基于启发式和贪心策略的社交网络影响最大化算法
2016-10-24曹玖新闵绘宇
曹玖新 闵绘宇 徐 顺 刘 波
(东南大学计算机科学与工程学院,南京211189)(东南大学软件学院,苏州215123)
基于启发式和贪心策略的社交网络影响最大化算法
曹玖新 闵绘宇 徐顺 刘波
(东南大学计算机科学与工程学院,南京211189)(东南大学软件学院,苏州215123)
为解决传统影响力最大化算法在影响范围和运行时间上存在的不平衡问题,提出了一种综合启发式和贪心算法的社交网络影响力最大化算法(MHG).该算法综合考虑了贪心算法和启发式算法的优势,将种子节点的选择分为2个阶段,即通过启发式算法选出候选种子节点集和使用贪心算法从候选种子节点集中筛选出种子节点集合.结果表明,与现有的启发式算法相比,MHG算法在影响范围上具有显著优势,且接近贪心算法,但其运行时间明显少于贪心算法,因而在效果和时间2个方面取得了较好的平衡.在真实数据集及不同传播模型下,MHG算法均表现出稳定的影响范围,体现了该算法在大规模社会网络处理中的可扩展性.
社交网络;影响最大化;贪心算法;启发式算法;传播模型
随着互联网技术的迅速发展,社交网络已成为人们交流沟通的重要平台,并在个体信息传播、思想交互等方面发挥着重要作用.朋友或其他信任源的推荐会使用户获得更高的满意度.文献[1]采用个体间的相互关系解决影响力最大化问题.该问题的关键是如何在大规模社交网络中挖掘出一个规模较小的种子节点集合,并利用种子节点与其他节点的交互行为使得最终受影响的节点数最多.文献[1-2]将影响最大化问题视为一个算法问题,并将其引入到社交网络领域进行研究.文献[3]将影响最大化问题作为一个离散优化问题,并证明在多种传播模型下,该问题均是一个 NP-hard 问题.文献[4-6]提出了多种近似算法.贪心算法的时间复杂度较高,无法用于大规模网络.近年来涌现出大量启发式算法,其运行时间较贪心算法降低了多个数量级.例如,文献[5]在度的基础上提出了DegreeDiscount算法,其性能优于简单的Degree算法[7].PageRank算法[8]也可用于寻找社交网络中具有影响力的节点.PMIA算法[9]提供了稳定的传播范围,但运行时需耗费较大的内存.IRIE算法[10]在运行时间、内存消耗及影响范围3个方面都展现出较大的优势.文献[11]提出了基于覆盖的最大核算法和最大度算法.文献[12]在核数的基础上提出了CCA算法,并结合节点核数分布的层次特征,引入覆盖距离参数,有效地解决了影响重叠问题.综上可知,贪心算法稳定性强且影响范围广,但效率低下,且不可扩展,不适用于大规模社交网络;启发式算法效率较高,但性能不稳定,且影响范围较窄.
鉴于此,本文提出了一种综合启发式和贪心算法的影响力最大化算法MHG.结果表明,该算法在运行时间和影响范围2个方面取得了较好的平衡,可处理大规模网络,具有可扩展性.
1 传播模型
用户影响力在社交网络中的作用与信息的传播过程密不可分,因此,信息传播模型是影响力最大化问题的研究基础.最基本的传播模型包括独立级联模型(IC)[3, 13]和线性阈值模型(LT)[3, 14].在这2种模型中,节点呈现出活跃和不活跃2种状态.节点可以通过传播模型从不活跃状态转变成活跃状态,反之则不可.随着节点的活跃邻居数越来越多,节点受影响变活跃的可能性越来越大.
独立级联模型来源于概率论中粒子交互系统,它以信息发布者为中心,侧重于影响力的扩散过程,其核心思想是活跃状态的节点可以以一定的概率激活不活跃的邻居节点.线性阈值模型以信息接收者为中心,侧重于受影响的用户,并考虑影响力的积累效果,其核心思想是一个节点是否被激活由其所有活跃邻居节点的影响力总和所决定.
2 综合启发式和贪心算法的影响最大化算法
贪心算法在节点选择时会计算所有节点的边际效益,但网络中的大部分节点处于网络边缘,只有小部分节点处于核心区域;处于边缘的节点影响力效用极其有限,几乎不会出现在种子集合中,因此可不必计算这些节点的边际效益.启发式算法所选择的节点虽有局限性,但它考虑了种子节点在某些属性上的优势.故可充分结合两者的优点,利用启发式算法找出候选节点集合,然后采用贪心算法从候选集合中筛选出k个种子节点;筛选过程在确保节点自身影响力的同时,还能使得所选节点集合的聚合影响力最大.
综合启发式和贪心算法的影响力最大化算法的基本思想为:首先,选择目前表现好的r(r≥1)个启发式算法,依次从这些算法中选取ki(ki≥1)个节点作为候选节点,且满足∑ki≥k;然后,采用贪心算法从中检索出k个种子节点.该算法可分2个阶段:① 候选阶段,即利用启发式算法选出候选集合;② 贪心阶段,即在候选集合中利用贪心算法找出较优解,以提供稳定的影响范围.
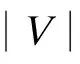
算法1综合启发式和贪心算法的社交网络影响最大化算法
输入: 社交网络G(V,E), 种子节点个数k,影响力最大化算法集合SIMA.
输出:种子节点集合S.
1. initializeScan=∅, S=∅
2. for each algorithmΦ∈SIMAdo
3.Stemp=SelectNodes(G,Φ,ki)//Φ为SIMA集合中的一个算法;通过SelectNodes(G,Φ,ki)函数选取社交网络G中的ki个节点并返回给集合Stemp;
4.Scan=Scan∪Stemp//Scan为候选节点集合
5. end for
6.B
7. for each vertexvinScando
8.Cv=ComputeMargin(v)//计算Scan中节点v的边际效益Cv
9. push_back(B,Cv)//将Cv添加至节点边际效益集合中
10. end for
11.H=BuildMaxHeap(B)//根据节点的边际效益建立最大堆H
12. fori=1 tokdo
13. do
14.u=topHeap(H)//u为堆顶元素
15.Cw=ComputeMargin(w)
16. adjustHeap(H)
17. while(u!=topHeap(H))
18. popHeap(H)//弹出堆顶元素
19.S=S∪{u}
20. end for
21. Return S
算法1中第2~5行为候选阶段,即利用启发式算法得到候选种子节点集合.第13~17行根据前一轮每一个节点的边际效益进行排序(堆排序),仅对处于顶端的节点w重新计算边际效益.若其边际效益仍为最大,则选择该节点作为种子节点,否则重新排序,直到所选取节点的边际效益在本次循环中为最大边际效益为止.第7~20行为贪心阶段,即在社交网络G的候选节点集合Scan下应用贪心算法选取k个种子节点.
