副本放置中的更新策略及算法*
2016-11-22武继刚
李 帅,党 鑫,王 旭,武继刚
1.天津工业大学 计算机科学与软件学院,天津 300387
2.广东工业大学 计算机科学与技术学院,广州 510006
副本放置中的更新策略及算法*
李 帅1,党 鑫1,王 旭1,武继刚2+
1.天津工业大学 计算机科学与软件学院,天津 300387
2.广东工业大学 计算机科学与技术学院,广州 510006
LI Shuai,DANG Xin,WANG Xu,et al.Replica update strategy and algorithms for replica placement.Journal of Frontiers of Computer Science and Technology,2016,10(11):1633-1640.
副本技术广泛应用于云计算及分布式系统中,合理的数据副本放置是降低网络运行成本的重要手段,也是副本技术的核心问题。副本更新是针对网络中数据访问请求的动态变化而进行的副本添加与删除。针对副本放置问题,提出了一种基于多访问策略的副本动态更新算法MPFSF(min_placement far servers first)。该算法在引入通信距离限制的同时,尽可能多地重用网络中已存在的副本,并根据需要实施必要的副本更新,最大使用每个副本的处理能力,以便降低数据访问的时延,提高数据访问效率。最后通过实验结果和分析证明,该算法在不同的通信距离限制下,网络的运行成本得到了明显的降低,对原有算法的改进最高可达84.6%。
树形网络;副本放置;多访问策略;更新
1 引言
在树形网络中,副本放置问题是指在网络中如何合理地放置副本以及如何使放置的副本数量最少。通过将副本分布在网络中,可以进行负载均衡,提高数据的可用性、可靠性,降低访问时延,节省网络带宽等。副本放置问题广泛应用于视频点播、互联网服务、内容分发系统等重要领域[1-7]。
为了解决网络中的副本放置问题,许多副本放置算法被提出[8-15]。文献[8]证明了在一般网络中的副本放置问题是NP完全的。文献[9]提出了一种副本放置节点选择的分布式算法,并将该问题转化为背包问题,在考虑对副本的访问频率的基础上,提出了一种近似算法。文献[10]将一般网络中的副本放置问题转换成经典的装箱问题,并给出了多项式时间的近似算法。文献[11]提出了一种广域分布式存储系统中的通用数据副本放置策略,实现最小化系统数据通信时延。文献[12]面向线性总线网络的需要,提出了两种数据副本优化放置策略,可以最大化数据有效性和最小化数据访问的代价。文献[13]面向提高云系统可用性的需要,通过建立数学模型,描述了系统有效性和副本数量关系,给出了副本计量方法和副本机制算法。文献[14]在Hadoop架构内,根据节点间距离与负载计算每个节点的调度评价值,选择最佳节点放置数据副本。为了降低数据访问延迟,提高网络的服务质量(quality of service,QoS),文献[15]在选择节点放置副本时,考虑了副本和客户间的通信距离,证明了新问题在距离约束下是NP难的,并给出了在二叉树上解决该问题的一个多项式时间最优算法。文献[16]提出了一种改进的近似算法,在多项式时间内解决副本位置选择问题,提高了网络容错性能。文献[17-18]对已存在的一些副本放置和选择策略进行了较为全面的介绍和分析。
在树形网络中,叶节点作为客户周期性地发送若干数据访问请求,该请求从含有相应副本的祖先节点获得服务。树形网络中广泛使用最近策略分配副本,即任一客户的所有数据访问请求只能由一个副本提供服务,且该副本是在客户节点到根节点的唯一路径上,距离客户节点最近的副本节点。然而最近策略的限制过高,导致副本使用率过低。为了提高副本使用率,即以尽可能少的副本数量满足所有客户请求,文献[19]提出了两个高效的策略:(1)单一策略,任一客户的所有请求由一个副本提供服务,该副本可以是客户节点到根节点的唯一路径上的任一副本。与最近策略相比,单一策略提高了副本的使用率,但若为客户提供服务的副本放置偏远,可能会造成服务时间过长。(2)多访问策略,任一客户的所有数据访问请求可由该客户的祖先节点中的一个或多个副本共同提供服务。与最近策略和单一策略相比,多访问策略更加灵活且副本使用率最高。同时,文献[20]已证明异构网络中基于多访问策略的副本放置问题是NP难解的。
初始时,大多相关文献假设树形网络中不存在任何副本,然而客户发送的数据访问请求是单位时间动态变化,因此这种假设并不完全符合实际要求。为了有效降低网络运行成本,需要平衡重用旧副本和添加新副本之间的关系。其中,重用旧副本的成本通常小于添加新副本的成本。对于树形动态网络中的副本更新问题,目前仅有文献[21]考虑了基于最近策略的副本更新问题,并提出了一种动态规划求最优解的方法。
本文的主要贡献:区别于最近策略,提出了基于多访问策略的启发式更新算法,即最小放置更新算法。本文算法是以最大重用网络中已存在的副本,降低网络放置的副本数量为目标,从而实现降低网络运行及更新成本的目的。本文算法不仅能够最大使用网络中每个副本的处理能力,而且不会过多增加网络运行及副本更新成本。同时,在所研究的副本更新问题中,为了降低访问时延,提高访问效率,额外考虑了通信距离的限制,即所有客户的数据访问请求需要在一定通信距离内获得服务,从而保证整个网络服务质量。
2 问题描述
在给定的树形网络中,将其节点分成两部分,客户集合C和内部节点集合N。任一叶节点代表一个客户,且客户i∈C在每个单位时间内发送ri个数据访问请求。内部节点 j∈N是可以放置副本的节点,且放有副本的节点称为服务器,并可为该节点子树中的客户提供服务。
设R是网络中放置副本的集合,ris表示服务器s为客户i提供服务的请求数。根据多访问策略可知,任一客户i的数据访问请求ri都能够被一个或多个服务器Servers(i)∈R提供服务:

为了满足客户的请求,需要通过不断地在网络中放置副本来实现这一目标,而每个副本的处理能力是相异的。设服务器s的处理能力为Ws,则该服务器能够提供的数据访问请求不得超过其最大处理能力:

为了有效降低访问时延,提高访问效率,本文在增加通信距离受限的条件下研究副本更新问题,即客户的请求必须在有限的通信距离内获得服务。因此该问题可定义为:对任一客户i,为其提供服务的服务器s与其距离d(i,s)不得超过给定的边界值qi:

若某客户的数据请求被其自身处理,即该客户节点上放有副本,将该节点分割成一个叶节点和一个内部节点。因此,副本只能是放置在树形网络中的内部节点上,且该节点与放有副本节点之间的通信距离为0。
设E表示网络中已存在的服务器集合,即含有副本的内部节点集合,集合E中的每一个副本在客户请求发生变化后或被重用,或被删除。N-E表示由不含有副本的内部节点构成的集合,在更新过程中,可在集合N-E中选择节点添加新副本。由于重用已存在的副本代价小于放置副本的代价,删除副本的代价小于重用副本的代价,根据上述描述,添加副本s的代价为其自身的处理能力Ws,重用副本s的代价为αWs(0<α<1),删除副本s的代价为βWs(0<β<α<1)。则整个网络的运行及更新成本为:

本文的目标是找出一个新的服务器集合R,在保证每个客户的数据访问请求能够获得服务,且不超过其允许的最大通信距离前提下,使得cost_upd (R)最小,这可形式化如下:

3 副本更新的策略及算法
基于多访问策略的副本放置问题,文献[4]提出一种启发式算法——最近优先放置算法(multiple small QoS close servers first,MSQoSC)。其中qi表示客户i的最大获得服务的通信距离,d(i,r)表示客户i到根节点r的距离。
3.1 最近优先放置算法
所有客户i∈C按其qi升序排序,若同一父节点的客户节点具有相同的距离约束,则根据客户请求大小降序,从而得到表list,依次对表list中的每个客户节点执行以下操作。
(1)在距离qi内查询客户的祖先节点上是否存在已放副本。若不存在,在距离该客户节点最近的祖先节点上放置副本;否则,转(2)。
(2)判断已放副本的处理能力是否能够满足客户的数据访问请求。若满足,该副本的处理能力减去当前客户请求数,剩余处理能力可以继续处理其他客户请求;若不满足,转(3)。
(3)选择距离该客户最近祖先空节点添加副本,满足当前客户剩余请求。
该算法的时间复杂度为O(n2),n为树形结构大小。该算法并不适用于具有较小请求数的客户,可能会造成副本资源的极大浪费。随着客户请求每单位时间内发生变化,最近优先放置算法需要每单位时间内重复部署副本,这需要花费极高的代价。因此,需要重用网络中已存在的副本,从而降低整个网络的运行成本。由于重用已存在副本的代价小于添加新副本的代价,在重新部署副本的过程中,从降低整个网络运行成本角度出发,应优先使用已存在副本。
3.2 最小放置更新算法
对所有客户i∈C按其到根节点r的距离d(i,r)的升序进行排序,构成列表list_d,依次对表中的各个节点进行操作。若按d(i,r)降序顺序处理客户请求,在处理距离根节点较远的客户时,可能会在距离根节点较近的客户节点的祖先节点上放置副本,从而导致距离根节点较近的客户节点没有足够多的节点放置副本为其提供服务。
排序后,依次对表list_d中的每个客户节点,在其允许的通信距离内,选择节点放置副本为其提供服务。由于处理节点前其祖先节点可能已存在若干副本,为了充分使用每个副本,减少副本放置个数,首先判断已存在副本是否还有剩余能力继续为该节点服务。选择策略如下:
(1)判断该节点的祖先节点中是否存在副本(集合E中的副本),若有则进行副本更新,依次从距离该客户节点最远的节点开始,重用已存在的副本,并最大使用每一个副本的处理能力,直至客户请求均获得服务或不存在符合条件的节点。
(2)若该节点的祖先节点不含任何副本或所有已放副本的剩余处理能力均为0或不满足当前客户需求,依次在距离该客户最远的节点添加副本,直至所有请求获得服务或不存在能够继续放置副本的节点。
(3)对于集合E中的副本,若在副本更新过程中没有使用,则删除对应节点中的副本。
算法的伪代码描述如下。

