基于Hadoop的排序性能优化研究
2016-09-14李千慧魏海平窦雪英
李千慧,魏海平,窦雪英
(1.辽宁石油化工大学 计算机与通信工程学院,辽宁 抚顺 113001;2.中国寰球工程公司辽宁分公司信息中心 辽宁 抚顺 113006)
基于Hadoop的排序性能优化研究
李千慧1,魏海平1,窦雪英2
(1.辽宁石油化工大学 计算机与通信工程学院,辽宁 抚顺 113001;2.中国寰球工程公司辽宁分公司信息中心 辽宁 抚顺 113006)
如何高效排序是在对大数据进行快速有效的分析与处理时的一个重要问题。首先对基于Hadoop平台的几种高效的排序算法(Quicksort,Heapsort和Mergesort算法)进行了研究。再通过对Hadoop平台的几种现有的排序算法的分析比较,发现频繁的读写磁盘降低数据处理的效率,提出了一种优化现有排序算法的置换选择算法,并进行了测试。测试结果表明,该算法简化了运行过程,可实现更快速的合并,从而提高数据处理的效率,对Hadoop的性能优化具有现实意义。
Hadoop;排序优化;置换选择算法;大数据
随着互联网等信息技术的飞速发展,网络用户的快速增加,各行各业中的数据也日益增长,形成了海量数据。这些数据是不但数据体量巨大,而且是高价值的,具有多样化和持续性等特点。其非结构化的特性,使得数据的存储和处理成了当前面临的挑战。这些数据需要在大型的分布式集群上来处理。如何有效地处理这些并行的计算,管理海量分布式的数据以及对大数据进行分析与处理,成为急需解决的重点问题。MapReduce是一个广泛应用于大数据分析和处理的计算框架[1-2]。Hadoop作为Apache开源组织的一个分布式计算并行编程框架[3],能够实现MapReduce计算模式的分布式并行编程,逐渐成为业界使用的标准。Hadoop已经应用在许多国内外的知名网站上,如Facebook、雅虎和百度等。其分布式文件系统的高容错性和高扩展性,能够满足数据量迅速增长的需要,所以已经广泛的用来解决海量数据的处理问题[4]。
本文经过对MapReduce计算模式研究后发现,MapReduce中的缺省排序本身既是一种对数据普遍的处理方式,也是一种预处理。但是针对日益增长的海量数据的分析处理,传统的排序方法由于大多是基于关键字的比较和交换两种操作,导致多次读取磁盘,所以消耗时间较多,难以有效地处理数据。本文通过优化排序减少对磁盘的读写操作,能使得后续处理更加高效、快捷。
1 Hadoop中的排序
排序算法分为两类:内部排序和外部排序[5-6]。内部排序是指输入数据在内存中进行排序,包括Quicksort,Heapsort和Mergesort等算法。当需要对一个非常大的文件中的内容进行排序时,由于计算机内存是有限的,数据不能完全存入内存时,则无法使用内部排序算法一次完成排序,需要利用磁盘空间进行外部排序。
1.1Hadoop中排序机制及排序算法
在Hadoop分布式环境中,Hadoop的排序功能是非常强大的,能够对TB级数据进行排序。当输入记录的规模较大时,利用快速排序、堆排序、归并排序这些时间复杂度为O (nlog(n))的排序算法。
1.1.1Quicksort
快速排序(Quicksort)是一个交换的排序算法,在实际中经常被使用,例如Microsoft.NET框架中。该算法被递归地应用到每个子集,直到所有记录都在它们的最终位置,其核心是分区操作。在Hadoop中的快速排序算法是通过自定义分区函数以保证数据整体有序。数据经过map函数操作后,通过分区函数进行数据等距划分后进行快速排序,不同范围内的数据划分到不同分区后由对应的reduce处理,最后按序收集各个reduce的数据。
Quicksort在最坏情况下的复杂度为O(n2),但是在实际中,通常比其他复杂度为O(nlog(n))的算法快。
1.1.2Heapsort
堆排序是基于堆的排序,分为最大堆和最小堆,可以用完全二叉树来表示。如图1所示是一个最大堆(由一个数组构成)及其相应的二叉树。
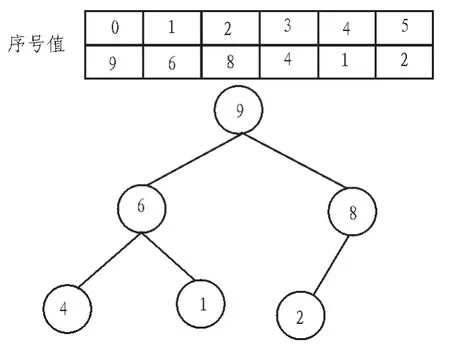
图1 数组与相对的完全二叉树Fig.1 Array and the corresponding complete binary tree
本质上讲,堆排序是一种选择排序,只不过堆排序选择元素的方法更为先进,时间复杂度更低,效率更高。堆排序主要用于形成和处理优先级队列,以及类优先级队列。
1.1.3Mergesort
归并排序的排序方式是基于归并操作的,是将两个或两个以上的有序排列合并成一个大的有序文件。虽然它与快速排序和堆排序相比更加稳定,时间复杂度在最坏的情况下也是O(nlog(n)),但却需要O(n)的辅助空间。
1.2Hadoop平台处理流程
Hadoop框架实现了 MapReduce的分布式并行编程,MapReduce的处理流程图如图2所示[7]。
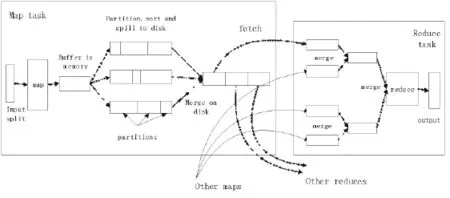
图2 MapReduce的处理流程Fig.2 The processing of MapReduce
MapReduce框架分为 Map与Reduce两个核心处理阶段。
Map阶段:
1)将输入数据做切片处理后交给map函数。