采用贪心算法解决影响最大化问题的策略是从网络所有节点中选取k个节点,而MHG算法仅在候选节点集Scan中应用贪心算法.其优点在于,无需求出网络中每个节点的边际效益,只需计算Scan中候选节点的边际效益,从而有效降低了算法的时间复杂度;在每一次种子节点的选择过程中也只需计算部分节点在本次循环中的边际效益,从而大幅度减少了运算时间.MHG算法的时间复杂度取决于各启发式算法和贪心算法的时间复杂度.现有启发式算法的时间复杂度通常为O(m).由于启发式算法所选择的候选节点数为O(k),远小于网络中节点个数,因此MHG算法的复杂度为O(k2mR),其中R为Monte-Carlo模拟次数.
3 实例分析
图1为社交网络G(V,E)的模拟图.假设SIMA集合包含2个启发式算法Φ1和Φ2,目标是从中选取3个种子节点.
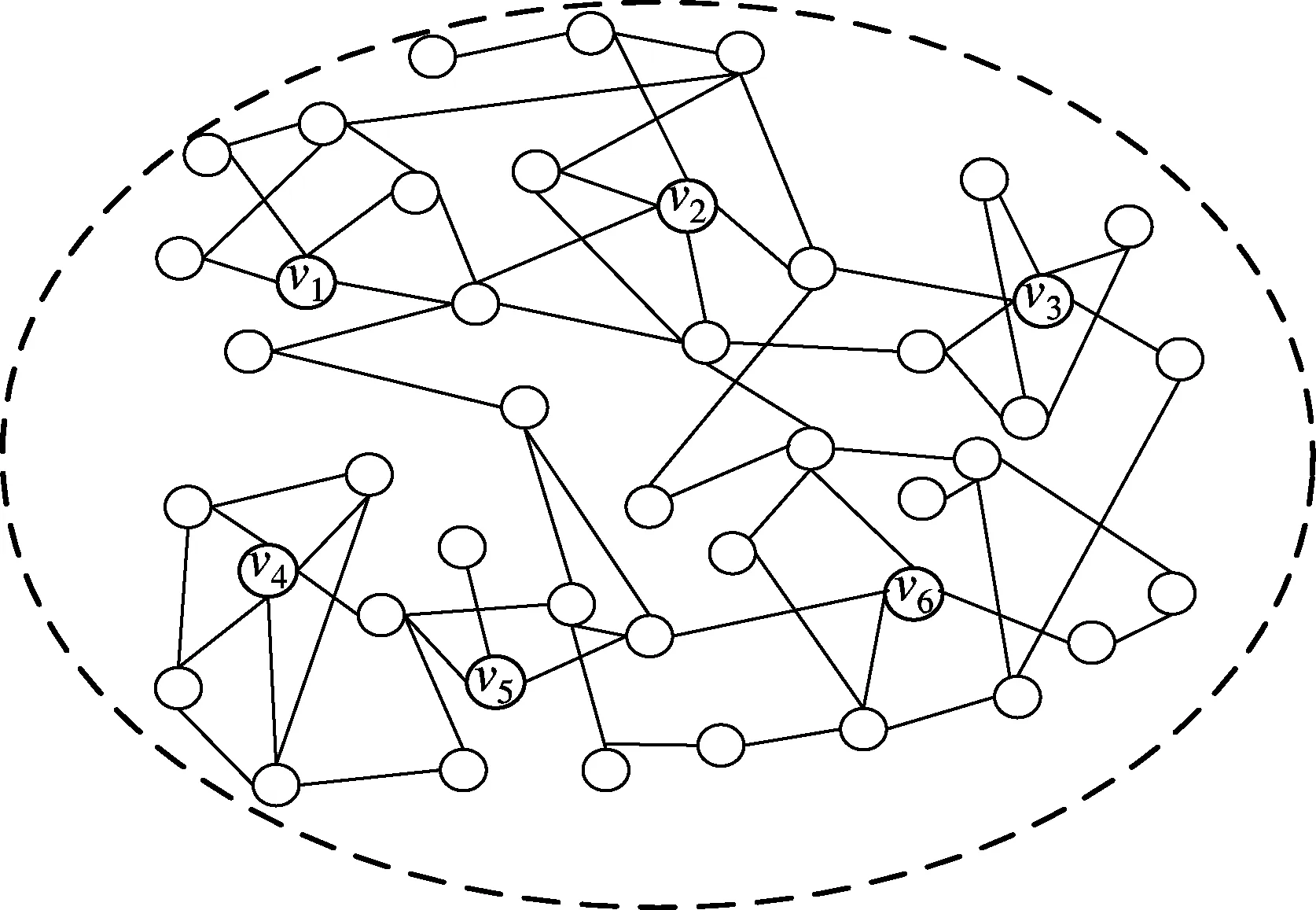
图1 社交网络G(V,E)的模拟图
采用MHG算法可将选择过程分为2个阶段.在候选阶段,运用算法Φ1和Φ2选取候选节点,令算法Φ1选择的节点集S1={v1,v5,v6},算法Φ2选择的节点集S2={v2,v3,v4},则候选节点集Scan=S1∪S2={v1,v2,v3,v4,v5,v6}.在贪心阶段,运用贪心算法从候选节点集Scan筛选出种子节点,具体步骤如下:
① 计算Scan中每个节点的边际效益.假设通过计算得到v1,v2,v3,v4,v5,v6的边际效益分别为4,8,7,5,6,9,建立最大堆(见图2(a)).节点v6的边际效益最大,则将节点v6加入到种子集合S中,即S={v6}.
