相似度计算会导致其极高的代价.本文所提出的DBugHelper将结合LDA和VSM模型的优势构造L VSM模型,在原本机械词频统计的基础上加入词之间的深层语义知识,使最终形成的向量更好地对bug报告的特征信息及其之间的关联信息进行描述.
本文工作的贡献是:
·将LDA与VSM相结合提出L VSM模型,该模型能更加有效地对大规模分布式系统所产生的bug报告进行分析.
·本文在大量的bug报告数据上,开展了充分的对比试验,验证工具的有用性和有效性.
·设计和实现了Debug协助分析工具DBugHelper.工具可以有效地分析所提交bug的特性,为系统开发人员提供最为相近的bug修复方案.
本文的组织如下:第1节阐述bug报告及其修复方案的分析;第2节介绍本文所提出的DBugHelper工具;第3节介绍了实验设计;第4节展示了实验结果并进行相关讨论;第5节对相关工作进行了介绍;第6节对全文进行总结.
1 Bug报告及其修复方案的分析
通过对现有bug报告及其修复方案的细致分析,其主要特征如下:
相似bug报告:当系统开发人员获取到新的bug报告后,首先考虑是否有类似的bug已被修复,通过查询已修复的bug报告,得到相近或相关的修复方案.再进一步查询相关的资料文档,最终对bug进行修复.因此,如何有效地查询历史记录来帮助修复bug是重要问题.
簇组:系统开发人员为修复bug而查阅大量文档资料,例如相似的bug报告及其修复方案、系统功能设计文档、系统日志文档等.为缩短bug修复时间以提高搜索和查询资料的效率,可提前对bug进行分析归类,在其所属簇组中查询相关修复方法的信息.因此,对bug及其报告进行归类,有利于提高bug的查询效率.
离线、在线处理:及时响应是工具的基本要素.大规模分布式系统所拥有的与bug相关的数据资源十分丰富,其数据处理耗时较长,因此迅速响应是工具可用性的表现.将复杂计算进行离线处理,缩短工具响应时间并提高其可用性.DBugHelper采取离线和在线处理操作分离的方式,离线处理已修复bug相关数据信息并提供索引机制,在线处理利用该索引及新的bug报告及时为系统开发人员提供最为接近的bug修复方案以及相关资料信息.
就目前相关研究来看,相似bug报告已经被用于bug的定位方法[2].而其他两方面都没有很好地利用和研究.在本文所设计的工具中,此类信息被进行考虑和利用.
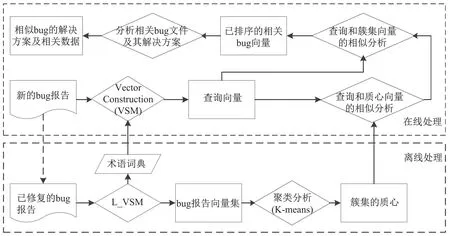
图1 DBugHelper的整体架构Fig.1DBugHelper overview
2 基于内容分析技术的Debug协助框架--DBugHelper
2.1 DBugHelper的整体架构
图1展现了为大规模分布式系统的开发提供Debug协助的工具--DBugHelper.整个系统分为两大部分:1)离线处理模块:主题分析、词典构建、术语选择、文本向量构建、簇及其质心构建;2)在线处理模块:查询向量构建、修复方案推荐.当获取到新的bug报告,工具基于离线处理所获取的术语词典将此报告转化为查询向量.已修复的bug报告经过L VSM模型构造向量集合,再通过聚类分析将bug的向量集合进行归类,并获取各类的质心以构建索引机制.将查询向量与所构建的索引向量进行相关性分析,查询出与新的bug报告相关的已修复的bug,再将这一类的bug文件资料进行融合,为新提交的bug推荐可能的修复方案及其他相关文件资料.新提交的bug报告会进入已修复bug的缓存队列中,bug一旦被修复会触发离线处理操作.
