基于贝叶斯文本分类算法的垃圾短信过滤系统
2016-11-20王文霞
王文霞
(运城学院计算机科学与技术系,山西运城044000)
基于贝叶斯文本分类算法的垃圾短信过滤系统
王文霞
(运城学院计算机科学与技术系,山西运城044000)
目前,手机短信成为了人们所喜爱的一种通信方式,同时也成为了商业广告或诈骗信息的载体,对人们的生活,甚至对社会的安定造成了严重的威胁。因此本文采用贝叶斯文本分类算法对垃圾短信进行了分类,进而实现其过滤,并结合黑白名单技术模拟实现了一垃圾短信过滤系统。通过测试,该系统不仅能较为准确的实现对垃圾短信的过滤,还能减少对合法短信的误判率。
垃圾短信;文本分类;短信过滤;黑白名单;贝叶斯分类算法
短信由于其简短、方便、便宜、快捷等特点,成为了目前重要的通信手段之一。据统计,中国的手机用户数量于2010年就达到近7.4亿,全国日均短信发送两竟达21亿条,全年总量达到了约7840亿条[1]。但据互联网协会2008年调查的结果,用户接受到的垃圾短信平均每周多达8.29条,其中每周收到40条以上的用户比例居然占到了6.25%。这样,飞速发展的短信业务在给用户带了方便的同时,也存有垃圾短信、诈骗短信、谣言短信等给用户带来很大的困扰,甚至危害。因此,对用户接受到的短信进行分类,从而实现对垃圾短信的过滤是非常必要的。
针对该问题,本文首先采用了黑白名单技术进行短信的初步过滤,接着再采用贝叶斯分类算法对短信文本进行分类,实现再次过滤,从而提高对垃圾短信过滤的准确性,降低其误判率,最后基于Android平台模拟实现了一垃圾短信过滤系统。
1 垃圾短信过滤相关技术
1.1 黑白名单技术
黑名单(BlackList)是现有垃圾短信发送者的信息列表,该列表中的用户发送的短信将会被禁止。白名单(WhiteList)是不受限制的信用度很高的发送者列表,该列表中用户发送的短信默认是合法的,将不受限制。黑白名单技术简单易实现、占用资源少、效率高,但不足的是需用户手动维护,且当白名单中的用户发送垃圾短信时不会被禁止,从而给用户带了麻烦。所以本文采用黑名单技术只实现对短信的初步过滤,发挥其辅助作用。
1.2 垃圾短信分类
1.2.1 垃圾短信文本表示
垃圾短信一般采用文本形式表示信息,因此要对其进行处理,就需要首先把它转变成计算机可以识别的形式[2]。本文采用了基于空间向量模型(Vector Space Model,VSM)的文本表示形式。下面介绍一些VSM的基本概念[3]:
(1)特征项,它是指文本中能够代表该文本特征的基本单位;
(2)特征项权值,它是指特征项代表文本的能力的大小。特征项权值计算方法有很多,例如:布尔权重计算、平方根权重计算、TF-IDF权重计算等。其中TD-IDF权重计算最为常用,本文就采用了该方法进行了特征项的加权计算[4];
(3)文本向量,它是指由文本特征项的权值所构成的向量[5]。
1.2.2 垃圾短信关键词提取
关键词提取的目的是去除原选特征集中的不能有效的表示短信类型的特征词,以提高分级精度,降低计算复杂度。其主要思想是:对原特征项集中的每个特征,构造一个评价函数,独立计算其评价值,然后按评价值进行排序。目前,国内外学者已经研究出了多种关键词提取方法,比如文档频率、互信息与信息增益等[6]。本文采用了互信息关键词提取法(Mutual Information,MI)。
互信息是信息理论中词条和类之间的相关程度的一个关键概念,基本过程是先计算每一个词条和每一个类别的互信息数量;然后利用这些互信息值计算词条的总的互信息量;最后移除原始特征空间中低于某特定阈值的词条,保留高于阈值的词条。其优点是考虑了低频词的信息含量,即低频词比常用词的互信息值要高。
1.2.3 贝叶斯文本分类算法
如果手机号码不在黑名单中,要做的工作就是进行短信内容的辨识。本文采用了贝叶斯文本分类算法。它基于贝叶斯定理,其算法可以预测出某些样本属于每类成员的可能性。该算法实现的垃圾短信过滤具体步骤如下:
(1)统计训练样本集的不同类别的短信的数量;
(2)预处理短信的文本内容以去除没有关系的字符对文本分词的一些影响;
(3)去除后,接下来把训练样本短信先进行分词处理,随后读入分类器进行文本具体分类;
