评Lee的油气资源量发现过程模型及预测模型的建立
2016-08-31陈元千
陈元千,唐 玮
评Lee的油气资源量发现过程模型及预测模型的建立
陈元千,唐玮
(中国石油勘探开发研究院,北京100083)
Lee的专著《Statistical Methods for Estimating Petroleum Resources》第4章和第7章的发现过程模型是评价油气资源量的重要理论基础。Lee利用对数正态(Lognormal)分布、威布尔(Weibull)分布、伽马(Gamma)分布、逻辑斯谛(Logistic)分布和帕雷托(Pareto)分布的概率密度函数来描述一个含油气盆地单峰周期资源量的发现过程,但Lee引用的5种概率密度函数,除对数正态分布正确外,其余4种都是错误的,因而,必然影响到发现过程模型的正确性。此外,由于概率密度函数是0-1的无因次量,必须进行量纲的变换,才能建立可靠的预测模型,但Lee在专著中没有提到关于概率密度函数的量纲变换。本文以对比的方式,指出了Lee引用的概率密度分布函数存在的错误,并经过量纲变换和推导,建立了评价油气资源量的预测模型。
油气资源量;发现过程模型;预测模型;概率密度函数
P.J.Lee(李沛然,1934—1999)是一位加拿大籍华裔的地球化学家。1979—1996年在加拿大地质调查局沉积与石油地质研究所工作,从事含油气盆地与区带的资源评价研究,1996年转入中国台湾成功大学任教,1999年11月离世。在他生前留下了大量的科研和教学方面的手稿,经朋友、同事们的整理和编辑,于2008年出版了专著《Statistical Methods for Estimating Petroleum Resources》[1],后经李小地教授等人翻译,于2011年出版了中文版专著《油气资源评价的统计方法》[2]。在专著中的发现过程模型是Kaudman教授于20世纪70—80年代在研究含油气盆地或区带的资源量发现过程时首先提出来的。Lee在专著的第4章和第7章中引用的概率密度函数,是油气田发现过程模型的理论基础。但令人遗憾的是,Lee引用的5种概率密度函数,除对数正态分布正确外,其余4种均是错误的。此外,概率密度函数是0-1的无因次量,必须进行量纲的变换才可用于建立有效的预测模型。Lee在其专著中却忽略了这一重要的技术要求。本文指出了Lee的发现过程模型所引用的概率密度函数存在的错误,并经过量纲变换和推导,建立了预测一个含油气盆地或区带资源量的不同模型。
1 对Lee发现过程模型基础的质疑
Lee的发现过程模型,就是在专著第4章和第7章中引用的对数正态(Lognormal)分布、威布尔(Weibull)分布、伽马(Gamma)分布、逻辑斯谛(Logistic)分布和帕雷托(Pareto)分布的概率密度函数。应当指出的是,这些概率密度函数,除对数正态分布的正确外,其余4种都是错误的。
(1)Lee引用的对数正态分布概率密度函数[1-2]为

在这里,Lee引用的对数正态分布概率密度函数(1)式是正确的。应当指出,正态分布的特点在于,当变量趋近于无穷大时,单峰随机变量的乘积是正态分布,2个或2个以上分布的乘积也是正态分布。因此,对数正态分布适用于多参数相乘计算地质储量的容积法。
(2)Lee引用的威布尔分布的概率密度函数[1-2]为
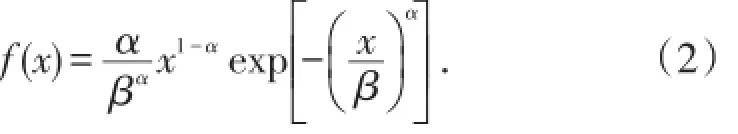
应当指出,Lee引用的(2)式是不正确的,正确的表达式[3-5]为

(3)Lee引用的伽马(Gamma)分布的概率密度函数[1-2]为
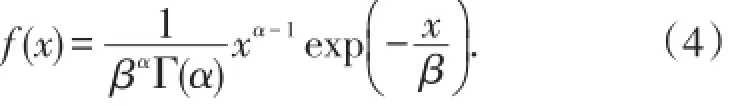
应当指出,Lee引用的(4)式是不正确的,正确的表达式[5-6]为