2.2 离线处理
离线处理环节,将大量已修复bug的相关文档资料进行分析处理,利用L VSM模型抽取bug报告的特征信息并将其向量化表示,向量分量的权值波动反映出bug报告之间的关联关系.DBugHelper存储了大量大规模分布式系统的bug报告F及其相关修复方案的文档R,采取离线处理方式,对已修复的bug报告F进行处理.分为几个步骤:
主题分析:本文从两个层面提取bug报告的主题,一是bug报告所具有的明确特征的主题Ts,例如bug等级、标签、状态、系统环境、所属版本、所属组件、作者等;二是从bug报告中的bug概要、描述、评论、历史等信息中抽取出的主题Tg;本文所抽取和利用的主题为T(Ts+Tg).本文对已修复的bug报告进行分析并抽取其主题T,对于每篇bug报告F所包含的主题T,在F中均有相关单词w进行描述.
术语选择:本文利用主题T和单词w之间的反向关系,将原本主题T的对单词w的概率分布θ(T→w)变为w→T,以计算单词w在每个主题T上的概率分布,从而得到每个w的向量,其中|T|是主题总数,c是当前词,wc,t表示为:

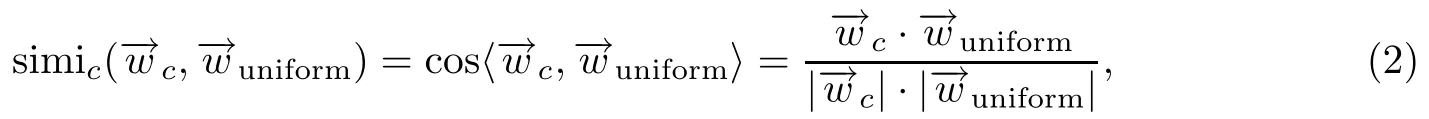
其距离越大分值将越高.将所有词按分值进行降序排序,将得分较低的单词去除.将所有留存的单词w来构成术语词典D.
词典构建:本文从已修复的bug报告F中抽取主题T,主题T由F中单词w进行描述,而单词w的概率值θ表示出其对于主题T的重要程度.为提高工具的性能和缩短响应时间,选取F中较为重要的单词作为术语,从而构建术语词典D.前期对bug报告进行文本处理,包括去除停用词、标点符号等,再通过术语选择,进一步降低工具的在线、离线处理的时间和代价.传统利用LDA模型进行特征抽取时,通常是以主题词来构建文档向量,但由于主题数为人为设定,因此误差性较大,当主题数设定较小时,甚至导致所有向量相似性极高.本文选择描述主题权重较高的单词作为术语,以术语构建文本向量,进而提高准确性以及减少模型处理代价.
文本向量构建:所构造的术语词典D涵盖所有已修复bug报告d的关键术语,基于词典D所形成的F的特征向量Q能表现bug的基本特性又能反映bug之间的关联关系,|F|为此向量的元素个数即词典D所含术语t的个数.将已修复bug报告进行向量化表示,其各个分量的权重值wi,j是基于术语频率(tf)和逆文档频率(idf)计算而来.该算法的基本思想是术语的重要性随着它在文档中出现的次数成正比增加,但同时也随其在词典中出现的频率成反比下降.在传统的VSM模型中,对tf和idf进行以下定义:
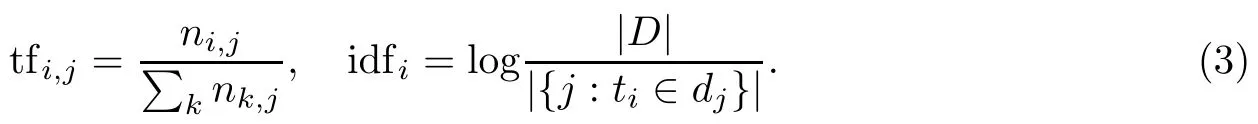
等式(3)中的ni,j是指术语ti在文档dj中出现的次数,其对应的分母表示文档dj所有术语出现次数之和.|D|为词典D所包含的文档dj的总数,它对应的分母则是包含术语tj的文件的个数.当前很多研究通过改变tf的形式,进一步提高VSM模型的性能,其中包括对数型、增广型以及布尔型等多种VSM模型改进方法[11].通过对比验证,本文采用对数型以提高性能:

在L VSM中,本文利用等式(4)来定义tf,因此术语ti所对应的权值wi,j被定义为:
