类标噪声研究综述
2016-09-23宋磊磊
宋磊磊
(四川大学计算机学院,成都 610065)
类标噪声研究综述
宋磊磊
(四川大学计算机学院,成都610065)
0 引言
文本分类被广泛应用于信息检索与其他知识管理系统中。一些常用的用于解决文本分类的有监督方法包括:朴素贝叶斯[1-2]、支持向量机[3-4]、K近邻[5]和最大熵模型[6]。
文本分类任务需要大量的被正确标注的训练数据集,这些标注数据集往往来自人工标注或者远距离监督方法。然后,不管是人工还是自动的标注,都会不可避免地引入类标噪声,对分类器的构建产生严重的影响。因此,研究有效地处理噪声方法就变得十分重要。主流的方法主要分为两种,第一种是去噪研究,即首先识别噪声实例,进而直接删除噪声数据以保证数据的“纯度”;第二种是容噪研究,与去噪算法不同的是,该思路假设噪声实例同样可以对分类器提供积极影响,前提是从模型的角度合理的挖掘其积极因素。
1 类标噪声处理策略
1.1去噪算法研究
早期的类标噪声处理思路主要集中在如何准确的识别出噪声实例,借用的模型有最近邻算法[7]、C4.5[8]、概率主题模型[9]和类别数据分布[10]。以下对前两个方法进行介绍:
(1)最近邻算法去噪
该方法利用最近邻算法制定启发式规则识别噪声实例。总的数据集为T,包括n个实例P1…n,每个实例P 有K个最近的邻居P.N1...k。P的“敌对”近邻集P.E被定义为与P具有不同类标的最近实例。P.A1...a表示包括最近邻集中包括P的实例的集合。那么,假如实例P被删除时,P.A1...a中的实例被分类判断正确,则说明实例P是噪声数据,应该被去除。具体的算法如图1所示。

图1 最近邻算法去噪
(2)C4.5去噪
该方法利用C4.5决策树算法来进行噪声识别,它的直观假设是当我们获得可靠的规则时,噪声实例与正常实例表现出了不同的特点,通常噪声实例会被可靠规则所覆盖,但是却产生错误的类标。基于以上的假设,该方法首先将整个数据集E分成若干个子集。对于每个子集,学习一个决策树模型Ri并从中选择可靠的规则集GRi,接着利用GRi评价整个数据集E。对于具体某个实例Ik,定义两个错误计数变量和,它们共同决定改实例是否为噪声数据。具体的框架流程如图2所示。
1.2容噪算法研究
去噪算法存在着潜在的风险,特别是当模型错误的识别了噪声数据,而把真正的噪声实例保留下来作为标准训练集时。可想而知,此时的去噪算法不但没有达到清理噪声的目的,而且还加剧了噪声数据对分类模型的影响。因此,噪声处理的重心开始向容噪研究方法转移。其中,比较典型的容噪算法包括改进的支持向量机[11]、BayesANIL[12]和Probabilistic Kernel Fisher method[13]。以下介绍前两个方法:
(1)改进的支持向量机
该方法在原有支持向量机的基础上仅仅对核矩阵进行修改,达到了容忍噪声的目的。我们知道,标准的SVM优化函数可以表示为:
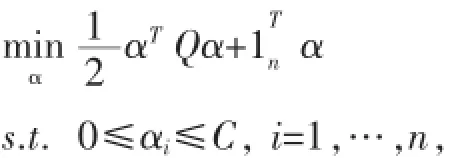
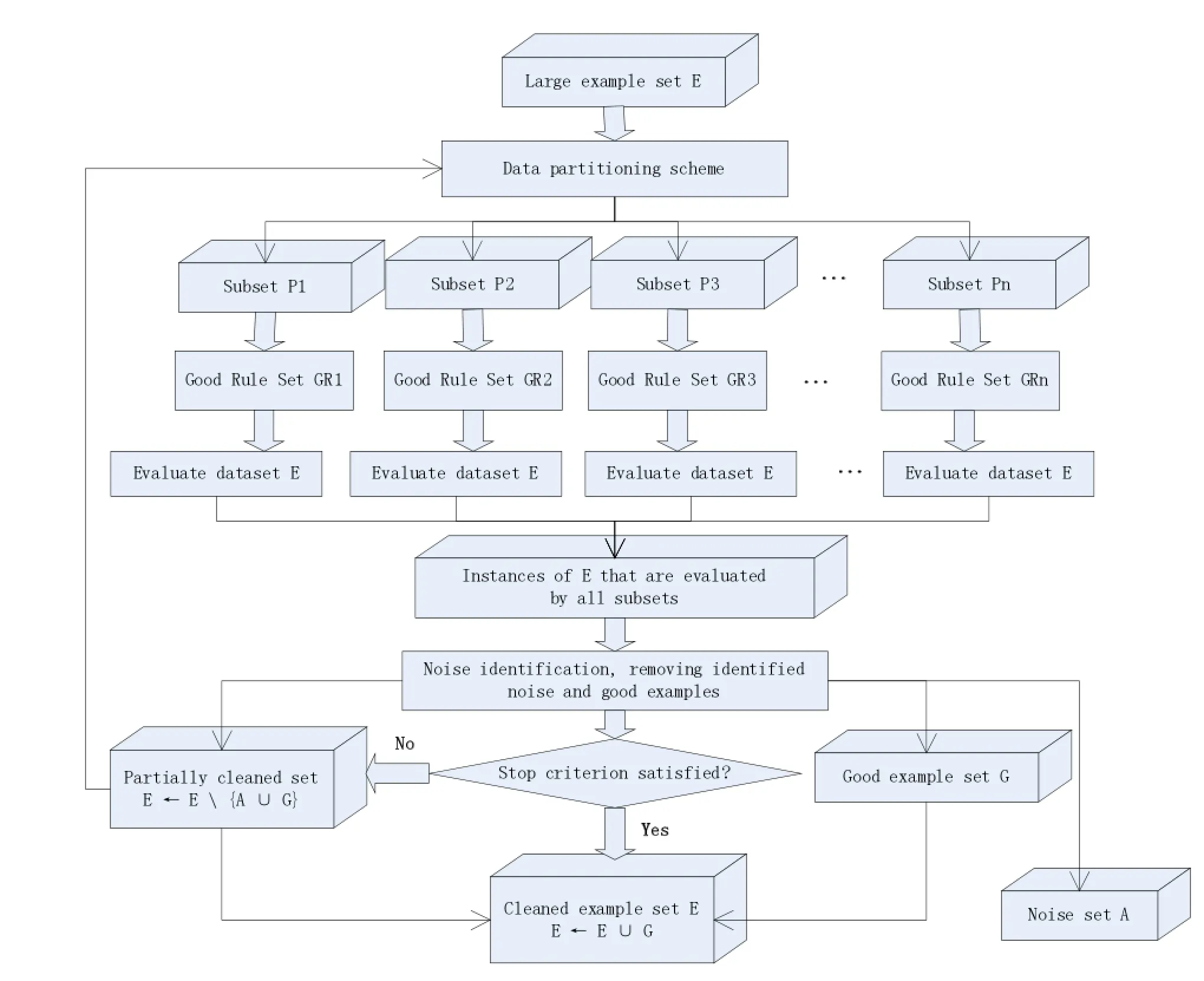
图2 C4.5去噪
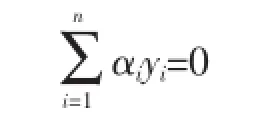
其中,Q=KoyyT,K为核矩阵。本文对每个实例xi引入了翻转变量εi,从而使得Q发生变化,最终影响SVM的优化函数为如下所示:
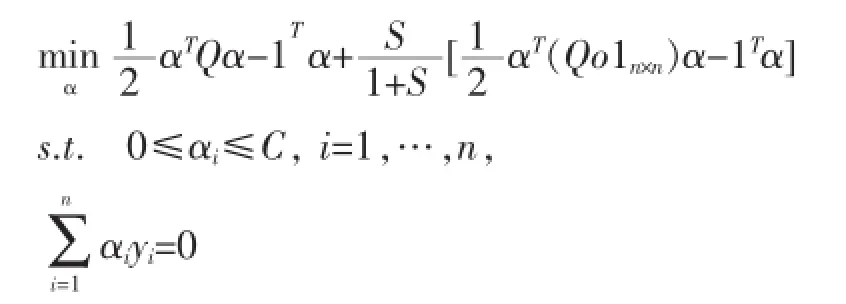
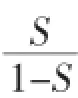
(2)BayesANIL
