基于C6678多核数字信号处理器的声纳信号并行处理设计
2016-10-15汲夏丛卫华杜栓平
汲夏,丛卫华,杜栓平
(杭州应用声学研究所声纳技术国家重点实验室,浙江杭州310012)
基于C6678多核数字信号处理器的声纳信号并行处理设计
汲夏,丛卫华,杜栓平
(杭州应用声学研究所声纳技术国家重点实验室,浙江杭州310012)
针对多核并行机制下,共享资源争夺激烈,硬件能力提升难以切实转变成程序效率提高的难题,通过协调存储器访存和核间同步等关键问题,研究了一种基于C6678多核数字信号处理器的声纳信号多级并行处理方法,包括核间流水线设计、数据传输与中央处理器并行设计和指令流线设计。以声纳二维相控方位滤波为例,介绍各级设计的实现方法,逐个测试并行性能,并编制实时处理软件。测试结果表明,该方法能够实现存储器访问和中央处理器运算并行,极大提高程序执行效率。通过采用该方法开发的实时处理系统,具有集成度高和实时性强的优点,获得了高航速下海中浮球和配重条石清晰的实时成像效果,具有工程应用价值。
声学;声纳;相控方位滤波;多核数字信号处理器;并行处理
0 引言
现代声纳大数据率、高集成度和强实时性的发展趋势,对信号处理平台核心器件的传输和运算能力提出了越来越高的要求[1]。在传统单核数字信号处理器(DSP)工作频率提升越来越困难,运算能力受限的情况下,多核DSP并行处理逐渐成为主流,广泛应用于现代声纳信号处理。在多核并行机制下,共享资源的争夺非常激烈,由此导致的对于系统性能的影响也更加显著,因而设计一个能够公平有效地调度资源的并行方法,将硬件能力的提高切实转变成程序性能的提升,在声纳信号处理中至关重要[2-5]。
本文系统介绍了TMS320C6678多核DSP架构,设计出一种基于C6678多核DSP的声纳信号多级并行处理方法,在协调各核公平竞争资源的同时,实现数据传输的后台执行和汇编指令的相互驱动,并以二维相控方位滤波为例,介绍各级并行处理实现方法,逐级进行性能测试。采用该方法开发的实时处理软件,获得了海上浮球及其配重条石的清晰成像,具有较高的工程应用价值。
1 C6678DSP多核架构
C6678DSP是美国TI公司最新推出的一款片上多内核处理器,它将8个运算核心集成到一个芯片上,具有极强的高速并行运算能力,能够以较小的硬件规模,满足多数声纳阵列信号处理的需求。C6678DSP多核架构主要包括8个C66x运算核心、10个增强型直接内存存取(EDMA)控制器、4通道高速串行互联接口(SRIO)、三级内部存储器、1个第3代双倍速随机动态存储器(DDR3)以及外设总线交换接口等,C6678DSP内部还集成了多核导航器、分组加速器等硬件加速模块,如图1所示C6678 DSP多核架构[5-7]。