2)运行map函数,其产生的中间输出结果(key/value对)存入内存缓冲区中。
3)根据最终被传送到的reduce对中间结果进行分区,排序后写入本地磁盘。
在Reduce阶段分为3个部分:
1)复制来自若干个map任务的输出文件。
2)对从map阶段复制过来的文件进行归并排序,形成一个大而有序的文件。
3)将归并后的有序文件交给reduce()函数处理,将输出写入Hadoop的分布式文件系统。
1.3Hadoop中排序性能分析
Hadoop集群环境中的应用程序只需要实现 map和reduce方法即可,但是由于需要sort,必须等记录全部接收完,才能开始排序,排序完了才能调用reduce()函数,严重影响了程序运行效率。对于大文件的排序,Hadoop现有的排序方式是将大文件分成n个小文件,分别对这些小文件利用内部排序(快速排序、堆排序等)算法排序。然后再对这些文件进行两两归并,直至归并成一个大的有序文件。这样归并的趟数比较多,导致读写文件的I/O次数增多。相对于内存中的运算,对文件的读写操作是特别费时间的。
在Hadoop集群中,MapReduce的自动排序有m个map,r个reduce。数据被分割成m块的时间复杂度为O(m),每个map进行Quicksort时间复杂度为O(n/mlog(n/m))。当排序任务负载均衡度不高,排序对磁盘反复的操作,加之集群运行时间消耗及网络传输,则Hadoop下Quicksort效率可能低于O(nlog(n))。
2 一种改进的置换选择算法
2.1改进算法的描述
本文提出一种优化Hadoop现有排序的算法,用于生成较长的顺串(初始归并段),以减少归并段的段数。在接收输入数据时使用改进的排序算法生成初始段,用败者树从已经传递到内存中的记录中找到关键值最小的记录并输出,得到一个顺串,暂时放到磁盘,最后将多个顺串进行归并直到最终完成排序。归并的同时,就可以回调reduce()函数,这样就可以一边接收数据,一边部分排序,实现MapReduce的并行化。具体步骤如下:
步骤1:从输入文件中读取n条记录到内存里。
步骤2:用败者树筛选出关键字最小的记录记为MIN,输出到一个临时文件中(或缓存区)。
步骤3:从输入文件中再读取一条记录到内存里 ,用败者树的一次调整过程找到关键字大于MIN的最小值输出到MIN所在的文件(或缓存区)并作为新的MIN。
步骤4:重复步骤3,直到在内存中选不出关键字大于MIN的记录,生成一个顺串,并输出一个归并段结束标签到输出文件。
步骤5:重复步骤2、3、4,直至内存为空,得到全部归并段。将生成的顺串做归并处理,形成一个大的排好序的文件。
利用败者树在内存中筛选MIN细节:1)败者树的外部节点为内存空间中的记录,而败者树中根节点的双亲节点为内存中关键字最小的记录。2)为每个记录设一个所在归并段的序号,简称为段号。筛选MIN记录时,比较段号的大小即可,段号小的为胜者;段号相同的,关键字小的为胜者。
2.2算法性能分析
改进的算法在排序过程中创建初始归并段,总数据量一定的情况下,初始归并段的平均长度变长,从而减小了初始归并段的段数n。处理过程中的归并趟数为logkn,虽然增大归并路数k可以减少对磁盘的操作,但是归并时的算法复杂度也会增加。改进后的算法由于减小了归并段数,可以在O(logk)的复杂度下得到最小的数,每次只需比较log2k次,算法复杂度将为O((n-1)*logk)。对于数据量超大的排序来说,这是可观的提高。
改进后的算法能够从map task端完整的把数据复制到reduce task端,尤其是跨节点复制数据,最大化的降低了复制数据的量以及对带宽的消耗,以尽量减少磁盘I/O对Job完成时间的影响,减少了不必要的消耗。
3 实 验
3.1实验环境
本文实验在一台PC机上搭建伪分布式环境,包含3个节点,一个Master,两个slave节点,而且两个slave的配置保持一致:PC内存8G,64位WIN8系统,虚拟硬件为1G内存,双核处理器,IDE硬盘;以 centOS6.5作为操作系统,JDK 1.7.0作为基础平台,搭建Hadoop1.1.2平台作为底层架构,Eclipse作为编程环境,集群各节点之间SSH免密码登录,虚拟机之间的通信通过虚拟网桥实现。数据来源为搜狗搜索引擎:http://www.datatang.com/data/43846。
3.2实验结果与分析
由图3可以看出,在相同输入量的情况下,经过优化后的置换选择算法比传统快速排序算法的速度快。在数据规模较大的排序过程中改进后的效率明显好于传统排序方式。
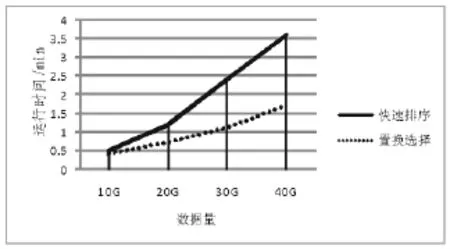
图3 优化前后性能对比Fig.3 The performance comparison before and after optimization
4 结束语
本文针对Hadoop框架实现大规模数据处理的排序进行了研究。首先,基于搭建好的Hadoop伪分布式环境分析了排序算法,提出了改进算法——置换选择算法,然后运行MapReduce程序比较了在具有相同输入量的情况下数据处理的时间。实验结果表明,在对相同的较大数据量进行排序时,置换选择算法优化了基于Hadoop的排序。
