基于改进向量空间模型的克隆群映射方法
2016-07-19陈桌张丽萍王欢张久杰王春晖
陈桌 张丽萍 王欢 张久杰 王春晖


摘要:针对Type3克隆代码映射方法少且效率低等问题,提出了一种基于改进向量空间模型(VSM)的映射方法。该方法将改进的VSM引入到克隆代码分析中,从而得到一种可有效映射Type1、Type2以及Type3克隆代码的克隆群映射方法。首先,将克隆群文档预处理得到去除无用词的代码文档,同时提取克隆群文档的文件名、函数名等特征项;其次,提取并构建克隆群词频向量空间,利用余弦算法计算出克隆群相似度;然后,通过克隆群相似度和特征项的匹配构建克隆群映射,最终得到克隆群映射结果。对5款开源软件进行实验并人工验证,所提方法能在低时耗的前提下,保证查全率和查准率均不低于96.1%和97.1%。实验结果表明了所提方法的可行性,为后期软件演化分析提供数据支撑。
关键词:
克隆代码;克隆群映射;向量空间模型;特征项;词频
中图分类号: TP311.5 文献标志码:A
0引言
在软件开发和维护过程中,开发人员经常采用复制粘贴的方式修改代码,导致重复的代码片段出现,即克隆代码[1]。以前的研究[2]已经表明,一个软件系统中会有9%~15%的克隆代码,有时甚至高达50%以上,相同或相似的代码会增加软件的维护费用。例如,如果一个bug在代码片段中被检测出来,所有和它相似的片段都应该被调查,检查相同的错误,加强或调整这些代码。所以对系统版本中的克隆进行追踪非常有意义。
相邻版本间的克隆群映射是研究克隆代码演化[3]工作的关键步骤,克隆演化研究关注的是一段克隆代码在软件多个版本中的变化情况,而克隆群映射是整个演化过程的纽带。本文提出的克隆群映射方法是根据自然语言领域中计算文章相似度的向量空间模型(Vector Space Model, VSM)改进的。向量空间模型[4]就是把对文本内容的处理简化为向量空间中的向量运算,并且以空间上的相似度表达文本的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。
在克隆代码方面,改进的向量空间模型的基本思想是把每个版本中的克隆群简化为以特征项(关键词)的权重为分量的N维向量,结果用十分简单的向量表示,使得模型具备了可计算性,有效衡量克隆群之间的相似性,并建立版本间的映射。
1相关工作
1.1克隆定义与分类
克隆代码的定义目前广受采纳的是将具有相似语法及语义特征[5]的代码段称为克隆代码。系统同一版本中的两段相似代码片段称为克隆对。两个或多个相似代码片段组成一个克隆群。追踪从前一版本到当前版本克隆群的变化过程称为克隆群映射。现有研究中,克隆主要有以下两种分类方法[6]:一是相似程度,二是代码段的粒度。按源代码文本相似性将克隆分为Type1型至Type4型克隆(定义见表1),其中Type1至Type3体现了语法上的相似程度,Type4体现了语义上的相似程度。按克隆关系中代码段的粒度分为文件、块、函数、类及语句等类型。
1.2克隆映射
克隆映射(Clone mapping)是对软件版本间的两个克隆建立映射关系,其映射条件是具有映射关系的两个克隆具有同源性。如何计算这些相似关系,并找出最大相似的克隆实例对它们建立映射关系,是克隆映射过程需要解决的问题。
目前构建克隆映射的方法主要有7类[6]。
1)先检测软件第一个版本中的克隆,然后根据并发版本系统(Concurrent Version System, CVS)代码库中提供的修改日志,计算版本间的变化,最终得到映射关系[7]。由于以第一个版本中的克隆为映射源,因而无法研究在后期版本中引入的克隆。
2)检测所有版本中的克隆,然后基于文本相似性及位置关系追溯映射[8-9]。此方法适用于多种不同的克隆演化研究,但时间复杂度高,且映射的最小阈值是经验值,易受克隆中大变化的影响。