该方法对生成的角度对噪声数据进行建模,模型可简单表示成Z→D→W,三个变量分别表示实例类标、实例以及实例的词袋子。其中P(w|d)与<d,z>为可观测值,P(d,z)为潜在变量值,也是本文需要估计的变量值,该值可以直观地理解为实例d在多大程度上属于z类。因此,本文利用EM算法对潜在变量进行估计,最终将P(d,z)运用到朴素贝叶斯和支持向量机分类器中,取得了不错的效果。
对于朴素贝叶斯分类器,关键在于估计词在类别条件下的概率:
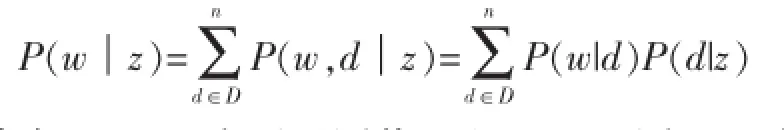
其中,P(w|d)为可观测值,而P(d|z)可由EM估计的P(d,z)得到。此种方法的优势还在于P(w|z)不需要平滑处理。
对于支持向量机分类器,我们可以改变每个实例的损失代价,让那些值得信赖的类标数据尽量被判别正确,而对于那些潜在的噪声数据设置一个较小的损失代价。形式化表示如下,Ci为损失代价。
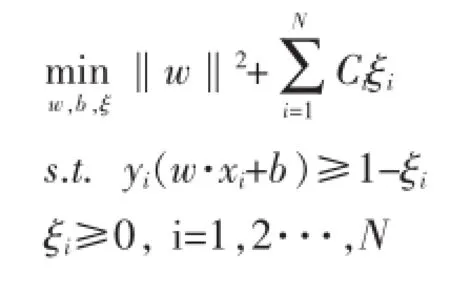
2 结语
随着网络数据量的爆炸式增长,如何利用大数据,从中挖掘出有价值的资源变得更加迫切。机器学习作为一种行之有效的方法在实际运用中需要大量的人工参与,例如为分类器标注大量的数据。而人工参与不可避免带来数据噪声,这是现有分类算法所不能容忍的。因此,大量的研究者开始设计不同的策略消除噪声的影响。早期的研究主要关注如何正确识别噪声实例。遗憾的是,去噪思路在实际运用中引入了潜在的风险,这才将研究的重心向容噪算法转移。但即使同是容噪算法,在处理不同问题、噪声水平不同时也表现不一。
[1]Lewis D D.Naive(Bayes)at Forty:The Independence Assumption in Information Retrieval[M].Machine Learning:ECML-98.Springer Berlin Heidelberg,1998:4-15.
[2]McCallum A,Nigam K.A Comparison of Event Models for Naive Bayes Text Classification[C].AAAI-98 Workshop on Learning for Text Categorization,1998,752:41-48.
[3]Joachims T.Text Categorization with Support Vector Machines:Learning with Many Relevant Features[M].Springer Berlin Heidelberg,1998.
[4]丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J].电子科技大学学报,2011,40(1):2-10.
[5]Yang Y.An Evaluation of Statistical Approaches to Text Categorization[J].Information Retrieval,1999,1(1-2):69-90.
[6]Nigam K,Lafferty J,McCallum A.Using Maximum Entropy for Text Classification[C].IJCAI-99 Workshop on Machine Learning forInformation Filtering,1999,1:61-67.
[7]Wilson D R,Martinez T R.Instance Pruning Techniques[C].ICML.1997,97:403-411.
