HDFS小文件读写优化策略*
2016-10-28朱永强周珂李丹赵亚萌
朱永强++周珂++李丹++赵亚萌


DOI:10.16644/j.cnki.cn33-1094/tp.2016.09.003
摘 要: HDFS是一种高容错性的分布式系统。它支持的数据集在GB到TB级别,然而对大量小文件存取支持不足。由于在处理大数量级的小文件时,会使得NameNode内存消耗过度,造成文件的存取性能降低。因此提出了一种根据文件类型分类小文件的合并策略。通过建立索引信息服务器来存储存放在用户文件中的小文件的元数据信息,可以达到高效读取小文件的目的。实验结果表明,该优化策略能有效降低NameNode内存消耗,提高HDFS文件系统对大量小文件读取效率。
关键词: HDFS; 小文件存取; 文件类型; 用户文件; 元数据信息
中图分类号:TP391 文献标志码:A 文章编号:1006-8228(2016)09-09-04
HDFS small file read and write optimization strategy
Zhu Yongqiang1,2, Zhou Ke1,2, Li Dan1,2, Zhao Yameng2
(1. School of Computer and Information Engineering Henan University, Kaifeng, Henan 475004, China;
2. Institute of Remote Sensing and Digital Earth Chinese Academy of Sciences)
Abstract: HDFS is a kind of distributed system with high fault tolerance. It supports data set at the GB to the TB level, but lacks of support for the access to a large number of small files. The processing of large number of small files will make the NameNode memory consumption excessive, and result in a reduction of the file access performance. This paper presents a method of merging small files according to the file type. Through the establishment of an index information server to store the metadata of small files stored in the user files, the purpose of reading small files efficiently can be achieved. Experimental results show that the optimization strategy can effectively reduce the NameNode memory consumption, improve the reading efficiency of HDFS file system to a large number of small files.
Key words: HDFS; small file access; file type; user file; Metadata information
0 引言
随着网络和信息技术的不断普及,人类产生的数据量正在呈指数级增长,大约每两年翻一番,根据监测,这个速度在2020年之前会继续保持下去,这意味着人类在最近两年产生的数据量相当于之前产生的数据量总和。资料显示,2011年,全球数据规模为1.8ZB,可以填满575亿个32GB的iPad,这些iPad可以在中国修建两座长城。淘宝网网站每天有超过数千万笔交易,单日产生数据量超过50TB,存储量40PB(1PB等于1000TB)。百度公司存储网页数量接近1万亿页,每天约处理60亿次搜索请求,几十PB数据[1]。云计算[2]已成为当今研究的热门课题,它很好的解决了大数据运算与存储的难题。HDFS是Apache Hadoop Core项目的一部分,现在已成为研究大数据,实现云存储服务的一个很好的模型[3],它是一个不错的分布式文件系统,大部分的HDFS程序对文件操作需要的是一次写多次读的操作模式[4]。它是一个主从结构,一个HDFS集群是由一个名字节点和多个数据节点组成,名字节点是一个管理文件命名空间和调节客户端访问文件的主服务器,数据节点用于存储数据。HDFS采用的是流式读取海量级数据,然而它在文件存储方面也有不足。这是由于HDFS是由单一NameNode多DataNode组成的,在集群运行时 NameNode的内存中加载了命名空间的元数据信息,因此大量小文件的使用会造成节点的内存消耗过多从而使系统的性能降低[5]。