3)对所有版本进行克隆检测,将检测到的克隆代码抽象成克隆区域描述符(Clone Region Descriptor, CRD),然后在不同版本中跟踪CRD,通过检测CRD中的文本区别构建映射关系[10]。此方法映射的建立不受克隆位置信息的影响,易实现克隆的一致修改,但映射误报率偏高。
4)使用增量的算法将克隆检测与映射结合在一起[11]。该方法时间复杂度低,适合处理给定版本的软件,但添加新版本时整个检测与映射需重新执行,空间复杂度高。
5)先映射相邻版本间的函数,在此基础上实现克隆映射[12]。该方法减少了运行时间,但易受重载函数与覆盖的函数影响。
6)利用源代码的文本和结构信息,将映射问题由高维的代码空间转化到低维的主题空间[13]上,通过映射主题来准确地构建相邻版本克隆群的映射关系,但没有考虑每个主题词所占的整体比例。
7)先将克隆群源代码Token化[14],得到克隆群的Token序列,然后比较其Token串之间的相似度,并最终得到克隆群的映射关系,但无法准确映射Type3类型的克隆代码,且演化过程中文件被重命名,可能无法准确追踪。
1.3向量空间模型
向量空间模型(VSM)是由Salton等[15]于20世纪年代提出的一种文本表示模型,并应用于文本检索系统。其基本思想就是将文本文档以关键词向量的形式表示,每个文本文档可以表示成一个关键词的特征向量,再计算得到关键词的权重向量;最后计算权重向量中间的余弦相似度,并返回结果。
权重向量为:V(d)=(t1,w1(d);t2,w2(d);…;tn,wn(d)),其中:V(d)是文档d的向量表示,ti表示文档中的特征项,wi(d)表示特征项ti在文档d中的权值,ti在文档d中出现的频率,即wi(d)=ψ(tfi(d))。
计算方法中每一个特征项的权重取决于两个元素:特征项ti在文档d中的词频(Term Frequency, TF)和在整个文档集的逆向文件频率(Inverse Document Frequency, IDF)。信息检索中最常用到权重计算方法是TFIDF(Term FrequencyInverse Document Frequency)函数,此计算公式为:
ψ=tfi(d)×lb (N/ni)(1)
其中:N表示原文档的数目,ni表示含有词条ti的所有文档的数目。计算公式:
wi(d)=tfi(d) lb (N/ni+0.1)∑ni=1(tfi(d))2×lb2(N/ni+0.1)(2)log的底是多少?是2吧?那么缩写为lb?其上面的2是上标吗?请明确。
一方面,在整个文档集中包含文档中某一词的数量越多,则说明其重要程度代表性越低,其重要程度也就越小;另一方面,某一词在文档中出现的频率越高,则说明其重要程度的代表性越强,其重要程度也就越大。一种常见的相似度测量是著名的余弦测量,当文档向量与查询向量被表示成向量时,它决定了两者之间的角度,如式(3):
Sim(di,dj)=cos θ=[∑nk=1ωk(di)×ωk(dj)]/(∑ni=1ω2k(di))(∑nj=1ω2k(dj))(3)
特征项的权重被确定以后,需要一个排名函数来测量查询和文档向量之间的相似度。一个文档Di和一个查询Q之间的相似度定义为:
1.4改进向量空间模型
基于TFIDF算法思想,本文将自然语言领域中的向量空间模型应用于代码克隆领域,提出了一种新的克隆群映射方法。然而现有的向量空间模型并不完全适用于克隆代码,TFIDF的核心思想为:某一特征项权重的高低依据的是在文档中出现的频率,出现频率越高,并且包含此项的文档数越少,表示其权重越高,关联程度更强,但这些仅仅是经验公式,并不能真实反映出每个特征项的重要程度。这种思想并没有考虑每一个特征项的整体比例,所以在确定每一个特征项权重时存在缺陷。另外,和形式语言不同,代码文档中的词在整个文档集中的出现比例并不能反映其重要程度,所以IDF的计算在软件代码文档中并不适用,因此在代码克隆领域中,须引入其他能表示克隆代码重要程度的度量值。
