结合汉明距离及语义的文本相似度量方法研究
2016-08-02胡维华
胡维华,鲍 乾,李 柯
(杭州电子科技大学计算机学院,浙江 杭州 310018)
结合汉明距离及语义的文本相似度量方法研究
胡维华,鲍乾,李柯
(杭州电子科技大学计算机学院,浙江 杭州 310018)
摘要:利用VSM模型的TF-IDF算法对文本进行相似度量是文本信息处理领域的常用做法,但是该方法涉及到高维稀疏矩阵的处理,计算效率不高,不利于处理大规模文本,同时该方法忽略词项语义信息对文本的影响.另有一种基于语义的相似度算法可克服前一种方法的语义缺点,但需要知识库的支持,其建立过程的繁杂使此类算法理论多过实践.为此提出一种新的文本相似度计算方法,方法综合TF-IDF算法以及HOWNET的语义信息,并利用汉明距离计算文本相似度,避开对高维稀疏矩阵的直接处理.实验结果表明,与常用方法相比较,处理速度更快、性能更好,适用于大规模文本处理.
关键词:文本相似度;向量空间模型;词频—逆文本频率;语义;汉明距离
0引言
文本相似度计算作为文本信息处理的关键性技术,其准确率直接影响文本信息处理的结果.文本相似度表征文本间的匹配程度,相似度大小与文本相似程度成正比.目前,文本的相似度量方法主要分为基于统计学和基于语义分析两类[1].基于统计学的方法,典型的是向量空间模型(Vector Space Model, VSM),其优点是:以向量表示文本,简化文本中关键词之间的复杂关系,使模型具备可计算性[2].其缺点是:文本表示模型维度高而稀疏以至于难以直接处理,同时忽略了词与词之间的语义关系,并需要大规模语料库支持.基于语义分析的方法,一定程度上与VSM互补,准确率较高,但建立知识库的过程太过繁杂,因此现有的相关研究一般采用收录词比较完备的词典代替知识库.中文文本相似性研究一般利用HOWNET[3],如文献[4]的词汇语义相似性研究,文献[5]的语句相关度研究,文献[6]的文本语义相似性研究等;英文文本相似性研究最常用的是WORDNET[7],如文献[8]的词语消歧研究.本文根据基于统计学和基于语义分析两类方法的优缺点,提出一种新的改进算法(HSim),实验结果表明,与传统空间向量模型方法如TF-IDF相比,新方法得到的结果更符合语义判断,运算速度有大幅度的提高.
1VSM模型与语义相似度
1.1VSM模型
VSM是统计学方法中最为经典的一种文本相似度量方法,其向量特性简化了文本中关键词之间的复杂关系,可计算性高,因此是目前信息检索领域中广泛采用的模型之一.其核心思想是用向量来表示文本,一般用TF-IDF(Term Frequency-Inverse Document Frequency)来进行文本—向量之间的转换.在VSM中,将文本看成是相互独立的词条组(T1,T2,T3,…,Tn),也即向量构成,于是文本间的相似度可以看成是向量之间的相互关系.文本相似度计算的核心是比较两个给定的文本之间的差异,通常用[0,1]之间的1个数值来度量.在该模型中可用余弦距离计算方法来计算两个向量之间的相互关系.即:
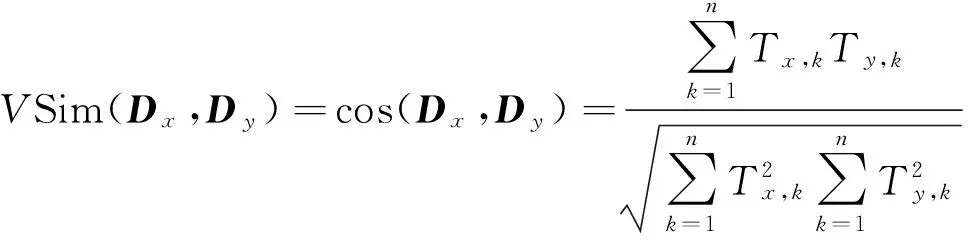
(1)
式中,Dx=(Tx,1,Tx,2,…,Tx,n),Dy=(Ty,1,Ty,2,…,Ty,n).VSim(Dx,Dy)越接近数值1,说明两个给定的文本相似度越高.
在用TF-IDF计算时会涉及到两个概念:TF(词频)和IDF(逆文本频率).