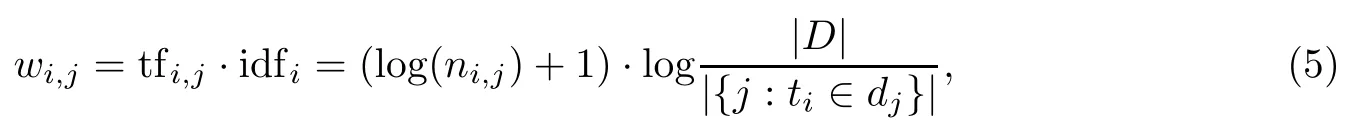
文档dj所对应的文本向量表示为:
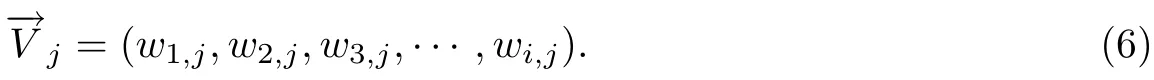
L VSM模型利用LDA的Gibbs Sampling实现,并结合等式(2)得到用于描述bug报告的特征值,以此作为改进的VSM模型的输入,最终通过等式(6)得到F的向量集合,其集合定义为:
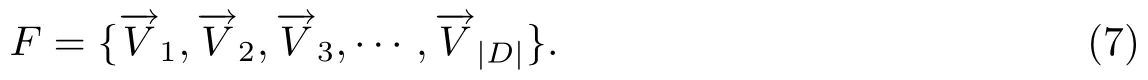
簇及其质心构建:随着已修复bug报告数量的不断增加,其处理分析的时间也随之增长,因此本文将此阶段进行离线处理.通过对已修复bug报告集进行聚类分析并进行归类,找出表示每个簇的质心来构建索引,从而提高相近bug修复方案的查询效率.Bug报告的区别性和关联性与K-Means聚类分析[12]所适用的场景吻合,同时结合算法的时间复杂度低、对大规模数据处理适用性高、伸缩性好等特点,因此将K-Means算法用于bug报告的聚类分析.向量集合F在给定簇组数K(K 6|D|)值的条件下,将F中的向量归为K类,所构成簇集合为:

簇组数K是人为设定的,不同的K值对聚类结果影响较大,本文通过确定指标的方式,对K值进行探寻,找出最接近于真实簇数目的K值.K-Means所定义的函数公式为:
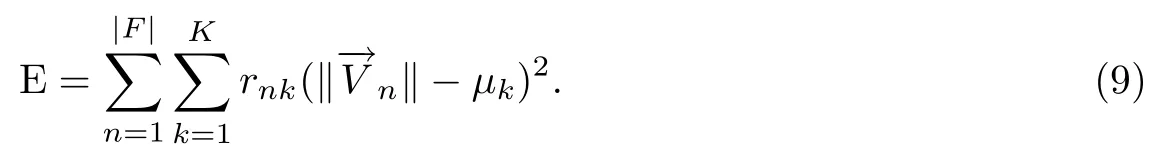
等式(9)中的μk表示的是每个分类Sk的平均值,rnk只有当被归类到某一簇Sn时,其值被赋为1,否则为0.通过计算E值来找出每个向量Vn所属的簇Sn,通过不断地迭代最终形成k个簇,每个簇的质心定义为:

簇以及簇的质心将被用于新提交bug报告B的相似度计算,以此判别B所属的簇.
2.3 在线处理
在线处理主要针对新提交的bug报告,如何利用离线处理所构建的索引机制迅速查询到相近的修复方案是在线处理环节的核心问题.针对此问题,本文提出三层处理架构,其结构如图2所示.第一层是用于缓存新提交bug报告,将所提交的bug报告基于词典D生成查询向量B;第二层缓存由离线处理阶段所获取的簇Sn及所对应的质心Cn;第三层缓存所有已修复bug的相关修复方法及其他相关资料文件.
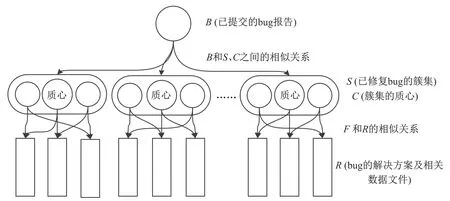
图2 DBugHelper在线处理三层处理架构Fig.2Three layers for online processing in DBugHelper
第一、二层的链接关系是B与Cn之间的相似度,通过计算B与Cn之间的相似度值判别其所属簇SB,同样利用公式(2)所采用的cosine相似度计算方法对B进行簇判别:

计算所得与B相似度值最大Cn簇即是B所属簇,这表明新提交的bug和簇中其他bug报告所描述的bug属于同一类,则其修复方案最为相似或相关.第二、三层的链接关系是已修复bug报告F和其相关修复方案的对应关系,同样通过将B与所属簇SB的其他bug报告进行相似度分析,将适用于新提交的bug报告的修复方案及相关文档资料进行排序,最终为系统开发人员提供最为相似或相关的bug修复方案.
