基于网页排名的其他链接方法的研究
2016-09-14张家健赵冰
张家健,赵冰
(河海大学 商学院,江苏 南京 211100)
基于网页排名的其他链接方法的研究
张家健,赵冰
(河海大学 商学院,江苏 南京211100)
目前针对主要的排名算法PageRank和HITS的研究与应用较广泛,同时,其它排名算法也逐渐得到了研究者的重视。文中将对其它排名算法中的SALSA和TrafficRank进行研究。文中首先对布尔搜索引擎、向量空间模型引擎、概率模型搜索引擎、元搜索引擎等基本搜索引擎模型进行综述,总结各基本搜索引擎模型的特征和优缺点。其次对SALSA和TrafficRank的算法进行分析,总结出两种排名算法的特征和优缺点。
布尔搜索引擎;向量空间模型引擎;概率模型搜索引擎;元搜索引擎;SALSA;TrafficRank
蒂姆·伯纳斯-李和他的万维网于1989年进入了信息检索的世界,记录网络信息检索的链接分析方法是包括谷歌使用的PageRank和Teoma使用的HITS在内的现今最为流行且成功的多个搜索引擎的底层机制。截至2004年1月,万维网包含了超过100亿个页面。如何准确并快速地在巨量的信息世界中寻找到对自己有价值的内容?当然这离不开搜索引擎,影响搜索引擎有效性的因素有许多,但从根本上说,关键在于搜索引擎自身的链接算法设计。
1 基本模型
网络信息检索是在世界上最大且相互链接的文档集中进行的搜索,大多数搜索引擎依赖于以下基本模型中的一种或者多种:
1)布尔搜索引擎
信息检索的布尔模型是最早最简单的检索方法之一,它使用严格匹配来将文档与用户的查询进行比对。该模型经过改良的派生方法为大多数图书馆所使用。信息检索的布尔模型工作原理是考察在文档中有哪些关键词出现了或未曾出现,并据此判定文档与检索相关或无关[1]。但是标准的布尔引擎无法返回那些语义相关但关键词未被包括在原始查询中的文档。许多布尔搜索引擎要求用户熟悉布尔运算符以及引擎的特殊语法。布尔模型的各种变体构成了许多搜索引擎的基础,其优点包括:建立并编写布尔引擎是直接的;查询处理迅速,可以采用并行方式对文档的关键词文件进行快速扫描;布尔模型可以很好地扩展到大的文档集[2]。
2)向量空间模型引擎
该模型中,向量空间模型被用于避开前述的若干信息检索难题[3]。向量空间模型将文本数据变换为数值向量和矩阵,使用矩阵分析方法来发现文档集之中的关键特征和联系。一些高级向量空间模型能够访问文档集中隐含的语义结构[4]。该模型的优点包括:①相关性评分:通过给每个文档赋予一个0到1之间的数,向量空间模型允许进行文档的部分匹配查询。该数值可以被解释为文档与查询之间的相关似然度。进而检索到的文档集可以根据相关程度进行排序。按照这一方式,向量空间模型以有序的列表返回结果文档,按照相关性的分数排序,返回的第一个文档被认为是与用户查询最为相关者,一些向量空间搜索引擎以相似度比例的形式给出相关性的评分。该模型的缺点为:必须计算每个文档和查询之间的距离度量,随着文档集的增大,矩阵分解的开销将使模型不再具有可行性[5];向量空间模型无法很好地扩展,它仅局限于小文档集。
3)概率模型搜索引擎
概率模型试图对用户找到某个特定相关文档的概率进行估计,检索得到的文档根据它们的相关几率进行排名。概率模型以递归的方式运行,并要求算法能够猜测得到初始参数,进而逐次尝试改善这一初始猜测,以得到最终的相关几率的排位[6]。概率模型的缺点为:构建和编程难度较大,因此限制了其扩展性。同时该模型要求做出若干不现实的假设。该模型的优点在于概率框架可以自然地纳入先验偏好,可以做到针对单个用户的偏好调整搜索结果。
4)元搜索引擎
该模型将以上3种模型相结合,其工作原理是用一个搜索引擎来搜索可以完成任务时,用两个或以上搜索引擎搜索的效果更显著。一个搜索引擎可能在某个任务上十分出色,而第二个搜索引擎则可能在另一项任务上表现好于第一个搜索引擎。元搜索引擎可以充分利用许多单独的搜索引擎各自具有的最佳特性,可以同时将一个查询发送至数个搜索引擎,并将所有这些搜索引擎的结果以一个统一的列表返回。元搜索引擎可以应用于某个特定学科内的搜索[7]。
