2D-Haar声学特征超向量快速生成方法
2016-11-24谢尔曼罗森林潘丽敏
谢尔曼,罗森林,潘丽敏
(北京理工大学 信息系统及安全对抗实验中心,北京 100081)
2D-Haar声学特征超向量快速生成方法
谢尔曼,罗森林,潘丽敏
(北京理工大学 信息系统及安全对抗实验中心,北京 100081)
针对大数据量音频的高速处理,提出一种快速的声学特征超向量生成方法,有效提高音频识别系统的识别速度和精度.所提方法首先将多个连续音频帧的常用声学特征构成声学特征图,进而使用低复杂度的运算方法在其中快速提取维数达数十万的Haar-like声学特征;然后使用AdaBoost.MH算法,筛选出具有较高代表性的Haar-like声学特征模式组合,用以构成声学特征超向量;进而提出Random AdaBoost特征筛选方法,进一步提高特征筛选速度.实验结果表明,在音频事件识别、说话人识别、说话人性别识别3种场合下,使用Haar-like声学特征可以使SVM、C5.0、AdaBoost等识别算法获得比MFCC、PLP、LPCC等常用声学特征更高的识别准确率,同时可以获得7~20倍的训练速度提升和5~10倍的识别速度提升.
音频处理;音频识别;2D-Haar声学特征超向量;Haar-like声学特征;AdaBoost.MH
近年来,随着音频识别(audio recognition)研究的不断深入,如何对常用的声学特征进行有效地筛选、统计,进而构造出代表性更强、运算复杂度更小的声学特征向量,对提升识别性能具有重要的研究价值,受到了越来越多的关注.在特定音频识别领域,人们提出了多种声学特征构造方法,有效提升了机器学习算法的识别性能[1-2];在说话人识别研究中,研究者使用GMM算法生成超向量,大幅提升SVM算法的识别精度[3-4];也有研究者使用分数阶傅里叶变换[5]、kernel k-means聚类[6]、设计新的窗函数[7]等方法提升声学特征的代表性,以提高识别系统的识别速度和准确率.
随着大数据时代的到来,在大数据量的音频处理任务中,音频识别系统的处理速度已成为衡量其性能的重要因素,如何在保证识别精度的前提下,尽可能地提高特征提取及特征超向量生成的速度,成为该领域研究的突出问题.
对此,本文提出一种快速高效的声学特征超向量生成方法,该方法的核心是对2维的声学特征图进行Haar-like声学特征的模式筛选,因而命名为2D-Haar,该方法不仅可以显著提高识别、训练阶段的速度,还可进一步提升识别精度.
1 原理框架
本文所提方法如图1所示,其基本原理是引入时频联合滤波和特征筛选的思想,首先借助Haar-like声学特征,对一定时长的常用的声学帧特征序列进行特征维度扩展,大幅增加了特征维数,因此具有更高的音频内容表征潜力,但其动辄数十万维的特征空间会显著增加计算复杂度,难以用于训练和识别.
因此加入特征筛选模块,筛选出最具代表性的特征维度,以提高运算速度.这些筛选出的特征模式组合就构成了2D-Haar声学特征超向量,可供后续的机器学习算法进行分类器训练与识别.
图2展示了一个基于本文所提方法的音频识别系统原理图.
2 Haar-like声学特征提取
2.1 构造声学特征图
Haar-like声学特征借鉴了在图像处理领域获得成功应用的Haar-like特征[8].为了能够从音频波形中提取Haar-like声学特征,本文提出了声学特征图的概念.
声学特征图即一定数量的连续音频帧的常用声学特征向量(例如子带能量或者MFCC、LPCC、PLPC等)的集合.除了上述声学特征外,各种其它的声学特征及其组合(仅使用子带能量)都可以用来构成声学特征图.其基本原理如图3所示.
对于音频库S={s1,s2,…,sk}(k为音频库中音频文件的总数)中的某音频文件sk,其声学特征图的计算方法如下.
步骤1 对音频文件sk进行去静音等预处理后,按照帧长fs、帧移Δfs进行分帧.