(4)Lee在专著的第7章[1-2]中以回归法命名的逻辑斯谛分布的概率密度函数为

应当指出,Lee引用的(6)式是不正确的,正确的表达式[7-8]应为

(5)在文献[1]和文献[2]中,Lee直接给出的所谓帕雷托分布概率密度函数为

应当指出,帕雷托分布是一个有因次量的确定性分布,完全不同于上述4种无因次量的概率分布。帕雷托采用一个负指数幂函数表示按储量规模排序的油气资源评价方法,详见本文的第3部分。
2 资源量预测模型的建立及求解方法
上述5种概率密度函数的概率f(x)是0-1的无因次量。而年度发现的资源量为有因次量。因此,必须进行量纲的变换,才能建立可靠的预测模型。若设一个含油气盆地t年度的油气发现量为N(t),预期最终可能发现的总资源量为NT,那么,t年度发现资源量的概率为

2.1对数正态分布的预测模型
将(1)式代入(9)式得,对数正态分布的预测模型[9]为



为了利用线性迭代试差法,确定模型常数a,b和c的数值,以及由(12)式和(13)式确定分布参数α和β的数值,将(10)式取常用对数
logtQ(t)=A-B(logt-b)2,(14)
式中


根据不同t时间的实际发现资源量Q(t),给定不同的b值,由(14)式进行线性迭代试差,并以最佳直线关系的回归求得A和B的数值后,再由(15)式和(16)式分别求得α和β的数值,最后由(13)式代入(11)式,可得确定总资源量的关系式

式中式中



为了进行线性迭代试差法求解,将(18)式改写并取常用对数得式中

给定不同的b值,由(22)式的线性迭代试差法,求得最佳直线的A和B的数值后,再由(23)式和(24)式分别求得a和c的数值。然后,由下式确定总资源量:

2.2威布尔分布的预测模型
由(3)式代入(9)式得,威布尔分布的预测模型[10]为
2.3伽马分布的预测模型
由(5)式代入(9)式得,伽马分布的预测模型[11]为

式中

为了进行线性迭代试差,将(26)式改写后再取常用对数为

式中

给不同的b值,由(30)式线性迭代试差法,求得最佳直线关系后,经线性回归求得A和B的数值,进而由(31)式和(32)式确定a和c的数值,然后由下式确定总资源量:

2.4逻辑斯谛分布的预测模型
由(7)式代入(9)式得,逻辑斯谛分布的预测模型[7]为

由(34)式对时间t求导数得

由(35)式除以(34)式得

将(36)式等号右端的分子,同时加和减一项bN(t)得,(36)式改写为

式中

根据由(37)式线性回归求得直线的截距A和斜率B的数值后,将(38)式代入(39)式,得总资源量为:

3 帕雷托(Pareto)分布的性质及预测模型的建立
帕雷托分布是一个由已发现油气田储量的规模排序,预测含油气盆地或区带的总资源量和未发现资源量的方法。对于一个含油气盆地或区带,按油气田储量规模,由大到小排序,相应的油气田按x=1,2,3…m…n…的正整数由小到大编号。因此,帕雷托分布是一个连续性分布的函数。由文献[12]和文献[13]可看出,帕雷托1897年提出的分布,是一个有因次量的确定性分布,并采用了如下的负指数幂函数表示

应当说明,美国地质调查局(USGS)的研究单位曾用(41)式对美国各州含油气盆地的资源量进行评价[14-16]。然而,由(41)式看出,将油气田按储量大小的编号作为函数的纵轴,在实际应用时很不方便。因此,文献[12]设A=a1b和B=1/b,将(41)式改为下式

在储量规模排序中,任取m和n两个序点,由(42)式可写出

由(43)式除以(44)式得:
将(45)式取常用对数得:

我国许多油气资源评价工作者,将(45)式和(46)式误称为帕雷托定律,这是一个误解,而在Lee的专著中将(45)式称为齐波夫定律[1-2]也是不正确的。
当储量编号x=1时,由(42)式可得油气田储量最大值为