社交网络、电商平台以及其他大数据领域每天都会产生大量的数据文件。据统计分析,邮件、文本、音乐、视频、互联网档案、网站图片等小于1M的海量小文件会占据整个集群小文件总数的90%以上。根据美国国家能源研究科学计算中心一个关于共享并行文件系统的研究显示,该系统存储的1300万个文件中,99%的文件大小不超过64MB,43%的文件大小不超过64KB[6]。由于HDFS是面向大文件存储与访问而设计的,面对这些大量小文件的存在,NameNode元数据的检索效率就会降低。本文提出了一种根据文件类型分类的小文件的合并策略,通过将不同类型的小文件的元数据信息存放在用户文件的不同位置,从而实现将小文件合并为大文件,很好的解决了HDFS存取海量小文件效率低下的问题。
1 研究现状以及存在的问题及分析
1.1 HDFS基本架构
如图1所示,HDFS是一个主/从(Mater/Slave)体系结构,HDFS集群拥有一个NameNode和多个DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNodes的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
1.2 现有的小文件存取方案
HDFS能够很好的支持大数据集的读写,提供很高的聚合带宽,通常支持大数量级的文件(GB级别甚至更大的文件)[7],然而对小文件的支持却有缺陷。主要原因在以下三个方面。
⑴ 由于HDFS文件系统命名空间中的元数据信息以及文件系统内部配置数据都存放在一个叫做FSImage的文件中,每次集群启动时都会将这个文件加载到内存中,若小文件数量巨大就会造成节点的内存消耗过多。
⑵ HDFS文件系统默认每一个block的大小为64MB,存储在DataNode中。大文件可能跨越多个数据块,理想情况下除了最后一个数据块会产生磁盘碎片,其余都会写满。小文件容量一般小于数据块的容量,多个文件存储在一个数据块,当数据块的碎片容量小于最小的文件大小时,这些空间将得不到利用,造成空间浪费。
⑶ 在频繁的与客户端交互过程中会形成大量的I/O操作,消耗在操作控制的时间远大于传输时间,造成网络通信延时高,从而使HDFS的性能下降。
Hadoop本身提供了一种将小文件进行归档的工具Hadoop Archives简称HAR Files,通过Hadoop的archive命令可以将大量小文件归档打包成一个HAR文件[8],因为访问HAR中的小文件要进行两次索引才能读取到小文件。还有多NameNode架构,文件元数据信息存储在多个NameNode节点上,需要采用映射文件来对NameNode进行映射,如果映射文件较大时也会严重影响系统的性能。现有的HDFS小文件解决方案都有着自身的不足。
2 基于文件合并策略的优化方案
合并小文件是为了减少NameNode内存消耗和提高其访问性能。我们在集群中为每个用户建立一个用户文件UserFile,该文件分成不同的文件类型区域(Part1、Part2…),利用HDFS提供的Append文件追加操作以流的形式将我们前面所提到的这些类型的小文件合并到用户文件的不同区域中,这样在HDFS集群中所表现出来的就是相当于一个文件,有效降低了 NameNode 的内存消耗。
2.1 小文件的存储结构设计
我们提出了小文件的合并策略,采取了如图2的架构设计。HDFS应用服务器封装了对HDFS中文件的基本操作,用户直接访问HDFS应用服务器就可以对HDFS集群中的文件进行操作,此外还有一个小文件索引信息服务器,这个服务器主要是针对优化小文件存储用的。在进行小文件的合并时需要记录小文件在UserFile中的偏移值和文件的大小,文件索引信息服务器存储了小文件的相关元数据信息并为其建立索引,从而提高了小文件的存取效率。
2.2 小文件优化方案的实现
当客户端上传文件,发出上传请求,根据文件的大小,HDFS执行不同的操作,对于大文件则直接上传至HDFS文件系统中。设置小文件的阈值为1MB,如果文件的大小小于阈值,判断小文件的类型,根据文件的类型将小文件以追加写的方式写到用户文件的不同区域中。待小文件上传完毕,我们将小文件的大小和偏移值记录在小文件索引信息服务器上,以便用户快速定位小文件,对小文件进行读取。
