基于改进Tri-training算法的中文问句分类
2016-08-25杨思春安徽工业大学计算机科学与技术学院安徽马鞍山243032
王 雷,杨思春(安徽工业大学计算机科学与技术学院,安徽马鞍山243032)
基于改进Tri-training算法的中文问句分类
王 雷,杨思春
(安徽工业大学计算机科学与技术学院,安徽马鞍山243032)
原始Tri-training算法对有标记的数据集通过随机采样方法,形成3个训练集去训练3个分类器。但是由这种随机采样形成的训练集中,可能出现有标记数据集中的不同类别数据数量相差较大,从而导致训练集中样本类别不平衡问题,影响分类器的分类正确率。本文通过分类采样对Tri-training算法的随机采样方法进行改进,根据该改进的Tri-training算法,建立分类模型,并利用其对哈工大中文问句集和本文扩展问句集进行分类实验。结果表明,本文算法有良好的适应性,且分类正确率明显提高;适当增大训练集和未标记样本数据可以增强分类器的泛化能力,从而使分类正确率提高。
Tri-training算法;随机采样;问句分类
问句分类作为问答系统中重要的组成部分,直接影响问答系统的性能。目前,问句分类的方法主要有两大类[1-2]:基于人工规则的方法;基于机器学习的方法。机器学习方法包括监督学习、无监督学习和半监督学习。目前基于监督学习的问句分类方法占据主流。在英文问句分类研究方面,Li等[3]采用语义词典WordNet问题分类取得了良好的效果;Le等[4]提出基于细粒度的POS标注特征提取算法提高了问句的分类正确率。在中文问句分类研究方面,牛彦清等[5]对中文问句分类的特征进行了研究,Liu等[6]提出一种结合句法依存关系和词性问题性质的核函数方法,在中文问句分类中取得了良好的效果。
监督学习的方法主要利用已标记样本,忽略未标记样本对于问句分类的意义,分类正确率难以提升,且分类灵活性较低。半监督学习是一种综合利用已标记样本和未标记样本进行学习的方法,能获得较好的学习泛化能力和学习效果。目前该类方法开始应用于中文问句分类中,如Yu等[7]利用半监督学习中的Co-training算法将中文问句进行分类,赵全[8]利用Co-training算法将云南旅游领域的中文问句进行分类。在半监督学习的诸多分类算法中Tri-training算法[9]在自然语言处理领域有良好的分类效果。其中,张雁等[10]对基于Tri-training的半监督分类算法进行了研究;高嘉伟等[11]提出一种基于Tri-training的半监督多标记学习文档分类算法,在文档分类中取得了良好的效果。因此本文将Tri-training算法应用于中文问句分类。
原始Tri-training算法从有标记样本集中通过随机采样形成3个训练集。这种方法形成的训练集中可能不会涵盖有标记样本集中的所有类别,导致训练集中有标记样本数量不平衡。针对此问题,本文通过对Tri-training算法[12]的理论分析,和受于重重等[13]提出的DSCC(semi-supervised collaboration classification algorithm with enhanced difference)算法启发,提出一种基于类别分类采样的Tri-training算法。
1 Tri-training分类算法的改进
1.1算法描述
改进Tri-training算法初始采样形成3个有标记的样本集,先提取出每一类,再从提取出的每类样本中随机采样,其基本流程如图1所示。

图1 改进的Tri-training算法流程Fig.1 Flow chart of improved Tri-training algorithm
该算法中基于标记类别的随机采样方法首先统计出标记样本集中类别的数量,记为H。再分别统计出每一类中标记样本的数量。然后利用可重复随机采样函数Bootstrap分别从每个类别中随机采样标记样本,从而形成3个有标记的样本集。改进Tri-training算法的详细步骤如下。
输入:有标记样本集L,未标记样本集U,测试集T,分类器H。输出:测试集T通过分类模型分类之后的分类精度。
1)根据L训练分类器
2)基于类别分类采样方法将L分为3份,形成3个有标记样本集
3)用Li(i=1,2,3)分别去训练3个分类器Hi(i=1,2,3),即Hi(i=1,2,3)←Learn(Li)。
4)设定分类器初始分类错误率ei←0.5。
5)对未标记样本集进行预测分类。对于一个分类器而言,如果另外两个分类器对未标记样本预测分类。结果一致,即将此样本加入到该分类器的有标记样本集中,并且对该分类器进行迭代训练。
6)重复3)~5)步骤,直至分类错误率ei不再发生变化。即分类器迭代训练结束。
7)用迭代训练好的分类器将测试集中样本分类,测算分类器的分类正确率。
8)算法结束。
1.2算法分析
在原始Tri-training算法的模型更新过程中,对于样本Lt采用随机采样的方法,可能会因为样本选取不当而使模型在第t轮更新后,并不如t-1轮的模型。并且在初始形成3个有标记样本集的时候,很可能不会涵盖有标记样本集中的所有类别,或者有的样本类别包含的多,有的类别包含的少,导致训练集中有标记样本数量不平衡,从而影响分类器的分类准确率。
基于标记类别的分类采样方法采样时,先将有标记的样本集中的每个类别样本提取出来,再分别从提取出来的每个类别样本中通过随机采样,最终形成3个有标记的样本集。这样就可以保证这3个样本集中的标记样本会涵盖标记样本的所有类别,不会出现有标记样本数量不平衡的情况,进一步增强分类器的泛化能力,避免多个分类器的协同训练退化为单分类器的自训练而失去半监督学习和协同训练的价值和意义的可能,提高分类器的分类正确率。
2 基于改进Tri-training算法的中文问句分类
基于改进Tri-training算法建立半监督分类模型。模型主要包括原始数据导入、数据预处理、协同训练和分类结果输出4个部分。其流程如图2。