根据这两个概念形成TF-IDF算法思想:fi,j表示词Ti在文档Dj中出现的频率,lg(N/ni)表示文本中所有文档数N与含有词Ti的文档数ni的比值.根据这两个参数得到词Ti的权重信息,称之为Ti的TF-IDF权重,表示为:

(2)
TF-IDF是根据向量空间模型设计的,因此可以有效区分高频词和低区分力词.将TF-IDF权重值代入D(T1,T2,T3,…,Tn),根据式(1)可得出VSim(Dx,Dy)值从而判断Dx与Dy相似度.
1.2语义相似度
VSM计算模型是基于统计的,其文档间的不相关性造成了文档的语义语境脱离,特别是中文文档,单纯考虑词频等统计信息,给中文文档的相似度计算带来了极大偏差.
语义相似度计算的基本思想是在单纯的代数统计基础上,结合上下文语义语境,发掘文本中蕴含的语义信息,使文本相似度计算更加准确[9].
对于中文语义相似度的研究,知网HOWNET是国内比较权威的代表之一.本文选择知网作为算法一部分的原因在于知网系统有独特的哲学思想.其特点反映在义项和义原上.义项是对词汇语义的描述,一个词分解为多个义项.义项又可以用更低层次的语言来描述,这种语言就是义原.义原是描述义项的最小单位.义原作为描述义项的基本单位的同时,相互之间又存在复杂的关系,如上下位关系、同义关系、反义关系、对义关系等.根据最重要的上下位关系,所有义原组成一个义原层次体系.该层次体系可称之为义原树,文献[6]、文献[10]就是围绕义原树设计相似度算法的.
2基于汉明距离和语义的文本相似度计算
2.1汉明距离
在信息论中,汉明距离是描述两个n长码字a=(a1a2…an),b=(b1b2…bn)之间的距离.
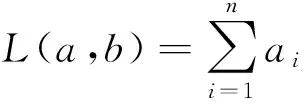
(3)
其中,⊕表示模2加法,ai∈{0,1},bi∈{0,1}.
L(a,b)表示两码字在相同位置上不同码的数目总和,因此它可以反映两码字的差异程度,进而为两码字的相似程度提供依据[11].L(a,b)是介于0和n之间的数,为使相似度表征更为明显,将式(3)变形为:
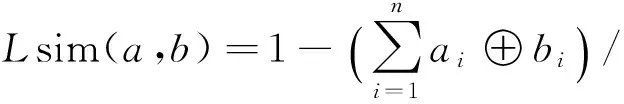
(4)
Lsim(a,b)介于0和1之间,Lsim(a,b)越接近1说明码字a和b越相似.
在上文提到VSM模型中,式(1)文本相似度可用向量余弦值VSim(Dx,Dy)来表征,同样的VSim(Dx,Dy)越接近1,说明文本Dx和Dy越相似.但是VSim(Dx,Dy)的计算涉及到高维稀疏矩阵,计算效率低.对文本来说,经过文本预处理以及分词,原文本转化为关键字集合,与码字的01串相似.将关键字集合继续经过某种规则转化为码字,使文本与码字建立1-1关系,这样文本集合中的文本相似关系就可利用式(4)计算得到.由于机器指令是01串,在计算速度上更具有优越性.
2.2算法思想
前文提到,义原是知网体系的特点之一,是描述概念的最基本单位,将每个词最终分解为多个义原.本算法所涉及的义原参照知网附带的语义相似度计算版本,其总数为1 617个.
本文借鉴VSM模型,结合TF-IDF,HOWNET语义义原以及汉明距离,提出一种新算法,简称HSim.其基本思想是:利用知网义原作为纽带,将TF-IDF算法得到词项集分解归入到义原集中,这一步骤称之为义原化.此时义原集中单项内容为其统计值,为建立词项集与码字集的1-1关系,首先,需要为之前的词项集设置词项阈值,以隔离低频度词项对其后建立的码字集的影响,这里将处理后的词项集称为关键字集;其次,将关键字集义原化,得到的集合称之为义原集.因义原集中的义原频度有高有低,需要将义原集按频度分割处理为n个义原子集,该义原子集称之为汉明集.若义原集为U,两个任意汉明集为Ai,Aj,则有Ai⊂U,Aj⊂U且Ai≠Aj,其中i,j∈(1,n),i≠j.若有2个文本Dx,Dy,则每个汉明集根据式(4)计算得到相似度Asimi.每个汉明集根据分割原理赋予不同权重值Wi.则文本相似度计算公式可表示为:

(5)
2.3HSim算法步骤
根据上述基本算法思想,给出基于汉明距离和语义的文本相似度计算算法的具体步骤.描述中涉及的“=”运算符为赋值运算符;“==”为等值运算符.