图1 C6678DSP多核架构Fig.1 Multicore architecture of C6678 DSP
C6678DSP允许8个1GHz的C66x运算核心完全并行,理论上具有单片浮点运算能力1600亿次/s,是TS201DSP的约40倍。C66x采用多级缓存,根据与中央处理器(CPU)的距离,由近到远依次为32kB数据存储器(L1DS)、512KB本地存储器(LL2S)、4MB内部共享存储器(MSMS)以及超大容量的DDR3. CPU突发访存缓存器时,距离越近访存速度越快。L1DS通常被配置成Cache模式,用来保障CPU对LL2S、MSMS的快速访存。
2 存储器访存瓶颈问题
存储器的合理调度是保证并行软件高效执行的基础,也是多核架构下并行软件设计的研究热点。C6678DSP的8个核心完全相同,但各级缓存器的访存带宽有限且存在很大差异,例如LL2S的连续访存带宽为16GB/s,MSMS为64GB/s,DDR3仅为10GB/s.由于存储器带宽远小于CPU处理和EDMA访存的带宽,在实时并行处理软件开发时,存储器将成为EDMA控制器并发访存的瓶颈,尤其是DDR3.
8个核心同时通过EMDA将数据在DDR3与MSMS之间双向传输,每个核心传输256MB,各EDMA优先级相同,统计得到的8个核心访存DDR3带宽如图2所示。可见自由竞争条件下,多核并行访存DDR3时,将均分DDR3带宽。因此设计并行软件时必须考虑C6678DSP各级存储器带宽的有限性和不一致性,采取任务均衡措施,设计一个公平的存储器调度的方法,减少访存请求的阻塞时间,才能保证软件的并行效率。
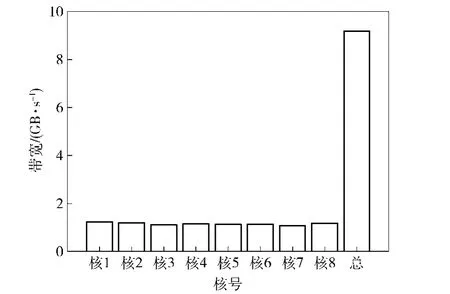
图2 8核并行访存DDR3带宽Fig.2 Bandwidth of DDR3 fetched by eight cores
3 声纳信号多级并行处理方法
综合考虑声纳信号高数据率和C6678DSP多内核、多级缓存的特点,本文设计了一种声纳信号多级并行处理方法,协调各内核公平竞争资源的同时,实现数据传输的后台执行和CPU的快速运算。第1级采用基于时间切片的核间流水线设计,克服多核并发访问低带宽存储器带来的程序阻塞;第2级采用基于ping-pong存储的内存数据传输与CPU并行设计,完成数据在内部存储器间的高速后台传输;第3级采用汇编指令流水线设计,实现多周期指令的相互驱动,充分挖掘CPU的运算能力。本文以声纳信号处理中较为复杂的二维相控方位滤波为例,介绍声纳信号多级并行处理流程,测试程序并行性能。
3.1任务分配策略
二维相控方位滤波的处理公式[1,8]为

式中:r为目标到参考点的距离;θ为目标的纵向方位角;β为目标的横向方位角;m、n分别为阵元在纵向和横向方位的位置索引,如图3所示横向和纵向方位角。相比于参考点,阵元(xn,ym,0)接收目标(x,y,z)回波的延时为

式中:c为声速。
根据声纳阵列信号的通道独立性和(2)式,二维相控方位滤波的信号处理任务可进行距离、横向方位角、纵向方位角三维分割,只要每一维都采用均匀划分,即可实现任务均衡。
3.2核间流水线设计
声纳信号阵元域的数据量非常大,只能存储在容量较大的DDR3中。由前面的介绍可知,来自不同核心的DDR3访存请求存在严重的竞争关系,本文设计了一种基于时间切片的核间流水线方法,控制8个核心轮流访存DDR3.首先将DDR3中的任务数据均分给8个C66x核心,每个核心进一步划分为更小的任务数据,使得每个任务数据传输仅占用很小的时间切片。然后通过设置和判读进程间通信中断生成寄存器,控制8核轮流访存目的存储器,CPU运算填充等待访存间隙,基于时间切片的核间流水线设计如图4所示。

图3 相控方位滤波的横向和纵向方位角Fig.3 Horizontal and longitudinal azimuth angles of phased azimuth filter

图4 基于时间切片的核间流水线设计Fig.4 Multicorepipelinedesignbasedontimeslice
将阵元域数据由DDR3传输至MSMS,每核256MB,在自由竞争和核间流水线设计条件下,传输耗时的100次统计平均如图5所示。由图5可知,自由竞争条件下,数据传输耗时远远大于核间流水线设计,CPU容易因等待数据而出现较长时间的程序阻塞。因此采用核间流水线设计,可以避免多EDMA并发访问存储器带来的总线竞争,既能够全带宽访存DDR3,又克服了多内核竞争引起的程序阻塞,可以兼顾公平和高效。

