不确定数据流中频繁模式的并行挖掘算法
2016-11-09常艳芬王辉兵
常艳芬 王 乐 王辉兵
1(宁波大红鹰学院信息工程学院 浙江 宁波 315175)2(大连理工大学创新实验学院 辽宁 大连 116024)
不确定数据流中频繁模式的并行挖掘算法
常艳芬1王乐2*王辉兵2
1(宁波大红鹰学院信息工程学院浙江 宁波 315175)2(大连理工大学创新实验学院 辽宁 大连 116024)
不确定数据集中频繁模式挖掘的研究热点之一是挖掘算法的时空效率的提高,特别在目前数据量越来越大的情况下,实际应用对挖掘算法效率的要求也更高。针对动态不确定数据流中的频繁模式挖掘模型,在算法AT-Mine的基础上,给出一个基于MapReduce的并行挖掘算法。该算法需要两次MapReduce就可以从一个滑动窗口中挖掘出所有的频繁模式。实验中,多数情况下通过一次MapReduce就可以挖掘到全部频繁项集,并且能按数据量大小均匀地把数据分配到各个节点上。实验验证了该算法的时间效率能提高1个数量级。
不确定数据频繁模式数据挖掘并行算法
0 引 言
由于数据的不确定性普遍存在于现实世界各个领域中,例如根据对电子商务网站页面的访问记录,只能获得潜在客户对特定商品购买倾向的一个估计(即一个概率性指标);并且随着数据量快速的增加,而频繁模式挖掘是数据挖掘中一项重要技术,因此不确定数据流频繁模式挖掘算法研究成为数据挖掘领域的研究热点之一。
数据流上的频繁模式概念,仍然定义在单个事务上,不考虑跨事务的模式(不同时间上的组合模式);其挖掘方法,一般是采用“窗口”获取当前用户关注的数据,然后基于已有的静态数据集上的频繁模式挖掘算法,设计数据流中被关注数据上的挖掘算法。
目前有3种典型的窗口模型[1]:界标窗口模型、时间衰减窗口模型和滑动窗口模型,如图1所示。界标窗口模型中的窗口指特定一时间点(或数据流中一条特定的数据)到当前时间(或当前条数据)之间的数据,如图1(a)所示,在C1、C2和C3时刻,窗口中的数据分别包含了从S点到C1点、C2点和C3点之间的数据。时间衰减窗口模型和界标窗口模型所包含的数据是相同的,只是衰减窗口中的每条数据有不同的权重,距离当前时间越近,数据的权重越大,如图1(b)所示。实际上,时间衰减窗口模型是界标窗口模型的一个特例。滑动窗口模型中,每次处理数据的个数固定或者是每次处理数据的时间段长度是固定的,如图1(c)所示。
已有的不确定数据流上频繁模式挖掘算法主要通过以上三种窗口方法来获取要处理的数据,即窗口中的数据,然后基于静态数据集上的挖掘算法(如UF-Growth)来挖掘窗口数据中的频繁模式[2-7]。
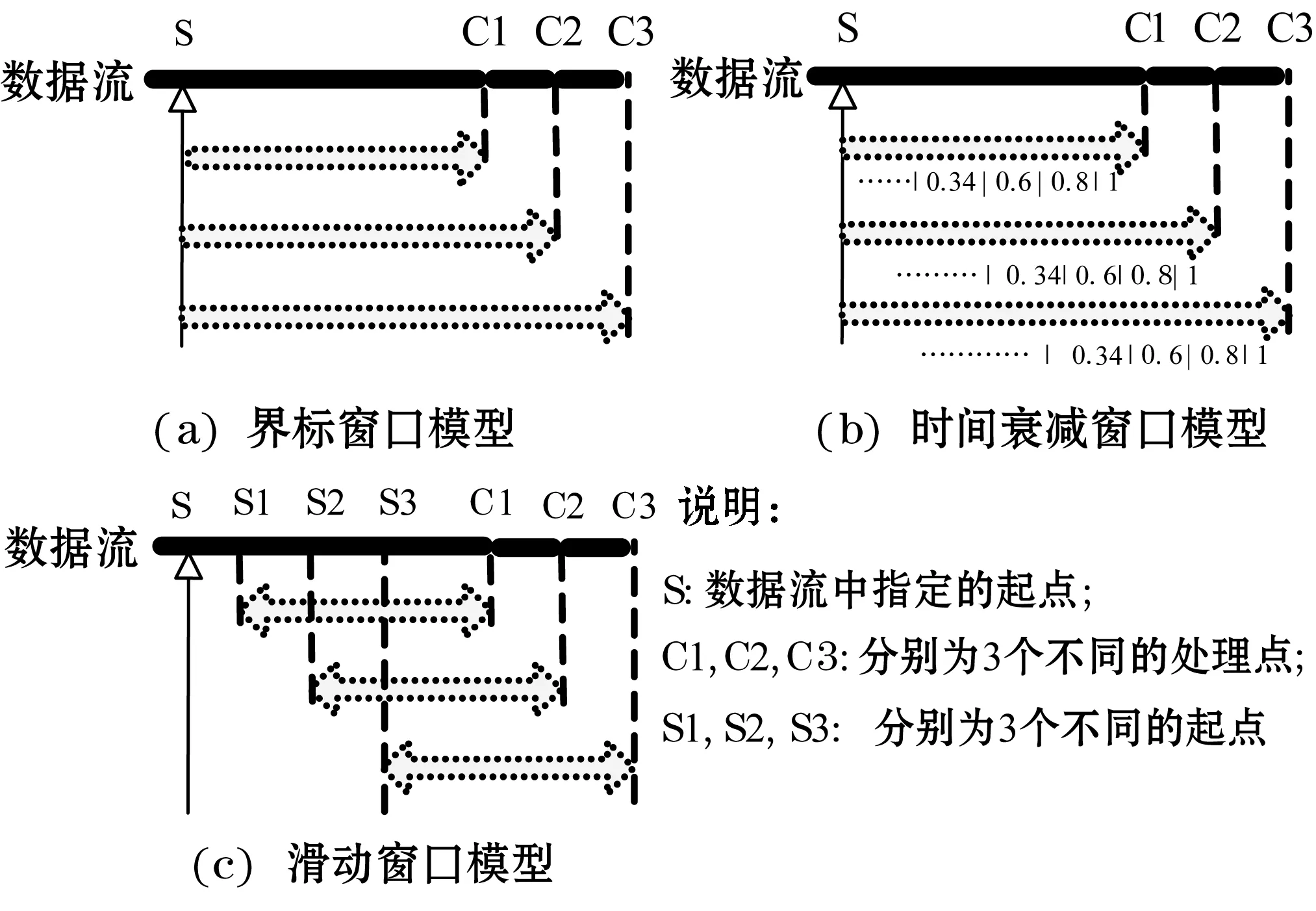
图1 三种窗口模型
Leung等[4]提出两个基于滑动窗口的算法UF-streaming和SUF-Growth,每个滑动窗口包含固定批数的数据,当一个窗口满了以后,每来一批数据,都会先从窗口中删除一批最老的数据,然后再将新来数据添加到窗口中。算法UF-streaming采用FP-streaming[8]的方法,预定义两个最小期望支持数preMinsup和minSup (preMinsup < minSup)。UF-streaming算法利用UF-Growth挖掘每批数据中的期望支持数大于等于preMinsup的项集做为候选项集,并保存到一个树UF-stream上,UF-stream树上每个节点记录窗口中每批数据的期望支持数;当新来一批数据中的候选项集被添加到UF-stream树上之前,会将树上最老批次数据对应的候选项集从树上删除;当一个节点上总的期望支持数(所有批上的期望支持数的和)大于等于minSup,则该节点到根节点对应的项集就是一个频繁模式。SUF-Growth算法主要基于算法UF-Growth,该算法将每批数据添加到树UF-Tree的时候,节点分别记录每批数据的期望支持数;当新来一批数据的时候,会首先将树上最老批次的数据删除,然后将新来数据添加到树上;挖掘频繁模式的时候从该树上读取数据,采用模式增长的方式进行。