将(47)式代入(42)式,即得中国第3轮全国油气资源量评价时广泛应用的公式

应当指出,这种把N(1)作为资源量预测的基础是不可靠的。由(42)式可看出,当i=0时,N(0)=∞(无穷)是不正确的。因为,作为一个连续性幂函数关系,当x=0时,N(0)不应当等于∞,而应当是一个实数,即模型常数A.
将(42)式等号两端取常用对数得
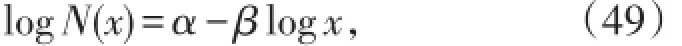
式中

由(49)式可以看出,log N(x)与log x之间应为直线下降关系。然而,在双对数坐标纸上的实际数据点却是一条明显的曲线。为了使用帕雷托分布,建立预测盆地或区带油气资源量的模型,文献[12]对(42)式进行了如下的修正

由(52)式看出,当x=0时,N(0)=A,这就符合了连续性负指数幂函数的要求。根据已发现油气田储量规模的排序,为了确定模型常数A和B的数值,将(52)式等号两端取常用对数得

式中

由(53)式看出,logN(x)与log(x+1)之间为直线关系。根据实际数据,利用(53)式的线性回归求得λ和ω的数值后,再由(54)式和(55)式分别确定A和B的数值。一个含油气盆地或区带的的总资源量(总地质储量)由下式确定为

将(52)式代入(56)式经积分后得,预测含油气盆地或区带的总资源量的关系式为

由(57)式看出,预测一个含油气盆地或区带的总资源量,除与A和B的数值有关外,还与经济极限储量的编号xEL的数值有关。当由经济评价确定了经济极限储量NEL后,可由下式确定与其相应的储量编号