3 实验设计
3.1 系统选择
为评估DBugHelper的有效性,本文选取四个开源的大规模分布式系统作为实验项目(如表1所示).所有项目都拥有完整的bug报告以及相关的修复方案,同时也包含与bug相关的包括讨论、历史、日志、状态转换等方面的数据信息.本文选取HDFS作评估对象,因其是一款非常流行并开源的分布式文件系统,并且是分布式系统基础架构Hadoop的核心部件.而MapReduce同样也是Hadoop的核心设计之一,它是用于大规模数据集并行计算的编程模型.HBase是基于Hadoop架构实现的分布式开源数据库系统,利用HDFS存储海量数据,并使用MapReduce进行数据处理.数据仓库工具Hive同样基于Hadoop架构所实现,是一种可以存储、查询和分析大规模数据的机制.

表1 研究项目Tab.1Study project
3.2 数据选择
对于每个项目系统,本文从bug跟l系统(例如BugZilla或APACHE官网)中选择最原始的bug报告作为实验对象,来评估DBugHelper所推荐bug修复方案的准确性.
用于评估的bug报告,包含以下几个方面:
(1)Bug的基本信息.它一般包括bug的主题、类型、优先级、所影响的系统版本以及其所属组件等(例如:“MapReduce job can infinitely increase number of reducer resource requests”,“Bug”,“Blocker”,“2.8.0”,“None”).
(2)Bug的描述信息.开发人员用自然语言对Debug过程中所产生的bug进行详细描述,有时也附加相关的日志信息等.
3.3 研究问题
本文设计实验对以下三个问题进行回答:
Q1:DBugHelper能否较为准确地为bug提供相一致或相近的修复方案?
为回答这个问题,本文将四个项目系统的已修复bug及其修复方案作为基准数据,将bug报告作为DBugHelper的输入条件.检查从工具中所返回的修复方案及其相对应的bug报告.若所输出的结果Top N(N=1,5,10,15,20)个包含该bug的真实修复方案,则认为bug的修复方案可以有效地被推荐.本文选取每个系统的100个已修复bug作为实验对象,计算bug被提供的修复方案的准确率(Accuracy).
Q2:L VSM模型是否能提高寻找相似bug报告的准确率?
在第2节中,本文提出了L VSM模型,将其用于bug分析从而构建查询向量及结合聚类分析构建索引机制.为评估L VSM的有效性,本文将其与传统VSM的方法进行对比,将DBugHelper中的L VSM模型替换为传统VSM模型,并在Q1的条件下对DBugHelper提供bug修复方案的准确率进行计算,并以此与基于L VSM模型实现的工具进行结果比对.
Q3:DBugHelper的在线、离线处理模式能否提高查询bug修复方案的效率?
在第2节中,本文提出在线、离线处理分离的模式,将大数据集进行离线处理构建查询索引,用在线处理获取查询向量,使用该查询向量结合索引机制查询bug修复方案.为评估该模式的可靠性,本文引入时间准确率比(TA)的度量标准(在下一小节介绍),以评估在线、离线处理模式的性能.
3.4 评估度量
为评估DBugHelper关于bug修复方案的查询效率,本文提出以下度量:
·Accuracy(准确率)是指bug的准确修复方案占DBugHelper所输出的修复方案Top N(N=1,5,10,···,n)的比率.工具所输出的修复方案越多,包含的bug准确修复方案就越多.此度量值越高,则其准确率越高.
·TA(时间/准确率)指时间与准确率的比值,以此衡量Bug修复方案的查询效率.TA表示单位准确率下DBugHelper的每个查询的执行时间,其值越小则表示查询效率越高.公式定义如下:

其中Time指的是分别返回Top N个bug修复方案所需时间;指的是针对相同返回Top N个bug修复方案所需的时间均值;Accuracy是指DBugHelper所返回Top N个bug修复方案中真实修复方案的所占比重.