步骤2 提取各帧的基础声学特征,将各帧的基础声学特征组合,形成一个包含c帧、每帧p维特征量的基础特征向量序列Vk.
Vk中每一帧的特征向量的内容为:{[基础特征1(p1维)],[基础特征2(p2维)],…,[基础特征n(pn维)]}.
假设音频文件sk的持续时长为t,则
步骤3 对于基础特征向量序列Vk,采用滑窗的方式,以a为窗长、s为步进,将所有的c帧声学特征向量转换成声学特征图序列Gk(参见图2).
2.2 Haar-like声学特征计算方法
Haar-like图像特征被定义为图4和图4中黑色区域的声学特征值之和减去白色区域的声学特征值之和.
让图5中的5种Haar-like声学特征模式在声学特征图上以不同的放大比例和不同位置进行计算,就可以产生维数庞大的特征新空间.Haar-like声学特征可以有更多的模式,本文仅使用了图5所列的5种模式.
假设声学特征图的尺寸为a×p,某一放大比例的Haar-like声学特征模式可以由一个4元组表示:f=(x,y,w,h),其中,(x,y)为Haar-like声学特征模式的左上角顶点;w,h为该特征模式的的长和宽.上述参数满足:x+w≤a,y+h≤p,x,y≥0,w,h≥0.
令X=⎣a/wmin」,Y=⎣p/hmin」.则X,Y分别为该声学特征图中所有Haar-like声学特征模式的最大放大因数,则该模式可以派生出的Haar-like声学特征总数为
一幅32×32的声学特征图,本文使用的5种Haar-like特征模式的总维数超过了51万,这远远超过了音频FFT能量谱的维数,也远远超过了音频FFT能量谱的维数.
Haar-like声学特征的另一个特点是提取计算速度快.配合积分图,任何尺寸Haar-like声学特征的提取只需执行固定次数的数据读取和加减运算.积分图与原始声学特征图的尺寸相同,其上任意一点(x,y)的值被定义为原始声学特征图对应点左上方所有的特征元素值之和(包括该点).定义为
(1)
式中:ii(x,y)表示积分图上点(x,y)的取值;i(x′,y′)表示原始声学特征图的特征元素值.
利用积分图,包含2个矩形的Haar-like声学特征只需从积分图中读取6个点进行加/减运算,3个矩形的特征只需读取8个点,4个矩形的特征只需读取9个点.
3 Haar-like声学特征筛选
3.1 基于AdaBoost.MH算法的特征筛选
使用训练数据集进行迭代运算,从十万计的Haar-like特征空间中筛选出对于识别任务更具代表性的Haar-like特征模式.首先定义两个函数.
定义1 对给定的样本空间X和类别标签集Y,一个多类别、多标签问题中的样本可表示为:(x,Y),x∈X,Y⊆Y.定义K[l]:
式中l表示类别标签.
定义2 对给定的输入单维特征fj(x)与阈值θj,l,定义弱分类器Decision Stump:
式中:pj,l指示不等号方向.
对包含m个样本的H维训练数据集S={(x1,Y1),(x2,Y2),…,(xm,Ym)},特征筛选过程为:
① 初始化样本权重D1(i,l)=1/(mk),i=1,2,…,m,l={“lk”,“其他”}
② Forf=1,2,…,F
ⅰ) 在Df下,进行H轮迭代,从H个弱分类器中选择一个hj(x,l),使
(2)
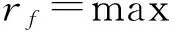
ⅱ) 按照下式计算弱分类器权重αf,
ⅲ) 按照下式更新Df+1,
式中Zf为归一化因子.
③ End For
④ 最终生成的2D-Haar声学特征为
(3)
W可直接用于后续的分类器训练,同时将Haar-like声学特征的模式组合Q存储下来,供后续的机器学习方法在识别阶段生成2D-Haar声学特征
(4)
式中:qn为一个3元向量{Patten,Location,Size}.Patten为指被选中特征fn(x)对应的Haar-like声学特征的模式类别(即图 4中的Ⅰ~Ⅴ型);Location为指被选中的Haar-like声学特征模式在声学特征图中的位置,用Haar-like声学特征模式左上角的在声学特征图中的坐票来表示;Size为指被选中的Haar-like声学特征模式的大小,以原始模式尺寸的倍数来表示.