未(待)发现的油气田资源量(地质储量),由下式确定

采用文献[12]的实例,我国金湖凹陷的A=1 327,B=0.926 6和xEL=175,将其代入(57)式可得金湖凹陷的总资源量(总地质储量)为
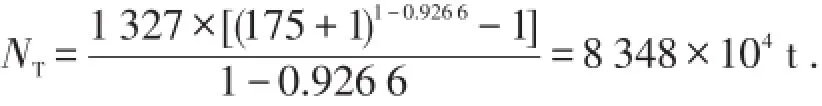
金湖凹陷已累计探明的地质储量为6 764×104t,因此,未发现的地质储量约为1 584×104t.
4 结语
P.J.Lee(李沛然)于2008年出版的《Statistical Methods for Estimating Petroleum Resources》专著,在北美和我国受到业内人士的高度重视。在专著的第4章和第7章中,Lee提出的发现过程模型可以说是专著的核心部分。然而,作为发现过程模型理论基础的概率密度函数,除对数正态分布正确外,其余的威布尔分布、伽马分布、逻辑斯谛分布和帕雷托分布都是错误的。因此,如果应用这些错误的概率密度函数,作为发现过程模型的理论基础,进行油气资源量的评价,肯定得不到正确的结果。当然,即使这些概率密度函数都是正确的,如果不进行量纲的变换,也建立不了可靠的预测模型。本文以对比的方式指出了在Lee的发现过程模型中,所引用的威布尔分布、伽马分布、逻辑斯谛分布和帕雷托分布的错误,并经过量纲变换和推导,建立了预测年度发现资源量和总资源量的不同实用模型。同时,本文对于在中国第3轮全国油气资源评价中,广泛应用的储量规模排序法(即帕雷托分布)存在的问题,以及笔者进行的修正原因作出了说明。最后,应当指出,在文献[17]和文献[18]中提出的多峰预测模型,以及在文献[19]、文献[20]和文献[21]中提出的典型曲线拟合求解法,都可以用于油气资源量的预测。最后,应当强调指出,文献[22]提出的应用于油气资源量评价的SP(Shifted Pareto)分布、STP(Shifted Truncated Pareto)分布、LDP(Lognormal Developed Process)分布,以及由文献[23]提出的广义帕雷托分布,均因未经过严格推导,而存在相当大的不确定性和不可靠性,值得大家关注,有待进一步探讨。
符号注释
A,B——不同概率密度函数的直线截距和斜率;
a,b,c——不同概率密度函数的模型常数;
aL——Lee引用的帕雷托分布的储量上限,104m3;
bL——Lee引用的帕雷托分布的储量下限,104m3;
f(x)——x变量的概率;
f(t)——t时间发现资源量的概率;
Ndis——已发现的资源量(或地质储量),104m3;
Nundis——未发现的资源量(或地质储量),104m3;
NT——总资源量(或总地质储量),104m3;
N(x)——编号x油气田的地质储量,104m3;
N(m)——编号为m油气田的地质储量,104m3;
N(n)——编号为n油气田的地质储量,104m3;
N(t)——t年度发现的资源量(或地质储量),104m3/a;
N(1)——在一个含油气区带内x=1油气田的最大地质储量,104m3;
Q(t)——t年度发现的资源量(或地质储量),104m3/a;
t——时间变量,a;
x——概率分布变量;
xEL——帕雷托分布的经济极限储量编号;
xL——Lee引用的帕雷托分布的储量规模,104m3;
Γ(α)——伽马函数值;
Γ(b+1)——b+1的伽马函数值;
α,β——控制不同分布形态的分布参数;
θ——帕雷托分布的形状因子(Shape factor);
λ,ω——帕雷托分布的直线截距和斜率。
[1]LEE P J.Statistical methods for estimating petroleum resources[M]. New York:Oxford University Press,2008:61-63;171-172.
[2]LEE P J.油气资源评价的统计方法[M].李小地,赵,梁英波,译.北京:石油工业出版社,2011:42-43;131-132. LEE P J.Statistical methods for estimating petroleum resources[M]. Translated by LI Xiaodi,ZHAO Zhe,LIANG Yingbo.Beijing:Petro-leum Industry Press,2011:42-43;131-132.
[3]PEARSON C E.Handbook of applied mathematics(2nd edition)[M]. NewYork:VanNostrandReinholdCompany,1983:1225-1229.
[4]BRONSHTEIN I N,SEMENDYAYEV K A.Handbook of mathematics[M].New York:Van Nostrand Reinhold Company,1985:1 225-1 229.
[5]《数学手册》编写组.数学手册[M].北京:人民教育出版社,1979:794-797. "Handbook of mathematics"writing group.Handbook of mathematics[M].Beijing:People's Education Press,1979:794-797.
[6]贺才兴.大学数学手册(第二版)[M].上海:上海交通大学出版社,2006:405-408. HE Caixing.Handbook of college mathematics(2nd edition)[M]. Shanghai:Shanghai Jiao Tong University Press,2006:405-408.
[7]陈元千,胡建国,张栋杰.Logistic模型的推导及自回归方法[J].新疆石油地质,1996,17(2):150-155. CHEN Yuanqian,HU Jianguo,ZHANG Dongjie.Derivation of logistic model and its self-regression method[J].Xinjiang Petroleum Geology,1996,17(2):150-155.
[8]AL-JARRI A S,STARTZMAN R A.Worldwide petroleum-liquid supply and demand[J].Journal of Petroleum Technology,1997,49(12):1 329-1 338.
[9]陈元千,袁自学.预测油气田产量和可采储量的新模型[J].石油学报,1997,18(2):84-88. CHEN Yuanqian,YUAN Zixue.A new model for predicting production and reserves of oil and gas fields[J].Acta Petrolei Sinica,1997,18(2):84-88.
[10]陈元千,胡建国.预测油气田产量和储量的Weibull模型[J].新疆石油地质,1995,16(3):250-255. CHEN Yuanqian,HU Jianguo.Weibull model for predicting output and reserve in an oil and gas field[J].Xinjiang Petroleum Geology,1995,16(3):250-255.
[11]陈元千,胡建国.对翁氏模型建立的回顾及新的推导[J].中国海上油气,1996,10(5):317-324. CHEN Yuanqian,HU Jianguo.Review and derivation of Weng model[J].China Offshore Oil and Gas,1996,10(5):317-324.
[12]陈元千.预测油气资源Pareto模型的建立、修正与应用——兼评我国现行的油田储量规模排序法[J].中国石油勘探,2008,13(4):43-49. CHEN Yuanqian.Establishment,modification,and application of Pareto model for forecasting oil and gas resources—review of existing rank order method of accumulation size in oilfields[J].China Petroleum Exploration,2008,13(4):43-49.