基于向量空间模型的思想,利用TF概念以及代码中的文件名、函数名等特征项,来表征克隆代码的相似性。一方面,首先通过表示一个词出现在文档中的次数,统计词频建立词频向量,然后对其进行规范化,最终利用cosine定理得到两个权重向量的相似度;另一方面,利用文件名以及函数名等特征项来匹配代码片段的相似性权重。
2基于改进向量空间模型的克隆群映射方法
2.1算法框架
本文使用的是改进的向量空间模型克隆群映射方法,从检测结果中提取克隆群文档,再从克隆群文档中抽取词频向量进行相似度计算,并匹配特征项,从而实现对版本间克隆群的映射。克隆群映射的流程如图1所示。
本文映射算法的思路为:首先对软件的前一版本和后一版本中的每一个克隆群计算词频,得到每个克隆群的词频字典,然后构建权重向量,得到克隆群相似度。同时提取克隆群中的特征项(文件名、函数名、起始行、结束行、代码行数),通过特征项匹配得到特征相似度,最终得到克隆群映射结果,实现了从高维度的代码文档空间到低维度的向量空间的转换。克隆群映射算法如下所示。
有序号的程序——————————Shift+Alt+Y
程序前
输入:FClones检测结果。
输出:克隆群映射结果。
1)
对后一版本Vn+1中的每一个克隆群CGn+1,i
2)
统计CGn+1,i中每个词的词频,存入字典Dn+1,i
3)
提取每个CGn+1,i的特征项,存入特征字典Tn+1,i
4)
对词频字典规范化
5)
对前一版本Vn中的每一个克隆群CGn, j
6)
统计CGn, j中每个词的词频,存入字典Dn, j
7)
提取每个CGn,i的特征项,存入特征字典Tn,i
8)
对词频字典规范化
9)
遍历比较Dn+1,i和Dn, j之间相似度,存储到数组cosin[]中
10)
遍历匹配Tn+1,i和Tn, j,并存储到数组T[]中
11)
IF cosin[k]>=t && T[k]==True
12)
THEN CGn+1,i映射到CGn, j
13)
即CGn+1,i → CGn, j
14)
ELSE
15)
CGn+1,i → NULL
16)
返回映射结果
程序后
2.2克隆群向量空间
2.2.1克隆群文档预处理
预处理是克隆群映射的基础工作。相比自然语言文本信息,形式语言中代码不仅包括与其功能相关的信息,也包括大量的程序语言信息。与编程相关的信息在其领域内大多是相对独立的,几乎不包含代码以及软件的功能信息。为保证克隆群映射更加准确,须将源代码中的编程相关信息进行过滤。
本文使用检测结果是由本团队开发的检测工具Fclones[16]检测得到,检测结果存储在可扩展标记语言(Extensible Markup Language, XML)文件中,存储方式如图2所示。
static void done_state_str ()
{
str_list_destroy (on_list);
str_list_destroy (off_list);
str_list_destroy (on_off_list);
}
2.2.3构建词频向量空间并规范化
经过研究之后发现,假设版本中克隆群有i个词频:D=[D1,D2,…,Di],每个目标都有相应的关键字。不同关键字之间的数量级差异可能很大,如果直接用词频计算余弦距离,就不能很好地平均反映出每个关键字的特性,所以必须对词频进行规范化。
词频规范化的方法如下:
ωi=Di/(∑ni=0Di)(5)
其中:Di是克隆群向量中词频的实际值;ωi为规范化后得到的权重值。
获得克隆群目标权重向量:
ω=[ω1,ω2,…,ωi]
2.2.4计算向量空间相似度
目前,克隆代码领域内判断相似程度的方法主要有基于文本和位置的映射方法。基于文本的相似度计算方法包括:最长公共子序列(Longest common subsequence)、杰卡德距离(Jaccard distance)、编辑距离(Levenshtein distance)等。基于位置的相似度计算方法是位置重叠率(Location overlapping rate)的计算,其原理就是将克隆代码的起止行号表示为克隆粒度的相对行号,然后依据特定的公式计算其重叠率。