[8]Zhu X,Wu X,Chen Q.Eliminating Class Noise in Large Datasets[C].ICML.2003,3:920-927.
[9]林洋港,陈恩红.文本分类中基于概率主题模型的噪声处理方法[J].计算机工程与科学,2010,32(7):89-92.
[10]李湘东,巴志超,黄莉.文本分类中基于类别数据分布特性的噪声处理方法[J].现代图书情报技术,2014,30(11):66-72.
[11]Biggio B,Nelson B,Laskov P.Support Vector Machines Under Adversarial Label Noise[C].ACML.2011:97-112.
[12]Ramakrishnan G,Chitrapura K P,Krishnapuram R,et al.A Model for Handling Approximate,Noisy or Incomplete Labeling in Text Classification[C].Proceedings of the 22nd International Conference on Machine Learning.ACM,2005:681-688.
[13]Li Y,Wessels L F A,de Ridder D,et al.Classification in the Presence of Class Noise Using a Probabilistic Kernel Fisher Method [J].Pattern Recognition,2007,40(12):3349-3357.
Class Label Noise;Denoising Algorithm;Robustness Algorithm
Research Overview of Class Label Noise
SONG-Lei-lei
(College of Computer Science,Sichuan University,Chengdu 610065)
1007-1423(2016)03-0020-04
10.3969/j.issn.1007-1423.2016.03.005
宋磊磊(1991-),男,贵州贵阳人,硕士研究生,研究方向为数据挖掘
2015-12-15
2016-01-10
在机器学习中,类标噪声难以避免的存在于标注数据里,这样的噪声数据会对分类器等模型的建构产生严重的影响。因此,越来越多的研究者把类标噪声算法研究作为分类器效果提升的一个突破口。针对解决问题思路的不同,提出并改进许多行之有效的噪声处理模型。其中,按照解决思路的不同,可将噪声处理算法分为去噪算法与容噪算法。
类标噪声;去噪算法;容噪算法
In machine learning,the class label problem is unlikely to be completely excluded in labelled dataset which would deteriorate classifier construction.Therefore,most of researchers are focusing on this problem for more reliable classification algorithms.There are lots of effective approaches for the class label problem according to different solutions.We can divide them into denoising and robustness directions.
