三支决策基于粒度的邮件过滤
2016-07-23肖瑶
肖瑶


摘要:现在目前的邮件处理方式一般将邮件分为:普通邮件和垃圾邮件。但在实际中,经常会有安全的邮件被放进垃圾邮件中。为了减少这部分的损失,现我们可以将邮件分为:普通邮件、可疑邮件和垃圾邮件。我们采用三支决策的方法,将邮件分为三类,来达到减少误判的目的。同时,由于现在的人们为了隐藏垃圾邮件,会将发送的内容中的一些字换成形似的其他字,来达到避开分类的目的。因此本文提出将粒计算也加入到分类的标准中,更好的能识别垃圾邮件,为邮件进行过滤分类。
关键词:邮件过滤;三支决策;粒计算
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2016)17-0248-04
1 概述
随着科技的发展,网络的普及,收发邮件已经成了人们日常生活中不可缺少的工作。我们都知道邮件拥有普及性、实用性等优点,然而有些人正是看中了这种高效的操纵性,频繁、大量的制造垃圾邮件,妨碍了邮件本该带来的方便,制造了不便。针对垃圾邮件过滤的问题,有人提出基于黑白名单过滤、反向DNS查询等方法。而这类方法很容易被有意识的修改某些信息而绕过过滤因而产生误判。因此,减少误判也是我们所需要关注的重点。
现在也有许多关于分类的机器学习算法来自动的对邮件进行分类。其中,贝叶斯分类器取得了很好的效果。朴素贝叶斯分类器以及其他的邮件分类算法,对邮件过滤一般处理为两类,即要么是垃圾邮件,要么是非垃圾邮件。而这种方法在现实生活中则太过绝对,很容易产生误判。因此,本文基于姚一豫教授提出的三支决策理论,结合贝叶斯算法、粗糙集、粒计算等,以提高垃圾过滤的准确性。
2 相关理论
2.1 朴素贝叶斯垃圾邮件过滤
其中,
同理,我们也可以写出邮件属于垃圾邮件类的条件概率为:
由(3)(4)式我们可以得到:
其中
2.2 知识粒度
3 邮件过滤模型建立
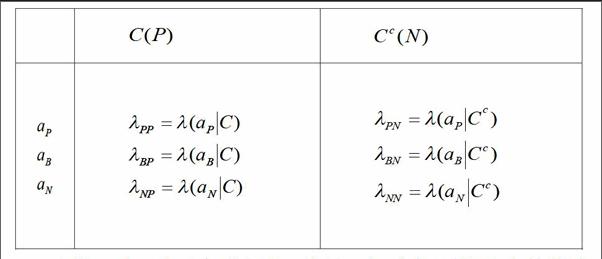
3.1 三支决策模型
在朴素贝叶斯算法中,当后验概率超过一定阈值时,可以将邮件归为非垃圾邮件类。在本文中的基于三支决策方法,我们将确定两个阈值,来对邮件进行三类的分类。一个阈值来决定邮件是否需要再判断,另一个阈值来确定是否把邮件归为垃圾邮件类。
本文中的三支决策方法是基于决策粗糙集理论和贝叶斯定理,其中,决策粗糙集是由两个状态集和三个行动集来进行的。
3.2 过滤过程建立
目前,许多不法分子为了躲避关键字的过滤,经常采取一些手段来编辑邮件。例如邮件的内容中,用很多特殊符号和繁体字,以及利用字形相似的文字来代替书写,躲避关键词。为了减少因这些问题带来的误判,本文将邮件划分为有限个粒度,层层递进的来对邮件进行处理。
我们将邮件划分为
决策过程:
(1)对粒度
(2)依次添加信息粒度,重复进行(1)中的过程,对划分为可疑邮件的邮件逐步添加属性粒度信息,及时进行决策。
(3)若所有的属性信息全部添加完后仍划为可疑邮件,则交由收件人自己判断。
过程流程图如下:
由(12)式得:
来划分一次分类中邮件所属的区域。
3.3 模拟实验分析
本文从自己的邮箱中提取数据集,一共400封邮件,其中124封正常邮件,276封垃圾邮件。接下来对邮件的关键字进行提取,过滤一些意义不大的字眼,如“啊”,“一”,“的”等。提取每一个词,计算每个词在正常邮件和垃圾邮件中出现的频率。例如,在276封垃圾邮件中,有23封包含这个词语,那么它出现的频率就是0.083。其中,为了避免太过绝对,若某个词只出现在垃圾邮件中,那我们就假设它出现在正常邮件中的频率为0.01。同时,统计垃圾邮件中,发件人的邮箱和发送时间的频率。并且,统计每一封垃圾邮件中繁体字出现的频率。
现有一封新邮件,我们将它分为5个粒度,A1=[邮件发件人],
其中,对于
现对
[Pr(NW1)=Pr(N)Pr(W1N)Pr(W1)] (18)
其中,
在各分类阶段中,第
4 结束语
在电子邮件普遍使用的今天,如何对邮件进行准确的过滤是我们一直关注的问题。本文以三支决策为基础,结合贝叶斯算法、粗糙集、粒计算等,建立了一个邮件过滤模型。通过从小到大的粒度,能够更高效、更准确地对邮件进行过滤。下一步将考虑如何划分适当的粒度,来提高准确性和高效性。然后,也可以考虑在大数据的平台下来实现这一过程。
参考文献:
[1] 王国胤, 张清华, 胡军. 粒计算研究综述[J]. 智能系统学报,2007,2(6):8-26.
[2] Bing Zhou, Yiyu Yao, Jigang Luo. A Three-Way Decision Approach to Email Spam Filtering[C]. Canadian Conference on Advances in Artificial Intelligence. Springer-Verlag, 2010:28-39.
[3] Sahami M, Dumais S, Heckerman D, et al. A Bayesian Approach to Filtering Junk E-Mail[J]. Papers from the Workshop Aaai,1998.
[4] Yao Y. Three-Way Decision: An Interpretation of Rules in Rough Set Theory[C]// International Conference on Rough Sets and Knowledge Technology. Springer-Verlag, 2009:642-649.
[5] 王国胤, 张清华. 不同知识粒度下粗糙集的不确定性研究[J]. 计算机学报, 2008, 31(9):1588-1598.
[6] 翟军昌, 秦玉平, 王春立. 改进的朴素贝叶斯垃圾邮件过滤算法[J]. 计算机工程与应用, 2009, 45(14):145-148.
[7] Yao Y. The superiority of three-way decisions in probabilistic rough set models[J]. Information Sciences, 2011, 181(6):1080-1096.
[8] 王国胤, 张清华, 马希骜,等. 知识不确定性问题的粒计算模型[J]. 软件学报, 2011, 22(4):676-694.
[9] 李建林, 黄顺亮. 多阶段三支决策垃圾短信过滤模型[J]. 计算机科学与探索, 2014, 8(2):226-233.
[10] 李华雄, 刘盾, 周献中. 决策粗糙集模型研究综述[J]. 重庆邮电大学学报:自然科学版, 2010, 22(5):624-630.