文献[6,7]中提出的算法采用的是时间衰减窗口模型,仍然采用UF-Tree来存储窗口中的事务项集。由于UF-Tree共享同一个节点时,不仅要求项相同,还要求项对应的概率值也相同,因此该树结构的存储需要大量的空间,同时也需要较多的处理时间。而另外一个静态数据集上的频繁模式挖掘算法AT-Mine[9]可以将数据集以较大的压缩比维护在一棵树上,同时没有丢失事务项集的概率信息,最终算法的挖掘效率得到了较大的提高。
为了快速地处理数据以及大规模的数据,并行算法来进行数据挖掘是一个重要的方法。 目前,模式挖掘的并行算法主要在MapReduce环境下实现,其研究主要集中在静态数据集的频繁模式挖掘中。文献[10-17]中的算法是基于Apriori,并且采用多次MapReduce,如果频繁模式中最大的模式长度是K,则需要(K+1)次MapReduce。算法PFP[18]是基于FP-Growth,其仅仅需要两次MapReduce,但是它分配到各个节点上数据存在大量的冗余,并且不能将数据按数据块的大小较为均匀地分配到各个节点上处理,因此这也会影响到它处理的时间效率。
以上并行算法主要是处理静态确定数据集中的频繁模式挖掘,针对不确定数据流中的频繁模式挖掘,在算法AT-Mine[9]的基础上,本文给出一个基于MapReduce的并行挖掘算法来挖掘一个窗口中的数据。该算法最多需要两次MapReduce就可以从一个窗口中挖掘出所有的频繁模式,在本文的实验中,多数情况下只需要一次MapReduce,并且数据能按数据量大小均匀分配到各个节点上。实验验证了本文提出算法的有效性。
1 问题定义
设D是一个包含n个事务的不确定数据集(记D= {T1,T2,…,Tn}),并且包含m个不同的项(记I= {i1,i2,…,im}),其中D中的第j个事务tj(j=1,2,…,n)表示为{(x1:p1),(x2:p2),…,(xv:pv) },其中{x1,x2,…,xv}是项集I的一个子集,pu(u= 1,2,…,v)是事务项集中项iu的概率。数据集D中事务个数可以用|D|表示,也被称为数据集的大小;包含k个不同项的项集被称为k-项集(k-itemset),k是项集的长度;|D|表示数据集的大小。
定义1事务项集t中的项集X的概率记为p(X,t),定义为p(X,t)=∏x∈X∧X⊆tp(x,t),其中p(x,t)是事务项集t中项x的概率。
定义2在不确定数据集D中,项集X的期望支持数记为expSN(X),定义为expSN(X)=∑t⊇X∧t∈Dp(X,t)。
定义3设minExpSup为用户预定义的最小期望支持阈值(Minimumexpectedsupportthreshold),则最小期望支持数minExpSN定义为minExpSN=minExpSup×|D|。
在文献[2-4,6-7,19-27]中,不确定数据集中的频繁模式定义为:在不确定数据集D中,如果项集X的期望支持数不小于预定义的最小期望支持数minExpSN,则该项集就是D中的一个频繁项集或频繁模式。不确定数据集中的频繁项集挖掘就是发现期望支持数不小于最小支持数的所有项集。
定义4在不确定事务数据集D中,频繁项集X的任一超集都不可能是频繁项集,则项集X也称为最大频繁项集(或最大频繁模式)。
定义5在不确定事务数据集D中,项集X(或项X)的∑t⊇X∧t∈D∧x∈tP(X,t)×max(p(x,t))称为X的超一项集的估计期望支持数(其中,max(p(x,t))表示事务项集t中最大的概率值),记为EexpSN(X)。
定义6在一个数据集中,一个项集X的支持数(sn) 是指数据集中包含项集X的事务项集个数。
定义7当一个数据集被划分为多个数据块时,一个数据块上包含的事务个数与最小期望支持阈值的乘积称为该数据块上的局部最小期望支持数。
定义8一个项集在数据集的一个数据块上的期望支持数大于等于该数据块的局部最小期望支持数,则该项集被称为该块上的局部频繁项集。