3.2 基于Random AdaBoost的特征筛选
对3.1节中所描述的流程加以分析,不难看出其中最耗时的运算在于:每筛选出一维Haar-like声学特征,就要对所有的H维特征都进行式(2)的rf,j求解和排序,而为了得到F维筛选出的特征,就需要进行F×H次rf,j的求解和F轮排序.由于H的值往往高达数十万,就会造成大量的运算耗时.
本文对AdaBoost.MH算法加以改进,提出Random AdaBoost特征筛选方法,即:在每维Haar-like声学特征的筛选过程中,并不是对整个H维的特征都进行rf,j求解,而只是对随机选出的E维特征进行rf,j求解,最终得到的Haar-like声学特征的模式组合用Q′=[q1q2… qF]表示.
4 2D-Haar声学特征超向量提取
对于每幅声学特征图guk,其2D-Haar声学特征超向量的提取步骤为:
① 按照式(1)计算guk对应的特征积分图;
②Forf=1,2,…,F
ⅰ) 从Q或者Q′中读取第f个Haar-like声学特征模式qf;
ⅱ) 依照Haar-like声学特征模式qf,在积分图上进行固定次数的读取和加减运算,将运算结果wf记载到超向量W中.
③ End For
④ 得到guk的2D-Haar声学特征超向量W:
可见,2D-Haar声学特征超向量的提取过程仅仅涉及加减运算,且任何尺寸的Haar-like声学特征模式都可以通过固定次数的加减运算完成提取.
5 实验过程及结果分析
本文设计了以下实验,所有实验的平台配置均为:Intel双核CPU(3.0GHz),2GB内存,WindowsXPSP3操作系统.
5.1 2D-Haar特征超向量提取速度实验
5.1.1 实验数据和评价指标
本实验中,Haar-like声学特征筛选、2D-Haar声学特征超向量提取均使用相同的数据集——总长为1h的连续音频文件,采集自《新闻联播》,包含音乐、语音、环境音等内容.
采用维度处理倍速xRTd作为处理速度的评价指标.对于一段时长为ts的音频段S,某特征提取算法消耗了Tps得到p维的特征向量,则维度处理倍速xRTd为
5.1.2 实验过程和参数说明
验证2组2D-Haar声学特征超向量,这两组超向量从2种不同的声学特征图中提取:
A组:{12维MFCC,12维LPCC,8维PLPC};
B组:{[1~18kHz]64维子带能量}.
作为对比的声学特征包括4组常用声学帧特征:
C组:{12维MFCC,12维一阶差分};
D组:{12维LPCC,12维一阶差分};
E组:{8维PLPC,8维一阶差分};
F组:{12维MFCC,12维一阶差分,12维LPCC,12维一阶差分,8维PLPC,8维一阶差分}.
对实验数据源进行声学特征提取实验,记录提取耗时(即从输入音频文件开始,经过Haar-like声学特征筛选训练、2D-Haar声学特征超向量提取,最终得到特征向量的耗时),并由此计算xRTd.
预处理过程中,对音频分帧加窗的参数为:汉明窗帧长fs=30ms,帧移Δfs=15ms.
声学特征图的构造过程中,Haar-like特征包含的帧数a采用网格法,从10开始,以5为步进增加到100,RandomAdaBoost处理方法的每轮迭代次数E采用一个足够大的整数,本组实验中确定为1 000;Haar-like特征筛选过程中,分别使用基于AdaBoost.MH与RandomAdaBoost两种筛选方法,2D-Haar声学特征超向量包含的维数F设定为100,a设定为50.