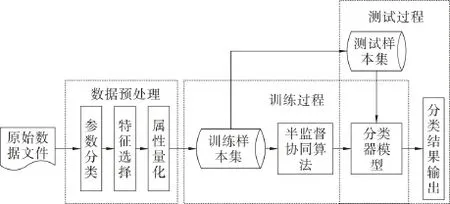
图2 半监督协同分类模型工作流程Fig.2 Flow chart of semi-supervised collaboration classification model
2.1数据预处理
一般来说,中文问句集均不是分类算法中所用分类器所需的数据格式。对于中文来说,中文问句包含词袋、词性、命名实体和依存关系等基本特征。数据预处理部分主要是将中文问句中的基本特征提取出来,并选择合适的基本特征将中文问句中所包含的属性进行量化,形成分类器所需数据格式。本文利用程序实现数据预处理,在建立的中文问句分类模型中,选用中文问句的词袋这一基本特征,旨在验证改进Tri-training算法对于中文问句分类的有效性。对于中文问句中不同的基本特征组合,不再一一验证。
2.2协同训练
协同训练部分利用数据预处理得到的中文问句集,对分类器进行训练、测试的过程。文中在基于类别分类采样的Tri-training算法基础上,运用3个分类器协同训练。
基于类别分类采样方法将有标记样本集中的每一类中文问句提取出来,然后分别对提取出来的每类问句进行随机采样,形成3个有标记的样本集。用形成的3个有标记样本集分别去训练3个分类器,再利用训练得到的3个分类器协同对未标记样本集中的样本进行标记。对于一个分类器而言,如果另外两个分类器对这些未标记样本标记了相同的分类结果,这些样本则被当成是已标记样本加入到该分类器的有标记样本集中参加对该分类器进行迭代训练。对每个分类器而言,均如此的进行迭代训练,直至分类器不再更新,则迭代训练结束。
3 实验结果及分析
3.1实验数据
所用实验数据主体来自哈尔滨工业大学的中文问句集。该问句集分为6大类,共包含6 266个已标记好问句类别的问句。在该问句集的基础上,本文又利用网络资源人工将每类问句数量进行扩展,扩展的总问句数为4 000个。将扩展的中文问句加入到哈尔滨工业大学的中文问句集中,形成新的中文问句集。
3.2实验设置
1)样本集分配
针对哈尔滨工业大学的中文问句集,选用25%的数据作为测试样本集,剩余75%的数据作为训练集,其中,训练样本集中未标记样本的比例依次选用20%,40%,60%,80%。将本文扩展的问句集加入至哈尔滨工业大学的中文问句集中,形成一个新的问句集,再将此问句集按照哈工大中文问句集的样本分配比例进行实验数据分配。
2)分类器选择
本实验选用了3个SVM分类器,旨在验证基于问句类别分类采样方法对问句分类的影响。对于其他不同分类器的组合用法对分类实验的效果影响,李心磊等[14]已经通过实验验证。
3)评价指标
对分类结果进行测试时,采用分类正确率(A)作为评价标准,其定义如下

3.3问句分类实验及结果分析
1)哈尔滨工业大学的中文问句集实验
采用图2分类模型,利用哈尔滨工业大学的中文问句集进行实验。分别得出单个SVM分类器的自训练、原始的Tri-training算法以及改进的Tri-training算法在此问句集上的分类正确率。表1给出了在4种不同的未标记比率下,上述3种方法的分类正确率。其中:T1为单个SVM分类器的自训练方法;T2为原始Tritraining算法;T3为改进Tri-training算法。
2)扩展的新问句集实验
表2为在扩展问句集上,分别采用单个SVM分类器自训练、原始Tri-training算法以及改进Tri-training算法在4种不同未标记比率下的分类正确率。

表1 不同未标记比率下各种分类方法在哈尔滨工业大学问句集上的分类正确率(%)Tab.1 Classification accuracy of various classification methods with different unlabeled ratios on HIT question set(%)

表2 不同未标记比率下各种分类方法在扩展问句集上的分类正确率(%)Tab.2 Classification accuracy of various classification methods with different unlabeled ratios on expanded set(%)
从表1中的试验结果可以看出:在原问句集上,改进Tri-training算法和原始Tri-training算法的分类正确率均高于单SVM分类器自训练方法的分类正确率,分别高出4.16%和2.78%;且改进Tri-training算法的分类正确率更高于原始Tri-training算法的分类正确率,高出其1.38%。表2表明,在扩展问句集的基础上,改进Tri-training算法的分类正确率高出原始Tri-training算法的分类正确率1.70%。比较表1,2中的实验数据可以看出,适当增大训练集和未标记样本数据可以提高分类器的泛化能力,从而使分类正确率提高。
综上所述,本文提出的基于类别分类抽样的Tri-training算法相对于原始Tri-training算法和单个SVM分类器自训练的分类方法而言,在处理中文问句分类问题上,性能提高,说明本文算法在中文问句分类问题上的适用性。
4 结 语
本文的主要工作是根据在前期研究过程中提出的基于类别分类采样的Tri-training算法,建立了半监督协同分类模型,并利用哈尔滨工业大学的中文问句集以及人工扩展的问句集进行分类实验。实验结果表明,基于类别分类采样的Tri-training算法较原始Tri-training算法分类正确率,分别提高2.78%和1.70%。
本文算法的分类实验主要是在哈尔滨工业大学的中文问句集基础上展开的,对于更大规模的中文问句集而言,算法是否有效,还有待验证。希望本文的算法能够为其他分类领域的研究者提供参考。
[1]郑实福,刘挺,秦兵,等.中文自动问答系统综述[J].中文信息学报,2002,6(16):46-52.