本文使用的相似性计算方式是余弦距离。计算两个文本相似度时采用的相似度计算公式如下:
CosSimilarity(ωi,ωj)=(∑ni, j=1(ωi*ωj))/∑ni=1ω2i∑nj=1ω2j(6)
其中:ωi*ωj指的是克隆群词频向量的内积;CosSimilarity(ωi*ωj)的取值范围是[0,1]。当克隆群中的克隆片段在演化过程中发生了变化,CosSimilarity的值小于等于1,本文启发式地设置一个阈值,把所有CosSimilarity≥t的克隆群对当作候选的具有映射关系的克隆群对。如果一个克隆群在相邻版本中有多个克隆群可能与其具有映射关系,则分别计算源代码的相似性,选取源代码相似性符合阈值条件的那些克隆群作为具有映射关系的候选克隆群。
2.3克隆群特征项
2.3.1选取克隆群特征项
为了保证克隆群映射的准确度,须匹配克隆群中的函数名等多个特征项,本文选取了文件名、函数名、起始行、结束行以及代码行数5个特征项来衡量一个克隆群的属性信息。具体特征项如表3所示。
2.3.2提取特征项
确定克隆群特征项之后,需提取出所需的克隆群特征项,并放入特征项字典中。文件名的属性字典表示为:File={“文件名”:FileName},函数名属性字典表示为:Fun={“函数名i”:FunName[i]},每一个克隆群可能包含多个函数,所以字典中包含多个函数名,克隆群特征项提取算法如下所示。
有序号的程序——————————Shift+Alt+Y
程序前
输入:XML文件。
输出:文件名、开始行、结束行、函数名。
1)
定义函数getFeatures(XMLpath)
2)
ElementTree ← 将XML文件解析为元素树
3)
root ← 获取ElementTree的根节点
4)
遍历查找根节点root下节点为source的所有内容
5)
查找并返回id、clones、sourcecode
6)
遍历查找根节点root下节点为sourcecode的所有内容
7)
查找并返回FunName
程序后
将已提取的特征项字典存储为XML文件,某克隆群的特征项字典如图4所示。
3.2评价方法
从源代码中映射克隆群可以看作一个分类问题,将相邻版本的克隆群代码之间进行分类,即分为有映射关系和无映射关系两类。本文选取分类中的经典评价方法:从查准率(precision)、查全率(recall)以及F值三方面来评估映射方法的效果,定义如下。
1)准确率:
precision=|TP|/(|TP|+|FP|)(8)
2)查全率:
recall=|TP|/(|TP|+|FN|)(9)
3)F值:
F=2*precision*recall/(precision+recall)(10)
其中:TP表示发现的真映射克隆群个数;FP表示发现的假映射克隆群个数;FN表示未发现的真映射克隆群个数。
3.3实验过程
3.3.1阈值选取实验
阈值选取的好坏直接影响到克隆群映射的效果,本文选取并验证阈值设置为0.6,0.65,0.7,0.75,0.8,0.85,0.9和0.95时映射结果的查全率和查准率。设置为不同阈值时查准率和查全率如图5所示,其中:X轴表示选取的不同阈值t,Y轴表示不同阈值下的查全率和查准率。
从图5可以看出,当阈值取0.85时克隆群相似度结果的查全率和查准率最高,即相似度在区间[0.85,1]范围内并且特征项匹配成功后则认为具有映射关系。
3.3.2克隆群映射实验
实验以版本号为时间线,往后追溯映射关系,查找克隆变化。为使得实验结果更加有效,本文进行了大量的对比实验并选取了bluefish1.0.5版本和bluefish1.0.6版本进行结果展示,图6显示了bluefish1.0.5版本和bluefish1.0.6两个相邻版本的克隆群映射结果。