3.3 时间复杂度
对于含有n个节点的树形结构,使用最小放置更新算法时,首先对所有的客户节点进行排序,最坏情况下时间复杂度为O(n lb n)。对任一客户选择节点重用或添加时,至多花费O(n),那么整个网络中的副本放置至多花费O(n2)。因此,算法在最坏情况下的时间复杂度为O(n2)。
4 实验
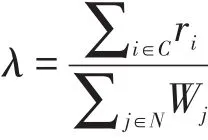
任一客户节点i的数据访问请求量ri为r≤ri≤2r且r= |N|/|C|×50×λ。
当考虑距离限制的副本放置问题时,根据通信距离范围可分成3类;(1)通信距离限制严紧,即q∈{1,2}。(2)通信距离限制为树高的一半,即q=h/2。(3)无通信距离限制,即q=h+1。其中,h为树的高度。
在含有n个节点的树形结构中随机放置|E|=N/4个副本。在树形网络中,重用旧副本的成本通常小于添加新副本的成本,而删除未重用的旧副本成本通常小于重用旧副本的成本,即0<β<α<1。因此,为了研究网络中重用和删除副本的代价对算法性能的影响,β/α取值为0.1,0.2,…,0.9。随机生成20个不同的且含有n=200个节点的树形结构。在同一树形结构中,本文提出的最小放置更新算法MPFSF和文献[4]中启发式算法MSQoSC,按照式(5)计算参数变化对整个网络的运行及更新成本的影响,如图1所示。
图1中,网络运行及更新成本是指网络中的副本运行和更新成本。在3种不同距离约束下,随着β/α值的变化,本文算法MPFSF始终保持着整体较低的网络运行及更新成本,而算法MSQoSC则需要花费极高的代价重新部署副本。当通信距离限制严紧时,即q∈{1,2},算法MPFSF和MSQoSC都需要放置较多的副本来满足所有客户的需求。然而本文算法在重新部署副本时,最大重用网络中已存在的副本,减少了副本添加的数量,从而降低了整个网络的运行及更新成本。当q=h/2和q=h+1时,通信距离限制宽松,本文算法通过重用网络中已存在的副本,最大程度上降低整个网络运行成本,而算法MSQoSC为满足所有的客户动态变化请求,需要花费极高的代价去重新部署网络中的副本。
随机生成若干含有n个节点的树形结构,10≤n≤300(n=|N|+|C|)。每个节点最多有5个孩子节点,任一服务器j的处理能力为50≤Wj≤150。网络中最重要的参数是负载,即所有客户的数据访问请求总和与所有服务器的处理能力之比,用λ表示,则
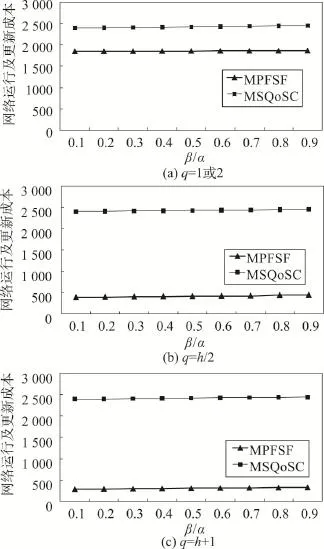
Fig.1 Effect of β/αfor algorithms in different distance constraints图1 β/α取值在不同距离限制下对算法的影响
为了进一步分析网络规模对网络中重用副本数的影响,取α=0.1,β=0.08。当网络中的节点数n=10, 50,100,150,200时,对同一树形结构,计算每个算法对副本的平均重用数目,如图2所示。
在不同的通信距离限制下,由本文算法MPFSF得到的整个网络运行及更新成本低于算法MSQoSC。由图2可知,本文算法MPFSF与MSQoSC相比,在最大使用网络中已存在副本的同时,降低了网络中新添加的副本数。
当q∈{1,2}时,通信距离限制严紧,本文算法MPFSF最大且优先重用网络中已有的副本,而算法MSQoSC逐步放置副本且可能在客户自身上放有副本,从而随着网络规模的变大,使得MPFSF算法和MSQoSC算法的重用副本数差别较大。
当q=h/2和q=h+1时,通信距离放宽,随着网络规模的变大,本文算法MPFSF和算法MSQoSC对已存在副本的重用数逐渐增加,而本文算法MPFSF优先重用网络中已有的副本。因而,MPFSF算法和MSQoSC算法的重用副本数差别较小。

Fig.2 Number of replicas reused in different distance constraints图2 在不同距离限制中的重用副本数
为了更直观地比较算法的性能,根据式(5)计算整个网络的运行及更新成本,如图3所示。

