基于CUDA的视频运动目标检测算法并行实现
2016-08-02楼先濠郭春生宋少雷齐利泉
楼先濠,郭春生,宋少雷,齐利泉
(杭州电子科技大学通信工程学院,浙江 杭州 310018)
基于CUDA的视频运动目标检测算法并行实现
楼先濠,郭春生,宋少雷,齐利泉
(杭州电子科技大学通信工程学院,浙江 杭州 310018)
摘要:在视频运动目标检测的能量优化算法中,引入目标先验约束信息,能有效地提高目标检测性能,同时也极大地增加了算法的复杂度.以CUDA平台为基础,从算法并行任务划分,实现粗细粒度并行;从合理规划GPU内存分配,提高数据的吞吐率两方面实现了带约束的能量优化视频运动目标检测算法的高效并行.实验结果表明,算法的GPU并行实现与CPU串行实现相比,显著提高了计算速度.
关键词:目标检测;能量优化;并行计算;统一计算设备架构
0引言
基于混合高斯背景建模的检测算法在视频运动目标检测领域得到广泛应用,但存在目标空洞、目标伪装和复杂背景适应性等问题[1],因此基于全局能量最小化的混合高斯背景建模的运动目标检测算法得到关注[2].带目标先验信息约束的全局能量最小化运动目标检测算法在改善运动目标检测性能的同时,也带来了计算量显著增加的问题.例如,当采用最大流/最小割的MATLAB实现对分辨率为768×576的视频序列进行运动目标分割,网络流参数计算和分配部分占全部计算时间的90%以上,严重影响了算法的计算效率.近年来,高重复性且运算量大的图像视频分析处理常利用GPU并行计算来改善计算效率.文献[3]利用GPU加速实现了非参数背景建模实时运动目标检测,文献[4]则利用统一计算设备架构(Compute Unified Device Architecture,CUDA)并行相应算法实现了对高光谱图像的实时异常检测.本文通过分析带目标先验信息约束的全局能量最小化运动目标检测算法中网络流计算部分的并行性,结合CUDA存储架构特点,实现了算法的并行计算,提高了目标检测的实时性.实验中对分辨率为768×576的视频序列进行测试,结果表明本算法的并行处理速度能够接近实时.
1视频运动目标检测算法
本文采用的基于最大流/最小割的能量最小化方法,其能量函数表示为:

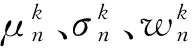
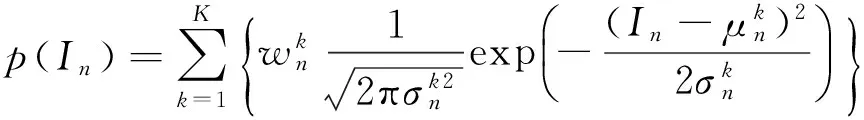
(2)
Pn,m为相邻两个像素点m,n受加权梯度约束时分属于目标和背景的概率,定义为:
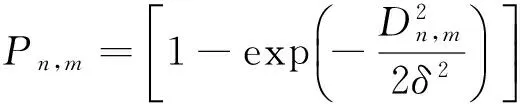
(3)
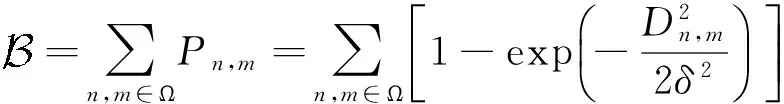
(4)
本文视频运动目标检测算法的整体流程如图1所示.

图1 视频运动目标检测算法流程图
2算法并行化
2.1并行任务划分
本文通过将网络流参数计算中的概率密度值计算、高斯滤波、区域项计算、梯度计算以及梯度加权计算定义为功能独立的CUDA内核,以此实现算法并行.依据图像按行连续排列存储的特点以及CUDA线程模型的特点对各个内核的计算任务做了粗细粒度的划分.首先,以行作为划分依据,按照行数H将视频图像划分成优先级一致的H组,实现粗粒度的并行;其次,各行图像以像素为单位再划分,实现细粒度的并行.