图6中第1行表示版本的名称以及所对应的版本号;第一列表示当前版本中的克隆群id号,前一版本bluefish1.0.5中含有32个克隆群,后一版本bluefish1.0.6中含有32个克隆群;第2列的箭头表示具有映射关系;第3列的数据表示下一版本克隆群中与当前版本具有映射关系的克隆群以及相似度。例如,bluefish1.0.5版本中13号克隆群和bluefish1.0.6版本中13号和15号克隆群具有映射关系,在代码维护中可能作了一致性的修改。bluefish1.0.5版本中4号克隆群没有找到与其具有映射关系的克隆群,可能是因为从上一版本到下一版本的演化过程发生了较大的变化而未达到阈值的范围,或者被去除。
另外,从图6中也可以看出,绝大多数具有映射关系的克隆群的相似度为1.0,这说明版本中的克隆群在演化过程中没有发生变化,很少一部分的相似度值接近1.0,这说明克隆群中的克隆代码在演化过程中只是作了一定程度上的微调,即语句的修改和增删。
3.4实验结果与分析
本文对5款开源软件中的471个克隆群进行实验,这些克隆群为已知映射关系的克隆群,将映射结果和已知数据进行人工比对,找出实验中的误检数和漏检数。表6展示了目标软件中的471个克隆群映射结果(误检数和漏检数)。
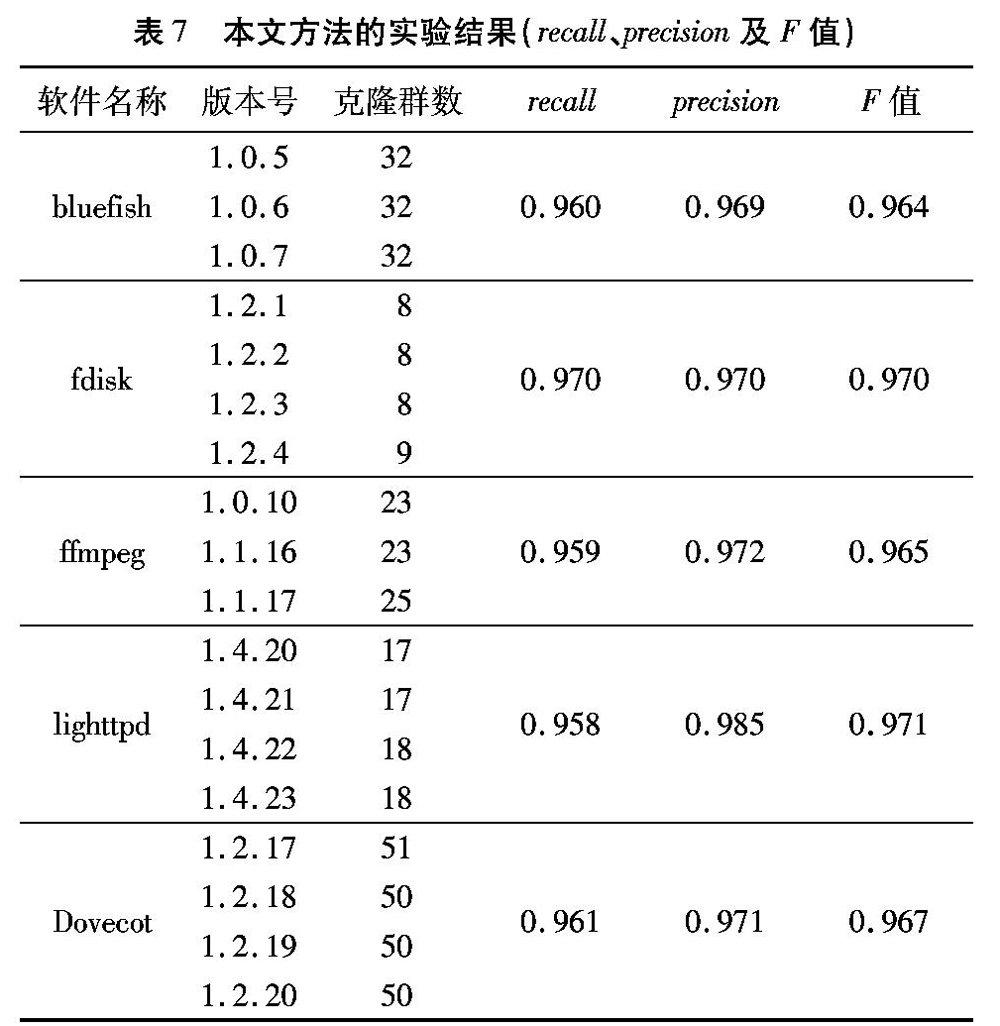
在进行大量的实验之后,进行了人工验证,得到了克隆群映射的查全率和查准率。针对实验映射结果,本实验查准率为471/484=0.973,查全率为471/490=0.961。在实验中查准率相对较高的原因是克隆群特征项匹配时函数名匹配不成功,导致原本具有映射关系的部分克隆群被过滤掉,具体验证结果见表7。
从表7可以看到,本文提出的映射方法整体查准率以及查准率都能达到96%以上,而且F值也达到了96%以上。说明本文克隆群映射方法能达到预期效果。上述实验在5款开源软件的62个版本上进行了对比实验以及人工验证,证明本文提出的基于改进的向量空间模型克隆群映射方法有效可行。
经过进一步的分析发现,影响本文映射方法的有以下3方面原因。
1)克隆检测工具的选取。
克隆检测结果是进行克隆映射的基础数据,克隆检测工具的性能直接影响克隆群映射的结果,因此,选取准确高效的克隆检测工具是本文研究的重要前提。
2)映射方法阈值的界定。
本文的映射方法阈值的选取是通过人工验证得到的,所以在一定程度上会影响映射的准确率。另外,软件的开发语言不同,版本间的差异程度也不同,相同的阈值不能很好地表示不同的软件,可能会影响映射效果。
3)版本开发方式的差异。
本文分析的是连续多版本软件的映射信息,若版本经过较大变动,会导致映射结果超过阈值,从而影响映射准确度,因此选择稳定更新的连续版本进行克隆群映射效果最佳。
4结语
针对当前Type3克隆代码映射存在的问题,本文提出了基于改进向量空间模型的克隆群映射方法,通过相邻版本间克隆群词频向量的计算,将映射内容由高维度的代码空间简化为向量空间中的向量运算;同时提取克隆群的特征项,匹配计算特征项,进而实现连续版本间克隆群的映射,实现原型克隆群映射工具,该工具能高效映射Type1、Type2以及Type3克隆代码。最后对5款开源软件进行对比实验,并进行人工验证,发现本文提出的克隆群映射方法的查全率和查准率都能达到0.96以上,充分验证了本文映射方法的有效性。
本文研究工作依然存在一定的缺陷和不足,例如设置阈值参数时是人工进行验证设置,无法自动根据软件自动调整。另外匹配规则仍需改善,比如当函数名发生变化时可能影响匹配准确度。这些问题将是下一步研究工作中的重点。
参考文献:
[1]
NGUYEN H A, NGUYEN T T, PHAM N H, et al. Clone management for evolving software [J]. IEEE Transactions on Software Engineering, 2012, 38(5): 1008-1026.