(4)收集垃圾短信关键词,同时利用特征项降维技术以更加高效的判定短信类型。本文采用互信息(MI)进行文本中的关键词进行提取;
(5)用训练好的分类器测试样本短信库中的短信;
(6)基于该分类器对未知类别的短信进行分类识别,进而获得各短信的分类。
2 垃圾短信过滤系统
2.1 系统总体设计
基于贝叶斯算法和黑白名单技术相结合的方法,使用Java语言,基于Android平台,模拟并实现了一个垃圾短信过滤系统。其核心处理过程如下:
(1)拦截短信发送的手机号码;
(2)查询该号码是否存在于设置的黑名单中,如果为真,信息直接会给用户一个提示:出现垃圾短信,并按用户意愿决定什么时候删除掉并投入垃圾箱;
(3)若黑名单中没有该号码,就基于贝叶斯分类算法,查看并确定短信是垃圾短信吗。如果最终给出的判断结果为垃圾短信,并在信息屏幕上出现收到垃圾短息的提示,询问用户是否要删除。
该系统的整体结构模块划分如图1所示。下面将对各个模块做一个简单说明[5]:

图1 系统功能模块图
(1)插入模块:实现的功能是将一个从来没有出现过的新电话号码加入到黑名单中;
(2)更新模块:修改黑名单中的电话号码;(3)删除模块:删除黑名单中的电话号码;
(4)短信预处理模块:预处理短信文本,如去除单个字符、符号、停用词以及数字等几乎对文本类别没有影响的词汇;
(5)中文分词模块:实现短信文本的分割;
(6)特征增益模块:指提取短信中的特征向量。系统根据分词后的结果,采用相应的特征抽取策略,各类短信的特征向量为:具有代表性的词;
(7)测试模块:主要是为了测试分类器的精确程度;
(8)分类器应用模块:应用分类器,对未知短信进行分类。
2.2 系统实现
2.2.1 开发环境及工具
(1)Android模拟器
Android Emulator可以像Android手机一样运行Android应用程序,是一个Dalvik虚拟机的运行工具,无需安装到手机,运行的结果可以在电脑上看到[7]。
(2)Android资源打包工具
Android的资源打包工具为AAPT(AAPT,Android Asset Packaging Tool)。APK.即为Android系统手机中的安装格式。可以通过AAPT,将编好的程序打包成.apk文件。
(3)系统开发环境
本系统采用Eclipse3.6开发环境,基于Android平台进行给短信过滤系统的模拟实现。
2.2.2 系统运行界面
完成源代码编辑和工程创建后运行程序。在Eclipse平台中选择Run→Open Run Dialog→type filter text→Android Application→SMS,点击对话框中的Run按钮,应用程序就能被加载运行,系统运行界面如图2所示。

图2 系统运行界面
2.3 系统测试结果分析
2.3.1 实验数据
我们自行收集短信410条,分成两部分,测试数据与训练数据。其中正常短信200条,垃圾短信2l0条。110条垃圾短信和100条正常短信组成训练样本,其余的短信测试用。
2.3.2 评价标准
文本分类的分类模型是根据训练数据得到的,进一步实现对不能确定类别的短信文本分类。其评价文本分类的准确度主要有正确率和查全率。
正确率:正确率是指分类系统对垃圾短信的识别能力,其值越大,将正常短信误判为垃圾短信的概率越大。计算公式为:

其中:
A——为被正确归类为垃圾短信的文本数,
B——为不属于垃圾短息但被被认定为垃圾短信的文本数,
C——为是垃圾短信但被归为正常短信的文本数,
查全率:即召回率。也表明系统对垃圾短信过滤的能力,召回率越高,将垃圾短信误判为正常短信的概率越小。计算公式为:
2.3.3 实验结果及分析
基于实验数据,启动Android模拟器,其模拟界面和我们平常使用手机的接收短信功能一样的。当判断为垃圾短信后,会显示提示接收方是否删除的界面。垃圾短信过滤系统对所有测试短信处理后的结果,如表1所示。
基于上节给出的评价标准,对该系统的短信过滤结果分析如下:
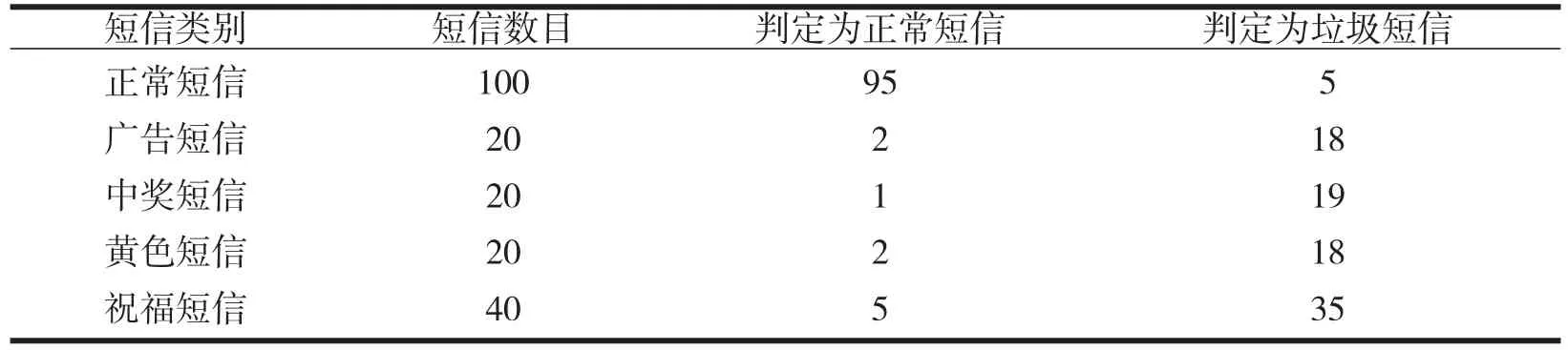
表1 垃圾短信过滤结果
(1)正常短信的正确率=95/(95+2+1+2+5)=95/105=90.5%;