5.1.3 实验结果及分析
图6显示了每幅声学特征图包含的音频帧数a对2D-Haar超向量提取速度的影响,其中采用RandomAdaBoost筛选方法的维度处理倍速在各种a的取值下保持不变,这是由于RandomAdaBoost筛选的处理速度仅仅取决于每轮迭代中随机选取的Haar-like声学特征模式个数E.
从图6中还可以看出,本文所提的Random AdaBoost算法可以有效提升2D-Haar声学特征超向量的生成速度;同时,由于B组的声学特征图由子带能量生成,其运算速度更快.
5.2 2D-Haar声学特征超向量的应用实验
5.2.1 实验数据和评价指标
本实验的数据资源如表1所示.

表1 实验3所用的数据资源
音频事件识别采用与文献[9,11]相同的评价指标;说话人识别的评价指标采用该领域通用的方法,即
准确率=1-等错率.
说话人性别识别使用由混淆矩阵统计出的整体准确率来评价算法性能.整体准确率由基于10折交叉法测试得到的混淆矩阵计算获得,对于给定的N维混淆矩阵C,总体准确率P的定义为
5.2.2 实验过程和参数说明
针对连续的音频流文件,分别使用2D-Haar声学特征超向量和常用声学帧特征,进行音频事件识别和说话人识别,均采用“子带能量构成声学特征图+Random AdaBoost筛选方法+AdaBoost训练/识别”的框架搭建识别系统.
音频事件识别的具体步骤为:针对50段音频流,使用本文所提特征超向量,结合AdaBoost.MH算法,与文献[9,11]进行比较.
说话人识别的具体步骤为:每个待识说话人进行50次目标测试和冒认测试,记录错误接受率(FAR)和错误拒绝率(FRR),绘制DET曲线,计算等错率和准确率.对比方法采用以高识别精度为特色的GMM-SVM算法,采用文献[12]中的识别框架结合KL核实现,使用与本文所提算法相同的声学特征.
说话人性别识别的具体步骤为:使用10折交叉法的思路,在300人的3 000段语音中进行10轮测试,每轮测试中,以男性、女性做子类区分,依次各选择150段语音(男、女合计300段)作为测试,其余语音作为训练数据.10轮测试结束后,合并混淆矩阵,计算总体准确率,并与常用声学帧特征进行比较,所采用常用声学帧特征与2D-Haar声学特征超向量的类型及参数配置与实验1相同.
5.2.3 实验结果及分析
① 音频事件识别实验.
进而通过实验比较融合GMM和SVM的混合算法与AdaBoost算法[9]、动态规划-贝叶斯神经网络[11](dynamic programming and bayesian network)算法的识别性能.文献[9]中使用AdaBoost.MH算给出了最优迭代次数T=860,本文所提算法的参数为:E=1 000,p=64,d=105,实验比较结果如表2所示.

表2 不同算法的识别性能
可见,本文所提2D-Haar声学特征超向量结合AdaBoost分类器,可以获得较对比算法更好的识别性能.
表3记录了在音频事件识别任务下,使用单纯音频片段作为训练测试集,总体准确率达到85%时,运用AdaBoost、SVM、C5.0 3种算法,使用常用声学帧特征(4种常用帧特征构成方式中,达到85%准确率的训练速度最快的是F组,即64维组合向量)与2D-Haar声学特征超向量的训练与识别耗时.训练耗时为4 h音频数据训练总的时间开销,识别耗时为识别1 s原始音频的时间.
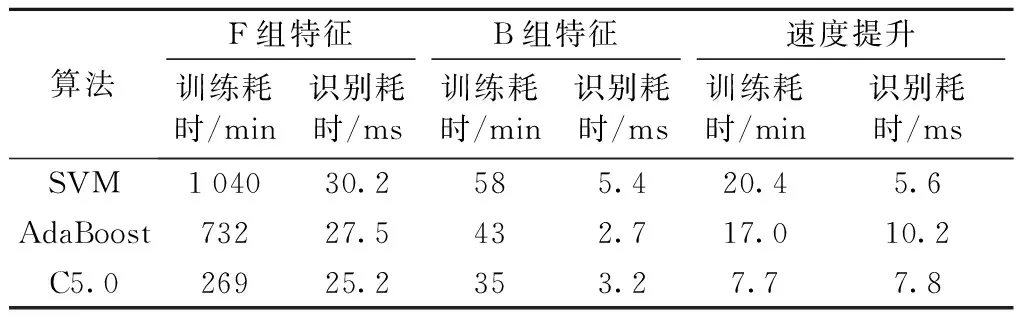
表3 训练与识别耗时
可见,由于2D-Haar声学特征使用较少的维度表示了更多的声学特征信息,使得训练和识别时间都有所减少,训练速度提升可达7~20倍,识别速度提升可达5~10倍.