性质1一个频繁项集的所有子集都是频繁项集,一个非频繁项集的所有超集都是非频繁项集。
2 本文提出的算法
本文给出的不确定数据流上的频繁模式挖掘算法采用滑动窗口方法,针对每个窗口中的数据,提出一个挖掘不确定数据流中频繁项集的算法MFPUD-MR(Mining Frequent Pattern from Uncertain Data based on MapReduce)。该算法主要包含三步:第一步,根据计算节点个数,将滑动窗口中数据集划分成若干个数据量相同的数据块,然后在MapReduce框架下并行找出每个数据块上的局部频繁项集作为候选项集;第二步,对候选项集进行筛选,减少候选项集的个数;第三步,在MapReduce框架下并行计算候选项集中每个项集的总期望支持数,其中总期望支持数不小于最小期望支持数的项集就是频繁项集。
2.1挖掘候选项集
算法MFPUD-MR中第一步挖掘候选项集的子算法如算法1所示,在每个节点上利用AT-Mine算法找到局部频繁模式,并统计所有一项集的期望支持数和局部数据集上的事务个数。
算法1SubProcedure MiningCandidate(D,minExpSup)
输入:不确定数据集D,最小期望支持阈值minExpSup
输出: 候选项集CFs
Begin
run(Mapper,Reducer)
End
Mapper(minExpSup,LD)
// LD 是一个划分好的数据块
Begin
利用AT-Mine算法挖掘数据块LD上局部频繁项集作为候选项集(候选项集的集合记为CFs);
For each itemset imst in CFs
Output(imst,count);
//计算候选项集中每个项集的期望支持数
EndFor
End
Reducer(
//计算CFs 中的每个项集在所有数据块上总的期望支持数
Begin
Output(key,sum(values))
//key 是CFs 中的项集,values 是每个项集的期望支持数
End
定理1算法1挖掘出的候选项集包含了数据集中全部的频繁项集。
设项集X是一频繁项集,由于频繁项集的期望支持数不小于最小期望支持阈值,因此X一定在一个或多个数据块上是频繁项集,
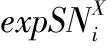
2.2对候选项集的剪枝处理
算法MFPUD-MR中第二步是对候选项集进行剪枝,剪枝策略如下:
策略1:如果一个项集在一部分数据集上的期望支持数大于等于最小期望支持数,则该项集在全局数据集上的期望支持数一定也大于等于最小期望支持数,所以该项集一定是一个频繁项集。因此这部分项集可以从候选项集移入到频繁项集集合中。
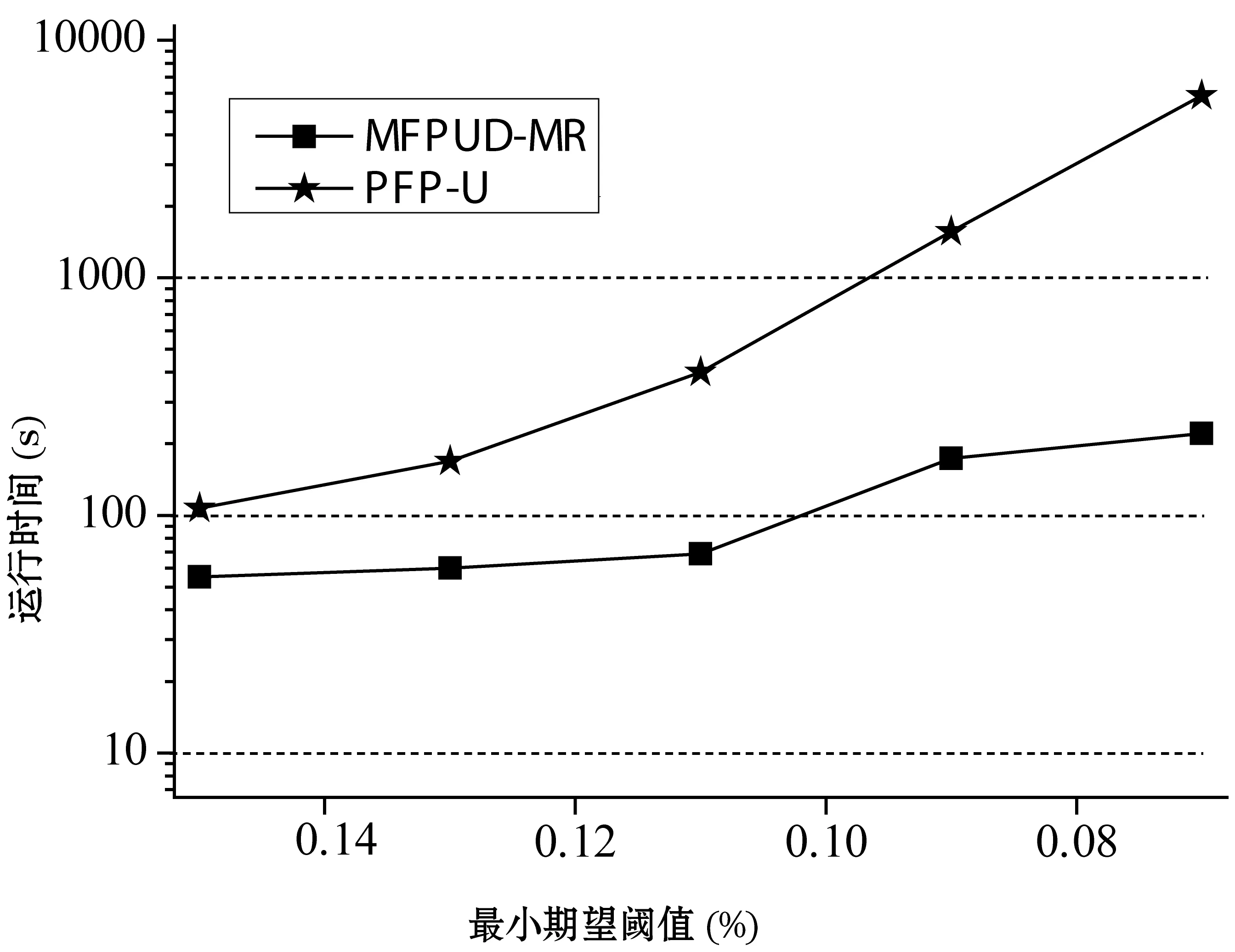
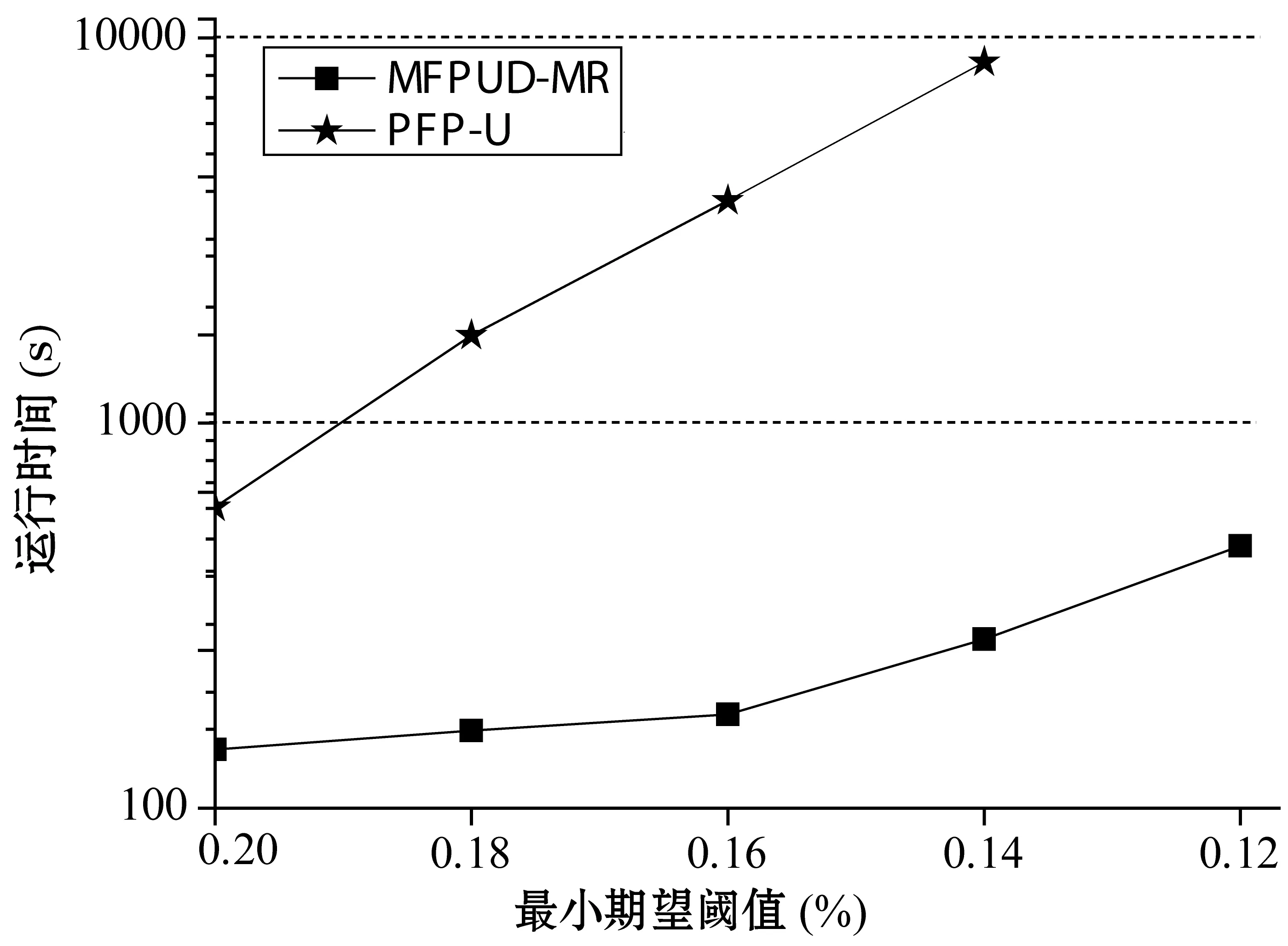
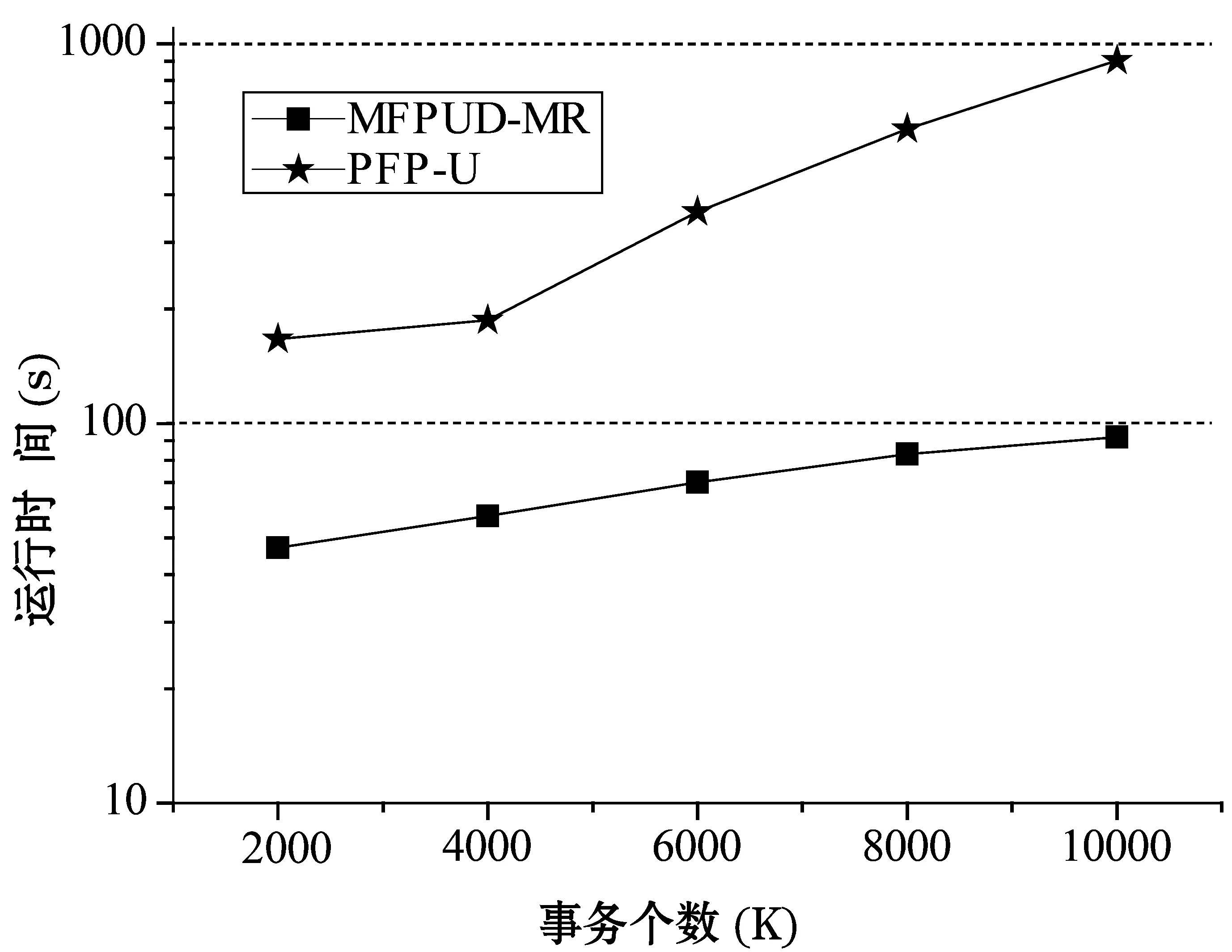
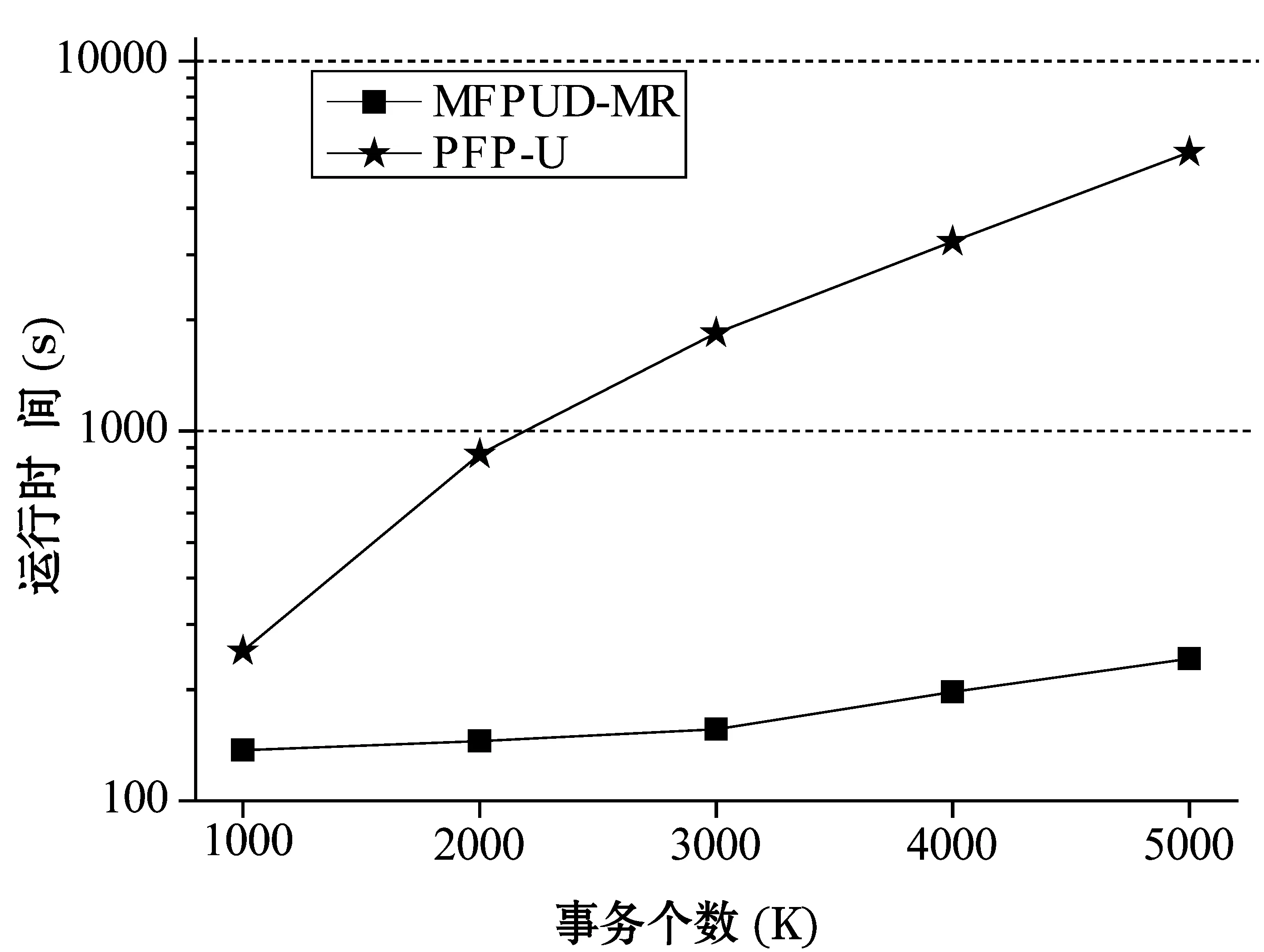
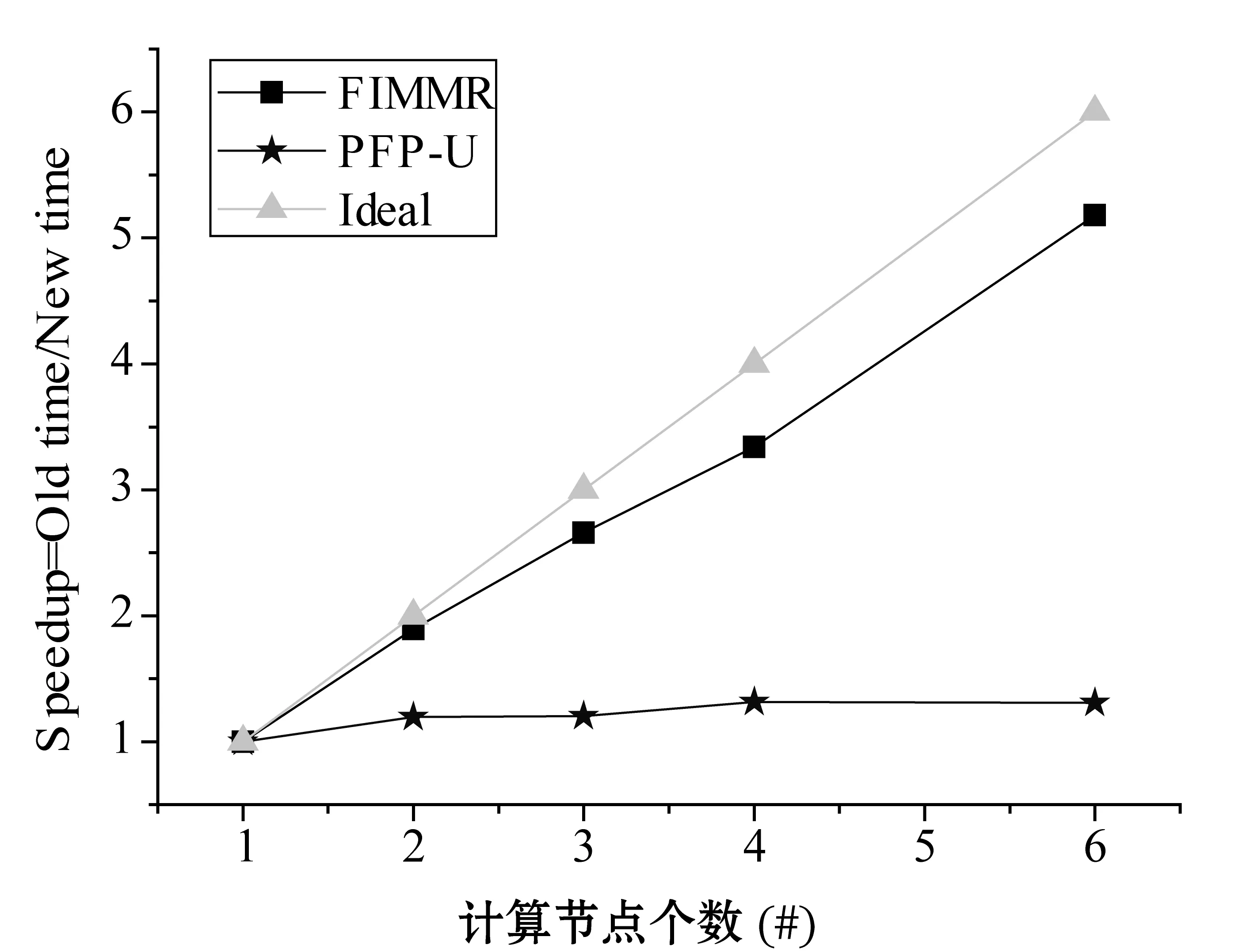
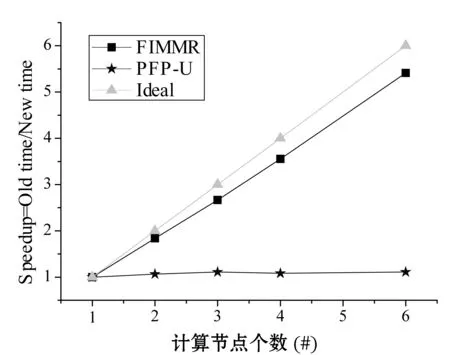
策略2:项集X在部分数据块D1,D2,…,Dj上是频繁的,设期望支持数之和为S1;在其它数据块Dj+1,Dj+2,…,Ds不是频繁的。设数据块Dj+1,Dj+2,…,Ds总事务个数为S,如果S1+S×minExpSup 策略3:算法1中返回所有1项集的期望支持数,包括非频繁1项集,根据性质1,如果候选项集包含非频繁一项集中项,则该候选项集一定是非频繁项集,因此可以从候选项集集合中删除。 2.3从处理后的候选项集中确认频繁项集 算法MFPUD-MR经过第二步对候选项集的处理,如果候选项集不为空,则进行第三步,第三步是计算候选项集中每个项集在全局数据集中总期望支持数算法如算法2所示。 