输入:词项集Dx,Dy
输出:词项集Dx,Dy的相似度HSim(Dx,Dy).
1)判断词项集Dx,Dy的码字集是否都已创建,若是,跳到步骤5;否则,根据式(2)分别处理Dx和Dy,得到文档中各词项的频度权重值Dx(Tx1,Tx2,…,Txm),Dy(Ty1,Ty2,…,Tyn);
2)设置词项阈值u,过滤文档词项,得到关键字集Dkx(kx1,kx2,…,kxp),Dky(ky1,ky2,…,kyq);
3)根据知网提供的词汇语义相似度算法,得到关键字义原.对应Dkx,Dky分别创建义原集Domx(omx1,omx2,…,omxs),Domy(omy1,omy2,…,omys),初始值归0.分别根据Dkx,Dky的关键字义原遍历Domx,Domy,并在对应义原上执行累加操作.累加数c按关键字频度权重值T递增,增量为1,初始值为1.权重值越高,累加数越大;
4)根据Domx,Domy分别建立码字集BDomx,BDomy,非零置1.设置义原阈值v;
5)遍历初始令i=1,j=1,h=1.从Domx,Domy的i位置同时开始遍历,若omxj或omyj大于阈值v代表的权重值,则将BDomx,BDomy中的对应omxj和omyj的项从i到j划分为汉明集h,记录此时omxj和omyj中较大者值为OMh.然后令h=h+1,i=j+1.每遍历1项令j=j+1;
6)根据式(4)计算汉明集h的相似度Asimh.重复步骤5,当j==s时,遍历结束;
7)根据OMh值从小到大整数递增设置汉明集权重Wh,增量为1;
8)根据式(5)计算词项集Dx,Dy的相似度HSim(Dx,Dy).
下面给出关于阈值参数的定义.
定义1词项阈值u,将文档词项集中词项按数值从大到小排成数列,则u为某词项值的数列位置与数列长度的比值.值域为(0,1).
定义2义原阈值v,将义原集中义原项按数值从小到大排成数列,则v为某义原项值的数列位置与数列长度的比值.值域为(0,1).
3实验及结果分析
3.1数据及预处理
本文实现了基于汉明距离及语义的文本相似度计算模块.实验数据来源于复旦大学中文语料库,从20个类别中,选取6个子集,共1 000篇文章作为数据集,如表1所示.本实验从中选取一部分作为实验数据进行算法验证.

表1 实验数据分布
算法输入的是词项集,因此需要对文本文档先进行词项化处理.本实验采用的词项化处理工具是ICTCLAS2013系统(http://ictclas.nlpir.org/),其创始人是钱伟长中文信息处理科学技术奖一等奖、中科院院长奖获得者张华平博士.该系统除了可以进行中文分词,还可以有效地识别命名实体,避免命名实体对文档内容造成干扰.词项化处理后,利用TF-IDF算法得到文档词项集中各词项的频度权重值.
3.2参数选择及实验
算法中需要设定的参数有词项阈值u以及义原阈值v.
为证实HSim方法的有效性,实验选择VSM模型的TF-IDF算法(以TF-IDF代称)进行比较.虽然TF-IDF存在一些问题,但它在搜索引擎、文本检测等文本处理领域中有广泛的应用.首先利用文本聚类确定词项阈值u以及义原阈值v,从0开始取值;再以TF-IDF算法的相似度结果作为参照,并从耗时方面进行比较;最后从文本聚类的效果上进行度量.在文本聚类上,采用K-MEANS算法[12],并用F度量值来衡量文本相似度算法.F度量值涉及到两个概念:查准率P和召回率R.查准率是指得到的结果中正确结果的百分比,反映的是精确度.召回率是得到的正确结果与全部测试数据总的正确结果的比率,反映的是查全度.F值由查准率和召回率综合而成,为查准率和召回率的调和平均值,是信息检索中重要的衡量手段.公式如下:

(6)
实验1为确定词项阈值u,将义原阈值v设为0,即每个义原项相互独立.图1为文本聚类中不同词项阈值对算法效率影响的实验结果.当词项阈值u为0.6时,F度量值最佳,聚类效果最好.阈值越低,说明得到的关键字集越小,越容易丢失一些逆文本词项;反之,关键字集越大,混在其中的噪音词项越多,对相似度的计算造成困扰.