② 说话人识别实验.
说话人规模由100增加到600时,两种方法的表现如表 4所示.当说话人规模不断增加时,本文所提方法下降趋势较缓,6种说话人规模下的平均识别准确率可达91.3%.

表4 不同说话人规模下两种方法的准确率
为了评价本文所提算法的时间效率,统计不同2D-Haar声学特征维数F下每秒钟音频数据的平均识别耗时t.由表5可知,本文所提方法具有较高的识别速度.
表5 不同F值下本文所提方法的平均识别耗时
Tab.5 Proposed method’s average recognition time-cost under differentFvalues

F值100200300400500平均耗时/ms275366385476587
可见,在说话人识别的应用场景中,2D-Haar声学特征超向量也获得了比GMM-SVM方法更好的识别精度和速度.
③ 说话人性别识别实验.
说话人性别实验中,测试不同2D-Haar特征超向量维数F下,SVM、AdaBoost、C5.0 3种方法的表现,图中Max.FF是使用4组常用声学帧特征所能达到的最大值.
可见,2D-Haar声学特征超向量在说话人性别识别这一场景中,获得了比常用声学帧特征更好的总体识别率,同时,SVM和AdaBoost算法的表现好于C5.0,C5.0在Haar-like声学特征维数较多时会出现识别精度下降.
6 结 论
由本文结果可知,使用Random AdaBoost筛选方法的2D-Haar声学特征超向量的维度处理倍速约为常用音频帧特征的2倍;在使用常用音频帧特征构成声学特征图和Random AdaBoost筛选方法的情况下,可以获得约5%的识别精度提升、7~20倍的训练速度提升和5~10倍的识别速度提升.
2D-Haar声学特征超向量的作用为:① 当构成声学特征图的基础声学特征是子带能量时,不同模式及尺寸的Haar-like声学特征起到了简化的时频域联合滤波的作用,比常用的帧/段特征具有更强的特征描述能力;② 当构成声学特征图的基础声学特征是诸如MFCC、LPCC等频域特征时,不同模式及尺寸的Haar-like声学特征起到了增强的差分或者特征统计功能,比常见的逐维统计方法具有更丰富的代表性;③ 任何尺寸的Haar-like特征只需读取6~9个积分图数值,再配合进行加减运算即可求得,因此可以迅速完成计算;④ 在庞大的Haar-like声学特征空间中,Random AdaBoost可以有效减少运算量.
2D-Haar声学特征超向量仍存在着以下问题,有待进一步的研究:① 本方法的引入了a、E、F3个参数,在不同的应用场景研究中,需要进行针对性的参数优化,这一局限需要使用参数自适应优化方法加以补偿;② 对2D-Haar声学特征超向量的提取方法进行的数理推导和分析,在数理层面加以印证研究也是一个有意义的研究方向;③ 本文仅仅使用了3类常用声学特征,更多的基本声学特征的采用,是否会进一步提升识别性能,也是有待探索的问题;④ 从理论上分析,2D-Haar声学特征超向量具有处理多种时序数据的能力,因此在非音频处理领域的应用也具有一定的研究价值.
[1] Dennis J, Tran H D, Chng E S.Image feature representation of the subband power distribution for robust sound event classification[J].IEEE Transactions on Audio Speech and Language Processing, 2013,21(2):367-377.
[2] Nishimura J, Kuroda T.Versatile recognition using Haar-like feature and cascaded classifier[J].IEEE Sensors Journal, 2010,10(5):942-951.