(2)垃圾短信的正确率=(18+19+18+35)/(18+19+18+35+5)=90/95=94.74%;
(3)正常短信的召回率=95/(95+5)=95%;
(4)垃圾短信的召回率=(18+19+18+35)/(18+19+18+35+2+1+2+5)=90%。
从上述分析结果可知,该分类系统在分类垃圾短信的正确率和召回率都较高,实现了绝大部分垃圾短信的过滤功能。
3 总结
本文针对目前垃圾短信的泛滥以及其所带来的危害,设计开发了一垃圾短信过滤系统。该系统将黑白名单技术和贝叶斯分类算法两者相结合,先对短信进行了类别分类,进一步实现对垃圾短信的过滤;并基于Android模拟器对系统进行了模拟实现。最后,通过自行收集的实验数据对该系统进行了测试,结果表明该系统能够获得较好过滤效果,具有较高的准确率。
[1]刘国香,张钧锋.垃圾短信分类方式的探讨[J].沧州师范专科学校学报,2011,27(4):122-124.
[2]张启宇,朱玲,张雅萍.中文分词算法研究综述[J].情报探索,2008(11):53-56.
[3]包金龙.基于向量空间模型的信息检索系统的设计[J].情报杂志,2007(7):44-49.
[4]任姚鹏,陈立潮,张英俊,等.结合语义的特征权重计算方法研究[J].计算机工程与设计,2010,31(10):2381-2383.
[5]付克志.基于N-Level VSM在Web信息检索中的研究[J].计算机工程与应用,2006(16):158-160.
[6]关娜.基于文本分类算法的垃圾短信过滤技术[D].成都:电子科技大学,2008.
[7]董月琴.基于Android的垃圾短信处理系统的研究与设计[D].淮南:安徽理工大学,2011.
〔责任编辑 高海〕
Spam Filtering System Based on Bayes Text Classificaiton Algorithm
WANG Wen-xia
(Department of Computer Science and Technology,Yuncheng University,Yuncheng Shanxi,044000)
At present,SMS(Short Message Service)has become a favourite communication way for people.Meanwhile,SMS has become a carrier of commercial advertisement and fraud information too.Thereby these spam messages have brought serious threat for people’s life and even social stability.So the Bayes text classification algorithm is adopted to classify the spam message,and even to achieve its filtering.And a spam filtering system is simulatively implemented combined with black and white list technology.Through test,this system can not only accurately achieves the spam filtering,but also reduce the misjudgment rate for legal texts.
spam message;text classification;message filtering;black and white list;bayes classifiction algorithm
TP391
A
1674-0874(2016)03-0017-03
2015-10-10
运城学院教学改革研究项目[JG201418]
王文霞(1979-),女,山西运城人,硕士,讲师,研究方向:算法分析与数据挖掘。