下面以计算概率密度值内核为例具体分析内核任务的划分情况.内核任务并行划分如图2所示,CUDA中的内核是以线程网格(Grid)的形式组织,一个内核对应一个线程网格,线程网格包含若干个线程块(Block),线程块又包含若干个线程(Thread)[5].内核任务划分对应到上述线程模型:一帧视频图像即映射到网格上;一行视频图像即映射到一个线程块;一行中的像素点即映射到线程块中的线程.本文中网格和线程块都设置为一维模式:一个网格包含H个线程块,其中第i(1≤i≤H)个线程块负责计算视频图像的第i行数据;每个线程块中启动S个线程,其中第j(1≤j≤S)号线程负责计算第j+S×k(k=0,1,2,…)个像素点(j+S×k≤图像宽度W).图2中,左下角图像代表连续输入的视频图像,任务划分完成后,每一个CUDA线程都执行相同的指令并按照自身的线程号索引来读取数据,实现并行计算,最终得到右下角表示目标出现的概率密度图.其他内核任务划分与上述内核一致,都按照以行为单位的划分方法进行了任务划分.
2.2内存规划
本文从纹理内存和共享内存两个方面对内存进行规划.首先,将输入图像数据绑定至纹理内存,以此来优化二维图像的随机读取速度;其次,根据一个线程块对应一行数据的并行任务划分方式规划了共享内存的使用;最后,结合纹理内存和共享内存一起使用来加速高斯滤波和梯度计算两个内核.本文算法在GPU中的整体内存规划如图3所示.
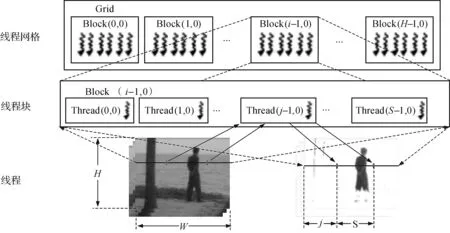
图2 “计算概率密度值”内核任务并行划分示意图
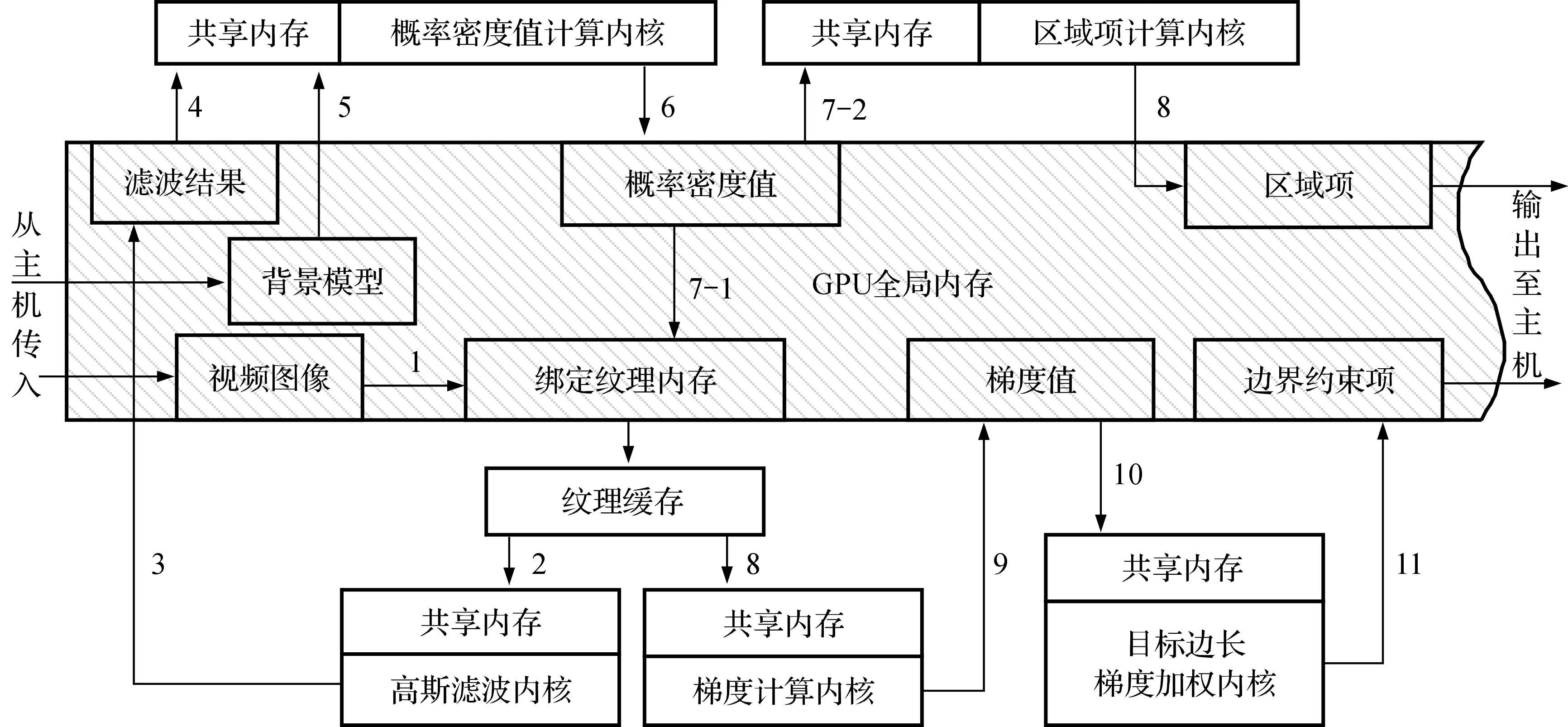
图3 并行算法内存规划及数据流转示意图
图3中,数字标明了本文并行算法中数据在GPU内存中的流转顺序.各个内核计算得到的中间值被保存在全局内存中,因此内核在开始计算时,首先根据并行任务划分方式从全局内存将计算当前行所需的数据存入共享内存,这样,块内线程就能以低延迟读取共享内存,从而加快计算速度.传统内存优化方式仅使用了纹理内存或者共享内存,单使用纹理内存速度没有使用共享内存快,单使用共享内存不如使用纹理内存方便.本文将纹理内存和共享内存结合起来使用,即提高了读取速度,又能利用纹理特性来处理图像边界问题,达到以空间换时间的目的.
3实验分析
为比较本文算法并行的有效性,本文做了另外两种不同的实现:一是纯MATLAB代码实现,二是把网络流参数计算部分转化成C代码串行实现.本文将CUDA并行和C串行的代码都编译成MEX函数的形式,再由MATLAB调用执行.CUDA-MEX、MATLAB和C-MEX分别代表3种实现方式.MEX函数由Microsoft Visual C++2010和CUDA5.5版本NVCC编译器编译.MATLAB为2012b 64位版本.
为测试本文并行算法在不同GPU上的加速能力,在两个实验平台上做了对比分析.两个平台软件环境一致,操作系统均为Windows7 64位版本,硬件配置不同之处如表1所示.

表1 实验平台硬件对比
实验对不同分辨率大小的视频作了对比分析,统计单帧图像网络流参数计算的时间,具体情况如表2所示.加速比Sp定义为Sp=Ts/Tp,Ts表示串行程序执行时间,Tp表示并行程序执行时间.表2中,以Sp1表示CUDA-MEX实现相对MATLAB实现的加速比,Sp2表示CUDA-MEX实现相对C-MEX实现的加速比.