② 从堆中移除节点v6并调整堆(见图2(b)).重新计算堆顶元素v2的边际效益.假设计算后v2的边际效益为7,则v2仍处于堆顶位置(见图2(c)),添加节点v2至集合S,即S={v6, v2}.根据影响最大化目标的子模函数特点可以得出,当v2仍处于堆顶位置时无需计算其他节点的边际效益,从而使得算法运行效率明显提高.子模函数的特点是,在网络中添加任一节点v到集合S中所获得的边际效益不能小于添加相同节点v到S的父集合T所获得的边际效益,即
f(S∪{v})-f(S)>=f(T∪{v})-f(T)
∀v∈VTS ⊆ T ⊆ V
(1)
③ 从堆中移除节点v2并调整堆(见图2(d)).假设计算后节点v3的边际效益为4,调整堆后发现节点v5为堆顶元素(见图2(e)).节点v3的新位置不处于堆顶,故仍需计算其他节点的边际效益,假设计算后其他节点{v1,v4,v5}的边际效益分别为4,5,5.调整堆后发现节点v5仍处于堆顶位置(见图2(f)),则将节点v5加入到种子集合S中,即S={v6, v2, v5},满足种子节点个数为3,算法结束.
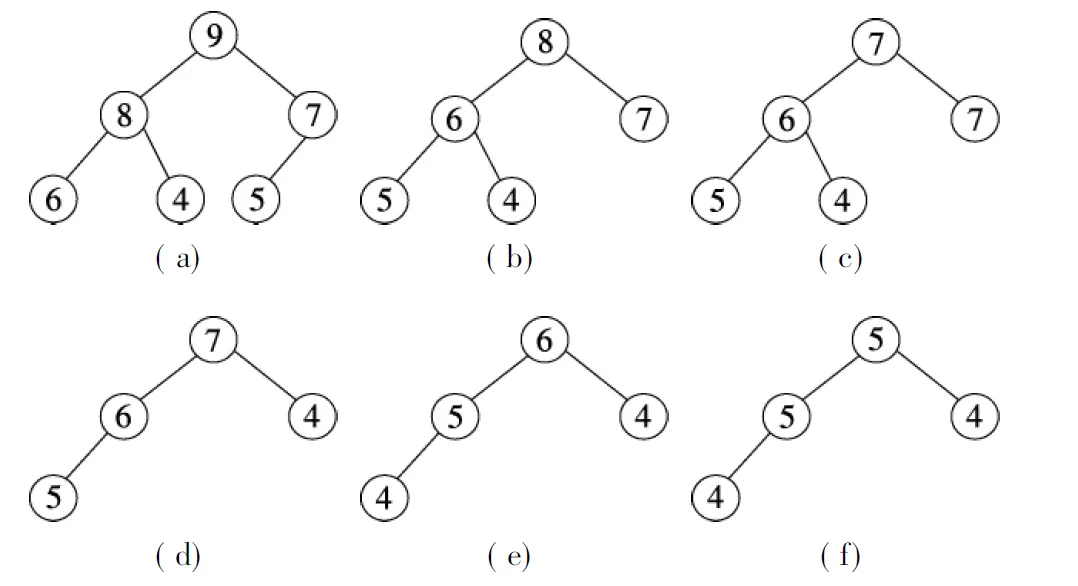
图2 影响力节点选择过程
4 实验设计
实验选择2个真实的作者合作网络数据集NetHEPT和DBLP[15].数据集的统计信息见表1.

表1 社交网络数据集
本文针对这2个真实的社交网络数据集和2种传播模型进行实验.为验证MHG算法的性能,将其与当前最具代表性的算法(Degree算法、DegreeDiscount算法、PageRank算法、CELF算法、PMIA算法、CCA算法、LDAG算法、Greedy算法,其中Greedy算法为贪心算法,其余均为启发式算法)进行了比较,实验中将PageRank算法的阻尼因子设置为0.15,PMIA算法的theta参数设置为1/320.假定在IC模型下社交网络中的传播概率相同,比较不同传播概率 (P=0.01,0.02,0.03,0.04,0.05,0.06)下各算法的性能.在IC模型下,MHG算法在候选阶段采用PMIA算法和CCA算法;在LT模型下,MHG算法在候选阶段采用LDAG算法和CCA算法.由于在CCA算法中引入了距离覆盖参数d来解决影响重叠问题,因此,实验还比较了d=1,2时CCA算法和MHG算法的影响范围和运行时间.
在种子节点数目相同的情况下,经过同一传播模型模拟传播后,不同算法会表现出不同的影响效果.因此,可通过比较传播结束后最终受影响节点的数目来反映算法间的差异.假设对于2种影响最大化算法A和Q,当种子数为j时,其差异D(A,Q,j)为
(2)
式中,σ(A,j)表示种子节点数目为j时算法A在传播模型结束后最终受影响的节点数目.
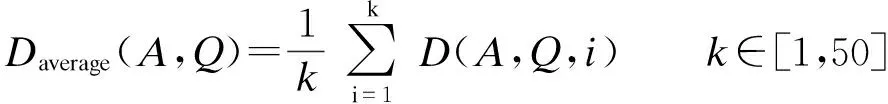
(3)
通过Monte-Carlo模拟104次传播过程来获得一个较为精确的影响范围.在实验分析中,算法A与Q的平均差异是指种子数从1变化到50时2种算法间差异的均值,平均差异更能体现出算法之间的差异性.
实验环境为Microsoft Windows 2008操作系统,服务器为IBM System X3755 M3,硬件配置为2.00 GHz Quad-Core处理器、16 GB内存.
5 实验结果及分析
社交网络影响力的评价指标为:① 时间效率,即传播结束后算法的运行时间;② 影响范围,即在规定种子节点数目的情况下算法最终影响的节点数目.本实验采用2个不同的数据集,将算法在2种传播模型下运行,并通过这2个评价指标对算法进行分析评价.
