基于大数据处理的ETL框架的研究与设计
2016-09-14沈琦陈博
沈琦,陈博
(北京工业大学 北京 100124)
基于大数据处理的ETL框架的研究与设计
沈琦,陈博
(北京工业大学 北京100124)
针对传统抽取、转换、装载(ETL)架构在数据处理过程控制方面和数据产品开发效率方面的不足,提出一种基于大数据处理的ETL架构。通过分析主流的ETL工具--Datastage的工作原理和ETL过程的特点,设计ETL元数据描述模块、ETL任务描述模块、配置解析模块和数据任务调度模块等。使用该框架处理数据任务时,以配置文件的方式开发,使工作效率得到了极大的提升。基于该设计思想开发一款基于大数据处理的ETL工具,在对数据处理过程(E、T、L)的控制方面得到了改进,同时也可以使数据开发人员从大量重复的操作中解脱出来,将更多的精力放在数据的逻辑处理方面。
大数据处理;数据抽取;数据转换;数据加载;ETL框架
信息是现代企业的重要资源,是企业运用科学管理、决策分析的基础。目前,大多数企业花费大量的资金和时间来构建联机事务处理OLTP的业务系统和办公自动化系统,用来记录事务处理的各种相关数据。据统计,数据量每2~3年时间就会成倍增长,这些数据蕴含着巨大的商业价值,而企业所关注的通常只占在总数据量的2%~4%左右。因此,企业仍然没有最大化地利用已存在的数据资源,导致浪费了更多的时间和资金,也失去制定关键商业决策的最佳契机。于是,企业如何通过 各种技术手段,并把数据转换为信息、知识,已经成了提高其核心竞争力的主要瓶颈。而ETL[2]则是主要的一个技术手段。
1 主流的ETL工具——Datastage
DataStage[3]包括设计、开发、编译、运行及管理等整套工具。通过运用DataStage能够对来自一个或多个不同数据源中的数据进行析取、转换,再将结果装载到一个或多个目的库中。通过DataStage的处理,最终用户可以得到分析和决策支持所需要的及时而准确的数据及相关信息。DataStage支持不同种类的数据源和目的库,它既可以直接从Oracle、Sybase等各种数据库中存取数据,也可以通过ODBC接口访问各种数据库,还支持Sequential?file类型的数据源。这一特性使得多个数据源与目标的连接变得非常简单,可以在单个任务中对多个甚至是无限个数据源和目标进行连接。DataStage自带了超过300个的预定义库函数和转换,即便是非常复杂的数据转换也可以很轻松的完成。它的图形化设计工具可以控制任务执行而无须任何脚本。
DataStage整体上还是按照ETL任务处理思想进行数据集成,不过它的并行处理技术使用分区处理技巧,将大型的整合工作切割为分区(分割并行处理)并将这些分区同时传送给所有处理器(管道并行处理)。管道与分区并行处理的组合可提供完整的并行处理功能(效能提升与处理器数量成正比),并让硬件成为性能的唯一决定性因素。不过下游的处理可能需要以不同方式分区数据。透过自动重新分区数据的功能,使用者便可根据下游处理数据分割的需求重新分区处理流程上的数据,而不需要将数据储存在磁盘上。其具体工作流程如图1所示。

图1 Datastage的工作流程图Fig.1 The flow chart of Datastage
DataStage的可执行应用的最小单位为ETL任务。而这些任务是通过DataStage Designer、DataStage Manager、DataStage Director来完成的。DataStage Designer是ETL任务开发的核心环境。DataStage Designer的主要功能可以概括为以下3个方面:ETL任务的开发、ETL任务的编译、ETL任务的执行。DataStage Manager主要用来管理项目资源[4]。DataStage Director主要有以下两个功能:监测ETL任务的运行状态、设置何时运行ETL任务。
2 基于数据处理的ETL框架的设计
现今企业每天都会产生大量的数据,这些数据绝大部分都会存储于日志文件中,而我们的ETL框架的功能就是需要将这些日志文件进行数据抽取、再对抽取出来的数据进行处理和转换、最终导入到为上层应用服务的DB中。hadoop分布式集群,其提供了hdfs文件系统可以为ETL工具提供技术支持。Hive是基于hadoop的一个数据仓库管理技术,可以方便我们对HDFS上的文件进行转换处理操作。因此,文中提供的ETL框架的运行环境为:hadoop、hive(数据仓库管理工具)、mysql(目标数据库)、python(主语言,还需要用到少量的shell脚本)。ETL的整体架构[5],如图2所示。
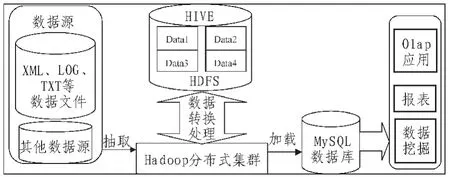
图2 ETL架构图Fig.2 ETL architecture diagram
由ETL的整体框架可以看出ETL操作[6]主要是在数据从底层数据源到上层应用数据库过程中进行。为了能更好地完成这些操作我们需要为这些操作设计良好的任务语法,使我们编写的数据任务脚本可以高效地处理在HDFS上的文件,还能使开发人员从繁重的代码中解脱出来,将重心转移到任务的逻辑上面;与此同时,还要为这些语法,编写相应的解析程序,支撑本框架的语法体系;最后,要为任务处理过程中的一些常用操作提供公共工具接口,以方便全局调用。
2.1任务语法设计
任务语法是指我们在用本文提供的框架开发数据任务时,如何才能清晰地区分E、T、L 3个步骤;在每一步的配置文件中我们又该以什么样的格式编写,才能被本文设计的框架识别。设计任务语法,不仅可以使我们的任务逻辑清晰,而且还有利于团队开发,极大的提高了开发效率。
