基于Hadoop的并行化聚类系统的设计
2016-07-26张友海李锋刚安徽职业技术学院信息工程系安徽合肥230011合肥工业大学管理学院安徽合肥230009
张友海,李锋刚(1.安徽职业技术学院 信息工程系,安徽 合肥 230011;2.合肥工业大学 管理学院,安徽 合肥 230009)
基于Hadoop的并行化聚类系统的设计
张友海,李锋刚
(1.安徽职业技术学院 信息工程系,安徽 合肥 230011;2.合肥工业大学 管理学院,安徽 合肥 230009)
摘 要:数据挖掘技术可以找出大量数据中的隐含的价值并对数据做作出预测.聚类分析是挖掘数据价值的重要手段之一,在识别数据的内在相似性具有极其重要的作用.近些年来,随着互联网技术的飞跃式发展,各行各业产生的数据以爆炸式的增长.面对如此庞大的数据量,传统的数据挖掘处理方式已经无法胜任,而以Hadoop生态圈为代表的大数据处理方法,提供了成熟且易用的工具技术支撑.因此,基于Hadoop相关工具来设计一种并行化聚类系统具有非常重要的意义.
关键词:数据挖掘;聚类分析;hadoop
1 引言
互联网的普及和各种互联网技术的快速应用,导致大量数据,充斥在人们生产和生活中.如何有效地从这些繁复复杂的数据中提取有价值的隐含信息意义重大.所谓聚类分析就是将包含有大量数据对象的数据集合划分为若干个类或者是簇,使得同一类或者簇中的对象彼此具有较高的相似度,而不同的类或者簇中的对象之间的相异度则比较大.聚类算法不同于其他的数据挖掘算法,它不依赖于预先已经定义好的簇或者类的特征.在数据挖掘领域,学术界提出了若干的基于不同思想的聚类算法,其中应用最为广泛且思想较为简便的是基于划分的聚类算法.如何采用快速有效的聚类算法对海量的数据进行有效处理十分迫切,分布式技术的应用为海量数据的处理提供了新的机遇.云计算是分布式发展的重要方向,它利用互联网,使用多台计算机进行分布式协同处理,共享各种信息以及软硬件资源,为用户提供分布式的信息服务.目前,Hadoop作为一种有效手段,被广泛应用于数据挖掘领域.Hadoop是一个开源的分布式云计算平台,能够实现对大量的数据集高效、可靠、可伸缩的分布式处理.它是一个软件框架,由底部的分布式文件系统(Hadoop Distributed File System,简称HDFS)和上层的MapReduce编程模式构成,它们是Hadoop的核心.HDFS用于存储Hadoop集群中的所有存储节点上面的文件,而MapReduce编程模式是将已有单机算法实现分布式的关键,通过实现MapReduce编程模式,我们就可以方便的把已有的算法移植到Hadoop平台实现算法的并行化.然而,在实际项目中,除了研究聚类算法外,还针对具体的应用需求来改善现有的聚类算法,并在Hadoop平台上进行分布式实现.这也是系统设计完成后的终极目标.
2 需求分析
2.1 功能性需求
本系统处理对象主要是以CSV的大容量文本文件,系统需要选取合适的存储方式存储这些大文件.另外系统需要提供合适的导入导出工具,实现预处理文件的导入和结果文件的导出,然后对数据进行预处理操作.用户可以选择分类算法对数据进行模型训练,可以利用测试集对分类效果进行评估.另外,聚类也是系统的一个重要功能,用户可以选择系统提供的并行化聚类算法对数据进行聚类,并对聚类效果进行评测.另外,系统提供数据导出工具,用于将结果数据导出系统.系统功能可以分为数据管理,数据预处理,并行化分类,并行化聚类4个部分.
数据管理:如何存储单机无法存储的数据是大数据处理系统需要解决的问题.另外如何保证在少数节点宕机的情况下数据不丢失也是本系统需要解决的问题.大数据处理系统的数据导入导出是数据处理系统的必要模块,对于大数据系统高效地将待处理数据上传到数据处理系统以及将结果数据下载或备份到其他系统都是需要完成的功能.
数据预处理:需要实现在分类和聚类前使用数据变换和数据清理,以提高数据的质量,分类和聚类的效果,同时也要提高分类和聚类的效率,以减少数据处理时间.
分类和聚类:需要以并行化方式实现自动化分类系统和聚类系统.提高分类和聚类的效率.并可以动态扩张,以适应数据量的膨胀.
集群管理:由于大数据系统的特点就是集群规模庞大,如果完全依赖人工运维的话,将不堪重负,而且也不切实际.系统也需要提供自动化运维工具以实现自动化安装,自动化配置软件,并提供告警和监控功能
2.2 非功能性需求
可扩展性:系统在现实使用过程中可能出现用户数量快速增长现象,这就要求系统有动态扩展的能力,以适应带来的系统负载量的增加,系统功能的扩展也要容易实现.