4 实验结果及讨论
针对所研究问题的实验结果展示如下:
Q1:DBugHelper能较为准确地提供与bug相一致或相近的修复方案吗?
表2展现了DBugHelper所输出的Top N个bug解决方案中包含bug真实解决方案的比例.本文分别选取4种系统项目各100个bug报告作为输入数据,而工具针对每个bug报告输出的Top N个修复方案.此类方案中包含真实bug修复方案的个数所占bug总数(即100个bug报告)的比例,即为工具的准确率.对于输入的100个HDFS相关的bug报告,工具输出的Top 10个修复方案包含真实方案的有44个,则其准确率为44%.对于Hive项目,相同的输入条件下,工具所返回的Top 20个修复方案包含68个真实方案,则其准确率为68%.随着N值的递增,DBugHelper所输出的修复方案准确率也在同步提升.

表2 DBugHelper的准确率Tab.2DBugHelper accuracy
Q2:L VSM模型是否能提高查询相似bug报告的准确率?
在DBugHelper工具中,L VSM模型被用于查询向量以及索引机制的构建,从而影响bug修复方案的推荐.表3表明基于VSM和L VSM实现的DBugHelper在提供修复方案的准确率上的差异.实验选取HDFS和MapReduce系统的bug报告数据,利用与Q1中相同的方法,对工具的两种实现方式作对比,以此证明L VSM模型在查询相似bug报告的准确率方面的提高.从表3的数据中可以发现,基于L VSM实现的工具在Top N(N=1,5,15,20)上所提供bug修复方案的准确率均高于VSM模型.在HDFS和MapReduce两种系统的实验数据对比中,L VSM模型所实现的工具准确率高于传统VSM模型.传统VSM所实现的DBugHelper的准确率同样满足随N值的递增而递增的趋势,但整体趋势均略低于L VSM模型.简而言之,L VSM模型的提出有利于提高相似bug报告的查询准确率以及所提供bug修复方案的准确率.

表3 基于VSM与L VSM实现的DBugHelper的准确率对比Tab.3Accuracy comparison between VSM and L VSM in DBugHelper
Q3:DBugHelper的在线、离线处理模式能否提高查询bug修复方案的效率?
表4展现了在Q1实验条件下,不同系统及Top N所组成的实验中工具所执行的时间.将系统HDFS的100个bug报告作为输入条件,执行工具100次输出Top N(N=1,5,15,20)个bug修复方案所用时间,求算术平均值,所输出的bug修复方案的准确率如表2所示.

表4 DBugHelper的执行时间Tab.4Execution time in DBugHelper
利用等式(12),计算时间与准确率的比值TA作为评估DBugHelper效率的度量.如图3所示,工具的TA值随着N值的递增呈现先上升后平稳的趋势.在Top 1到Top 5阶段,工具的效率值呈现快速上升趋势;但从Top 5到Top 20阶段,工具效率值趋于平稳.对于不同的项目系统,效率趋势图都比较相似或相近.TA作为时间与准确率的比值,其物理意义在于单位准确率下DBugHelper每个查询的执行时间.TA的值越小,工具的执行效率越高,即在较短的时间内能返回较为准确的bug修复方案.
本文利用三个方面的实验对DBugHelper工具进行评估,分别为工具的准确性、L VSM模型查询相似bug报告的准确性以及工具的效率.通过与传统的VSM模型进行对比实验,进一步阐明本文提出L VSM模型的必要性;通过对工具在准确性和查询效率两方面的实验验证,并且将大规模分布式系统数据作为实验对象,进一步证明本文所提出的适用于大规模分布式系统开发的Debug协助工具--DBugHelper的必要性和有效性.