当客户端访问文件时,发出读取文件请求,先判断文件大小,若是大文件就直接从HDFS集群中读取文件。如果小于设定的文件阈值,根据文件名称和文件类型派生出的一个哈希函数,此哈希函数H(key)的值均匀分布在哈希表中,哈希表将按文件类型分离许许多多的索引文件。哈希函数的作用是定位文件分类,找到文件索引,哈希代码除以该类型小文件数得出一个值,根据这个值定位元数据文件中的index文件(类型文件),根据文件名称从而定位到Part文件中文件实际位置,最后根据文件大小length以流式读取文件。在实现的过程中,用到了一层索引,就定位到了小文件的实际位置[9]。由于小文件的数量庞大,用文件名称和文件类型派生出的哈希函数检索,效率会提升很多。根据文件类型对小文件进行一次筛选,大大缩小了检索的范围,能够快速地定位小文件的位置,达到快速读取小文件的目的。
3 实验结果与分析
实验的硬件环境:DFS服务器,小文件索引信息服务器,名称节点,数据节点。
实验的软件环境:linux,Hadoop,JDK,Tomcat,Mysql。
我们用程序生成2000,5000,8000,10000,30000个不同类型的测试小文件,这些小文件的大小都是小于我们在前面设定的小文件阈值,平均大小为50KB。我们根据测试结果的平均值进行测试数据的对比,包括改进前和改进后的HDFS架构NameNode内存消耗以及写入文件和读取文件的效率比较。
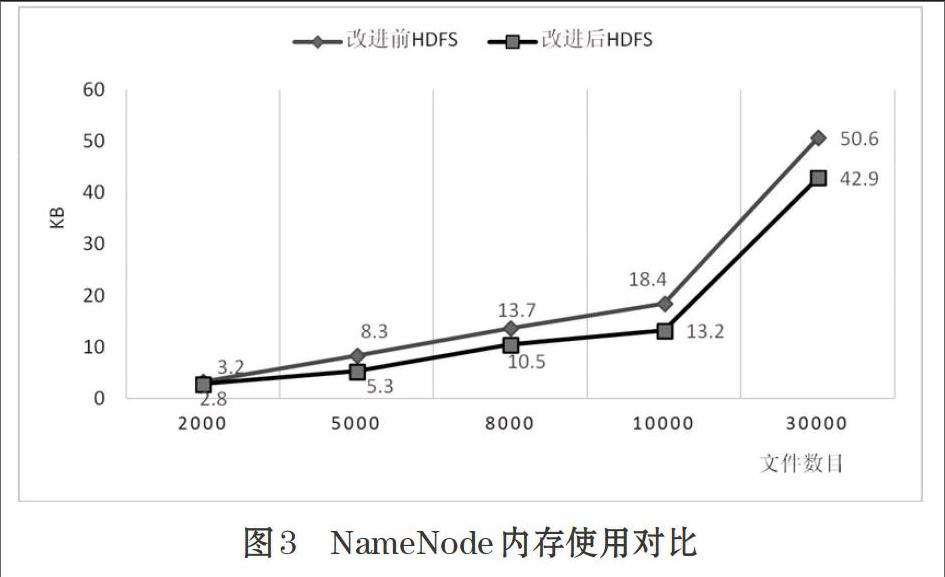
实验结果对比分析:由于改进后的HDFS架构的小文件元数据信息是存放在小文件索引服务器上,没有存放到NameNode节点上,所以在集群启动时,内存并不会随着文件的增多而占用过多内存,如图3所示。
从图4可以发现,在小文件数量小的时候,改进后HDFS架构文件上传时间会比改进前的时间长,这是由于改进架构后,对于小于文件阈值的小文件,我们根据文件类型的判断,将文件以追加写的方式写到用户文件的不同区域中,这样会比改进前直接添加元数据信息和文件所需要的时间会长一些。随着小文件的数量趋向庞大,由于改进的HDFS架构的NameNode的内存使用得到优化,使得文件写入的性能有所提升,但是优化的性能不太明显。
如图5所示,改进后的HDFS架构,读取文件的速度显著提高。这是由于改进后的架构中小文件是从索引服务器读取其元数据信息、偏移值,由构造的哈希函数所得值去定位用户文件中的某个区域该小文件的具体位置,达到快速读取小文件的目的。相比改进前的架构,遍历NameNode索引,检索效率大大提升。
4 结束语
本文阐述了基于文件类型分类的小文件存储架构,针对HDFS分布式文件系统在处理大量小文件时存在空间资源浪费以及内存消耗严重的问题,提出了一种根据文件类型分类的小文件合并策略。将小于文件阈值的小文件根据文件类型合并到一起,存放在用户文件中。通过哈希函数提出一种新的索引策略,定位文件类型索引号,再根据文件名称定位文件位置。单层索引,可以将定位文件的位置最简化,降低了检索文件的索引时间。改进后的HDFS架构,有效利用了磁盘空间资源以及解决了大量小文件元数据信息在NameNode节点上,造成内存过度消耗的问题,提高了小文件的存取效率,优化了系统的整体性能。
在实际运行测试环境中,改进后的小文件存储架构,能很好地解决空间资源浪费和内存过度消耗的问题,但同时也存在一些缺点和不足,比如在文件上传时需按照文件类型分区域存储在用户文件中,这样会花费HDFS一些时间。下一步将研究小文件写入效率以及参数优化问题,小文件存储架构也需要进一步的设计和探讨。通过优化小文件存储架构,内存利用率仍有可能加以改善。对此,我们将在后续的工作中进一步研究和完善。
参考文献(References):
[1] 唐永建.“大数据”现状及发展浅谈[EB\OL].http://www.
zbeic.gov.cn/art/2013/12/9/art_2344_171250.html,2013.8.
[2] 刘鹏.云计算[M].电子工业出版社,2011.
[3] 张春明,芮建武,何婷婷.一种Hadoop小文件存储和读取的
方法[J].计算机应用与软件,2012.11.
[4] 马建红,张海.基于HDFS的小文件存储与读取优化策略[J].
计算机系统应用,2014.5.
[5] 陈光景.Hadoop小文件处理技术的研究与实现[D].南京邮电
大学,2013.3.
[6] 周国安,李强,陈新,胡旭.云环境下海量小文件存储技术研究
综述[J].信息网络安全,2014.6.
[7] 陈剑,龚发根.一种优化分布式文件系统的文件合并策略[J].
计算机应用,2011.12.
[8] 蔡睿诚.基于HDFS的小文件处理与相关MapReduce计算
模型性能的优化与改进[D].吉林大学,2012.4.
[9] 左大鹏,徐薇.基于Hadoop处理小文件的优化策略[J].
SOFTWARE,2015.2.