可维护性:可维护性是指系统管理员能够方便地进行系统维护,在系统发生错误或者崩溃时,能够很快地定位到问题所处位置.因此系统在投入使用后,需要提供带宽、磁盘、CPU、内存等性能指标实时监控工具.另外系统还应该有详细的日志输出,这些日志包括系统运行日志和系统错误日志.系统运行日志主要记录用户登录、退出和重要数据变更等反映系统运行状况变化的信息;这些信息主要用于管理员对系统使用情况进行跟踪.系统错误日志包括系统的错误、警告信息等;这些信息主要用来提供给技术人员对系统的错误原因进行分析.系统需要提供方便的日志管理程序,以方便查询、删除系统日志.
精确性:系统的分类效果需要达到一个理想的值.如召回率和准确性都有一个较高的值.
高效性:系统需要在特定数据量情况下能够处理完成.
3 系统设计
系统的总体架构如图1所示,其中基础设施层保证了网络,存储,以及运算的基本能力.在基础设施层之上部署基于hdfs的分布式文件存储系统,以提供大文件的存储能力和存储可靠性.另外在基础设施之上同时还会构建MapReduce计算框架,以提供分布式处理能力.数据管理构建在分布式文件存储hdfs之上,实现用户数据高效导入和结果文件的高效导出.本系统将通过MapReduce编程框架实现数据的预处理功能,并行化分类以及并行化聚类功能.最后系统接口提供用户可以通过WEB页面方式使用本系统.

图1 系统总体结构
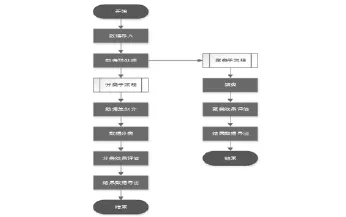
图2 系统的运行流程
本系统的使用流程如图2所示,用户实现导入数据到分布式文件存储系统hdfs,通过数据预处理模块运行预处理.用户可以安装需要选择分类还是聚类.用户如果需要进行分类预测,用户可以选择对数据进行划分,划分为数据集和测试集,然后对通过分类模型进行分类.分类完成后会对分类效果进行评估.最后用户可以将分类结果导出.如果用户需要对数据进行聚类,用户可以选择聚类模型对预处理后的文件进行聚类,然后对结果进行评估,最后用户可以将结果数据导出.系统主要涉及5个功能模块,分别是:数据管理,数据预处理,并行化分类,和并行化聚类,集群运维.
3.1 集群运维子系统
大数据运维子系统将依托开源集群运维工具Ambari进行集群管理,采用主从式架构,主节点进行管理,从节点执行节点组件添加删除,组件配置,运维消息采集等等工作.
3.2 大数据存储系统
存储系统将采用hdfs和hbase作为底层存储系统,使用hdfs存储文件,有hbase存储需要实时查询的信息.本系统实现用户可以通过多种方式将文件导入到存储系统中.提供ftp方式将本地文件导入到存储.也支持通过页面上传小文件到存储系统,另外支持,将关系数据表导入到存储系统或者将结果导入到关系数据库中.
3.3 数据预处理模块
该子系统将包括数据预处理模块和数据分类挖掘模块.预处理模块将为用户提供MR,hive,pig等多种方式进行数据预处理.用户可以编写简单的sql脚本,或pig脚本进行数据处理.对于复杂的问题可以是使用MapReduce进行处理.
3.4 并行化分类模块
本模块将提供基于MapReduce的kMeans聚类算法的并行化实现.提供基于pig,hive的模型评估功能对聚类效果进行评估.并提供基于Pig,Hive的模型评估功能,实现对数据分类效果的评估.充分发挥MapReduce并行化计算的优势,提高分类效率.
总的来说,基于Hadoop的并行化聚类分析系统的设计是一个比较复杂的过程,这里只是简要分析了系统的需求,并对系统进行了总体设计,对系统架构和系统基本流程作了描述以及对系统的各个模块做了简要设计.如果需要实现该系统功能还需要进行具体的编程实现.
参考文献:
〔1〕【美】陈封能,【美】斯坦巴赫,【美】库玛尔.数据挖掘导论(完整版)[M].人民邮电出版社,2011.305-347.
〔2〕王骏,王士同,邓赵红.聚类分析研究中的若干问题[J].控制与决策,2012(03):321-328.
〔3〕喻云峰.数据挖掘算法的分析与研究[J].科技广场,2010 (9):54-56.
〔4〕解二虎.数据挖掘中数据预处理关键技术研究[J].科技通报,2013(12):211-213.
〔5〕吴昉,宋培义.数据挖掘的应用[J].贵州科学,2012,30(3):54-56.
〔6〕周莹.数据挖掘聚类算法研究及实现[J].信息技术与标准化,2013(9):32~34.
中图分类号:TP311.13
文献标识码:A
文章编号:1673-260X(2016)05-0015-02
收稿日期:2016-03-18
基金项目:国家自然科学青年基金项目资助(71301041)