5.1IC模型下算法性能分析
DBLP数据集是拥有数百万条边关系的较大规模网络,Greedy算法在此数据集上需要运行数天时间才能得到实验结果,因此在DBLP数据集上没有运行Greedy算法.不同传播概率下各算法在DBLP数据集中的影响范围见图3.由图可知,MHG算法总体上优于其他启发式算法.当P=0.01,k∈ [1,26]时,MHG算法较其他算法具有更好的影响效果. 当k∈[27,50]时, Degree算法、DegreeDiscount算法、PMIA算法的传播范围接近d=1时的MHG算法,究其原因在于,在传播概率较低的情况下贪心算法不一定能达到最优解.
各算法在DBLP数据集上的运行时间见表2.由表可知,当P<0.06时PMIA算法的运行时间小于6 s,但当P=0.06时则上升为197 s;MHG算法的最高运行时间约为17 h.
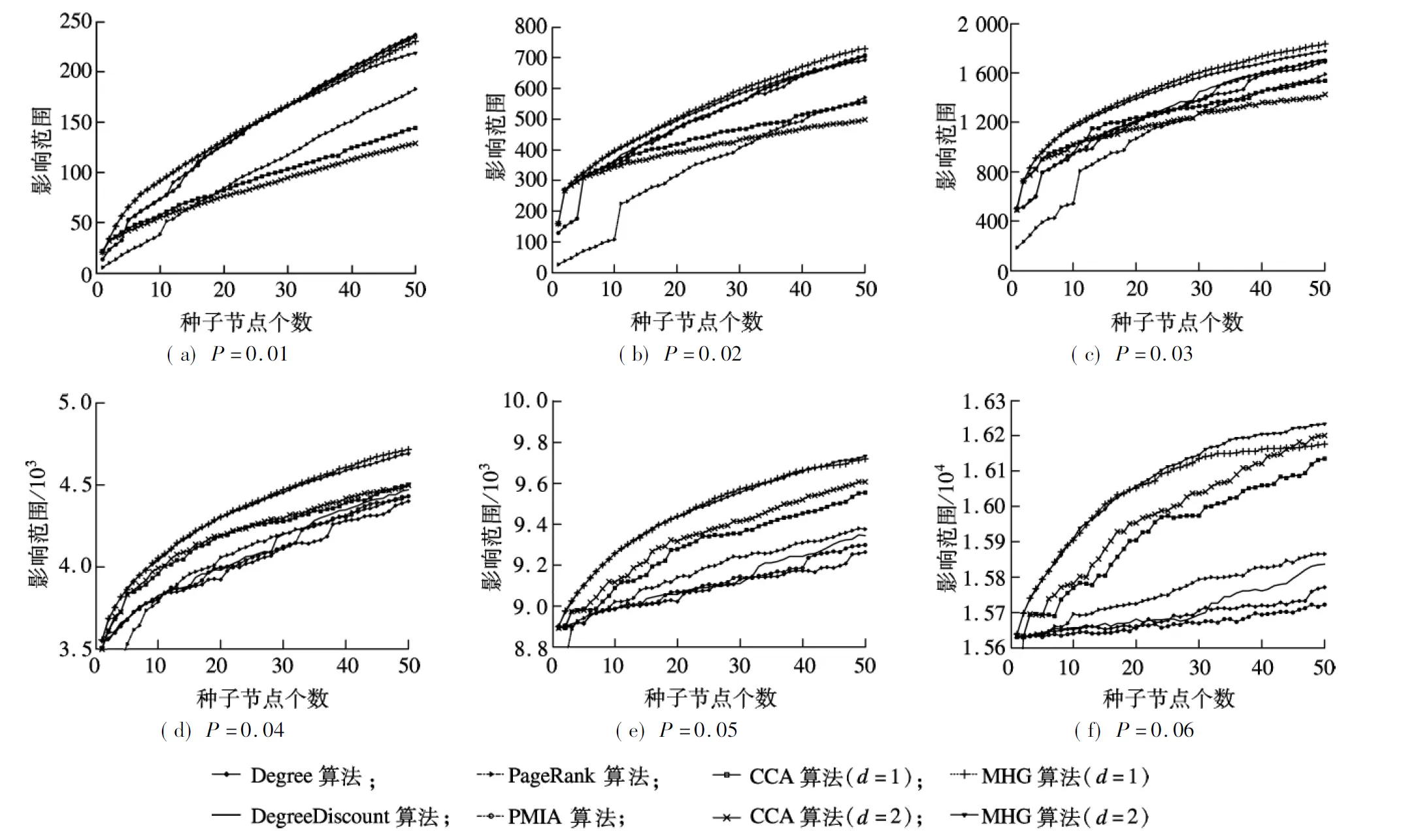
图3 不同传播概率下各算法在DBLP数据集中的影响范围
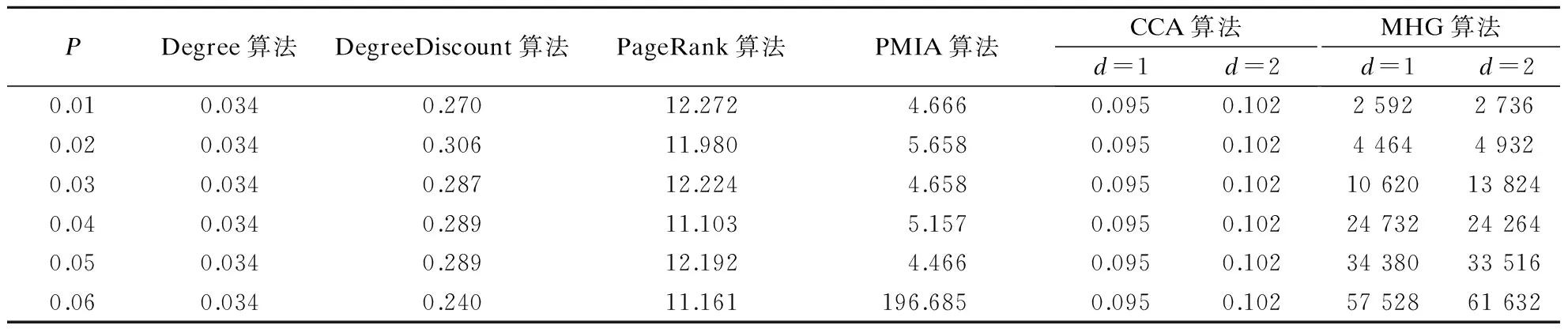
表2 不同算法在DBLP数据集上的运行时间s
对于小规模网络NetHEPT,MHG算法依然表现出较好的优势(见图4).由图可知,当传播概率P=0.01,0.02,0.03时,MHG算法的影响范围接近于Greedy算法.当P>0.03时,Greedy算法表现最优,MHG算法其次,与启发式算法相比差异为5%~15%.但随着传播概率的增大, Greedy算法需要运行数天,因此当P=0.05,0.06时,没有就Greedy算法进行对比.由图4(e)和(f)可知,MHG算法依然保持优势,d取值不同时影响范围存在一定差距.随着传播概率的增大,种子节点对距离为2的周围节点影响力持续升高,而对距离为1的周围节点的影响力趋于平稳.由图4(e)和(f)可知,随着种子节点个数的增加,d=1时CCA算法的影响范围趋于稳定,d=2时CCA算法的影响范围却有较大幅度的上升.此外,d=1时MHG算法的影响范围较d=2时MHG算法的影响范围平均高出2.69%,较d=2时CCA算法的影响范围平均高出4.43%.其他启发式算法在P=0.05,0.06时均表现较差,随着种子节点个数的增加,影响范围增长较缓.
