车辆通行数据的分布式存储系统浅析
2016-08-04郭旭卫彪江建宇
郭旭+卫彪+江建宇
摘 要 卡口车辆通行数据的分布式存储方法,包括配置计算节点和数据节点服务器,搭建并行计算集群环境;按照需要采集的车辆特征建立表结构,在表结构中选取至少两个特征作为主键,由主键组成一条卡口数据信息;对主键和常用查询字段建立分布式可变索引,再针对车牌号建立分布式检索索引;接入待存储的各个卡口的过车信息数据源;用户以包含索引的字段进行查询,系统在100m/s之内返回相应数据。满足日常业务中卡口系统对海量过车信息数据存储的需求,而且通过对过车信息的数据结构的索引数据结构设计实现了快速查询的功能,大大提高了查询速率,增强了用户体验。
关键词 分布式存储;Hadoop分布式计算框架;海量过车信息
中图分类号 TP31 文献标识码 A 文章编号 1674-6708(2016)166-0074-01
1 系统架构和实现步骤
1.1 系统架构图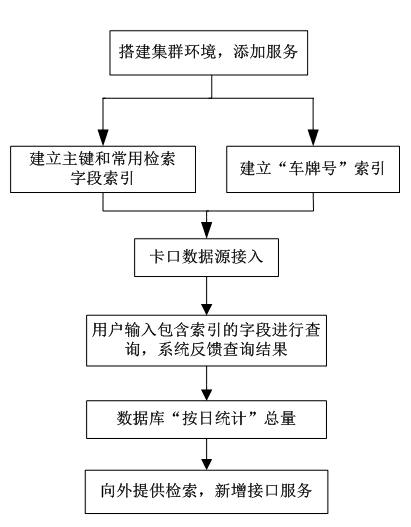
1.2 系统实现步骤
1)配置计算节点和数据节点服务器,搭建并行计算集群环境,安装与集群环境版本匹配的数据访问中间件。
2)按照需要采集的车辆特征建立表结构,在表结构中选取至少2个特征作为主键,由主键组成一条卡口数据信息。
3)对主键和常用查询字段建立分布式可变索引,再针对车牌号建立分布式检索索引。
4)接入待存储的各个卡口的过车信息数据源。
2 系统实现功能综述
2.1 过车数量统计
卡口车辆通行数据的分布式存储方法,其特征在于:设定定时任务,自动统计前一天各个卡口的过车数据总量。
2.2 过车信息格式
卡口车辆通行数据的分布式存储方法,其特征在于:将车牌号、通过时间、卡口编号这3个特征作为主键,由车牌号、通过时间和卡口编号共同组成一条能被用户查询到的卡口数据信息,卡口数据信息格式为:车牌号+通过时间取反+卡口编号。
2.3 模糊查询
卡口车辆通行数据的分布式存储方法,其特征在于:用户输入一个车牌号的其中任意一段连续字符,便可通过分布式索引文件的查询返回相似度最高的前20个车牌号;返回车牌号之后,系统再根据相似度最高的车牌号列表进行全字段的匹配查询;车牌号的分布式索引存储在大数据集群中的分布式文件系统中。
3 具体实施方式
3.1 配置计算节点和数据节点服务器
首先,配置计算节点和数据节点服务器,搭建并行计算集群环境,安装与集群环境版本匹配的数据访问中间件,Apache Phoenix数据访问中间件把传统数据库的SQL语句编译成HBase存储所需要的操作语句,加快了开发效率,降低了开发难度;其次,按照需要采集的车辆特征建立表结构,在表结构中选取至少两个特征作为主键,由主键组成一条卡口数据信息。
3.2 表结构建立
如图1所示,按照业务需求采集的车辆特征建立表结构,采集到字段有“车牌号”“通信时间”“卡口编号”,“车辆颜色”“车辆大小”“通行方向”“数据来源”等存储字段;根据具体业务需求,整理需要持久化的所有数据信息字段,同时选取能够唯一标志一条记录的字段作为主键,这里将车牌号、通过时间、卡口编号这3个特征作为主键,由车牌号、通过时间和卡口编号共同组成一条能被用户查询到的卡口数据信息。
3.3 大数据集群配置
大数据集群运行在Linux内核的服务器,计算节点、备份计算节点和数据节点使用Hadoop分布式计算框架,采用HDFS的分布式文件系统,利用MapReduce算法实现“分而治之”的计算模型,所有数据通过Phoenix中间件存储在HBase数据库内,整个Hadoop框架内的计算转发、监控和策略决定都由ZooKeeper管理。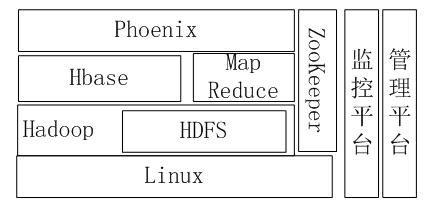
参考文献
[1]Tom Wbite.hadoop权威指南第三版[M].北京:人民教育出版社,2014(7).
[2]涂子沛.大数据应用实例[M].桂林:广西师范大学出版社,2015(6).