实验2确定义原阈值v.根据确定的词项阈值u后,同样利用K-MEANS文本聚类以及F度量,可以确定最佳义原阈值v.图2为文本聚类中词项阈值u为0.6时,义原阈值v不同取值对算法效率影响的实验结果.义原阈值v为0时,义原项相互独立,此时,一些高价值义原项容易被忽略.随着v值越来越大,义原之间相关性也越强.当义原阈值v取0.3时,文本聚类效果达到最佳.义原阈值v大于0.30的趋势表明,随着义原项间相关性加强导致独立性下降,一些义原项的高价值被稀释,降低了算法效率.
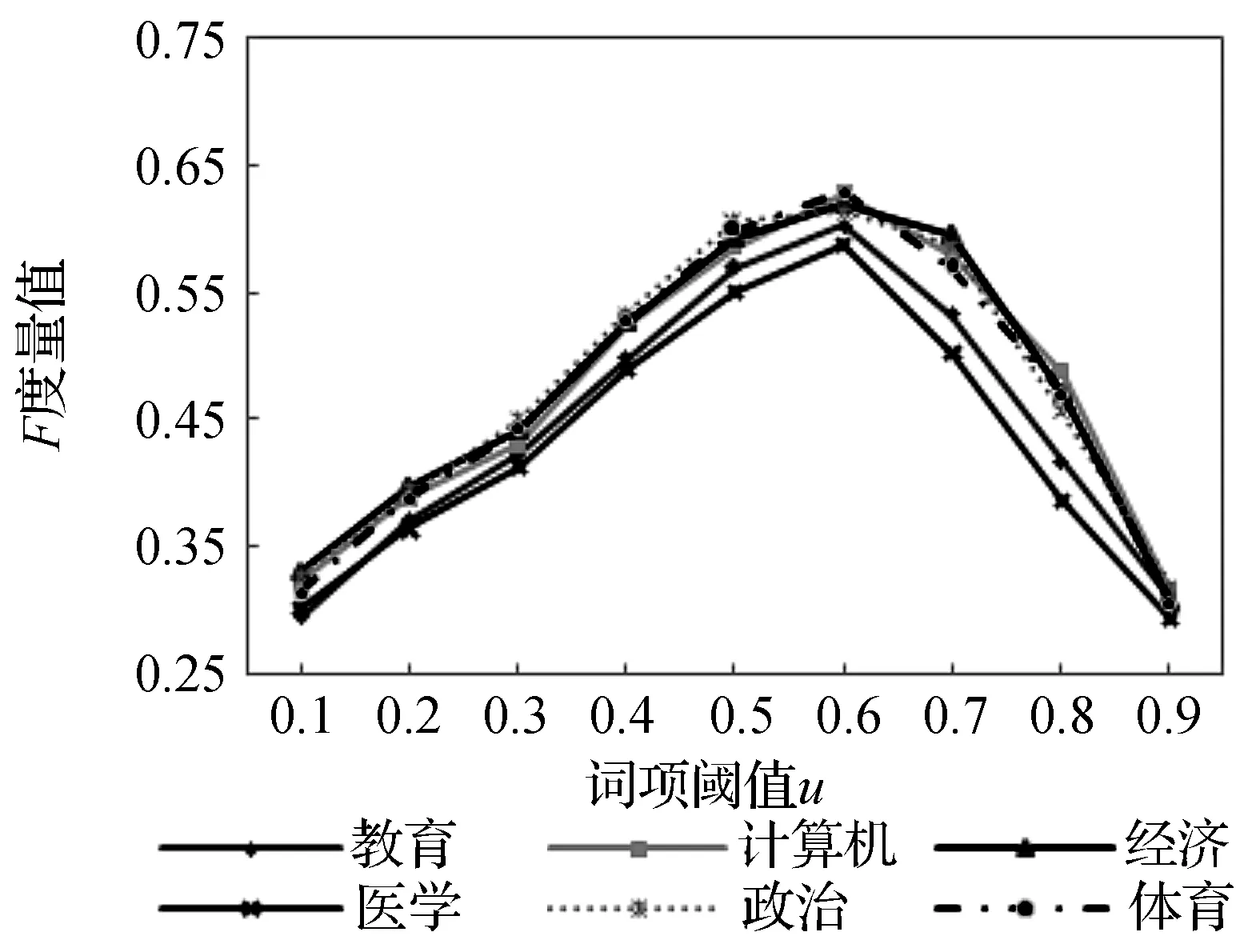
图1 词项阈值对算法的影响

图2义原阈值对算法的影响
实验3选定词项阈值u=0.6,义原阈值v=0.3后,与VSM模型的TF-IDF算法进行比较.在计算相似度方面的耗时上,结果如图3所示.TF-IDF算法的余弦度量在计算时涉及矩阵运算,耗时较长,而HSim算法在相似度计算上进行类似于汉明距离的运算,耗时较短.