各算法在NetHEPT数据集上的运行时间见表3.由表可知,所有启发式算法的运行时间都小于1 s;MHG算法的最高运行时间为1.15 h.当P>0.04时,Greedy算法需运行数天时间,因此不再进行对比.
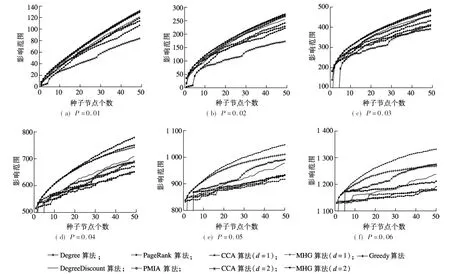
图4 不同传播概率下各算法在NetHEPT数据集中的实验结果
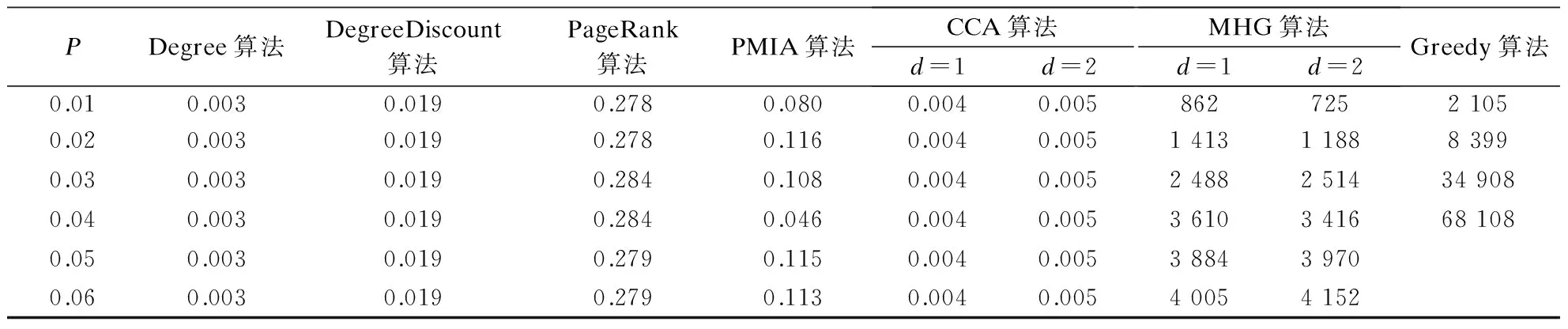
s
此外,还进行了P=0.07,0.08,0.09,0.10的实验,结果表明,各算法的影响范围与P=0.06时相似.通过分析d>2时各算法的影响范围发现,随着传播概率的增加,覆盖距离越大,其影响力传播得越远,但影响范围不一定越广.对于MHG算法,d=3时的传播效果略优于d=2时的情况.但当d=4时,MHG算法的表现并不理想,这是因为网络直径有限,覆盖距离的增大会使后续所选节点可能处于核心区域之外,从而导致边际效益较低,影响范围不会明显增长.
综上可知,MHG算法在不同规模的社交网络和传播概率下均表现出较稳定的优势.虽然MHG算法在影响范围上稍逊于贪心算法,但其运行时间明显较少,由此证明MHG算法在运行时间与影响范围上取得了较好的平衡.
5.2LT模型算法性能分析
LT模型对节点的影响力是通过活跃邻居节点的影响力累加而成的.通常在同样的数据集下,LT模型所影响的节点数目比IC模型多.由于PMIA算法不适用于LT模型,因此,LT模型下的实验中没有对比PMIA算法.