由于框架的主语言是python,并且python对.yaml这种配置文件有很好的解析技术支持,所以本框架的任务配置文件选择用.yaml文件。按照ETL任务的一般处理过——程数据抽取、转换和加载(Extract、Transform、Load),因此我们可以将每个ETL任务都设计成E、T、L 3个子任务。每个任务的配置信息写在相应目录下的task.yaml中,每个子任务目录下还可以有一些其他的脚本,具体任务文件的编写和脚本的相关规则将在下文做详细介绍。
ETL(extract,transform,load)是在建设数据仓库过程中对一份数据的整个处理流程,大致过程为把数据从源系统抽取(E)出来,经过一系列的处理(T),然后加载到目标库中(L)。下面是一个任务的配置文件task.yaml的大致框架:
parent:[parent_task_name]#父任务名称,用来继承
task_name:[task_name]#任务名称
[phase_name]:#执行的阶段
-step:[plugin_name].[module_name]#执行中用到的插件配置
[attr_name]:[attr_value]
-step:[plugin_name].[module_name]
[phase_name]:
-step:
下面对配置项进行一些解释:parent:父任务名称,无特殊需求,统一配置为EtlTask。task_name:任务名称,由开发者自行指定,保证不会与其他现在任务名称重复即可。phase_name:阶段名称,对应于EtlTask中target中的定义,比如前面的EtlTask定义了以下阶段extract,transform,load分别对应于ETL 3个阶段。这些阶段(phase)只是起了一个标识作用,让配置文件内容看起来更清晰。真正的操作是由phase下的一系列的步骤(step)决定的。step:步骤名称,指定这一步进行什么操作,例如transfer.move_data,则代表指定了执行transfer插件中的move_date模块。这些插件都用python语言在框架中编写。
2.2配置文件解析
配置文件解析部分的功能主要是负责将任务规则设计中产生的配置文件中出现的一些标签和插件的引用与框架的python脚本相关联。
2.2.1插件
本框架中定义的插件主要分为transfer类、file类、script 类3大类插件。
transfer插件主要定义了一些数据传输的模块,具体的模块有:从ftp服务器上将数据日志文件下载到本地、从本地到HIVE、从本地到MYSQL数据库。
file插件主要定义了一些数据文件处理的模块,具体模块有:将文件增加一列常量数据、检查文件是否为空、替换文件中的特殊字符。
script插件主要定义了一些task.yaml文件中要调用的脚本文件的模块,具体模块有:script.shell(调用 shell脚本)、script.hive(调用hiveQL脚本)、script.sql(调用SQL脚本)。
2.2.2linux命令
本框架中有runtask、install_task两大命令。
runtask-d数据日期。例如:runtask-d 20110101;-d,--date=YYYYmmdd或者YYYYmmddHHMM。表示执行2011年1月1号的任务。
Install_task执行任务名称。例如:install_task data_time_info。表示安装任务data_time_info。会将该任务的所需要的一些文件、数据信息加载到缓存。
2.3主要功能
本框架主要的功能有以下几方面:初始化功能:清除db中数据和清除已存在文件;下载功能:下载上游数据文件,校验MD5;文件规则检查功能:检验下载的文件是否符合设定的规则;其他基础db功能:同db相关的操作,如查询任务,查询下载列表等。
2.3.1初始化功能
该模块主要是对数据和文件进行清理,比如需要导入2011-11-01的数据,需要先把这天的数据删除掉,避免插入重复的数据;同时需要建立当天数据的文件夹同时如果是修复数据的话会把之前下载过的这天的文件进行删除然后再进行下载。具体流程,如图3所示。

图3 初始化模块流程图Fig.3 Initialization module flow chart
由上图可以看出在执行脚本时不会对公共文件进行删除操作,避免出现公共文件多次下载影响下载效率。
2.3.2下载功能
该模块主要是进行数据文件的下载,其中分为对ftp协议和http协议的下载,下载文件的同时判断是否存在MD5文件并进行校验;对下载失败的文件提供重试功能。具体流程,如图4所示。
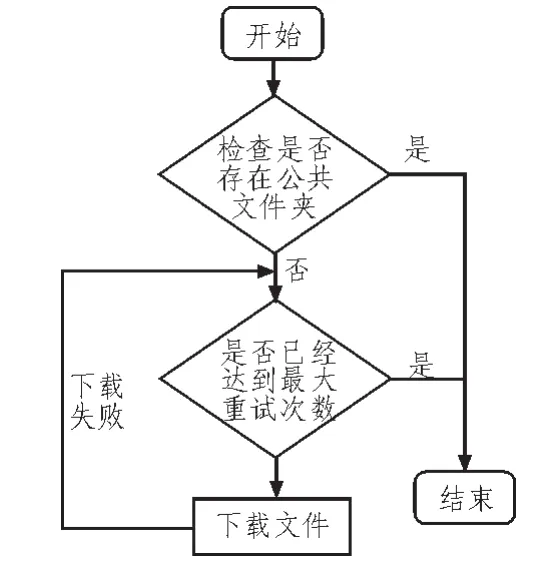
图4 下载模块流程图Fig.4 Download the module flow chart
2.3.3文件规则检查功能
该模块主要是对下载的文件通过设定的规则进行校验,检查文件下载的内容是否正确。功能使用awk命令实现。
2.3.4db功能
该模块内容主要是同db之间的操作,其中包含查询任务相关内容,下载文件相关内容等。包括函数:Update(执行指定的 sql)、Gettask(通过任务 id查询任务相关信息)、Getdownload(通过任务名称查询任务对应的需要下载的文件相关内容)。
2.3.5调度功能