算法2IdentifyFrequentItemsets(D,minExpSup,CFs) 输入: 不确定数据集D,最小期望支持阈值minExpSup,候选项集CFs 输出: 频繁项集FIs Begin run(Mapper,Reducer) End Mapper(LD,CFs) Begin For each transaction itemset Tiin LD For each itemset X in CFs If X is the subset of Ti X.expSN+= p(X,Ti); EndIf EndFor EndFor For each itemset X in CFs output(X,X.expSN) EndFor End Reducer(key,values,minExpSup) //找出总期望支持数(sum)不小于最小期望支持数的项集 Begin sum=0; For each value in values sum+=value EndFor If sum>= minExpSup output(key,sum) EndIf End 为了测试本文算法的有效性,本文将PFP算法[18]改为不确定数据集中的频繁模式挖掘算法,这里记为PFP-U,算法MFPUD-MR和PFP-U采用Python实现,AT-Mine是Java语言实现。为了测试算法MFPUD-MR的运算效率、加速度比和算法的扩展性,本节设计了如下的实验。 实验平台使用26个节点组成的集群,其中包含1个主节点,1个调度节点,1个备份节点, 23个数据节点。每个节点的硬件配置为2.5 GHz双核CPU及8 GB内存,软件配置为ubuntu 12.04及Hadoop 0.22.0。 利用IBM数据生成器来产生两个数据T20I10D10000K和T40I20D5000K,其中T表示事务项集的平均长度,I表示事物项集默认阈值下的频繁项集长度,D表示数据集中事务个数(其中K表示1000);同时采用常用方法,为每个事务项集的每项随机生成一个范围在(0,1]的数做为概率值。由于MapReduce默认将一个大的数据文件分割成68M大小的数据块,本文中为了充分利用23个数据节点,本文将被测试的数据文件大小均匀的分割为20个小数据文件。 3.1不同最小期望阈值下的运行时间对比 (a) 数据集T20I10D10000K (b) 数据集T40I20D5000K 图2显示了2个算法在不同支持度的运行时间。可以看出本文提出的方法MFPUD-MR的时间效率明显高于PFP-U,这是因为随着支持度的降低,频繁1项集的个数增加的比较快,PFP-U中也会出现更多更长的子事务项集,因而随着最小支持度的降低,算法PFP-U的运行时间增加的比较快;而算法MFPUD-MR第一次MapReduce产生了全局候选项集,通过候选项集的筛选,候选项集的个数减少了很多,甚至有时候候选项集为空,不需要第二次的MapReduce来统计候选项项集的期望支持数,因此算法MFPUD-MR的时间性能比较稳定。 3.2算法扩展性 (a) 数据集T20I10D10000K (b) 数据集T40I20D5000K 图3是采用不同数据规模的数据集来测试2个算法的时间性能。当数据规模发生变化的时候,频繁1项集的个数变化不大,但是算法PFP-U会产生子事务项集的个数增加的比较快,因此算法PFP-U的运行时间基本上都是成比例的增加;而算法MFPUD-MR在挖掘局部频繁项集的时候,它的运行时间会随着数据规模的增加而稍微的增加,并且很多情况下,不需要第二次的MapReduce来统计候选项项集的期望支持数,因而算法MFPUD-MR的时间性能比较稳定。 3.3算法的加速度性能 (a) 数据集T20I10D10000K (b) 数据集T40I20D5000K 图4是2个算法在不同数据集上加速比实验结果。而加速度是指算法在一个节点上总运行时间和在多个节点上的总运行时间的比值。理想的加速度(Ideal)是随着节点个数的增加,算法的运行时间也成比例的增加,如图4中Ideal的那条线。