[2]
ZIBRAN M F, ROY C K. The road to software clone management: a survey [R]. Saskatoon, SK: The University of Saskatchewan, 2012: 1-66.
[3]
ROY C K, ZIBRAN M F, KOSCHKE R. The vision of software clone management: past, present, and future [C]// Proceedings of the 2014 IEEE Conference on Software Maintenance, Reengineering & Reverse Engineering. Piscataway, NJ: IEEE, 2014: 18-33.
[4]
SIDOROV G, GELBUKH A, GóMEZADORNO H, et al. Soft similarity and soft cosine measure: similarity of features in vector space model [J]. Computación Y Sistemas, 2014, 18(3):491-504.
[5]
BETTENBURG N, SHANG W, IBRAHIM W, et al. An empirical study on inconsistent changes to code clones at release level [J]. Science of Computer Programming, 2009, 77(6): 85-94.
[6]
史庆庆,孟繁军,张丽萍,等.克隆代码技术研究综述[J].计算机应用研究,2013,30(6):1617-1623.(SHI Q Q, MENG F J, ZHANG L P, et al. Survey of research on code clone technique [J]. Application Research of Computers, 2013, 30(6): 1617-1623.)
[7]
THUMMALAPENTA S, CERULO L, AVERSANO L, et al. An empirical study on the maintenance of source code clones [J]. Empirical Software Engineering, 2010, 15(1): 1-34.
[8]
DUALAEKOKO E, ROBILLARD M P. Tracking code clones in evolving software [C]// Proceedings of the 2007 International Conference on Software Engineering. Washington, DC: IEEE Computer Society, 2007: 158-167.
[9]
CANFORA G, CERULO L, PENTA M D. Identifying changed source code lines from version repositories [C]// Proceedings of the Fourth International Workshop on Mining Software Repositories. Washington, DC: IEEE Computer Society, 2007: 14-14.
[10]
DUALAEKOKO E, ROBILLARD M P. Clone region descriptors: Representing and tracking duplication in source code [J]. ACM Transactions on Software Engineering and Methodology, 2010, 20(1): 483-496.
[11]
GDE N, KOSCHKE R. Incremental clone detection [C]// Proceedings of the 13th European Conference on Software Maintenance and Reengineering. Piscataway, NJ: IEEE, 2009: 219-228.
[12]
KAMIYA T, KUSUMOTO S, INOUE K. CCFinder: a multilinguistic tokenbased code clone detection system for large scale source code [J]. IEEE Transactions on Software Engineering, 2002, 28(7): 654-670.
[13]
张瑞霞,张丽萍,王春晖,等.基于主题建模技术的克隆群映射方法[J].计算机工程与设计,2015,36(6): 1524-1529.(ZHANG R X, ZHANG L P, WANG C H, et al. Clone group mapping method based on topic modeling [J]. Computer Engineering and Design, 2015, 36(6): 1524-1529.)
[14]
涂颖,张丽萍,刘东升,等.基于软件多版本演化提取克隆谱系[J].计算机应用,2015,35(4):1169-1173.(TU Y, ZHANG L P, LIU D S, et al. Clone genealogies extraction base on software evolution over multiple versions [J]. Journal of Computer Applications, 2015, 35(4): 1169-1173.)
[15]
SALTON G, WONG A, YANG C S. A vector space model for automatic indexing [J]. Communications of the ACM, 1975, 18(11): 613-620.
[16]
张久杰,王春晖,刘东升,等.基于Token编辑距离检测克隆代码[J].计算机应用,2015,35(12):3536-3543.(ZHANG J J, WANG C H, LIU D S, et al. Code clone detection based on Levenshtein distance of token [J]. Journal of Computer Applications, 2015, 35(12): 3536-3543.)