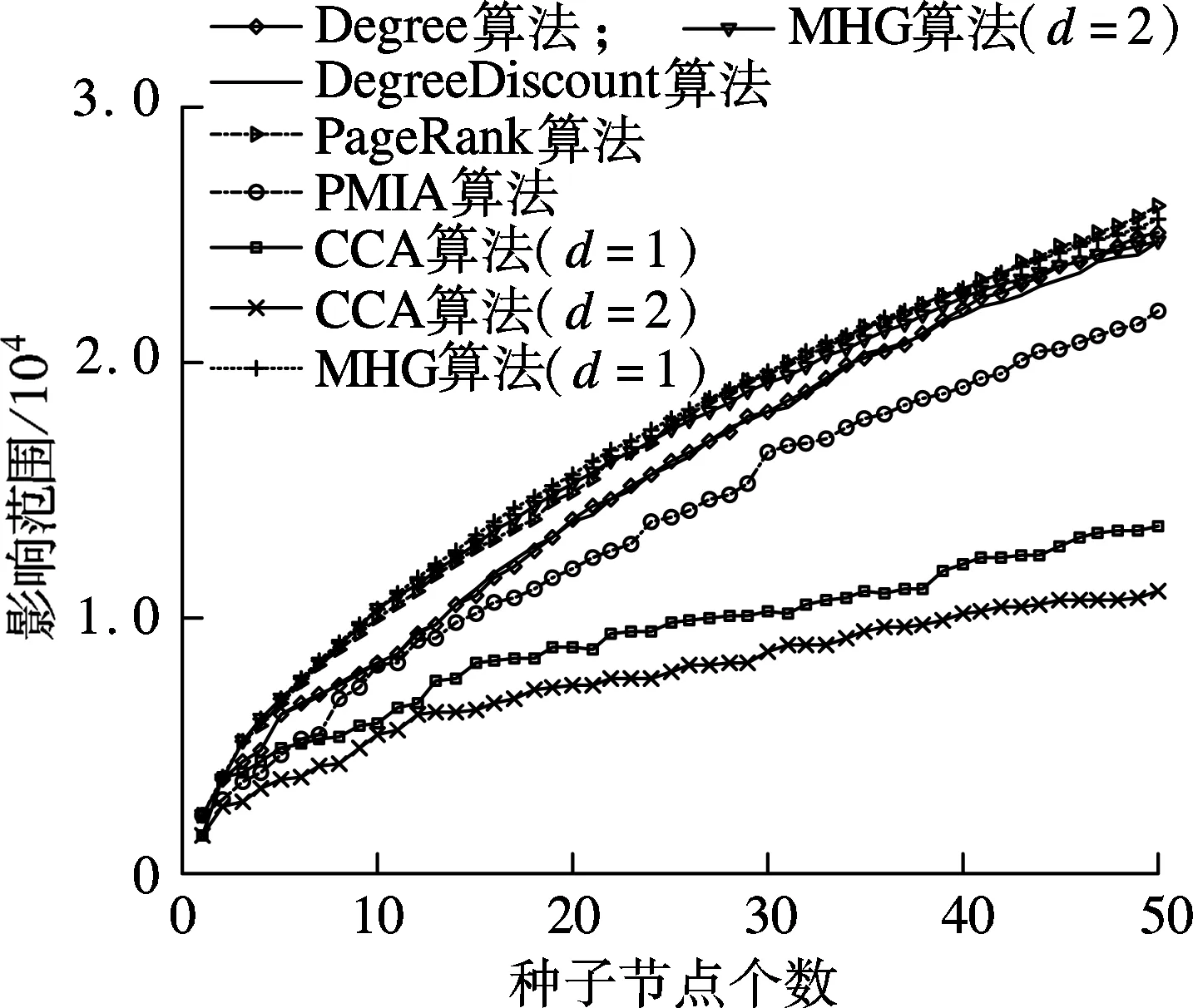
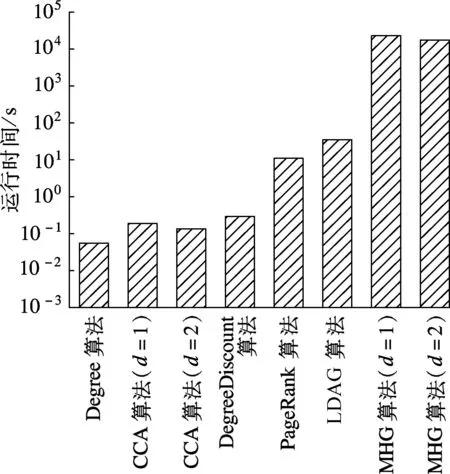
图5为LT模型下各算法在DBLP数据集中的实验结果.由图可知,当k>43时,PageRank算法的影响范围大于d=1时的MHG算法,但纵观全局,后者在平均差异上仍高于前者1.55%.d=1,2时MHG算法的运行时间分别为4.81和3.91 h.
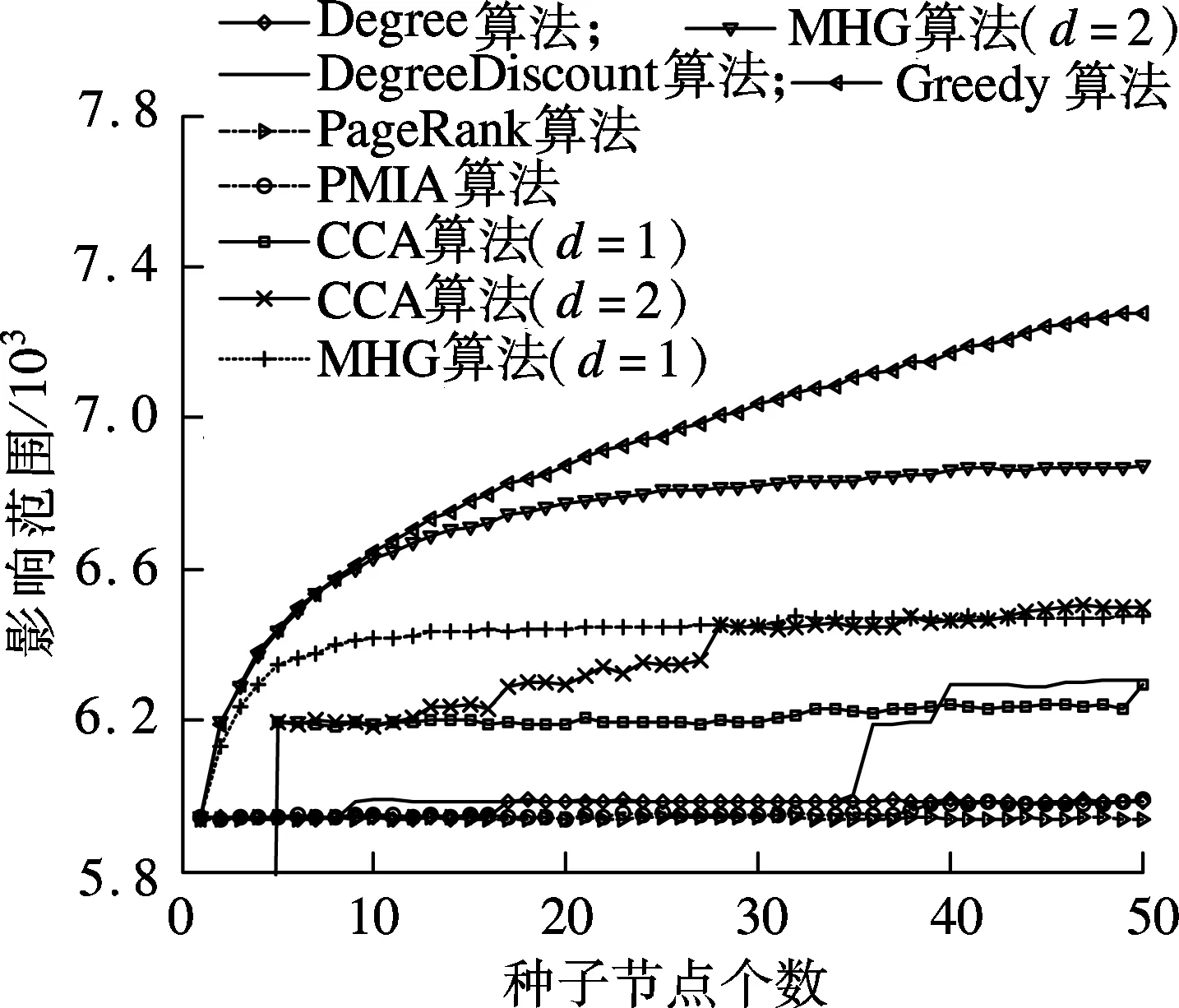
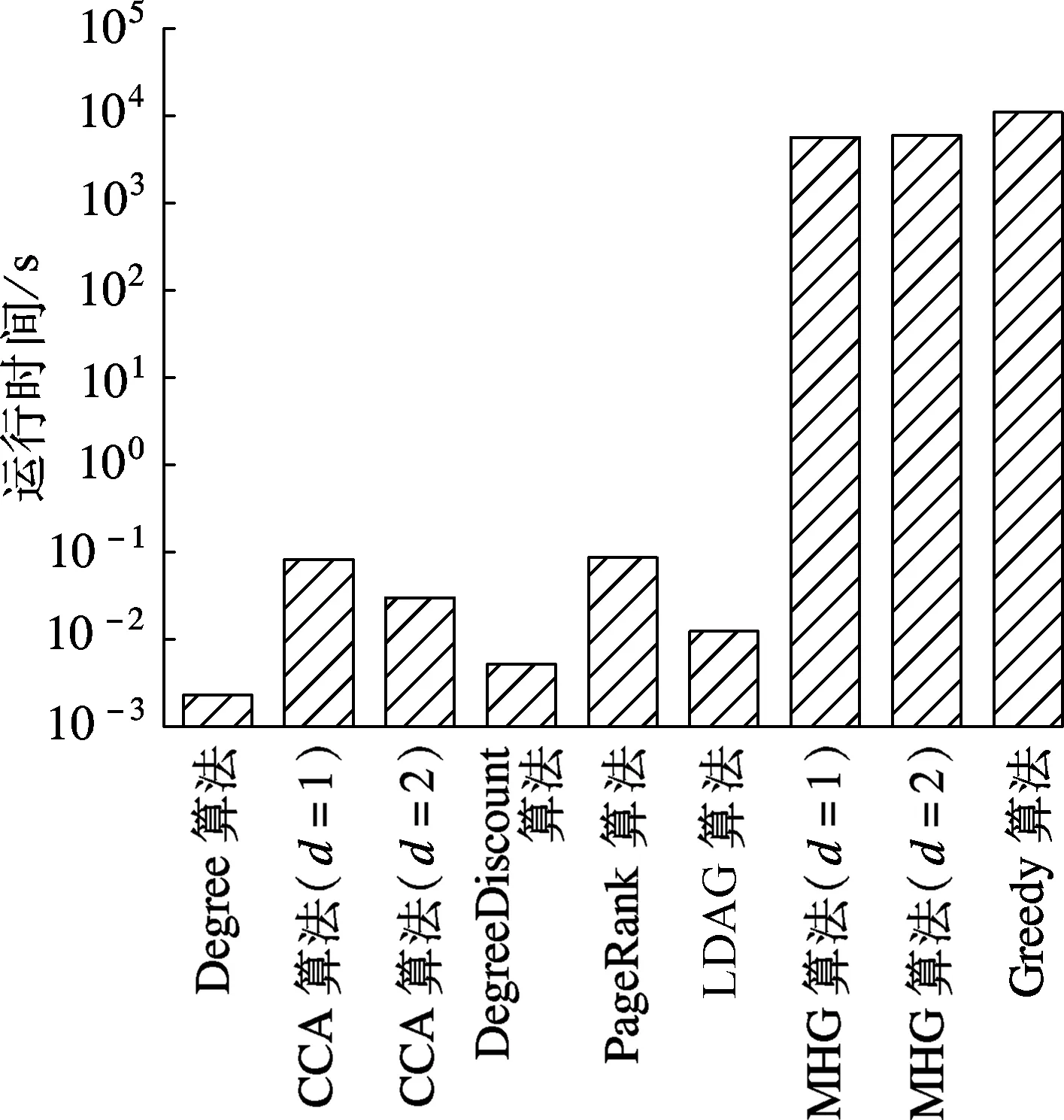
图6为LT模型下各算法在NetHEPT数据集中的实验结果.由图可知,Greedy算法表现依然最优,MHG算法其次.随着种子节点个数的增多,MHG算法在后期增长较缓慢,这是因为MHG算法受限于LDAG算法和CCA算法所选的种子节点集. 但相对于其他启发式算法, MHG算法仍表现出较大的优势.在运行时间上,由于MHG算法使用了贪心算法,因此其运行时间相对较高,但仍在可接受范围内.对于MHG算法,d=1,2时的运行时间分别为1.50和1.61 h.
(a) 影响范围
(b) 运行时间图5 LT模型下各算法在DBLP数据集中的实验结果
综上所述,在不同传播模型下,MHG算法始终表现出较大优势,且在运行时间与影响范围上取得了较好的平衡;在不同规模的数据集中,MHG算法均表现出平稳优势,表明MHG算法在大规模数据集中具有可扩展性.