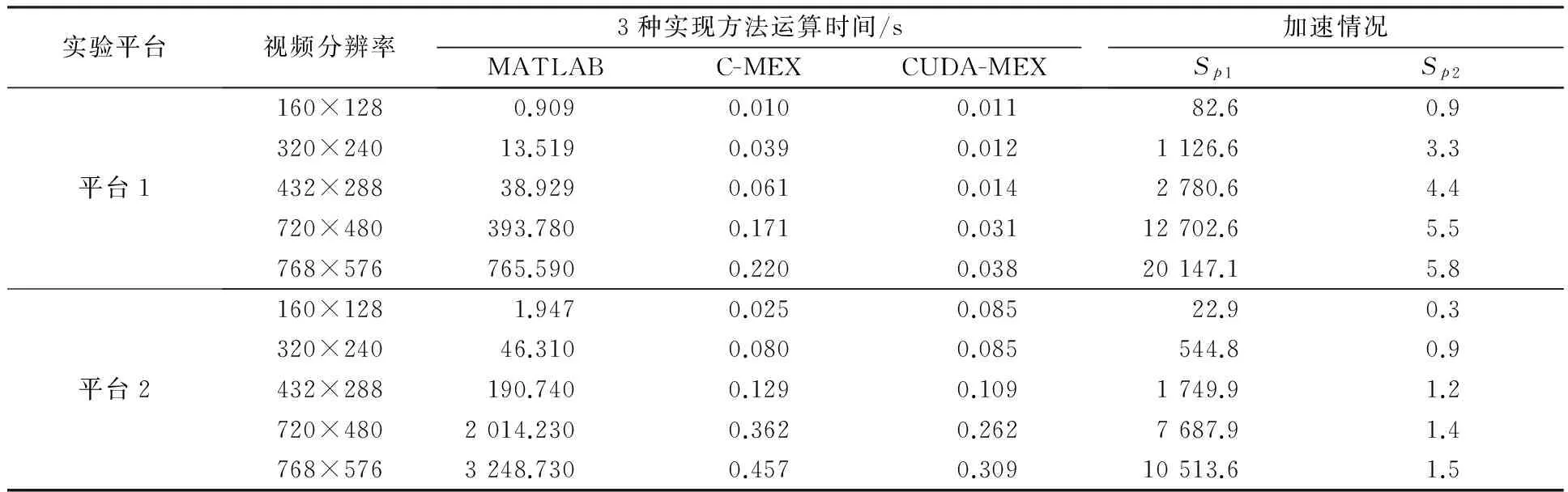
表2 3种实现方法运算时间对比
从表2中的Sp1可以清晰地看到GPU并行实现带来的巨大效果,对MATLAB实现来说高分辨率图像甚至达到了上万倍的加速效果.Sp2数据更加真实地反映了加速情况,从中可以看到平台1的CUDA并行加速效果较为明显.以432×288分辨率的视频为例,平台1的网络流并行计算速度较平台2快7.7倍(0.109/0.014),而720×480分辨率快8.4倍(0.262/0.031),这也反应了平台1的GPU计算能力较强.平台2虽然计算能力只有1.2,但是随着视频分辨率增加也取得了一定的加速效果.两个平台在图像尺寸为160×128的情况下,并行实现效果反而不如CPU串行实现,原因在于调用CUDA需要在主机和设备之间传递数据,而在计算量较小的情况下通过并行加速节省的时间还不足以掩盖传输数据带来的延迟.
4结束语
带约束的能量最小化视频运动目标检测算法比普通目标检测算法性能更优,但是过高的算法复杂度限制了它的使用范围.本文实现了一种基于CUDA并行计算的带约束能量最小化视频检测算法.算法将计算任务划分至多线程并行实现,同时充分利用了GPU中纹理内存和共享内存的特性,提高了数据吞吐量.实验结果表明了本算法并行实现的高效性,在不同平台上都取得了显著的加速效果.
参考文献
[1]BOUWMANST,ElBafF,VACHONB.Backgroundmodelingusingmixtureofgaussiansforforegrounddetection-asurvey[J].RecentPatentsonComputerScience, 2008, 1(3): 219-237.
[2]GUOC,LIUD,GUOYF,etal.Anadaptivegraphcutalgorithmforvideomovingobjectsdetection[J].MultimediaToolsandApplications, 2014, 72(3): 2633-2652.
[3]BERJOND,CUEVASC,MORANF,etal.GPU-basedimplementationofanoptimizednonparametricbackgroundmodelingforreal-timemovingobjectdetection[J].ConsumerElectronics,IEEETransactionson, 2013, 59(2): 361-369.
[4]TARABALKAY,HAAVARDSHOLMTV,KÅSENI,etal.Real-timeanomalydetectioninhyperspectralimagesusingmultivariatenormalmixturemodelsandGPUprocessing[J].JournalofReal-TimeImageProcessing, 2009, 4(3): 287-300.