加快农业产业化发展。支持具有比较优势的龙头企业建设现代农业精深加工项目,建立示范性生产基地,大力培育省级农业产业化集群。鼓励农民专业合作社发展农产品加工、销售,拓展合作领域和服务内容,积极发展订单性农产品生产、加工、配送。
2 SALSA
2.1SALSA示例
1998年开始,人们利用PageRank或HITS对网页的受欢迎程度进行排名。2000年,SALSA方法也被应用于这一领域[8]。SALSA(Stochastic Approach to Link Structure Anatysis)是由罗尼·伦佩尔和什洛莫·莫兰发明的一种网页排名方法,该算法采用了HITS的评分方法,为网页生成了枢纽和权威评分;同时结合了PageRank的导出方式,评分由马尔可夫链导出。
1)SALSA示例
首先为某个特定查询产生一个对应的领域图N,如图1所示:
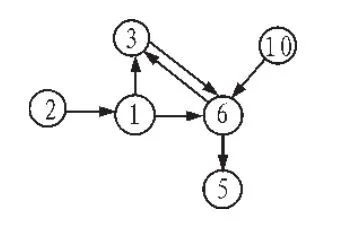
图1 页面1和6的领域图NFig.1 Page 1 and 6 field figure N
SALSA和HITS的区别在于,SALSA并不构造领域图N的领接矩阵L,而是构建了一个二分无向图G。其中G由三个集合给出:枢纽结点集合Vh(N中所有出度>0的结点)、权威结点集合Va(N中所有入度>0的结点)和N中有向边的集合E,N中的某个结点可能同时出现在Vh和Va中。因此,对于上述领域图可得:
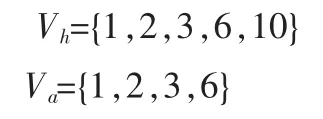
如图2所示,二分无向图G中有一个枢纽侧和一个权威侧。Vh中的结点列在枢纽侧,Va中的结点列在权威侧。E中的每条有向边由G中的一条无向边所表示。
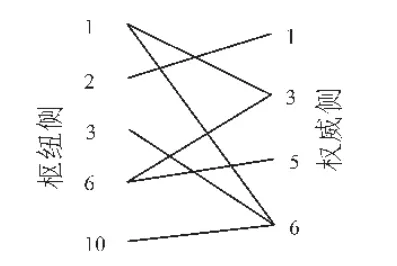
图2 G:SALSA的二分图Fig.2 G:binary chart of SALSA
由此,G可以得出两条马尔可夫链:一条枢纽马尔可夫链,转移概率矩阵为H;一条权威马尔可夫链,转移概率矩阵为A。HITS使用了N的邻接矩阵L以计算未加权矩阵L的权威和枢纽评分,PageRank使用行归一化的加权矩阵G以计算类似于权威评分的度量。SALSA则同时使用了行加权和列加权的非零列除以其列和后所得的矩阵。进而计算领域图N可得:


由此得出的SALSA枢纽矩阵和权威矩阵为:

如果二分图G是联通的,那么H和A就均为不可约的马尔可夫链,而H的稳态向量可以给出查询关于领域图N的枢纽评分,则可以给出权威评分;如果G不连通,那么H和A各自包含若干个不可约的组分,此时需要通过将每个单独的不可约部分的稳态向量拼接以得到全局的枢纽和权威评分。对于更大的图,不能通过简单地观察来了解联通性时,那么也已经有图的遍历算法,可以判断图的连通性并识别其联通组分[9]。由于G不连通,因此H和A中包含了多个联通组分,H包含了两个联通组分,即C={2},和D={1,3,6,10};A的联通组分为E={1}和F={3,5,6}。H和 A中所有不可约组分均包含了自循环,即以上的链均是非周期的。H的两个不可约组分的稳态向为:
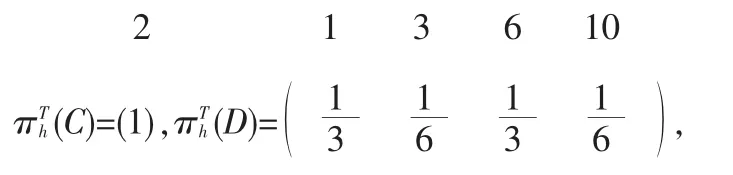
而A的两个不可约组分的稳态向量为:
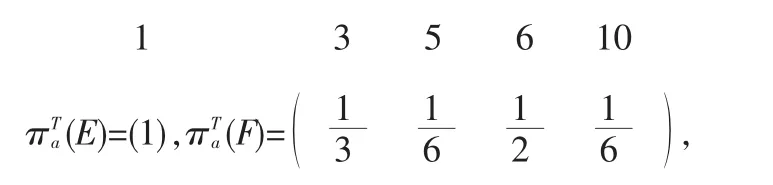
既然枢纽组分C仅包含了所有5个枢纽结点中的1个,那么其稳态枢纽向量的权值为1/5,而D包含了5个枢纽结点中的4个,其稳态向量的权值为4/5。因此,全局的枢纽向量为:

对权威结点进行加权,可由单独的权威向量构成出全局权威向量:
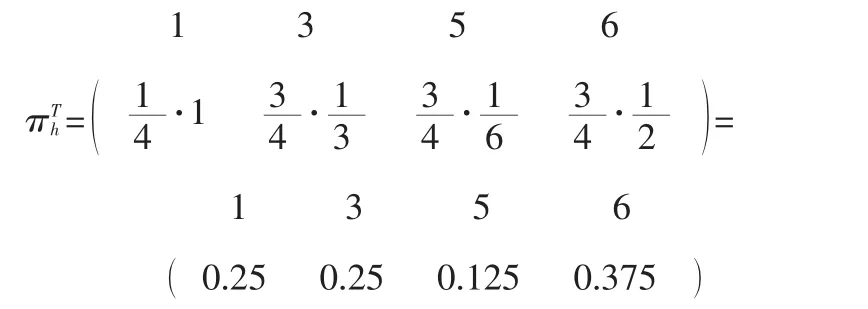
有上述示例可以可出如下结论:1)SALSA是将独立部分的评分加以拼接以构成全局评分的一种方法;2)多个联通组分对于计算是个优点,因为现在有待求解的马尔代夫链较小。这与PageRank对不连通网络图进行的人工调整形成对比,PageRank中的调整需要通过在所有的网页间增加有向链接以使联通性成立。
2.2SALSA优缺点分析
SALSA将HITS和PageRank的特点进行了结合,因此,SALSA具有的优点包括:不存在主题漂移问题,即跑题的重要页面会混进领域集并由此获得了位居前列的评分;因为枢纽和权威评分之间的耦合相对较弱,SALSA受垃圾信息影响的程度较低;SALSA的二分图G中存在的、实际中常常会出现的多个联通组分,对于计算而言非常有利。