[13]BARTON C C,LA POINTE P R.Fractals in petroleum geology and earth processes[M].New York:Plenum Press,1995:59-72.
[14]MANDELBROT B B.The statistics of natural resources and the law of Pareto[M]//BARTON C C,LA POINTE P R.Fractals in petroleum geology and earth processes.New York:Plenum Press,1995:1-12.
[15]ROOT D H,ATTANASI E D.Small field in the national oil and gas assessment[J].AAPG Bulletin,1993,77(3):485-490.
[16]BAKER B A,GEHMAN H M,JAMES W R,et al.Geologic field number and size assessments of oil and gas plays[J].AAPG Bulletin,1984,68(4):426-437.
[17]陈元千,郝明强.多峰预测模型的建立与应用[J].新疆石油地质,2013,34(3):296-299. CHEN Yuanqian,HAO Mingqiang.Establishment and application of the multi-peak forecasting model[J].Xinjiang Petroleum Geology,2013,34(3):296-299.
[18]陈元千,郝明强.HCZ模型在多峰预测中的应用[J].石油学报,2013,34(4):747-752. CHEN Yuanqian,HAO Mingqiang.Application of HCZ model to predict multiple production peaks[J].Acta Petrolei Sinica,2013,34(4):747-752.
[19]陈元千,邹存友.预测油田产量和可采储量模型的典型曲线及其应用[J].石油学报,2014,35(4):749-753. CHEN Yuanqian,ZOU Cunyou.Model's typical curve and its application for forecasting production and recoverable reserves of fields[J].Acta Petrolei Sinica,2014,35(4):749-753.
[20]陈元千,邹存友,于立君.累积增长预测模型的典型曲线及应用[J].中国海上油气,2014,26(1):54-57. CHEN Yuanqian,ZOU Cunyou,YU Lijun.A type curve of the cumulative growth forecast models and its application[J].China Offshore Oil and Gas,2014,26(1):54-57.
[21]陈元千,李剑.威布尔模型的典型曲线及应用[J].油气地质与采收率,2014,21(1):33-39. CHEN Yuanqian,LI Jian.Application and type curves of Webull's model[J].Petroleum Geology and Recovery Efficiency,2014,21(1):33-39.
[22]郭秋麟,闫伟,高日丽,等.3种重要的油气资源评价方法及应用对比[J].中国石油勘探,2014,10(1):50-59. Guo Qiulin,Yan Wei,Gao Rili,et al.Application and comparison of three petroleum resource assessment methods[J].China Petroleum Exploration,2014,10(1):50-59.
[23]金之钧.五种基本油气藏规模概率分布模型比较研究及其意义[J].石油学报,1995,16(3):6-13. JIN Zhijun.A comparison study of five basic oil and gas pool size probability distribution models and its significance[J].Acta Petrolei Sinica,1995,16(3):6-13.
(编辑杨新玲)
Review of Lee's Discovery Process Model for Petroleum Resources and Establishment of Prediction Model
CHEN Yuanqian,TANG Wei
(Research Institute of Petroleum Exploration and Development,PetroChina,Beijing 100083,China)
The discovery process model in Chapters 4 and 7 of Lee's Statistical Methods for Estimating Petroleum Resources is the important theoretical foundation to evaluate oil and gas resources.Lee uses probability density functions of Lognormal distribution,Weibull distribution,Gamma distribution,Logistic distribution and Pareto distribution to describe the discovery process of unimodal cyclic resources in a petroliferous basin.But,it is found that except for Lognormal distribution,other 4 distributions are all wrong,which will inevitably influence the accuracy of the model.Additionally,dimension transformation must be performed to establish a reliable prediction model because the probability density function is a dimensionless quantity of 0~1.But Lee never mentions the dimension transformation of the probability density functions in his monograph.Based on comparison,the authors point out the mistakes of probability density functions introduced by Lee,and establishes a prediction model to evaluate petroleum resources through dimension transformation and derivation.
petroleum resource;discovery process model;prediction model;probability density function
TE319
A
1001-3873(2016)04-0442-05
10.7657/XJPG20160410
2016-05-15
陈元千(1933-),男,河南兰考人,教授级高级工程师,油气田开发,(Tel)15910321810(E-mail)twei@petrochina.com.cn