[1]EKANAYAK J,PALLICKARA S,FOX G.MapReduce for data intensive scientific analyses[J].Fourth IEEE International Conference on eScience,2008,7(12):277-284.
[2]李建江,崔健,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[3]Dhruba B.Apache Hadoop filesystem and its usage in facebook project lead[EB/OL].[2014-11-20].http://cloud.berkeley.edu/data/hdfs.pdf.
[4]KONSTANTINS,HAIRONGK,SANJAYR,etal.The Hadoop distributed file system[C]//Proceedings of IEEE 26th Symposium on Mass Storage Systems and Technologies.Incline Village:[s.n],2010:1-10.
[5]JACK D,FRANCIS S.Guest editors′introduction:The top 10 algorithms[J].Computing in Science&Engineering,2000,2(1):22-23.
[6]VITTER J S.Algorithms and data structures for external memory[J].Foundations&Trends in Theoretical Computer Science,2006,2(4):29-56.
[7]TOM W.Hadoop:The definitive guide[M].3rd ed.The United States of America:O′Reilly Media,Inc,2009.
Optimization of sorting performance based on Hadoop
LI Qian-hui1,WEI Hai-ping1,DOU Xue-ying2
(1.School of Computer and Communication Engineering,Liaoning University of Petroleum&Chemical Technology,Fushun 113001,China;2.Information Center HQC(Liaoning)CO.,Fushun 113006,China)
When people analysising and processing big data fast and efficiently,how to efficiently sorting is an important issue.There have several efficient sorting algorithms,including Quicksort,Heapsort and Mergesort algorithm,ware studied based on Hadoop platform.Through analysis and the differences of several existing sorting algorithms in Hadoop platform,frequently operating on disk reducing the efficiency of data processing was discovered,so a new sorting algorithm,replacement and selection algorithm,was proposed to optimize the existing sorting algorithm.New algorithm has been tested,and the test results have shown that the new algorithm simplified the process of running,could achieve a more rapidly consolidation,improving the efficiency of data processing,so had practical significanceon Hadoop performance optimization.
Hadoop;optimization of sorting;replacement selection algorithm;big data
TN919
A
1674-6236(2016)02-0045-03
2015-03-31稿件编号:201503462
辽宁省教育科学“十二五”规划立项课题(JG12DB279;JG13DB077)
李千慧(1989—),女,内蒙古自治区赤峰人,硕士研究生。研究方向:计算机网络与多媒体技术。