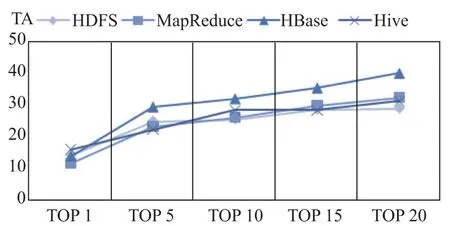
图3 DBugHelper的效率趋势图Fig.3The efficiency of DBugHelper
5 相关工作
在系统的开发周期内,Debug工作至关重要.Bug的难以预知性和无法避免性导致其成本消耗巨大,有时甚至超过整个系统开发成本的三分之一[13].通过利用已有的bug报告、源代码文件、系统日志等资源,为系统开发人员定位bug、修复bug等提供协助的工作一直被研究领域所关注.Lukins等人用LDA模型对bug报告进行分析,从而对bug进行有效定位[14].该方法利用LDA模型对所有bug报告和代码源文件进行主题抽取,根据所抽取的主题作为查询条件对所有的资源文件进行查询.而DBugHelper利用bug报告所含的相关术语作为查询属性,更加完整地对bug相关资源文件进行查询,同时提高查询效率、降低查询时间.在他们的方法中,如果新提交的bug报告所提取出的主题较少,其所查询出的资源文件准确度就较低.DBugHelper充分利用bug报告所具有的特征,以主题相关的术语构建文本向量,以此可以充分表示bug报告及其关联关系.
近些年,有关利用信息检索的技术去进行bug报告的分类、bug定位的方法不断被提出. DBugHelper工具利用LDA和VSM相结合的手段对Bug报告进行检索和分析具有一定的优势,Rao等人[15]用具体的试验对Unigram Model(UM),Vector Space Model(VSM),Latent Semantic Analysis Model(LSA),Latent Dirichlet Allocation Model(LDA)以及Cluster Based Document Model(CBDM)进行了对比,从结果可以发现UM和VSM从文本集中检索相关文档的效果更好.本文将LDA和VSM相结合对与Bug报告相关的文档信息进行检索分析,在一定程度上比单一模型在准确度上有了一定的提高.
本文的工作也与很多软件资料库的挖掘工作有关.大量有关系统软件开发的数据资料越来越多地被人们所搜集,并且很多资料开始被用来分析和挖掘以解决与bug相关的众多问题.许多研究人员通过挖掘bug报告及相关信息来解决与bug相关的一系列问题,如bug的自动分类[16],二重bug报告的探测[17],以及bug的预测研究[1]等.随着计算机技术的发展和应用,面对更多大规模分布式系统或者其他系统软件的开发,大量的bug以及其相关信息被源源不断地产生出来,用人工处理的方法已经无法满足当前科技发展的需求,因此越来越多的研究人员着手用机器学习、数据挖掘等技术对这类数据进行自动分析处理.本文提出的工具,充分利用bug报告对大规模分布式系统的开发人员提供Debug协助.
6 总结
每当新的bug报告来临,系统开发人员需尽快掌握bug的特性,并寻找出合适的方案进行bug的修复.对于大规模分布式系统而言,bug产生原因更为复杂,除需要检查系统自身可能出现的bug,还包括与之相关或紧密联系的其他系统,因此系统的bug更具有依赖性、传递性以及关联性等特征.并且此类系统开发周期长、难度大,需要在其Debug工作上投入大量成本.本文充分挖掘大规模分布式系统bug的独特性,利用信息检索的相关方法,提出了一个适用于大规模分布式系统开发的Debug协助工具--DBugHelper.工具利用L VSM模型和聚类分析技术构建了bug报告的查询向量和bug修复方案的索引机制,采用在线、离线进行数据处理的模式提高查询效率和准确率.评估结果阶段,本文利用4个真实开源的分布式系统作实验对象,展现出DBugHelper推荐相关或相似bug修复方案的准确性和高效性.
后续我们将会继续探究将分布式系统的详细设计文档信息加入到现在的方法中,从而进一步提高工具推荐bug修复方案准确度的问题.同时也将会把DBugHelper应用到企业项目中,以真实地评估工具的有效性.
[1]KIM S,ZIMMERMANN T,WHITEHEADE E J,et al.Predicting faults from cached history[C]//Proceedings of the 29th International Conference on Software Engineering.2007.
[2]ZHOU J,ZHANG H,LO D.Where should the bugs be fixed?-more accurate information retrieval-based bug localization based on bug reports[C]//Proceedings of the 2012 International Conference on Software Engineering. 2012:14-24.
[3]NGUYEN A T,NGUYEN T T,AL-KOFAHI J,et al.A topic-based approach for narrowing the search space of buggy files from a bug report[C]//Proceedings of the IEEE/ACM International Conference on Automated Software Engineering.2011:263-272.