实验4同样在选定词项阈值u=0.6,义原阈值v=0.3的情况下,采用K-MEANS聚类算法与VSM模型的TF-IDF算法进行聚类效果比较,结果如图4所示.在聚类效果上HSim优于TF-IDF,其原因在于它在根植于语义的基础上,吸收了TF-IDF精髓,有效结合了汉明距离运算与TF-IDF权重运算,并在相似度计算上规避了TF-IDF所需的大量运算.
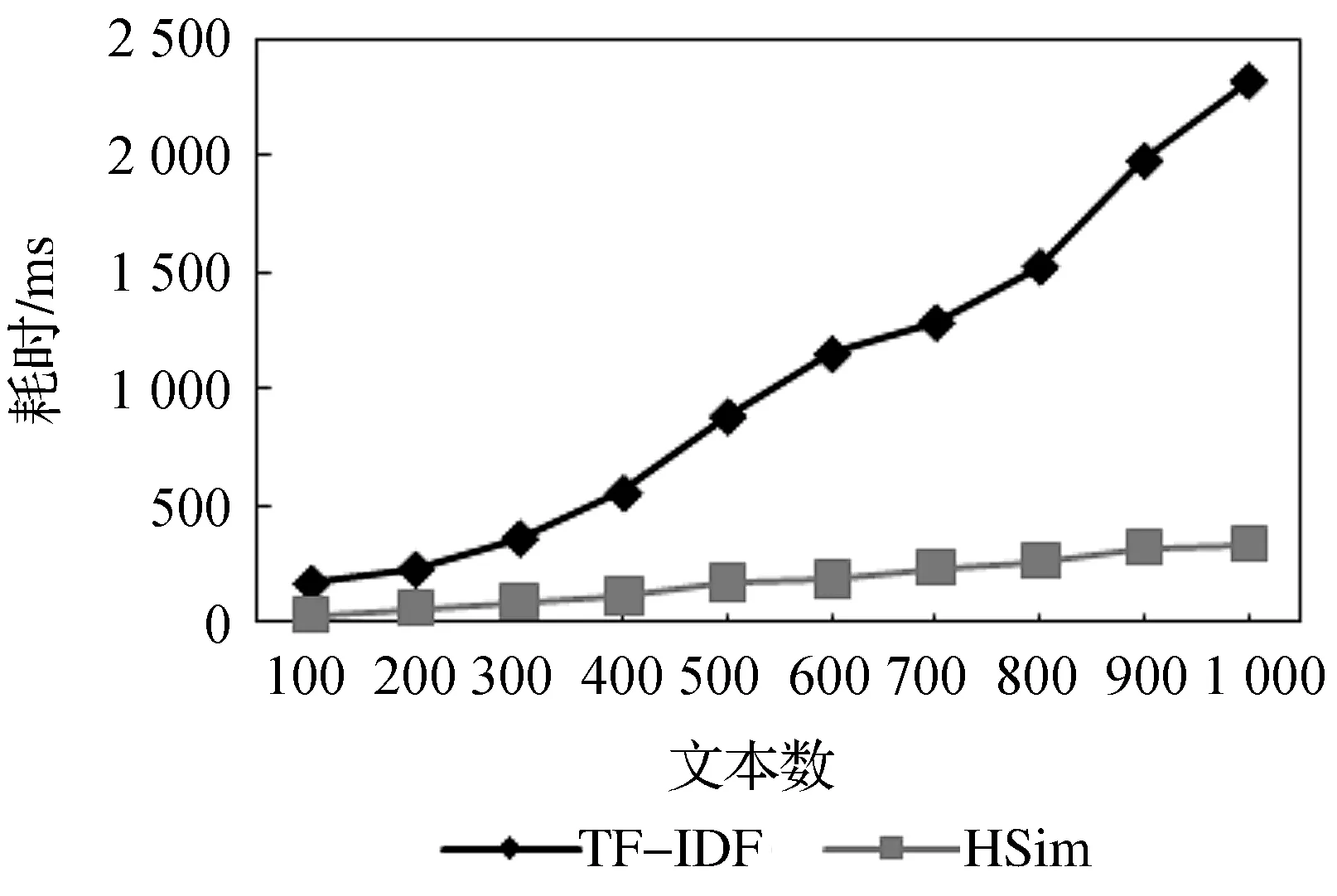
图3 两种算法耗时比较

图4 两种算法实现聚类算法的比较
4结束语
在分析基于统计以及基于语义两类文本相似度量方法优缺点的基础上,本文提出了一种结合汉明距离及语义的文本相似度量新方法HSim.方法综合了VSM模型、知网义原、汉明距离这3个基本概念,通过理论分析和实验验证,本文提出的HSim算法与目前文本处理领域中应用较广泛的类似方法相比,复杂度低、精度高、耗时少.
参考文献
[1]华秀丽,朱巧明,李培峰.语义分析与词频统计相结合的中文文本相似度量方法研究[J].计算机应用研究,2012,29(3):833-836.
[2]GOBLC,NA.Theroleofvoicequalityincommunicatingemotion,moodandattitude[J].SpeechCommunication, 2003, 40(1):189-212.
[3]董振东.知网[EB/OL].(2003-09-10)[2015-05-10].http://www.keenage.com.
[4]刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002,7(2):59-76.
[5]李素建.基于语义计算的语句相关度研究[J].计算机工程与应用,2002,38(7):75-76.
[6]金博,史彦军,滕弘飞.基于语义理解的文本相似度算法[J].大连理工大学学报,2005,45(2):291-297.
[7]MILLERGA.WordNet:alexicaldatabaseforEnglish[J].CommunicationsoftheACM, 1995, 38(11): 39-41.
[8]PATWARDHANS,BANERJEES,PEDERSENT.Usingmeasuresofsemanticrelatednessforwordsensedisambiguation[M]. 2003: 241-257.
[9]夏志明,刘新.一种基于语义的中文文本相似度算法[J].计算机与现代化,2015(4):6-9.
[10]彭京,杨冬青,唐世渭,等.基于概念相似度的文本相似计算[J].中国科学(F辑:信息科学),2009,39(5):534-544.
[11]张焕炯,王国胜,钟义信.基于汉明距离的文本相似度计算[J].计算机工程与应用,2001,37(19):21-22.
[12]李春青.文本聚类算法研究[J].软件导刊,2015,14(1):74-76.
DOI:10.13954/j.cnki.hdu.2016.03.008
收稿日期:2015-10-16
作者简介:胡维华(1949- ),男,浙江富阳人,教授,网络协议、图像处理、数据挖掘研究.
中图分类号:TP391.1
文献标识码:A
文章编号:1001-9146(2016)03-0036-06
The Research about Text Similarity Measuring through Hamming-distance and Semantics
HU Weihua, BAO Qian, LI Ke
(SchoolofComputer,HangzhouDianziUniversity,HangzhouZhejiang310018,China)
Abstract:To measure the text-similarity, the term frequency-inverse document frequency(TF-IDF) algorithm combined with vector space model(VSM) is a common practice in the field of text information processing. However, this method involves the processing of high-dimensional sparse matrix with a low computational efficiency. In addition, it ignores the impact of semantic information on the text. Another kind of similarity algorithm based on semanteme can overcome this shortcoming. But it needs support of knowledgebase in specific fields, and the complexity of its establishment results in more theory than practice of such algorithm. For these concerns a new method is advanced, which integrates the advantages of TF-IDF and semantic information from HOWNET. This method works out the value of text-similarity by Hamming-distance, avoiding direct processing of high dimensional sparse matrix. The results show that new method is higher than the current method in the efficiency of processing, and is more suitable for processing a large amount of text.
Key words:text-similarity; vector space model; term frequency-inverse document frequency; semantic information; Hamming-distance