Fig.3 Effect of the size of a tree in different distance constraints图3 不同距离限制下网络规模对算法的影响
在图3中,对于不同网络规模的树形结构,本文算法MPFSF在不同的通信距离限制下,与算法MSQoSC相比,始终保持较低的网络运行及更新成本。
当q∈{1,2}时,通信距离限制严紧,需要放置较多的副本来满足客户的需求,从而随着网络规模的变大,网络运行成本逐渐增加。在此过程中,本文算法MPFSF优先重用网络中已存在副本且最大使用每一个副本,与算法MSQoSC相比,网络运行及更新成本平均降低了20.3%。
当q=h/2时,通信距离限制放宽,随着网络规模的变大,本文算法MPFSF对已存在副本的重用数逐渐增加,与严紧的通信距离限制相比,网络运行成本逐渐降低。算法MSQoSC随着网络规模的变大,重新部署副本所需花费的成本不断提高。与算法MSQoSC相比,网络运行及更新成本平均降低了79.8%。
当q=h+1时,即无通信距离限制,客户的请求可以被网络中任意放有副本的节点处理。随着网络规模的变大,本文算法MPFSF在最大重用已存在的副本同时,最大使用网络中每一个副本,而算法MSQoSC则需要不断地重新部署网络中的副本。与算法MSQoSC相比,网络运行及更新成本平均降低了84.6%。
5 结束语
树形网络广泛存在于计算机网络的各个领域,数据的共享访问是其亟待解决的一个重要问题。在实际网络中,客户发送的数据访问请求是动态变化的,为了确保网络的服务质量,降低数据访问延迟,副本更新策略的提出刻不容缓。本文提出了基于多访问策略解决树形网络中的副本更新问题的启发式算法,与算法MSQoSC相比,不仅最大使用网络中的每一个副本,同时大大降低网络运行及更新成本。
除了降低访问数据时延,减少副本更新代价,为了提高服务质量,网络中的副本放置还要考虑其他问题,如通信代价最小,网络的容错性等,这将是未来工作的主要方向。同时,也将考虑其他网络模型上副本放置和更新问题。
[1]Han Guodong,Zhu Yige.Replica placement for time-shifted IPTV system[J].Application of Electronic Technique,2012, 38(7):116-119.
[2]Lin Yifang,Liu Pangfeng,Wu Janjan.Optimal placement of replicas in data grid environments with locality assurance [C]//Proceedings of the 12th IEEE International Conference on Parallel and Distributed Systems,Minneapolis, USA,Jul 12-15,2006.Piscataway,USA:IEEE,2006:465-474.
[3]Corporation H P.Efficient dynamic replication algorithm using agent for data grid[J].The Scientific World Journal,2014, 14(3):713-730.
[4]Benoit A,Rehn-Sonigo V,Robert Y.Replica placement and access policies in tree networks[J].IEEE Transactions on Parallel and Distributed Systems,2008,19(12):1614-1627.
[5]Chen Y,Katz R H,Kubiatowicz J D.Dynamic replica placement for scalable content delivery[M]//Peer-to-Peer Systems.Berlin,Heidelberg:Springer,2002:306-318.
[6]Wauters T,Coppens J,De Turck F,et al.Replica placement in ring based content delivery networks[J].Computer Communications,2006,29(16):3313-3326.
[7]Fu Xiong,Wang Yibo,Zhu Xinxin,et al.QoS-aware replica placement in data grids[J].Systems Engineering and Electronics,2014,36(4):784-788.
[8]Tang Xueyan,Xu Jianliang.QoS-aware replica placement for content distribution[J].IEEE Transactions on Parallel and Distributed Systems,2005,16(10):921-932.
[9]Zaman S,Grosu D.A distributed algorithm for the replica placement problem[J].IEEE Transactions on Parallel and Distributed Systems,2011,22(9):1455-1468.
[10]Beaumont O,Bonichon N,Larchevêque H.Modeling and practical evaluation of a service location problem in large scale networks[C]//Proceedings of the 2011 IEEE International Conference on Parallel Processing,Taipei,China, Sep 13-16,2011.Piscataway,USA:IEEE,2011:482-491.
[11]Chandy J A.A generalized replica placement strategy to optimize latency in a wide area distributed storage system[C]// Proceedings of the 2008 International Workshop on Data-Aware Distributed Computing,Boston,USA,Jun 23-27, 2008.New York,USA:ACM,2008:49-54.
[12]Hsu F,Hu X D,Huang H J,et al.Optimal data replica placements in linear bus networks[C]//Proceedings of the 7th IEEE International Symposium on Parallel Architectures,Algorithms,and Networks,Hong Kong,China,May 10-12,2004.Piscataway,USA:IEEE,2004:129-134.
[13]Sun Dawei,Chang Guiran,Gao Shang,et al.Modeling a dynamic data replication strategy to increase system availability in cloud computing environments[J].Journal of Computer Science and Technology,2012,27(2):256-272.
[14]Lin Weiwei.An improved data placement strategy for ha-doop[J].Journal of South China University of Technology: Natural Science Edition,2012,40(1):65-71.
[15]Benoit A,Larchevêque H,Renaud-Goud P.Optimal algorithms and approximation algorithms for replica placement with distance constraints in tree networks[C]//Proceedings of the 26th IEEE International Parallel and Distributed Processing Symposium,Shanghai,May 21-25,2012.Piscataway,USA:IEEE,2012:1022-1033.
[16]Chudak F A,Williamson D P.Improved approximation algorithms for capacitated facility location problems[J].Mathematical Programming,2005,102:207-222.
[17]Kingsy G R,Manimegalai R.Dynamic replica placement and selection strategies in data grids—a comprehensive survey[J].Journal of Parallel and Distributed Computing,2014, 74(2):2099-2108.
[18]Benoit A.Comparison of access policies for replica placement in tree networks[C]//LNCS 5704:Proceedings of the 15th International Conference on Parallel Processing,Delft, The Netherlands,Aug 25-28,2009.Berlin,Heidelberg: Springer,2009:253-264.
[19]Benoit A,Rehn V,Robert Y.Strategies for replica placement in tree networks[C]//Proceedings of the 2007 IEEE International Parallel and Distributed Processing Symposium, Long Beach,USA,Mar 26-30,2007.Piscataway,USA:IEEE, 2007:1-15.
[20]Aupy G,Benoit A,Matthieu J,et al.Power-aware replica placement in tree networks with multiple servers per client[J]. Sustainable Computing:Informatics and Systems,2015,5: 41-53.
[21]Benoit A,Renaud-Goud P,Robert Y.Power-aware replica placement and update strategies in tree networks[C]//Proceedings of the 2011 IEEE International Parallel and Distributed Processing Symposium,Anchorage,USA,May 16-20,2011.Piscataway,USA:IEEE,2011:2-13.