图5 数据从DDR3到MSMS传输耗时Fig.5 Time consuming of data transmission from DDR3 to MSMS
3.3内存数据传输与CPU运算并行设计
C6678DSP中MSMS接口带宽64GB/s,LL2S接口带宽为16GB/s,因此MSMS到LL2S的访存速度非常快,能够允许多个EDMA通道同时访存。MSMS工作在1/3CPU主频,LL2S工作在1/2CPU主频,且LL2S可以自动完成内存一致性维护,所以CPU对LL2S的访存效率更高。因此,进一步设计了基于ping-pong存储的内存数据传输与CPU并行方法,通过ping-pong存储使EDMA和CPU同一时刻访存不同的存储区间,从而将数据在MSMS和LL2S之间的后台传输与CPU运算并行。如图6所示基于ping-pong存储的数据传输与CPU运算并行设计,该方法的实现步骤为:
1)各核心分别在LL2S中开辟ping-pong缓存区,EDMA将数据从MSMS传输到LL2S的ping缓存,数据传输完成但暂不处理,而是启动EDMA将数据后台传输至pong缓存,不等待数据传输结束。
2)等待ping传输结束,如果结束则对ping内存数据进行处理,否则等待直至传输结束后CPU再执行处理程序。
3)ping处理完成后读出,但不等待ping读出结束,而是使读出结束自动触发ping的读入中断服务程序。
4)等待pong传输结束,如果结束则对pong内存数据进行处理,否则等待直至传输结束后CPU再执行处理程序。
5)pong处理完成后读出,但不等待pong读出结束,而是使pong读出结束自动触发pong的读入中断服务程序,程序返回到步骤2.
6)循环结束,依次等待ping-pong传输结束,同时CPU完成相应数据的处理。
采用基于ping-pong存储的数据传输与CPU运算并行设计,可在后台将待处理数据从MSMS传输到访存性能更好的LL2S,该方法既可以避免人工进行Cache一致性维护,简化程序,又不占用CPU处理时间。图7是程序采用常规串行设计和数据传输与CPU运算并行设计,各核完成声纳回波数据二维相控搜索耗时的100次统计平均。由图7可知,采用数据传输与CPU运算并行设计,数据传输被完全并入CPU运算耗时,数据传输不增加程序开销。
3.4汇编指令流水线设计
C66xCPU有两组完全并行的处理通路A和B,每组通路有L、S、M、D4个独立的功能单元。每时钟周期,CPU可以读取一个指令包,每个指令包最多可含有8条32位指令,只要功能单元不冲突,同一包内的指令完全并行。但大部分C66x汇编指令的执行需要多个时钟周期,需要空等待指令NOP的驱动。指令的多周期性极大地限制了CPU运算能力的发挥。
本文采用指令并行和相互驱动的汇编指令流水线设计方法,开发求和、复乘、滤波、取共轭等矢量算法函数。通过指令排流水尽可能地增大指令包内的指令个数,使一个NOP驱动更多的指令,然后进一步利用指令包互相填充延迟间隙,避免使用NOP指令驱动,以实现多次迭代的并列执行,实现C66x CPU的满负荷运算。

图6 基于ping-pong存储的数据传输与CPU运算并行设计Fig.6 Parallel processing design of data transmission and CPU computation based on ping-pong memory
4 海上试验
综合采用上文所述的并行处理方法,控制8核流水线访问外存DDR3,以避免并发访问引起程序阻塞,控制EDMA和CPU互斥访问内存空间,以降低内存数据传输耗时,控制汇编指令相互驱动,以提高CPU使用率,在一台仅拥有8片C6678DSP的信号处理机上开发了二维相控方位滤波的实时处理软件。
组织海上试验,以验证基于本文多级并行处理方法开发的二位相控方位滤波软件的实时性和可靠性。首先在某海域用条石作为配重,布放了一个浮球目标,然后进行实时扫海试验。试验结果表明,该实时处理软件在15kn高航速下,仍可以实现每秒对32×32元面阵完成64(方位)×64(俯仰)× 8192(距离)共32兆像素点的实时聚焦成像,获得清晰的浮球及其配重石块的三维图像。说明该处理软件可以以较小的硬件规模,突破大数据率声纳强实时成像的难题。浮球及石块三维成像的试验效果如图8所示,悬浮小球清晰可见,配重条石轮廓分明。

图7 顺序处理和并行设计方式下相控方位滤波耗时Fig.7 Time consumed by phased azimuth filter with serial design and parallel processing design