该模块是整个框架执行的主体调度程序,实现的内容是自动地按照顺序计划执行任务,从而使所有的数据任务严格按照ETL流程执行。ETL流程即:通过任务名称查询出任务和下载文件相关信息->下载文件->校验MD5文件->导入到HIVE数据仓库中(E)->执行业务脚本(T)->把转化好的数据load入库(L)->删除临时文件。
3 结束语
在数据仓库中,ETL有两个特点,一是数据同步,它不是一次性倒完数据就拉到,它是经常性的活动,按照固定周期运行的,甚至现在还有人提出了实时ETL的概念。二是数据量,一般都是巨大的,值得你将数据流动的过程拆分成E、T 和L。将数据任务按照E、T和L 3个部分层次化划分,可以使用户更好的把握数据的转换过程。文中先通过对ETL工具——Datastage的优缺点、整体架构及工作原理做了细致地分析。随后提出了设计一款ETL框架的基本思路和解决方案,该框架通过使用HIVE作为数据集成的中转工具,可以提高文件的操作效率。该框架设计时考虑到了ETL的两个特点,使该框架有以下特点:
1)使用HIVE作为数据集成的中转工具,可以提高文件的操作效率(基于hadoop分布式集群)。
2)将数据任务按照E、T和L3个部分层次化划分,可以使用户更好的把握数据的转换过程。
3)使用配置文件的方式创建任务,可以大大加快开发人员的数据处理效率。
[1]PVassiliadis,ASimitsis,PGeorgantas,MTerrovitis SSkiadopoulos.Ageneric and customizable framework for the design of ETL scenarios[J].Information Systems Journa,200530(7): 492-525.
[2]PVassiliadis,etal.ARKTOS:to wards the modeling,design,control and execution of ETL processes[J].Information Systems,2001(26):537-561.
[3]陈弦,陈松乔.基于数据仓库的通用ETL工具的设计与实现[J].计算机应用研究,2004(8):214-216.
[4]尤玉林,张宪民.一种可靠的数据仓库中ETL策略与架构设计[J].计算机工程与应用,2006(3):172-175.
[5]周茂伟,邓苏,黄宏斌.基于元数据的ETL工具设计与实现[J].科学技术与工程,2006,6(21):3503-3507.
[6]郑洪源,周良.基于CWM的标准ETL的设计与实现[J].吉林大学学报(信息科学版),2006,1(24):50-55.
Research and design of ETL framework based on data processing
SHEN Qi,CHEN Bo
(Beijing University of Technology,Beijing 100124,China)
According to the traditional extraction,conversion,loading(ETL)architecture forprocess control deficiencies in data processing and data product development efficiency,the article presents a data processing based on ETL.The characteristics of ETL working principle and process analysis of the mainstream ETL tool--Datastage,design of ETL metadata description module,ETL module,configuration task description analysis module and data task scheduling module etc.Using the framework of data processing tasks,development to the configuration file of the way,so that the work efficiency has been greatlyimproved.ThedesignideaofthedevelopmentofalargedataprocessingbasedonETL tools,in data processing(E,T,L)of the control has been improved,but also can make the data developer freed from a large number of repetitive operations,will focus more on the aspects of the data logic processing.
data processing;data extraction;data conversion;data loading;ETL framework
TN709
A
1674-6236(2016)02-0025-03
2015-03-09稿件编号:201503111
沈 琦(1964—),女,北京人,博士,副教授。研究方向:计算机网络与应用。