但是SALSA也存在阻碍其广泛使用的因素,即其查询相关性。在查询期间,必须构建查询的领域图N并计算两条马尔可夫链的稳态向量;SALSA的另一个缺陷是收敛性。SALSA的收敛性和HITS相似,原始形式的HITS和SALSA都不能强行使得图具有不可约性,因此当领域图可约时,算法给出的向量可能不唯一[10]。
3 TrafficRank
排名算法在为网络信息检索提供帮助时具有较高的有效性,很多新的算法都是基于PageRank、HITS、SALSA3种方法的改进或组合[11]。而TrafficRank则是一种原创性的新的排名算法。
令Pij为由页面i到页面j的链接上的流量占总网络流量的比例。如果没有从i到j的超链接,则Pij=0。Pij的这一定义意味着,对万维网中的每条超链接对对应着一个变量。对这些Pij的值进行估计,然后将进入页面j的流量比例作为页面j的TrafficRank值。变量Pij必须满足某些约束:;对任何页面j,有;Pij可以任意取值。因此,TrafficRank模型中的Pij值:,满足对所有j,
这个熵函数对选择Pij的自由度进行了最大化,在以上约束条件下,对这些概率的最佳无偏估计。进而求解这个最优化问题来获得Pij,并给出每个页面的TrafficRank值。利用拉格朗日乘子对最优化问题中的多个变量进行快速迭代计算,高的 TrafficRank值倾向于对应具有许多出链的情况。TrafficRank衡量了流经一个页面的流量,而大量的流量需要大量的入链和出链。
TrafficRank的优点为:当等多的流量信息变得可用时,可以用约束的形式将这些信息加入到模型中;对于该最优化问题的对偶解,将原始解的拉格朗日乘子取倒数,会得到每个网页的HotRank。
4 结 论
网页排名的链接算法在为网络信息检索提供帮助的这一方面已经展现了有效性,但是无论是SALSA、TrafficRank、HITS或是PageRank,目前的研究都还不尽完善。由于不同算法给出的排名前K位的网页列表彼此之间存在明显差别,因此未来的研究工作可以将多个相互独立的评分算法的结果加以融合。
[1]Ricardo Baeza-Yates and Berthier Ribeiro-Neto.Modern Information Retrieval[C]//.ACM Press,New York,1999: 1217-1264.
[2]William B.Frakes and ricardo Baeza-Yates.Information Retrieval:Data structures and algorithms[C]//Prentice Hall,Englewood Cliffs,NJ,1992:381-419.
[3]Gerard Salton and Chris Buckley.Introduction to Modern Information Retrieval[M].McGraw-Hill,New York,1983.
[4]Susan T.Dumais.Improving the retrieval of information from external sources[C]//.Behavior Research Methods,Instruments and Computers,1991.
[5]Carl D.Meyer.Matrix Analysis and Applied Linear Algebra [C]//.SIAM,Philadelphia,2000.
[6]Michael W.Berry and Murray Browne.Understanding search engines:mathematical modeling and text retrieval[J].SIAM,Philadelphia,2an edition,2005:78-93.