图8 浮球及条石的三维成像效果Fig.8 Sonar image of suspended ball and rectangle stone
5 结论
本文设计了一种基于C6678多核DSP的声纳信号多级并行处理方法,并以声纳中较为复杂的二维相控滤波为例,逐级测试并行效果。测试结果表明:该方法通过控制8核流水线访问DDR3外存,可以避开外存总线竞争,实现外存数据的全带宽读取与运算的并行;通过控制EDMA与CPU互斥访问内存,可以实现内存数据传输的零开销;通过汇编语言的相互驱动,可以实现CPU的满负荷运算。因此,本文方法有利于突破大数据率声纳高集成度和强实时性的难题。海上试验表明,采用本文多级并行处理方法开发的实时处理系统,稳定可靠,且具有集成度高和实时性强的优点,获得了水中浮球和配重条石清晰的实时成像效果,证明本文方法具有较高的工程应用价值。
(References)
[1] 李启虎.进入21世纪的声纳技术[J].应用声学,2002,21(1):13-18. LI Qi-hu.Sonar technology in entering the 21st century[J].Applied Acoustics,2002,21(1):13-18.(in Chinese)
[2] 王磊,刘道福.片上多核处理器共享资源分配与调度策略研究综述[J].计算机研究与发展,2013,50(10):2212-2227. WANG Lei,LIU Dao-fu.Survey on partitioning and scheduling policies of shared resources in chip multiprocess[J].Journal of Computer Research and Development,2013,50(10):2212-2227.(in Chinese)
[3] 袁琪,杨康.大点数FFT算法C6678多核DSP的并行实现[J].电子测量技术,2015,38(2):74-80. YUAN Qi,YANG Kang.Implementation of large points FFT based on C6678 multi-core DSP[J].Electronic Measurement Technology,2015,38(2):74-80.(in Chinese)
[4] Suh G,Devadas S,Rudolph L.Dynamic partitioning of shared cache memory[J].The Journal of Supercomputing,2004,28(1): 7-26.
[5] 周本海,乔建忠.基于多核处理器的动态共享缓存分配算法[J].东北大学学报:自然科学版,2011,32(1):44-47. ZHOU Ben-hai,QIAO Jian-zhong.Research on the dynamic allocation algorithm of shared cache for multicore processor[J].Journal of Northeastern University:Natural Science,2011,32(1): 44-47.(in Chinese)
[6] Texas Instruments.TMS320C6678 multicore fixed and floatingpoint digital signal processor data manual[M].Texas:Texas Instruments,2012.
[7] Texas Instruments.Keystone architecture multicore shared memory controller(MSMC)user guide[M].Texas:Texas Instruments,2012.
[8] Élias G.Source localization with a two-dimensional focused array: optimal signal processing for a cross shaped array[C]∥The 1995 International Congress on Noise Control Engineering.Newport Beach,CA,US:International Institute of Noise Control Engineering,1995:1775-1778.
Sonar Signal Processing Parallel Design Based on C6678 Multicore DSP
JI Xia,CONG Wei-hua,DU Shuan-ping
(State Key Laboratory of Sonar Technology,Hangzhou Applied Acoustics Research Institute,Hangzhou 310012,Zhejiang,China)
In parallel processing system with multicore,it is hard to turn the improvement of hardware into the efficiency of software substantially for the drastic competition of shared resources on chip.To solve the problem,a multistage parallel sonar signal processing method based on C6678 multicore digital signal processor(DSP)is presented by scheduling memory access and multicore synchronization,which includes multicore pipeline design,parallel processing design of data transmission and CPU computation,and assembly code pipeline design.The multi-parallel stage method is introduced by taking two-dimension phased azimuth filter as an example.Performance of each stage above is tested,and a real-time processing software is developed.Test result shows that the proposed method can parallel memory access and CPU computation effectively,and the software developed based on the proposed method works efficiently. In a high speed sea trial,the sharp images of a suspension ball and its counterweight rectangle stone were got by the real-time processing system.The multistage parallel processing method is of great application value in engineering.
acoustics;sonar;phased azimuth filter;multicore DSP;parallel processing
TB566
A
1000-1093(2016)08-1476-06
10.3969/j.issn.1000-1093.2016.08.020
2015-05-18
武器装备预先研究项目(7301303);
汲夏(1986—),男,博士研究生。E-mail:ljx060721@163.com;杜栓平(1970—),男,研究员,博士生导师。E-mail:skldusp@tom.com