LI Shuai was born in 1989.He is an M.S.candidate at Tianjin Polytechnic University.His research interest is data center.
李帅(1989—),男,江苏赣榆人,天津工业大学硕士研究生,主要研究领域为数据中心。

DANG Xin was born in 1983.He received the Ph.D.degree in intelligence science from Shizuoka University in 2013.Now he is a lecturer at Tianjin Polytechnic University.His research interests include embedded system,high performance architecture and machine learning.
党鑫(1983—),男,陕西合阳人,2013年于日本国立静冈大学信息科学系获得博士学位,现为天津工业大学讲师,主要研究领域为嵌入式系统,高性能体系结构,机器学习。

WANG Xu was born in 1989.She received the M.S.degree in computer technology from Tianjin Polytechnic University in 2015.Her research interests include high performance computing and data center.
王旭(1989—),女,山东城武人,2015年于天津工业大学计算机技术专业获得硕士学位,主要研究领域为高性能计算,数据中心。

WU Jigang was born in 1963.He received the Ph.D.degree from University of Science and Technology of China in 2000.Now he is a chair professor at Guangdong University of Technology.His research interests include theoretical computer science and high performance architecture.
武继刚(1963—),男,江苏沛县人,2000年于中国科学技术大学获得博士学位,现为广东工业大学计算机科学与技术学院特聘教授,主要研究领域为理论计算机科学,高性能体系结构。在国际重要学术期刊与会议上发表学术论文200余篇,主持国家自然科学基金课题、教育部博士点科研基金课题。
Replica Update Strategy andAlgorithms for Replica Placementƽ
LI Shuai1,DANG Xin1,WANG Xu1,WU Jigang2+
1.School of Computer Science and Software Engineering,Tianjin Polytechnic University,Tianjin 300387,China
2.School of Computer Science and Technology,Guangdong University of Technology,Guangdong 510006,China
+Corresponding author:E-mail:asjgwucn@outlook.com
Replica technology is widely applied in cloud computing and distributed systems,the reasonable data replica placement is an important means to reduce the operation cost of network,and is also the key issue of replica technology. Replica update is that the replicas are added and deleted when data access requirements dynamically change.Based on multiple policy,this paper proposes a dynamic updating algorithm named MPFSF(min_placement far servers first)to solve the update problem.According to the need to implement the necessary replica update,this paper reuses as much as possible the pre-existing replicas and maximizes the capacity of each replica to reduce the date access latency and improve the efficiency of data access,by adding the constraint of communication distance.The experimental results show that,for the proposed algorithm with update policy,the running cost of the network gets a considerable reduction under the different distance limits,and the best improvement is up to 84.6%in comparison to the state-of-the-art.
tree network;replica placement;multiple policy;update
10.3778/j.issn.1673-9418.1507048
A
TP302
*The National Natural Science Foundation of China under Grant No.61403276(国家自然科学基金);the Specialized Research Fund for the Doctoral Program of Higher Education of China under Grant No.20131201110002(高等学校博士学科点专项科研基金).
Received 2015-07,Accepted 2015-09.
CNKI网络优先出版:2015-10-09,http://www.cnki.net/kcms/detail/11.5602.TP.20151009.1542.004.html