[7]Paolo Boldi and Sebastiano Vigna.The WebGraph framework II.Codes for the World Wide Web[C]//.Technical Report 286-03,Universita di Milano,Dipartimento diScienze dell’Informazione Engineering,2003.
[8]Ronny Lempel and Shlomo Moran.The stochastic approach for link-structure analysis and the TKC effect.In The Ninth International World Wide Web Conference[C]//.New York,2000.ACM Press,2000:161-226.
[9]Thomas H.Cormen,Charles E.Leiserson,Ronald L.Rivest,and Clifford Stein.Introduction to Algorithms[C]//.MIT Press,2001(11):278-296.
[10]Ayman Farahat,Thomas Lofaro etc.Authority rankings from HITS,PageRank,and SALSA:Existence,uniqueness,and effect of initialization[J].SIAM Journal on Scientific Computing,2006 (27):1181-213.
[11]Matthew Richardson and Petro Domingos.The intelligent surfer:Probabilisticcombinationoflinkandcontent information in PageRank[J].Advances in Neural Information Processing Systems,2002(14):1398-1399.
The research of other links method based on page rank
ZHANG Jia-jian,ZHAO Bing
(Business School of HOHAI University,Nanjing 211100,China)
There are a lot of PageRank and HITS against the main ranking algorithm study.At the same time,other ranking algorithms also gradually got the attention of the researchers.This paper will study of SALSA and TrafficRank.This paper summarizes the basic characteristics and advantages and disadvantages of search engine model,including the Boolean search engine,vector space model engines,search engines,metasearch engines.Finally,this paper analyzes the algorithm of the SALSA and TrafficRank,summed up the characteristics and advantages and disadvantages of these two kinds of ranking algorithm.
Boolean search engine;vector space model engines;search engines;metasearch engines;SALSA;TrafficRank
TN99
A
1674-6236(2016)02-0128-04
2015-03-31稿件编号:201503473
江苏省社科联研究基金(201035)
张家健(1987—),男,江苏南京人,硕士。研究方向:企业管理、技术经济。