[3] Asbai N, Amrouche A, Debyeche M.Performances evaluation of GMM-UBM and GMM-SVM for speaker recognition in realistic world[J].Neural Information Processing, 2011,7063(II): 284-291.
[4] Liu M, Huang Z.Multi-feature fusion using multi-gmm supervector for svm speaker verification[C]∥Proceedings of CISP’09.2nd International Congress on Image and Signal Proceeding.[S.l.]: IEEE, 2009:1-4.
[5] Ajmera P K, Holambe R S.Fractional Fourier transform based features for speaker recognition using support vector machine[J].Computers &Electrical Engineering, 2013,39(2):550-557.
[6] Zou M C.A novel feature extraction methods for speaker recognition[J].Communications And Information Processing, 2012,288:713-722.
[7] Sahidullah M, Saha G.A novel windowing technique for efficient computation of MFCC for speaker recognition[J].IEEE Signal Processing Letters, 2013,20(2):149-152.
[8] Viola P, Jones M.Rapid object detection using a boosted cascade of simple features[C]∥2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.[S.l.]: IEEE, 2001:511-518.
[9] 罗森林,李金玉,潘丽敏.特定类型音频流泛化识别方法[J].北京理工大学学报,2011,31(10):1231-1235.
Luo Senlin, Li Jinyu, Pan Limeng.A generic method of recognizing specific type audio stream[J].Transactions of Beijing Institute of Technology, 2011,31(10):1231-1235.(in Chinese)
[10] Zue V, Seneff S, Glass J.Speech database development at MIT: TIMIT and beyond[J].Speech Communication, 1990,9(4):351-356.
[11] Pikrakis A, Giannakopoulos T, Theodoridis S.Gunshot detection in audio streams from movies by means of dynamic programming and Bayesian networks[C]∥Proceedings of IEEE ICASSP 2008.the 33rd International Conference on Acoustics, Speech, and Signal Processing.[S.l.]: IEEE, 2008:21-24.
[12] Chang H Y, Kong A L, Haizhou L.An SVM Kernel with GMM-supervector based on the bhattacharyya distance for speaker recognition[J].IEEE Signal Processing Letters, 2009,16(1):49-52.
(责任编辑:刘芳)
2D-Haar Acoustic Super Feature Vector Fast Generation Method
XIE Er-man,LUO Sen-lin,PAN Li-min
(Information System and Security and Countermeasures Experimental Center, Beijing Institute of Technology,Beijing 100081,China)
A fast and efficient acoustic feature super vector generation method was proposed to effectively improve the recognition accuracy and speed yielded by traditional frame based acoustic features.This paper makes 3 contributions: firstly, certain number of acoustic feature vectors extracted from continuous audio frames was combined to be an acoustic feature image;secondly, AdaBoost.MH algorithm was used to select higher representative 2D-Haar pattern combinations to construct super feature vectors;thirdly, random feature selection method was proposed to further improve the processing speed.Experimental results show that under 3 kinds of audio recognition occasions such as audio events recognition, speaker recognition, speaker gender recognition, the use of 2D-Haar acoustic feature super vector can make SVM, C5.0, AdaBoost algorithms obtain higher recognition accuracy than ones that MFCC, PLP, LPCC and other traditional acoustic features yielded, and can make the training processing 7~20 times faster and the recognition processing 5~10 times faster.
audio processing;audio recognition;2D-Haar feature super vector;2D-Haar acoustic feature;AdaBoost.MH
2013-12-11
国家“二四二”计划项目(2005C48);北京理工大学科技创新计划项目(2011CX01015)
谢尔曼(1981—),男,博士生,E-mail:erman@icce.org;罗森林(1968—),男,教授,博士生导师,E-mail:luoshenlin@bit.edu.cn.
潘丽敏(1968—),女,工程师,E-mail:panlimin@bit.edu.cn.
TP 391
A
1001-0645(2016)03-0295-07
10.15918/j.tbit1001-0645.2016.03.014