[5]NVIDIA.CUDACProgrammingGuide[EB/OL].[2015-09-01].http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html.
DOI:10.13954/j.cnki.hdu.2016.03.005
收稿日期:2015-10-16
基金项目:国家自然科学基金资助项目(61372157)
作者简介:楼先濠(1990-),男,浙江浦江人,硕士研究生,电子与通信工程.通信作者:郭春生副教授,E-mail:guo.chsh@gmail.com.
中图分类号:TN911.73
文献标识码:A
文章编号:1001-9146(2016)03-0023-04
Parallel Implementation of Video Moving Object Detection Algorithm Based on CUDA
LOU Xianhao, GUO Chunsheng, SONG Shaolei, QI Liquan
(SchoolofCommunicationEngineering,HangzhouDianziUniversity,HangzhouZhejiang310018,China)
Abstract:In the energy optimization algorithm of video moving object detection, the introduction of object priori constraint information such as edge length helped to achieve a more robust detection, but also greatly increased the complexity of the algorithm. On the compute unified device architecture(CUDA) platform, this paper implemented a moving object detection algorithm based on constrained energy optimization with high efficiency by two aspects: multi-granularity parallelization by parallel task partition, elevated data throughput by optimized GPU memory allocation. Experimental results show that the parallel algorithm achieved a significant improvement of computing speed compared with the serial algorithm.
Key words:object detection; energy optimization; parallel implementation; compute unified device architecture