[2]镇丽华,王小林,杨思春.自动问答系统中问句分类研究综述[J].安徽工业大学学报(自然科学版),2015,32(1):48-66.
[3]LI X,ROTH D.Learning question classifiers:the role of semantic information[J].Natural Language Engineering,2006,12(3):229-249.
[4]LE J,NIU Z D,ZHANG C X.Question classification based on fine-grained pos annotation of nouns and interrogative pronouns[J]. Lecture Notes in Computer Science,2014,8862:680-693.
[5]牛彦清,陈俊杰,段利国,等.中文问句分类特征的研究[J].计算机应用与软件,2012,29(3):108-111.
[6]LIU L,YU Z T,GUO J Y,et al.Chinese question classification based on question property kernel[J].International Journal of Machine Learning and Cybernetics,2013,5(5):713-720.
[7]YU Z T,SU L,LI L N,et al.Question classification based on co-training style semi-supervised learning[J].Pattern Recognition Letters,2010,31(13):1975-1980.
[8]赵全.基于半监督学习的中文问句分类研究[D].昆明:昆明理工大学,2010.
[9]ZHOU Z H,LI M.Tri-training:exploiting unlabeled data using three classifiers[J].IEEE Trans on Knowledge and Data Engineer,2005,17(11):1529-1541.
[10]张雁,吕丹桔,吴保国.基于Tri-training半监督分类算法的研究[J].计算机技术与发展,2013,23(7):77-80.
[11]高嘉伟,梁吉业,刘杨磊,等.一种基于Tri-training的半监督多标记学习文档分类算法[J].中文信息学报,2015,29(1):104-10.
[12]周志华,王珏.机器学习及其应用[M].北京:清华大学出版社,2007.
[13]于重重,商利利,谭励,等.半监督学习在不平衡样本集分类中的应用研究[J].计算机应用研究,2013,30(4):1085-1089.
[14]李心磊,杨思春,彭月娥.Tri-training算法中分类器组合的改进[J].苏州科技学院学报(自然科学版),2014,31(2):52-56.
责任编辑:丁吉海
Chinese Question Classification Based on Improved Tri-trainingAlgorithm
WANG Lei,YANG Sichun
(School of Computer Science and Technology,Anhui University of Technology,Ma'anshan 243032,China)
The originalTri-training algorithm classifies the labeled data by the method of random sampling,forming three training sets for three classifiers.There is an phenomenon that the number of different categories may have huge differences between the exiting labeled data sets in this training sets formed by random sampling three classifiers,which may lead the categories of training sets into imbalance,and influence the accuracy of classifier. By employing a method of classification sampling to replace the random sampling,Tri-training algorithm wasimprovedandaclassificationmodelwasestablished.ClassificationexperimentwereperformedonHITquestion set and expanded question set.The results were compared with those of original Tri-training algorithm on the same data sets,which indicates that the new algorithm has good adaptability,and the accuracy of the algorithm is improved.With the increase of training set and the number of unlabeled samples,the generalization ability and the accuracy of the classifier are improved.
Tri-training algorithm;random sampling;question classification
TP391
Adoi:10.3969/j.issn.1671-7872.2016.02.015
1671-7872(2016)02-0172-05
2015-07-08
安徽省高校自然科学研究重点项目(KJ2011A048,KJ2016A098)
王雷(1990-),男,安徽定远人,硕士生,主要研究方向为自然语言处理。
杨思春(1970-),男,安徽六安人,博士,教授,主要研究方向为自然语言处理、信息检索、粗糙集和概念格。