算法MFPUD-MR的加速度和理想的加速度(Ideal)比较接近,之所以不能完全达到理想的加速度这是因为节点越多,节点之间的通讯需要的时间也会越多,这会导致总的运行时间增加。而算法PFP-U不能将数据按大小均匀的分配到各个节点上执行,而它的运行时间总是和一个负担重的节点上任务相关。综上,算法MFPUD-MR的加速度比较理想。 本文给出一个不确定数据集中的频繁项集挖掘算法MFPUD-MR。首先并行挖掘出小数据块上的局部频繁项集作为候选项集,然后对候选项集进行筛选:确定的频繁项集从候选项集中移到频繁项集集合中,确定的非频繁项集从候选项集中删除;最后再执行一次MapReduce对剩余候选项集进行全局期望支持数进行统计即可得到频繁项集。从本文的实验中可以发现,本文提出的候选项集剪枝策略可以很好地对候选项集进行筛选,在很多情况下,进行剪枝后,候选项集都为空,即不需要第二次执行MapReduce。本文实验也很好地验证了MFPUD-MR算法的时间效率明显高于算法PFP-U,同时该算法的加速度还比较理想。 [1] Rawat R,Jain N.A Survey on Frequent ItemSet Mining Over Data Stream[J].International Journal of Electronics Communication and Computer Engineering (IJECCE),2013,4(1):86-87. [2] 廖国琼,吴凌琴,万常选.基于概率衰减窗口模型的不确定数据流频繁模式挖掘[J].计算机研究与发展,2012,49(5):1105-1115. [3] 刘殷雷,刘玉葆,陈程.不确定性数据流上频繁项集挖掘的有效算法[J].计算机研究与发展,2011(S3):1-7. [4] Leung C K,Hao B.Mining of frequent itemsets from streams of uncertain data[C]//Proceedings of the International Conference on Data Engineering,Shanghai,China,March 29-April 2,IEEE Computer Society,Washington,DC,2009. [5] 王爽,王国仁.基于滑动窗口的Top-K概率频繁项查询算法研究[J].计算机研究与发展,2012,49(10):2189-2197. [6] Leung C K,Jiang F.Frequent itemset mining of uncertain data streams using the damped window model [C]//Proceedings of the 26th Annual ACM Symposium on Applied Computing (SAC 2011),TaiChung,Taiwan,March 2-24.Association for Computing Machinery,2011.[7] Leung C K,Jiang F.Frequent pattern mining from time-fading streams of uncertain data[C]//Proceedings of the 13th International Conference on Data,Warehousing and Knowledge Discovery (DaWaK 2011),Toulouse,France,August 29-September 2,Springer Verlag,2011. [8] Giannella C,Han J,Pei J,et al.Mining frequent patterns in data streams at multiple time granularities[J].Next generation data mining,2003,2003(212):191-212. [9] Wang L,Feng L,Wu M.AT-Mine:An Efficient Algorithm of Frequent Itemset Mining on Uncertain Dataset[J].Journal of Computers,2013,8(6):1417-1426. [10] 李玲娟,张敏.