[4]ZHANG J,WANG X Y,HAO D,et al.A survey on bug-report analysis[J].Science China,2015,58(2):1-24.
[5]Hadoop Map/Reduce[EB/OL].[2016-06-20].https://issues.apache.org/jira/browse/MAPREDUCE.
[6]SUN X,LI B,LEUNG H,et al.MSR4SM:Using topic models to effectively mining software repositories for software maintenance tasks[J].Information&Software Technology,2015,66:1-12.
[7]HUANG L,NG V,PERSING I,et al.AutoODC:Automated generation of orthogonal defect classifications[J]. Automated Software Engineering,2015,22(1):3-46.
[8]THUNG F,LO D,JIANG L.Automatic defect categorization[C]//Proceedings of the 2012 19th Working Conference on Reverse Engineering(WCRE).IEEE,2012:205-214.
[9]BLEI D M,NG A Y,JORDAN M I.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003: 993-1022.
[10]THOMAS S W.Mining software repositories using topic models[C]//Proceedings of the 33rd International Conference on Software Engineering.2011:1138-1139.
[11]MANNING C D,RAGHAVAN P,SCHÜTZE H.Introduction to Information Retrieval[M].Cambridge:Cambridge University Press,2008.
[12]KANUNGO T,MOUNT D M,NETANYAHU N S,et al.An efficient k-means clustering algorithm:Analysis and implementation[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2002,24(7):881-892.
[13]SI X S,HU C H,ZHOU Z J.Fault prediction model based on evidential reasoning approach[J].Science China Information Sciences,2010,53(10):2032-2046.
[14]LUKINS S K,KRAFT N A,ETZKORN L H.Bug localization using latent Dirichlet allocation[J].Information &Software Technology,2010,52(9):972-990.
[15]RAO S,KAK A.Retrieval from software libraries for bug localization:A comparative study of generic and composite text models[C]//Proceedings of the International Working Conference on Mining Software Repositories. 2011:43-52.
[16]PINGCLASAI N,HATA H,MATSUMOTO K.Classifying bug reports to bugs and other requests using topic modeling[C]//Proceedings of the Asia-Pacific Software Engineering Conference.IEEE Computer Society,2013: 13-18.
[17]RUNESON P,ALEXANDERSSON M,NYHOLM O.Detection of duplicate defect reports using natural language processing[C]//Proceedings of the 29th International Conference on Software Engineering.2007:499-510.
(责任编辑:林磊)
DBugHelper:A Debug assistant tool for distributed systems
ZHANG Yan-fei,ZHANG Chun-xi,LI Yu-ming,ZHANG Rong
(Institute for Data Science and Engineering,Shanghai Key Laboratory of Trustworthy Computing,East China Normal University,Shanghai200062,China)
Development of large-scale distributed systems has experienced a long developing period.During the whole development cycle,debug is one of the most important steps.We meet the challenges of finding all the bugs and the corresponding solutions fixing bugs in a short time.Bug reports record bug histories and solutions,which provide a way to understand bug features and help to find solutions for new bugs.After we analyze the bug reports and fixed solutions,we find that there are strong correlation and similarity among many large-scale distributed systems.Thus the developing and fixing scheme ofbugs may have similar characteristics.Then existed fixing solutions of bugs can be used to assist fixing new bugs.In this paper,we propose DBugHelper,a debug helping tool which can be applied to boost the development of large-scale distributed systems and provide a more effective way to fix bugs.In DBugHelper,the existed bug reports are processed offline,and the latest bug report is represented as a query vector.We query the bug report history database and find the similar bugs with their solutions.In such way,we suppose to shorten the whole system development period.
large-scale distributed system;Debug;bug report;assistance
TP391
A
10.3969/j.issn.1000-5641.2016.05.017
1000-5641(2016)05-0153-12
2016-05
国家863计划项目(2015AA015307);国家自然科学基金重点项目(61232002,61332006);国家自然科学基金(61432006)
张燕飞,男,硕士研究生,研究方向为数据库系统、数据挖掘. E-mail:yfzhang@stu.ecnu.edu.cn.
张蓉,女,博士,副教授,研究方向为分布式数据管理.E-mail:rzhang@sei.ecnu.edu.cn.