6 结语
本文提出了一种综合启发式和贪心算法的混合算法,以解决社交网络影响力最大化问题,并在真实的社交网络和2个传播模型下进行了实验,与现有的影响力最大化算法进行了对比.实验结果表明,MHG算法总体上优于现阶段表现较好的启发式算法,其时间复杂度小于贪心算法,不但能处理数百万规模节点和边的网络,而且能够在时间效率和传播效果中达到一个良好的平衡.下一步将从群体角度研究影响力最大化问题.
(a)影响范围
(b) 运行时间图6 LT模型下各算法在NetHEPT数据集中的实验结果
References)
[1]Domingos P, Richardson M. Mining the network value of customers[C]//Proceedingsofthe7thACMSIGKDDInternationalConferenceonKnowledgeDiscovery&DataMining. San Francisco, CA, USA, 2001:57-66. DOI:10.1145/502512.502525.
[2]Richardson M, Domingos P. Mining knowledge-sharing sites for viral marketing[C]//Proceedingsofthe8thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining. Edmonton, Alberta, Canada, 2002:61-70. DOI:10.1145/775047.775057.
[3]Kempe D, Kleinberg J, Tardos É. Maximizing the spread of influence through a social network[C]//Proceedingsofthe9thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining. Washington, DC, USA, 2003:137-146. DOI:10.1145/956750.956769.
[4]Leskovec J, Krause A, Guestrin C, et al. Cost-effective outbreak detection in networks[C]//Proceedingsofthe13thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining. San Jose, CA, USA, 2007: 420-429. DOI:10.1145/1281192.1281239.[5]Chen W, Wang Y, Yang S. Efficient influence maximization in social networks[C]//Proceedingsofthe15thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining. Paris, France, 2009: 199-208. DOI:10.1145/1557019.1557047.
[6]Goyal A, Lu W, Lakshmanan L V S. CELF++: optimizing the greedy algorithm for influence maximization in social networks[C]//Proceedingsofthe20thInternationalConferenceCompaniononWorldWideWeb. Hyderabad, India, 2011: 47-48.
[7]Wasserman S, Faust K. Social network analysis[J].EncyclopediaofSocialNetworkAnalysis&Mining, 2011, 22(S1):109-127.
[8]Brin S, Page L. Reprint of: The anatomy of a large-scale hypertextual web search engine[J].ComputerNetworks, 2012, 56(18):3825-3833. DOI:10.1016/j.comnet.2012.10.007.
[9]Chen W, Wang C, Wang Y. Scalable influence maximization for prevalent viral marketing in large-scale social networks[C]//Proceedingsofthe16thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining. Washington, DC, USA, 2010:1029-1038. DOI:10.1145/1835804.1835934.
[10]Jung K, Heo W, Chen W. IRIE: Scalable and robust influence maximization in social networks[C]//IEEE12thInternationalConferenceonDataMining(ICDM). Brussels, Belgium, 2011:918-923. DOI:10.1109/icdm.2012.79.
[11]Kitsak M, Gallos L K, Havlin S, et al. Identification of influential spreaders in complex networks[J].NaturePhysics, 2010, 6(11):888-893. DOI:10.1038/nphys1746.[12]曹玖新, 董丹, 徐顺, 等. 一种基于k-核的社会网络影响最大化算法[J]. 计算机学报, 2015, 38(2):238-248. DOI:10.3724/SP.J.1016.2015.00238.
Cao Jiuxin, Dong Dan, Xu Shun, et al. Ak-core based algorithm for influence maximization in social networks[J].ChineseJournalofComputers, 2015, 38(2):238-248. DOI:10.3724/SP.J.1016.2015.00238.(in Chinese)
[13]Cao T, Wu X, Wang S, et al. OASNET: An optimal allocation approach to influence maximization in modular social networks[C]//Proceedingsofthe2010ACMSymposiumonAppliedComputing(SAC). Sierre, Switzerland, 2010:1088-1094.
[14]Kleinberg J. The small-world phenomenon: An algorithm perspective[C]//Proceedingsofthe32ndAnnualACMSymposiumonTheoryofComputing. Portland, OR, USA, 2000:163-170. DOI:10.1145/335305.335325.
[15]Yang J, Leskovec J. Defining and evaluating network communities based on ground-truth[J].KnowledgeandInformationSystems, 2013, 42(1):181-213. DOI:10.1007/s10115-013-0693-z.
Mixed heuristic and greedy strategies based algorithm for influence maximization in social networks
Cao JiuxinMin HuiyuXu ShunLiu Bo
(School of Computer Science and Engineering, Southeast University, Nanjing 211189, China) (College of Software Engineering, Southeast University, Suzhou 215123, China)
To solve the imbalance problem between the influence scope and the running time of the classic influence maximization algorithms, a mixed heuristic and greedy strategies based algorithm (MHG algorithm) for influence maximization in social networks is proposed. The algorithm considers the advantages on the greedy and heuristic strategies, and the selection of seed nodes is divided into two steps. First, the candidate node set is selected by the heuristic algorithm, and then the final seed node set is deduced from this set by the greedy algorithm. The results show that the MHG algorithm is superior in influence scope compared with current heuristic algorithms. It exhibits the approximate effect of the greedy algorithm, but the running time is obviously lower. Therefore, the MHG algorithm achieves a good balance between the influence scope and the running time. Moreover, the MHG algorithm presents a stable influence scope when running on real data sets and different dissemination models, showing its scalability in large scale social networks.
social networks; influence maximization; greedy algorithm; heuristic algorithm; dissemination model
10.3969/j.issn.1001-0505.2016.05.009
2016-03-17.作者简介:曹玖新(1967—),男,博士,教授,博士生导师,jx.cao@seu.edu.cn.
国家自然科学基金资助项目(61272531, 61472081)、江苏省科技厅产学研前瞻性联合研究资助项目(SBY2014020139).
TP393
A
1001-0505(2016)05-0950-07
引用本文:曹玖新,闵绘宇,徐顺,等.基于启发式和贪心策略的社交网络影响最大化算法[J].东南大学学报(自然科学版),2016,46(5):950-956. DOI:10.3969/j.issn.1001-0505.2016.05.009.