云计算环境下关联规则挖掘算法的研究[J].计算机技术与发展,2011(2):43-46. [11] 戎翔,李玲娟.基于MapReduce的频繁项集挖掘方法[J].西安邮电学院学报,2011(4):37-39. [12] 黄立勤,柳燕煌.基于MapReduce并行的Apriori算法改进研究[J].福州大学学报(自然科学版),2011(5):680-685. [13] Xiao T,Yuan C,Huang Y.PSON:A parallelized SON algorithm with MapReduce for mining frequent sets[C]//Proceedings of the 2011 4th International Symposium on Parallel Architectures,Algorithms and Programming,Tianjin,China,December 9-11,IEEE Computer Society,2011. [14] Riondato M,Debrabant J A,Fonseca R,et al.PARMA:A parallel randomized algorithm for approximate association rules mining in MapReduce [C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management (CIKM 2012),Maui,HI,United states,October 29-November 2,Association for Computing Machinery,2012. [15] Yang X Y,Liu Z,Fu Y.MapReduce as a programming model for association rules algorithm on Hadoop[C]//Proceedings of the 3rd International Conference on Information Sciences and Interaction Sciences,Chengdu,China,June 23-25,IEEE Computer Society,2010. [16] Cryans J,Ratte S,Champagne R.Adaptation of apriori to MapReduce to build a warehouse of relations between named entities across the web[C]//Proceedings of the 2nd International Conference on Advances in Databases,Knowledge,and Data Applications (DBKDA 2010),Menuires,France,April-April 16,IEEE Computer Society,2010. [17] 余楚礼,肖迎元,尹波.一种基于Hadoop的并行关联规则算法[J].天津理工大学学报,2011(1):25-28. [18] Li H,Wang Y,Zhang D,et al.PFP:Parallel FP-growth for query recommendation[C]//Proceedings of the 2008 2nd ACM International Conference on Recommender Systems25,2008,Lausanne,Switzerland,October 23-25.Association for Computing Machinery,2008. [19] Lin C W,Hong T P.A new mining approach for uncertain databases using CUFP trees[J].Expert Systems with Applications,2012,39(4):4084-4093. [20] Aggarwal C C,Yu P S.A survey of uncertain data algorithms and applications[J].IEEE Transactions on Knowledge and Data Engineering,2009,21(5):609-623. [21] Leung C K,Mateo M A F,Brajczuk D A.A tree-based approach for frequent pattern mining from uncertain data[C]//Proceedings of the 12th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2008),Osaka,Japan,May 20-23,Springer Verlag,2008. [22] Sun X,Lim L,Wang S.An approximation algorithm of mining frequent itemsets from uncertain dataset[J].International Journal of Advancements in Computing Technology,2012,4(3):42-49. [23] Calders T,Garboni C,Goethals B.Approximation of frequentness probability of itemsets in uncertain data[C]//Proceedings of the IEEE International Conference on Data Mining (ICDM 2010),Sydney,NSW,Australia,Dec.13-17,IEEE Computer Society,Washington,DC,2010. [24] Wang L,Cheung D W,Cheng R,et al.Efficient Mining of Frequent Itemsets on Large Uncertain Databases[J].IEEE Transactions on Knowledge and Data Engineering,2012,24(12):2170-2183. [25] Leung C K,Carmichael C L,Hao B.Efficient mining of frequent patterns from uncertain data[C]//Proceedings of the IEEE International Conference on Data Mining Workshops (ICDM Workshops 2007),Omaha,NE,United states,Oct.28-31,IEEE Computer Society,Washington,DC,2007. [26] Aggarwal C C,Li Y,Wang J,et al.Frequent pattern mining with uncertain data[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2009),Paris,France,June 28-July 1,ACM,NewYork,2009. [27] Liu Y.Mining frequent patterns from univariate uncertain data[J].Data and Knowledge Engineering,2012,71(1):47-68. A PARALLEL MINING ALGORITHM WITH FREQUENT PATTERN FOR UNCERTAIN DATA STREAM Chang Yanfen1Wang Le2*Wang Huibing2 1(School of Information Engineering,Ningbo Dahongying University,Ningbo 315175,Zhejiang,China)2(SchoolofInnovationExperiment,DalianUniversityofTechnology,Dalian116024,Liaoning,China) One of the research focuses of frequent pattern mining in uncertain dataset is to improve time and space efficiency of the mining algorithm,especially in the case of growing data amount increase at present,the practical applications have higher demand on the efficiency of mining algorithms as well.Aiming at the frequent pattern mining model for dynamic uncertain data streams,we propose a MapReduce-based parallel mining algorithm on the basis of the algorithm of AT-Mine.By invoking twice at most the MapReduce procedures this algorithm can mine all the frequent patterns from a sliding window.In experiments presented in the paper,in majority cases by only executing MapReduce once it is able mine all frequent itemset,and the stream data can be distributed uniformly to each node according to the size of their amount.Experiments validate that the proposed algorithm can raise the time efficiency one order of magnitude. Uncertain dataFrequent patternData miningParallel algorithm 2015-05-04。国家自然科学基金项目(61370200);宁波市自然科学基金项目(2013A610115,2014A610073);宁波市软科学研究计划项目(2014A10008);浙江省科技厅计划项目(2016C31128);浙江省教育厅一般科研项目(Y201533234)。常艳芬,讲师,主研领域:数据挖掘与软件工程。王乐,副教授。王辉兵,讲师。 TP311.13 A 10.3969/j.issn.1000-386x.2016.09.0053 实验结果
4 结 语
